基于LangChain框架编写大模型应用的过程就像垒积木,其中的积木就是Prompts,LLMs和各种OutputParser等。如何将这些积木组织起来,除了使用基本Python语法调用对应类的方法,一种更灵活的方法就是使用位于LangChain-Core层中的LCEL(LangChain Expression Language)。
使用LCEL,我们可以获得流式支持、异步和并行执行支持,同时提供了中间结果访问、验证输入输出模式及无缝的LangSmith追踪和LangServe部署。通过这些能力,LCEL为用户提供了一种高效、可靠和易于维护的方式来构建和部署复杂的LLM应用程序。
在前一篇文章《LangChain入门学习笔记(一)——Hello World》中
chain = prompt | llm | output_parser这一行的代码跟其他行Python语法不同,是的,它就是使用了LCEL进行的编写。使用LCEL的好处可以参考官方文档的这篇文章。
Runnable接口
LCEL的基础是Runnable接口。通过实现Runnable接口,LCEL定义了一组具有通用调用方式的方法集。LangChain代码中定义的Runnable如下:
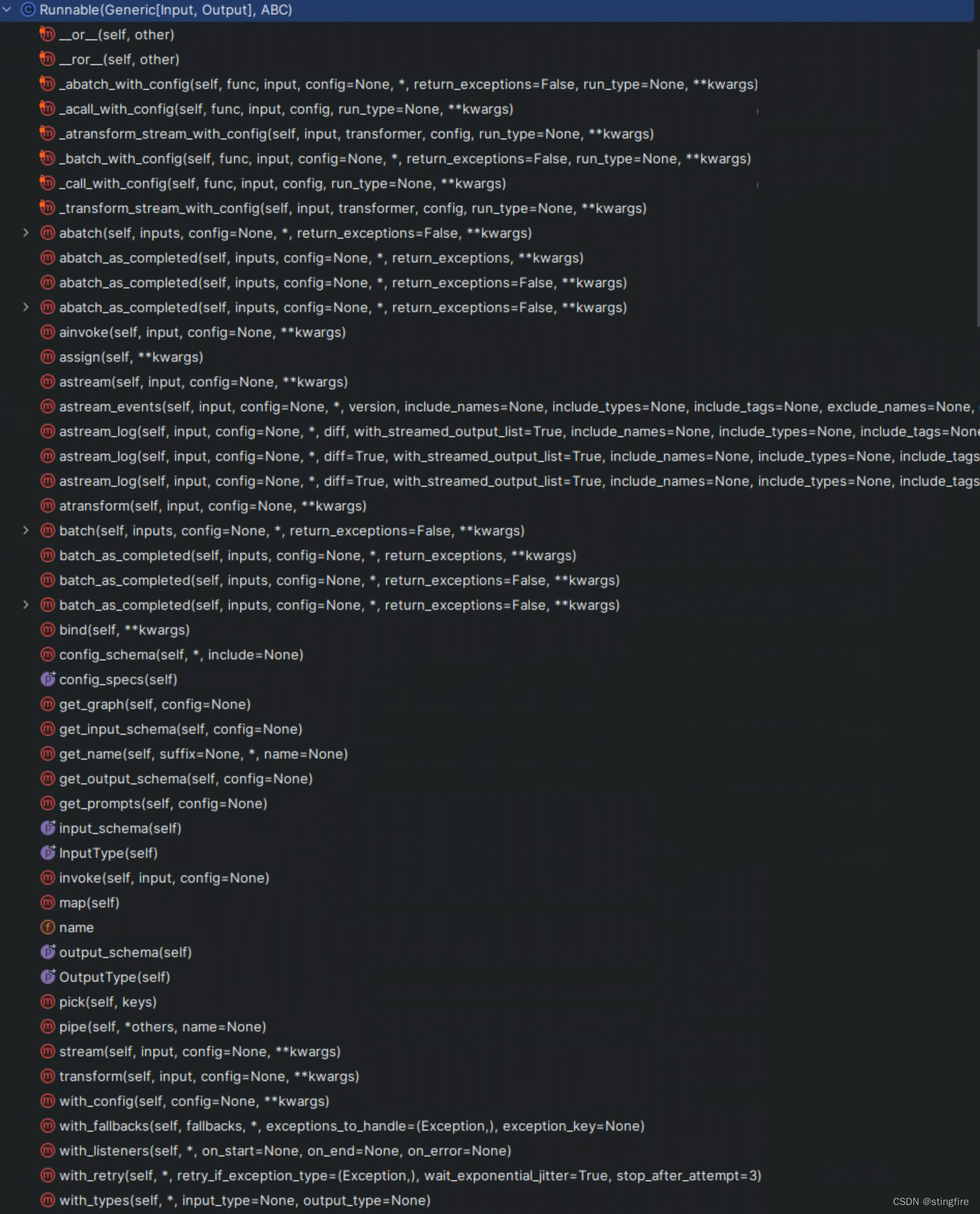
它有一系列的子类,比如PromptTemplate、LLM和StrOutputParser(还有更多),这些组件子类都间接继承自Runnable(继承自RunnableSequence,而后者又继承自Runnable)。
Runnable的__or__()方法重新定义了"|"语法,所以基于LCEL的chain就能通过或(也类似shell中的管道)操作符号"|"串起来。这也就是前面提到的“chain = prompt | llm | output_parser”这行代码虽然看上去跟普通Python不一样,但它是合法的,原因就在这里。__or__()的定义如下:
def __or__(
self,
other: Union[
Runnable[Any, Other],
Callable[[Any], Other],
Callable[[Iterator[Any]], Iterator[Other]],
Mapping[str, Union[Runnable[Any, Other], Callable[[Any], Other], Any]],
],
) -> RunnableSerializable[Input, Other]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(self, coerce_to_runnable(other))可以看出通过"|"(__or__()重定义的管道操作)前后两个组件合成一个Runnable的子孙类RunnableSequence对象返回,从而达到串起来形成链(chain)的目的。
此外,Runnable还定义了一系列的标准方法,方便统一使用这套标准的定义:
stream/astream: 同步/异步流式化组件响应。
invoke/ainvoke: 同步/异步接收输入并调用链(chain)。
batch/abatch: 同步/异步接收批量输入并调用链(chain)。
input_schema/output_schema: 描述Runnable的输入/输出的结构,用于类型检查和可视化调试。
继承自Runnable的各类组件,输入输出类型如下表所示:
| 组件 | 输入类型 | 输出类型 |
|---|---|---|
| Prompt | 字典 | PromptValue |
| ChatModel | 单个String,ChatMessage列表,或者PromptValue | ChatMessage |
| LLM | 单个String,ChatMessage列表,或者PromptValue | String |
| OutputParser | LLM或ChatModel的输出 | 根据所使用的Parser确定 |
| Retriever | 单个String | Document列表 |
| Tool | 依赖所使用的Tool,可能是单个String也可能是字典 | 依赖所使用的Tool |
