1.1 什么是注意力机制(attention)
注意力机制(Attention Mechanism)是一种在神经网络中用于增强模型处理特定输入特征的能力的技术。它最早被应用于自然语言处理(NLP)任务中,特别是在机器翻译中,如Google的神经机器翻译系统(GNMT)。其基本思想是,在处理输入数据时,模型能够“关注”到输入序列中的某些部分,而不是平均对待所有部分。这样可以使模型更有效地从数据中提取相关信息,提高处理性能。
注意力机制的核心概念包括:
-
注意力权重(Attention Weights):这些权重决定了模型应该对输入序列中的哪些部分给予更多关注。权重的计算通常依赖于输入序列的上下文信息。
-
加权求和(Weighted Sum):通过对输入特征进行加权求和,可以生成一个“上下文向量”,该向量综合了输入序列中最相关的信息。
-
注意力函数(Attention Function):常见的注意力函数包括点积注意力(Dot-Product Attention)和加性注意力(Additive Attention)。点积注意力通过计算查询和键的点积来确定权重,而加性注意力则通过使用一个小型神经网络来计算权重。
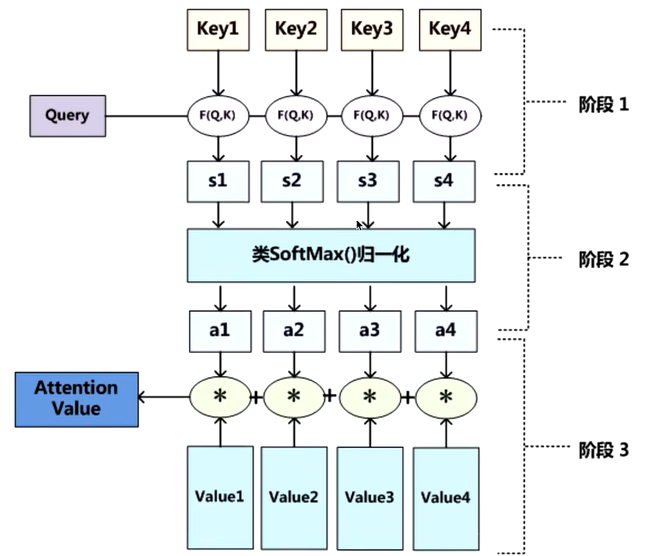
具体来说,注意力机制通常涉及以下步骤:
-
计算相似度得分(Score Calculation):对于给定的查询(Query)和键(Key),计算它们的相似度得分。例如,对于点积注意力,得分可以表示为查询向量和键向量的点积。
-
计算注意力权重(Attention Weights):将相似度得分通过一个softmax函数转换为概率分布,得到注意力权重。
-
生成上下文向量(Context Vector):使用注意力权重对值向量(Value)进行加权求和,得到最终的上下文向量。
注意力机制已经被广泛应用于各种领域,不仅限于自然语言处理,还包括计算机视觉、语音识别等。例如,Transformer架构通过完全依赖注意力机制,去掉了传统的循环神经网络(RNN)和卷积神经网络(CNN),在多种任务上取得了显著的成功。
1.2 什么是自注意力机制(self-attention)
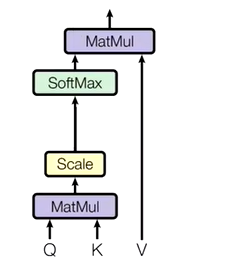
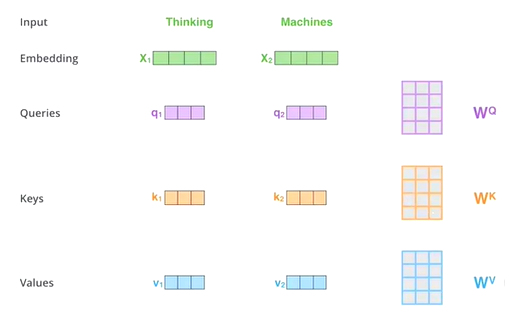
自注意力机制(Self-Attention Mechanism)是一种特殊类型的注意力机制,它特别适用于处理序列数据,如自然语言处理中的句子、计算机视觉中的图像像素序列或时间序列数据。在自注意力机制中,输入序列的每个元素都会扮演双重角色:既是查询(query)也是键(key)和值(value)。这意味着序列中的每个位置不仅与其自身相关,还会考虑与其他所有位置的关系,从而能够捕获序列内不同位置间的复杂依赖关系。
自注意力机制的工作流程大致如下:
-
输入编码:输入序列的每个元素首先转换成一个向量表示,这些向量可以视为包含该位置信息的“值”(Values)。
-
构造查询、键和值:对于序列中的每一个位置,同样的输入向量或者经过不同的线性变换得到查询(Queries)、键(Keys)和值(Values)。尽管它们源自相同的输入,但这些变换使得模型能够从不同角度审视输入信息。
-
计算注意力权重:通过计算查询向量与所有键向量之间的相似度(通常用点积表示),然后应用softmax函数归一化,得到一个权重分布。这个分布反映了序列中每个位置对于当前考虑位置的重要性。
-
加权求和得到输出:使用上述计算出的注意力权重对值向量进行加权求和,从而为每个位置生成一个新的表示,这个表示融合了序列中其他位置的信息,加权方式依据它们的相关性。
自注意力机制的优点在于它能够并行计算,极大地加速了处理过程,同时有效捕捉长距离依赖,提高模型在处理序列数据时的表达能力。这一机制是诸如Transformer架构等现代深度学习模型的核心组件,已经在机器翻译、文本生成、图像识别等多个领域展现了强大的性能。

