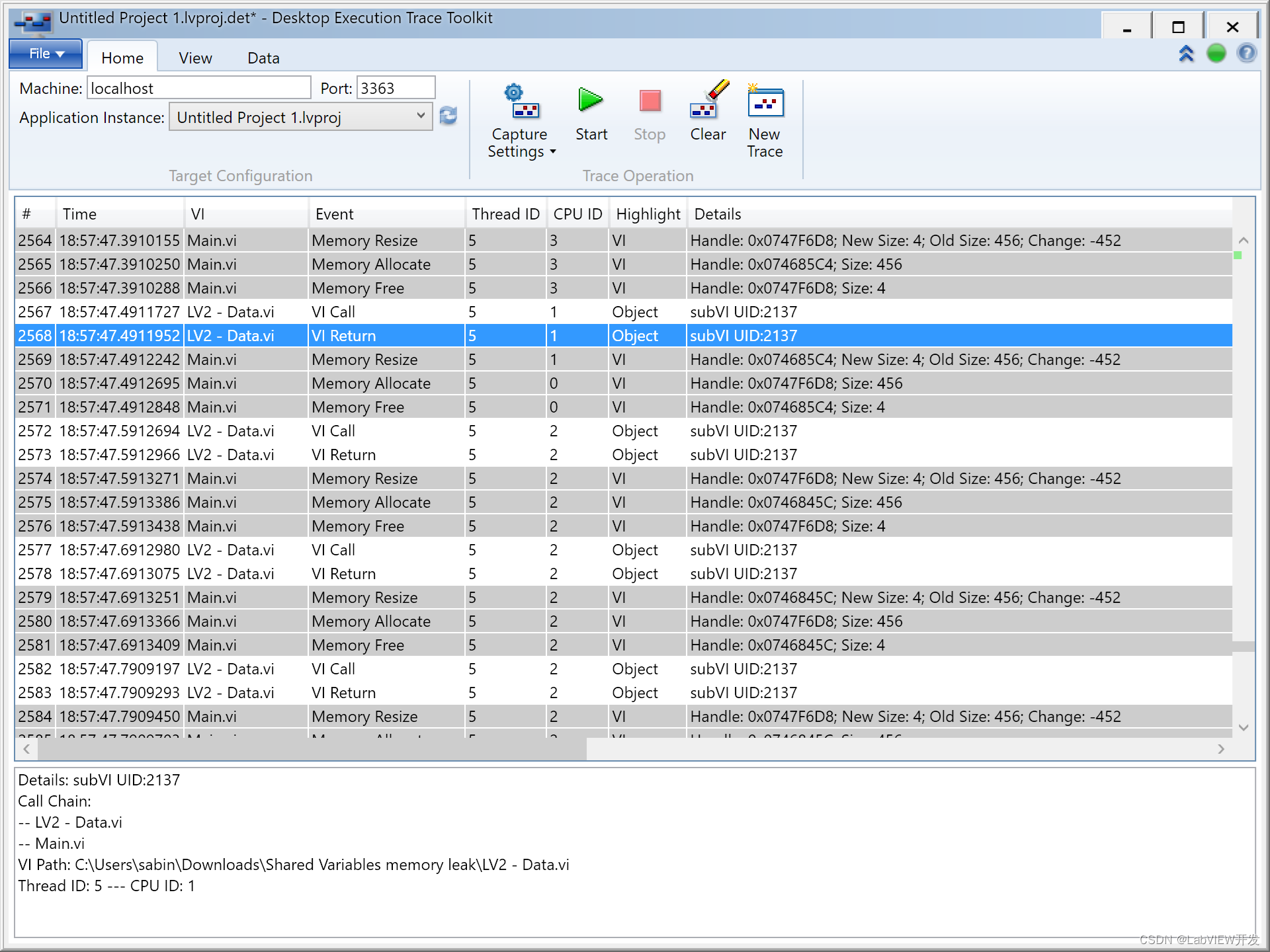
如果得到的是一组样本在两个算法上的一次预测结果,其中每个样本都被赋予了一个为正样本的概率(例如,通过逻辑回归或朴素贝叶斯分类器得到的概率估计),那么可以通过改变不同的阈值点来利用这些预测结果画出PR曲线。
如果得到的是一组样本在两个算法上的一次预测结果,其中输出结果是每个样本的类别(例如决策树、支持向量机、k近邻算法),只能得到两个(R,P)点,无法直接画出完整的PR曲线,只能通过计算该情况下的fβ度量来衡量哪个算法好。

如果得到的是一组样本在两个算法上的一次预测结果,其中每个样本都被赋予了一个为正样本的概率(例如,通过逻辑回归或朴素贝叶斯分类器得到的概率估计),那么可以通过改变不同的阈值点来利用这些预测结果画出PR曲线。
如果得到的是一组样本在两个算法上的一次预测结果,其中输出结果是每个样本的类别(例如决策树、支持向量机、k近邻算法),只能得到两个(R,P)点,无法直接画出完整的PR曲线,只能通过计算该情况下的fβ度量来衡量哪个算法好。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1812303.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!

![[2024-06]-[大模型]-[Ollama] 0-相关命令](https://img-blog.csdnimg.cn/direct/cbfab5ca57e44ec5a7dbb4f02604df70.png)