LCEL的基元操作
LangChain表达式语言LCEL包含了一些基础的操作,称为基元操作(Primitives)。
串形化(Sequences)
如前介绍Runnable时所述,通过管道操作符"|",将前一个Runnable组件的RunnableSequence输出结果作为下一个Runnable组件的输入,以此类推形成一个chain,再调用.invoke()方法发生“链式反应”得到最终输出。
下面用代码举例,为了国内访问方便,未使用官网的OpenAI接口,取而代之的是阿里的百炼,接入方法见阿里云文档《如何集成langchain》。
首先安装对应的Python模块:
pip install langchain-bailian阿里云账号授权及环境变量设置,可以参考这篇文章《搭建访问阿里云百炼大模型环境》。然后可以编写Python代码如下进行调用:
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_bailian import Bailian
# 构建prompt
prompt = ChatPromptTemplate.from_template("给我讲一个关于 {topic}的笑话")
# 构建LLM模型
# 需要在环境变量设置ACCESS_KEY_ID、ACCESS_KEY_SECRET、AGENT_KEY和APP_ID
access_key_id = os.environ.get("ACCESS_KEY_ID")
access_key_secret = os.environ.get("ACCESS_KEY_SECRET")
agent_key = os.environ.get("AGENT_KEY")
app_id = os.environ.get("APP_ID")
llm = Bailian(access_key_id=access_key_id,
access_key_secret=access_key_secret,
agent_key=agent_key,
app_id=app_id)
chain = prompt | llm | StrOutputParser()
print(chain.invoke({"topic": "人才"}))上面的"chain = prompt | llm | StrOutputParser()"这一行代码能够串联运行,是因为:
- prompt和llm以及StrOutputParser都是Runnable的子类,重定义了"|"操作符;
- 前一个的输出类型和后一个的输入类型相同;
调用chain的invode方法,输出结果如下:

还可以将上面的chain作为另一个链中的一个输入,这需要用到一种称作强制转换(Coercion)的概念。
比如我们再假设需要构造一个链来评估前面生成的笑话故事,可以在前面代码后面添加:
analysis_pompt = ChatPromptTemplate.from_template("这个笑话好笑吗?{joke}")
composed_chain = {"joke": chain} | analysis_pompt | llm | StrOutputParser()
print(composed_chain.invoke({"topic": "人才"}))这里{"joke": chain}会被自动解析成RunnableParallel,并行运行chain后返回一个包含结果的字典作为analysis_prompt的输入,而后者的输入类型正是字典类型,所以整个组合链成功。运行结果如下:

当然也可以使用代码完成上面的串形化,只是看上去不那么“美观”,例子如下:
from langchain_core.runnables import RunnableParallel
composed_chain_with_pipe = (
RunnableParallel({"joke": chain})
.pipe(analysis_prompt)
.pipe(model)
.pipe(StrOutputParser())
)显然使用"|"更显得简单明了。
并行化(Parallelism)
LangChain的基本形态是一条链将每个组件串起来处理,如果涉及到不同任务需要不同的链处理的话,就需要应用并行化能力。这里的并行不是新起线程进程的并发,而是执行多个链,在不同链之间是同时进行而又相互有关联。