1.3 Attention和self-attention的区别?
一句话总结:注意力机制包括自注意力机制,且注意力机制的含义很宽泛,并没有明确表明QKV矩阵的来源,而自注意力机制的QKV是同源的,都来源于X。
-
来源不同:
-
注意力机制:在最典型的实现中,注意力机制涉及的查询(Query)和键(Key)来源于不同的数据序列或模型的不同部分。例如,在Encoder-Decoder框架中,解码器(Decoder)中的某一步骤产生的查询向量会与编码器(Encoder)的所有或部分输出键向量进行匹配,以决定哪些输入部分更重要。这种方式允许模型在生成输出时,有选择性地关注输入序列中的相关信息。
-
自注意力机制:相比之下,自注意力机制中的查询、键和值都来自于同一个序列或数据结构内部。也就是说,序列中的每个元素都会基于其自身的表示(作为查询)与其他元素的表示(作为键)进行比较,从而确定彼此间的相关性。这使得模型能够学习序列内部元素间的复杂依赖关系。
-
-
应用场景差异:
-
注意力机制常用于需要跨序列或跨时间步传递信息的场景,如在机器翻译中,将源语言序列的上下文信息引导到目标语言序列的生成过程中。
-
自注意力机制则更侧重于序列内部的元素交互,广泛应用于自然语言处理、图像识别等领域,帮助模型理解序列中每个部分如何相互依赖,尤其适合处理长序列数据,增强模型的全局感知能力。
-
-
并行计算能力:
- 自注意力机制因其内在的对称性,天然支持高度并行化的计算,这对于大规模数据处理和加速训练过程尤为重要,而传统的注意力机制可能因为查询和键来源于不同序列或模型阶段,而难以同样高效地并行化。
1.4 掩码自注意力机制(Masked Self-Attention)
掩码自注意力机制(Masked Self-Attention Mechanism)是自注意力机制的一个变体,主要用于序列生成任务中,尤其是在需要根据已经生成的部分序列预测下一个元素的场景下,比如文本生成、机器翻译等。它通过在自注意力计算过程中引入一个“掩码”(Mask),来控制模型在查看序列中的哪些部分时忽略某些特定位置的输入,从而实现特定的目的,比如避免信息泄露或者指导模型按照一定的顺序处理序列信息。
掩码的具体应用可以分为几种情况:
-
前瞻遮挡(Look-Ahead Mask):在序列生成任务中,为了防止模型在生成一个词时看到序列中它之后的词(这在很多情况下是不允许的,因为它会导致模型“作弊”,直接利用未来信息),会在自注意力层为当前位置之后的所有位置设置掩码,通常这些位置的掩码值会被设置为-∞或其他极小值,以确保这些位置的注意力权重变为0或接近0。这样模型在预测第i个词时,只能看到第i个词之前的词,保证了生成的一致性。
-
填充遮挡(Padding Mask):在处理可变长度序列时,通常需要对较短序列进行填充以达到统一长度。填充遮挡就是用来指示模型哪些位置是实际的输入,哪些是填充的。填充位置的掩码值为0,实际输入位置为1,这样模型在计算注意力权重时会忽略填充位置的影响。
-
下三角遮罩(Lower Triangle Mask):在某些自回归(Autoregressive)模型中,比如Transformer的编码器或解码器部分,会使用下三角遮罩来确保模型在预测序列中的每一个元素时,只依赖于它之前的元素,形成一种从左到右的信息流。
掩码自注意力机制的关键在于通过掩码灵活控制模型的“视野”,既保持了模型处理序列数据的能力,又遵循了序列生成任务必要的限制条件,从而提高了模型的预测能力和效率。

1.5 多头注意力机制(Multi-head Self-Attention)