假设这么一个场景:我们需要一个LLM给我们讲笑话,另一个LLM作诗,可以这么编写:
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_bailian import Bailian
from langchain_core.runnables import RunnableParallel
# 构建LLM模型
# 需要在环境变量设置ACCESS_KEY_ID、ACCESS_KEY_SECRET、AGENT_KEY和APP_ID
access_key_id = os.environ.get("ACCESS_KEY_ID")
access_key_secret = os.environ.get("ACCESS_KEY_SECRET")
agent_key = os.environ.get("AGENT_KEY")
app_id = os.environ.get("APP_ID")
llm = Bailian(access_key_id=access_key_id,
access_key_secret=access_key_secret,
agent_key=agent_key,
app_id=app_id)
# 一个链讲关于给定topic的笑话
joke_chain = ChatPromptTemplate.from_template("给我讲一个关于{topic}的笑话") | llm
# 一个链作关于给定topic的诗
poem_chain = ChatPromptTemplate.from_template("写一首关于{topic}的两行诗") | llm
# 生成并行处理的两个链
map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)
print(map_chain.invoke({"topic": "人才"}))
通过RunnableParallel对象生成了包含两个chain的并行处理链,返回包含键值分别为"joke"和"poem"的map对象:

参数传递
创建好chain之后,它处理的输入数据不可能固定不变,如何将外部输入传给chain并保持不变就需要RunnablePassthrough;在chain处理的过程中可能会产生新的数据传给下游组件使用,这时需要RunnablePassthrough.assign()静态方法传给指定函数。
“直通车”RunnablePassthrough
RunnablePassthrough能保持你传入的输入不变,可以简单理解它是输入的变量符。
看官方文档例子:
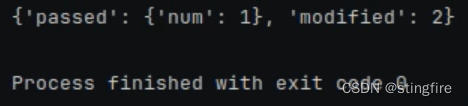
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
runnable = RunnableParallel(
passed=RunnablePassthrough(),
modified=lambda x: x["num"] + 1,
)
print(runnable.invoke({"num": 1}))对于passed,被RunnablePassthrough直接不变的赋予了传入的{"num": 1},对于modified则通过lambda表达式取得输入的"num"键值并加1,所以返回了2。最终的结果如下:
添加字段的“Assign”
在实际应用中,我们可能会产生一些中间计算的值——也许是业务计算结果或者设置观测用的值。这时我们使用RunnablePassthrough.assign()静态方法将这些值添加到一些设定的变量上。来看官方文档例子:
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
runnable = RunnableParallel(
extra=RunnablePassthrough.assign(mult=lambda x: x["num"] * 3),
modified=lambda x: x["num"] + 1,
)
print(runnable.invoke({"num": 1}))我们先看这段代码的返回:

对比前面“RunnablePassthrough”一节的输出,我们通过RunnablePassthrough.assign()给输入的字段新增了mult的键值对。
处理逻辑的控制
在实际处理中,除了数据的变化之外,我们可能对处理链的逻辑也要做到控制。
自定义处理函数
可能我们需要对输入的prompt进行一些自定义的处理,这时候将自定义的处理逻辑函数作为传参对象传入RunnableLambda,不过要注意的是目前RunnableLambda只接受一个参数的函数定义。具体例子见下面,其中"b"的输入“{"text1": itemgetter("foo"), "text2": itemgetter("bar")}”封装为一个参数传给multiple_length_function,后者其实需要的参数是两个:
import os
from operator import itemgetter
from langchain_bailian import Bailian
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
def length_function(text):
return len(text)
def _multiple_length_function(text1, text2):
return len(text1) * len(text2)
def multiple_length_function(_dict):
return _multiple_length_function(_dict["text1"], _dict["text2"])
prompt = ChatPromptTemplate.from_template("what is {a} + {b}")
access_key_id = os.environ.get("ACCESS_KEY_ID")
access_key_secret = os.environ.get("ACCESS_KEY_SECRET")
agent_key = os.environ.get("AGENT_KEY")
app_id = os.environ.get("APP_ID")
model = Bailian(access_key_id=access_key_id,
access_key_secret=access_key_secret,
agent_key=agent_key,
app_id=app_id)
chain1 = prompt | model
# 传入的Json字段值经过RunnableLambda处理
# "a"通过itemgetter("foo")获得"hello",再经过length_function处理,结果是 "a": 5
# "b"通过itemgetter得到{"text1":"hello", "text2":"world!",再经过multiple_length_function处理,结果是"b": 30
# "b"的处理有个注意事项,RunnableLambda接受的函数是只能有一个参数,所以这里的multiple_length_function是个接受封装了text1和text2的对象
chain = (
{
"a": itemgetter("foo") | RunnableLambda(length_function),
"b": {"text1": itemgetter("foo"), "text2": itemgetter("bar")} | RunnableLambda(multiple_length_function),
}
| prompt
| model
)
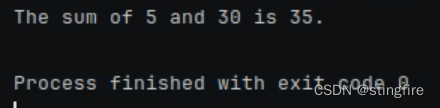
# "a": 5; "b": 30, 所以传入的prompt是"what is 5 + 30",结果是35。
print(chain.invoke({"foo": "hello", "bar": "world!"}))
最终输出:
RunnableLambda还能使用RunnableConfig传递一些回调、标签和其他配置信息。使用样例可以参看这里的“Accepting a Runnable Config”一节。