多头注意力机制(Multi-Head Attention Mechanism)是注意力机制的一种扩展形式,最初在Transformer模型中被提出,现在已被广泛应用于各种深度学习领域,如自然语言处理(NLP)、计算机视觉(CV)等。其核心思想是在不同的表示子空间中独立地执行注意力操作,然后将这些独立的注意力结果合并,以捕获输入数据中的多种类型的相关性。
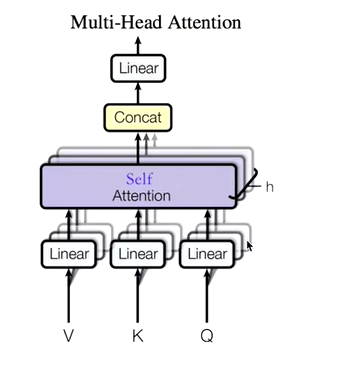
具体来说,多头注意力机制的工作流程如下:
-
输入映射:首先,输入数据(通常是键(Keys, K)、查询(Queries, Q)和值(Values, V))通过线性变换(即权重矩阵乘法)被映射到不同的表示空间。对于每个输入,通常有三个变换矩阵
Wq,Wk, 和Wv,分别用于生成查询、键和值的投影。每个头(Head)都有自己的变换矩阵。 -
多头并行计算:接下来,变换后的查询、键和值被分成多个“头”,每个头对应一个不同的注意力分布计算。这意味着对于每个头,都会独立地执行缩放点积注意力(Scaled Dot-Product Attention)计算,即计算查询和键之间的相似度,然后根据这个相似度对值进行加权求和。
-
注意力结果合并:所有头的输出被连接(Concatenate)或平均(尽管通常采用连接方式)起来,形成一个综合的注意力表示。这个步骤将从不同表示子空间获得的信息融合在一起。
-
输出变换:最后,合并后的注意力表示会通过一个额外的线性变换层,以产生最终的输出,这个输出通常具有与原始输入相同维度。
多头注意力机制的优势在于,它允许模型并行地探索输入数据的不同方面或模式。每个头可以专注于输入的不同部分或特征,从而提升模型捕捉复杂模式和长期依赖关系的能力。这种机制增强了模型的表达能力,是Transformer模型及其他基于注意力机制架构的核心组件之一。



1.6 注意力机制存在的问题
优点:1.解决了长序列依赖问题2.可以并行。
缺点:1.开销变大了。2.既然可以并行,也就是说,词语词之间不存在顺序关系(打乱一句话,这句话里的每个词的词向量依然不会变),即无位置关系(既然没有,我就加一个通过位置编码的形式加)
1.7 位置编码(Positional Encoding)
位置编码(Positional Encoding)是为了解决在使用自注意力机制(Self-Attention Mechanism)和其他类型的序列处理模型时,由于模型本身不包含显式的时序或位置信息,所导致的无法区分序列中不同位置的元素的问题。具体而言,位置编码的作用和目的包括:
-
注入顺序信息:在Transformer等模型中,词嵌入(word embeddings)能够捕获词汇的语义信息,但没有直接的方式表征词语的位置。位置编码通过添加特定的、与位置相关的向量到词嵌入中,使模型能够理解序列中词的位置关系。
-
保留位置顺序:通过为序列中的每个位置分配一个唯一的向量表示,位置编码帮助模型区分“cat sat on the mat”和“on the mat sat cat”的区别,即使两个序列包含相同的词。
-
捕捉长距离依赖:在长序列中,位置编码有助于模型捕捉词语间跨越较远距离的依赖关系,这对于理解复杂的语言结构和上下文非常重要。
-
并行计算兼容性:位置编码能够在保持自注意力机制并行计算优势的同时,引入位置信息,这对于提高模型训练效率至关重要。
位置编码的具体实现方式多样,常见的方法包括使用正弦波和余弦波函数来生成随位置变化的周期性模式,这样既能体现绝对位置,也能区分不同位置的距离关系,同时还保留了对不同尺度信息的敏感性。这种设计使得模型能够区分近邻位置和远距离位置,从而在无序的注意力机制中引入有序性。



那为什么这么做有用呢?