配置Prompt和LLM的字段属性
LLM的模型参数
有时候我们需要提供用户一些选择,让他们能够指定提示语或者模型的参数,这里使用configurable_fields方法。(由于bailian中的temperature在平台的应用中心配置,没有看到可以通过代码配置的方法,下面采用Ollama本地化部署llama3进行实验。具体方法可以参考前一篇文章这里的“LangChain本地运行LLM”部分。)
from langchain_community.llms import Ollama
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
# 通过configurable_fields设置temperature为可配置字段
model = Ollama(model="llama3", temperature=0).configurable_fields(
temperature=ConfigurableField(
id="llm_temperature",
name="LLM Temperature",
description="The temperature of the LLM",
)
)
prompt = PromptTemplate.from_template("pick a random number above {x}")
chain = prompt | model
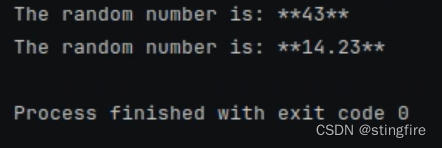
# 使用初始化时temperature为0的配置
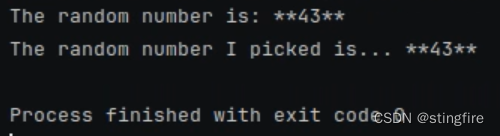
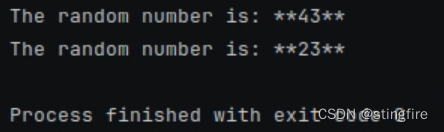
print(chain.invoke({"x": 0}))
# 根据id设置参数temperature为0.99
print(chain.with_config(configurable={"llm_temperature": 0.99}).invoke({"x": 0}))
从上面代码中,我们通过configurable_fields设置了temperature为可配置的变量字段,指定id为"llm_temperature"。后面在使用时,通过with_config方法的configurable参数指定这个id进行赋值(比如例子中将初始化设置的0改为了0.99)。多次执行可以发现temperature在0.99时明显比为0时更随机些,说明设置有效:
prompt的模版选择
有时候我们可以复用一些现成的prompt模板,在不同场景下选择不同的prompt库进行加载。这时候选择使用HubRunnable的configurable_fields方法(继承自RunnableSerializable)进行参数设置:
from langchain.runnables.hub import HubRunnable
from langchain_core.runnables import ConfigurableField
# 使用了"rlm/rag-prompt"的模板
prompt = HubRunnable("rlm/rag-prompt").configurable_fields(
owner_repo_commit=ConfigurableField(
id="hub_commit",
name="Hub Commit",
description="The Hub commit to pull from",
)
)
# 打印"rlm/rag-prompt"的模板被赋值后的ChatPromptValue内容
print(prompt.invoke({"question": "foo", "context": "bar"}))
# 使用了"rlm/rag-prompt-llama"的模板,打印被赋值后的内容
print(prompt.with_config(configurable={"hub_commit": "rlm/rag-prompt-llama"}).invoke(
{"question": "foo", "context": "bar"}
))
# prompt在调用with_config之后,还是原来的对象
# 下面两个print方法打印结果后可以发现new_prompt用的"rlm/rag-prompt-llama", prompt还是用的"rlm/rag-prompt"
new_prompt = prompt.with_config(configurable={"hub_commit": "rlm/rag-prompt-llama"})
print(new_prompt.invoke({"question": "foo", "context": "bar"}))
print(prompt.invoke({"question": "foo", "context": "bar"}))
输出的结果是:

HubRunnable传入的参数"rlm/rag-prompt"是prompt模板路径,具体内容可以参考仓库地址:
- "rlm/rag-prompt":LangSmith
 https://smith.langchain.com/hub/rlm/rag-prompt
https://smith.langchain.com/hub/rlm/rag-prompt - "rlm/rag-prompt-llama":LangSmithhttps://smith.langchain.com/hub/rlm/rag-prompt-llama其他模板可以访问下面地址查询:LangSmithhttps://smith.langchain.com/hub
备选prompt设置
通过HubRunnable我们可以从prompt的模板仓库中选择prompt模板进行提示语的生成。另一种提供多种prompt的方法是通过configurable_alternatives方法(继承自RunnableSerializable)给prompt赋予多个prompt备选。我们来看下面例子:
from langchain_community.llms import Ollama
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
model = Ollama(model="llama3", temperature=0)
prompt = PromptTemplate.from_template(
"Tell me a joke about {topic}"
).configurable_alternatives(
# 指定id,在后面设置配置值时进行引用
ConfigurableField(id="prompt"),
# 默认key,在后面设置时用这里的值"joke"指定前面的prompt “Tell me a joke about {topic}"
default_key="joke",
# 添加一个prompt选项,命名为"poem",后面用"poem"指定时将使用这里的prompt
poem=PromptTemplate.from_template("Write a short poem about {topic}"),
# 添加一个prompt选项,命名为"poem",后面用"poem"指定时将使用这里的prompt
essay=PromptTemplate.from_template("Write a short essay about {topic}"),
# 后面还可以继续添加
)
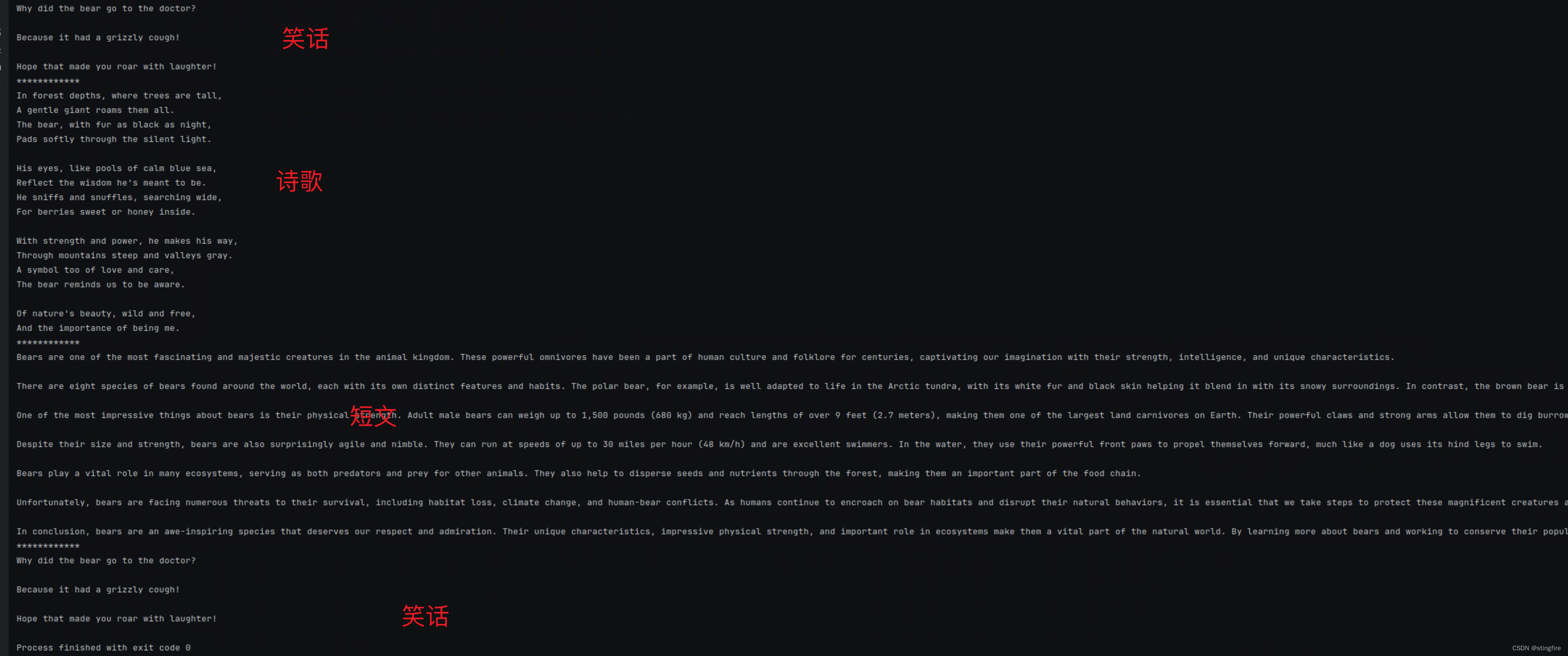
chain = prompt | model
# 直接使用chain中默认定义的prompt,写个笑话
print(chain.invoke({"topic": "bears"}))
print("************")
# 切换到"poem"这个prompt, 写一首诗
print(chain.with_config(configurable={"prompt": "poem"}).invoke({"topic": "bears"}))
print("************")
# 切换到"essay"这个prompt, 写一篇短文
print(chain.with_config(configurable={"prompt": "essay"}).invoke({"topic": "bears"}))
print("************")
# 切换到"joke"默认key, 写个笑话。这里明确指定名称,其实可以不指定,直接就是使用了默认prompt
# 如果在configurable_alternatives方法中没有指定default_key值(在这里指定了"joke"),那么"prompt"的值就是"default"
print(chain.with_config(configurable={"prompt": "joke"}).invoke({"topic": "bears"}))
通过configurable_alternatives的设置,我们提供了默认的"joke"(使用定义时from_template方法中指定的prompt), "poem","essay"三个prompt选项。如果需要使用哪个prompt,通过with_config方法给ConfigurableField中指定的id赋值即可。上面代码输出的结果如下:
备选LLM设置
通过configurable_alternatives方法,我们还能设置备选的大模型。使用方式和prompt类似,在初始化大模型实例时调用configurable_alternatives方法提供多个备选大模型。
import os
from langchain_bailian import Bailian
from langchain_community.llms import Ollama
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
access_key_id = os.environ.get("ACCESS_KEY_ID")
access_key_secret = os.environ.get("ACCESS_KEY_SECRET")
agent_key = os.environ.get("AGENT_KEY")
app_id = os.environ.get("APP_ID")
model = Ollama(model="llama3", temperature=0).configurable_alternatives(
ConfigurableField(id="llm"),
default_key="llama3",
bailian=Bailian(access_key_id=access_key_id,
access_key_secret=access_key_secret,
agent_key=agent_key,
app_id=app_id)
)
prompt = PromptTemplate.from_template(
"Tell me a joke about {topic}"
)
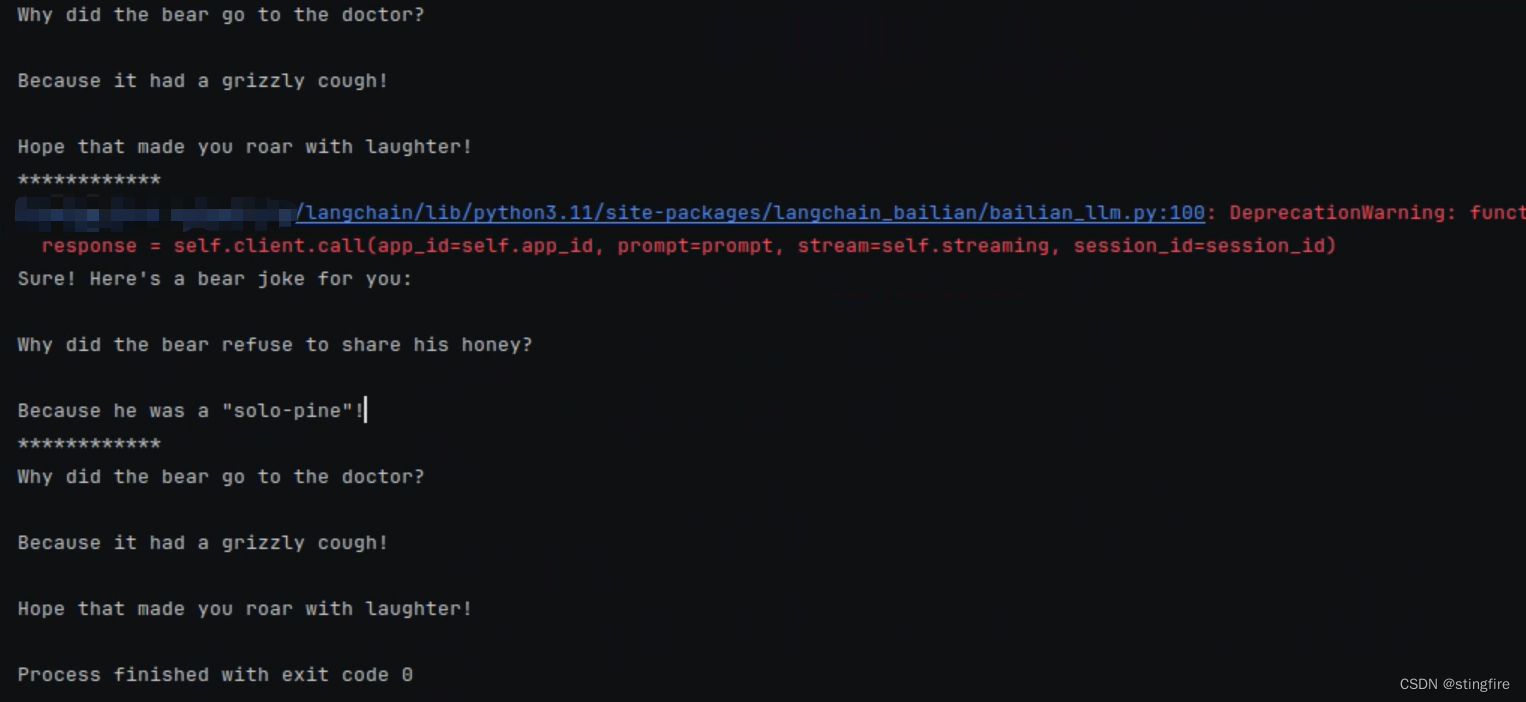
chain = prompt | model
# 使用llama3写个笑话
print(chain.invoke({"topic": "bears"}))
print("************")
# 切换到使用百炼写个笑话
print(chain.with_config(configurable={"llm": "bailian"}).invoke({"topic": "bears"}))
print("************")
# 切换回llama3写个笑话
print(chain.with_config(configurable={"llm": "llama3"}).invoke({"topic": "bears"}))
在上面代码中,定义了llama3的大模型实例,并且定义了bailian作为备选模型。后面代码通过指定"llm"的值来切换使用的LLM。执行结果:
上面备选prompt和llm设置好之后,可以同时选择备选prompt和llm,比如下面代码同时指定了prompt使用"poem"这个来生成一首诗,使用的llm是"llama3":
# 在chain中同时指定prompt和llm
chain.with_config(configurable={"prompt": "poem", "llm": "llama3"}).invoke(
{"topic": "bears"}
)