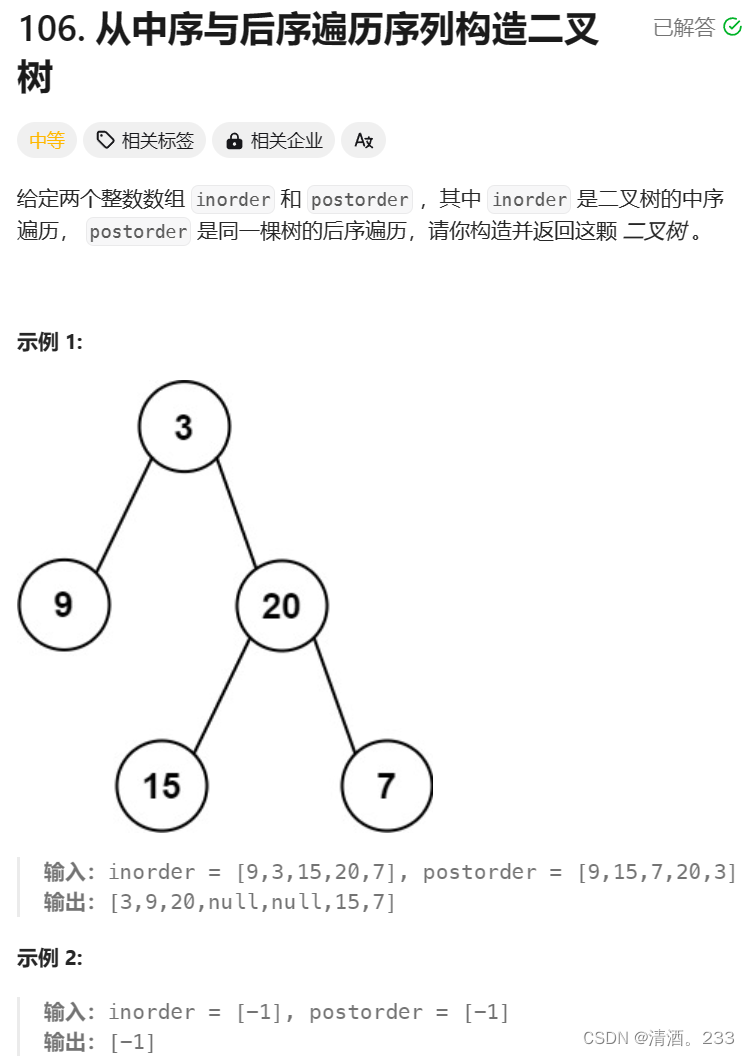
目录
双塔模型
训练
pointwise训练
pairwise训练
listwise训练
双塔模型
矩阵补充模型只用到了用户id和物品id,其余属性没有用上
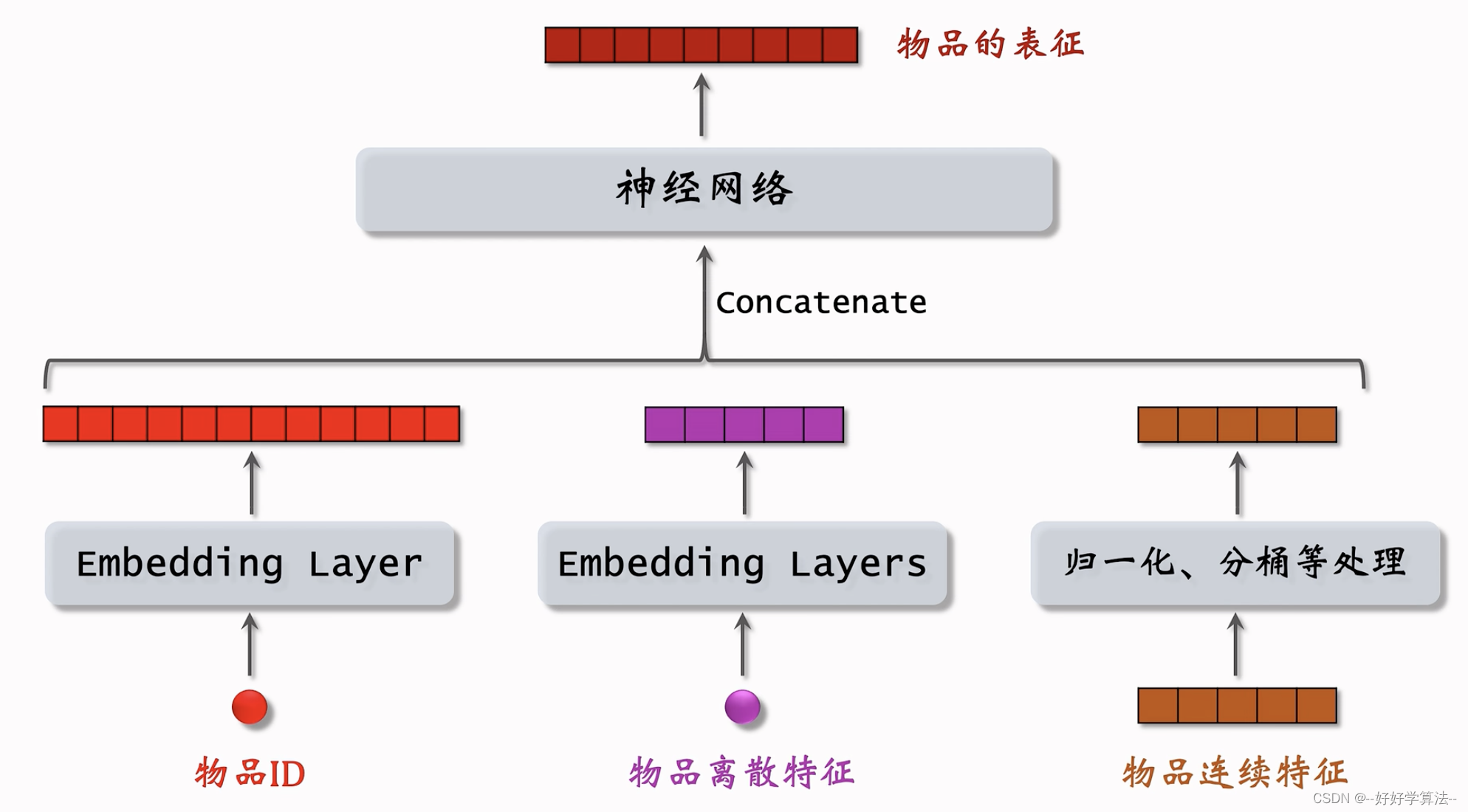
用户属性也可以这样处理
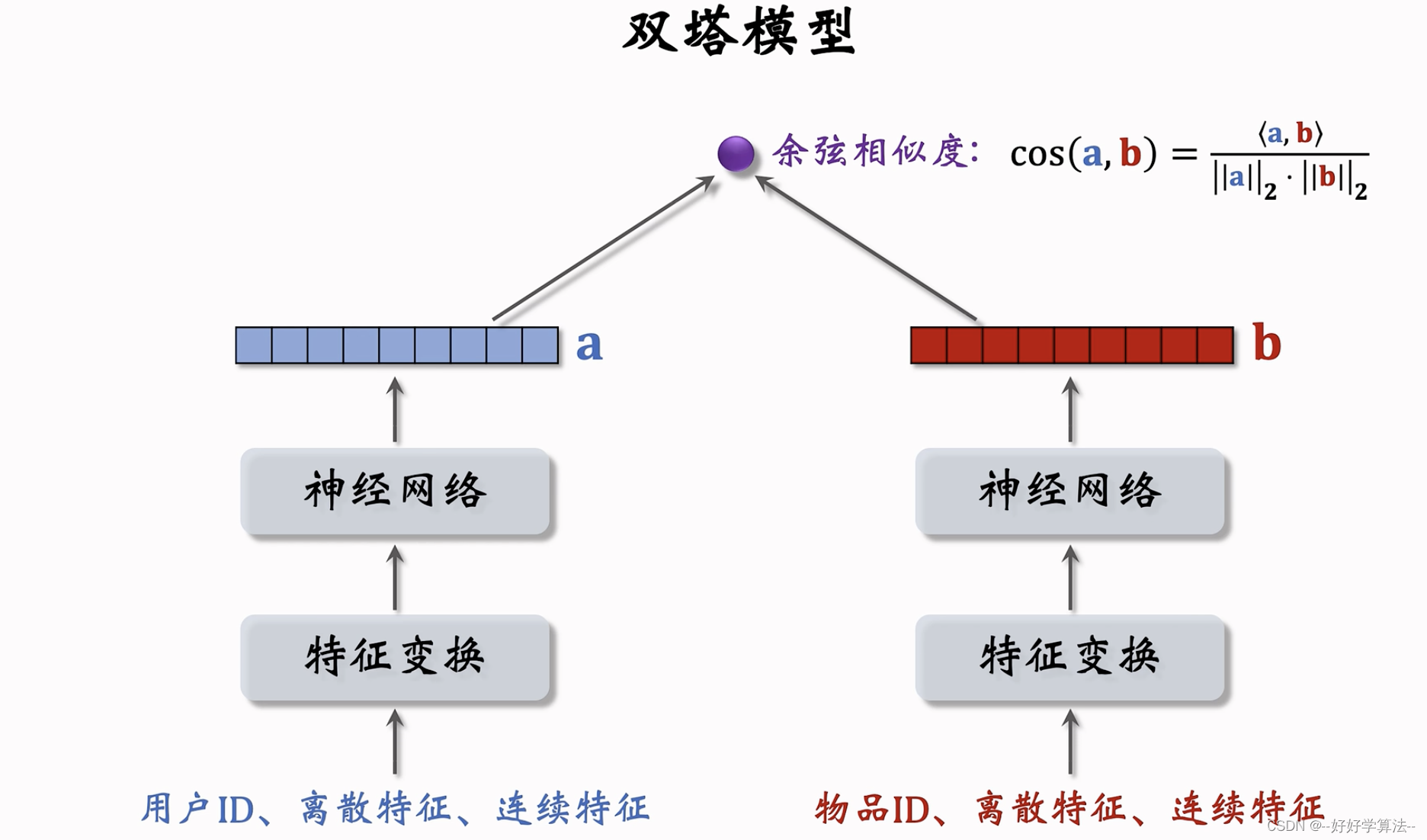
用户塔和物品塔各输出一个向量,两个向量的余弦相似度作为兴趣的预估值
训练
第一种:pointwise,独立看待每个正负样本,做二分类
第二种:pairwise,每次取一个正样本一个负样本
第三种:listwise,每次取一个正样本多个负样本,多分类
正负样本的选择:
正样本:用户点击
负样本:未被召回的,召回但是被粗排精排淘汰的,曝光但是未点击的(具体怎么选择后面会讲)
pointwise训练
把召回看作二元分类任务,鼓励正样本相似度接近1,负样本相似度接近-1
控制正负样本比例1:2,1:3(互联网大厂的经验之言)
pairwise训练
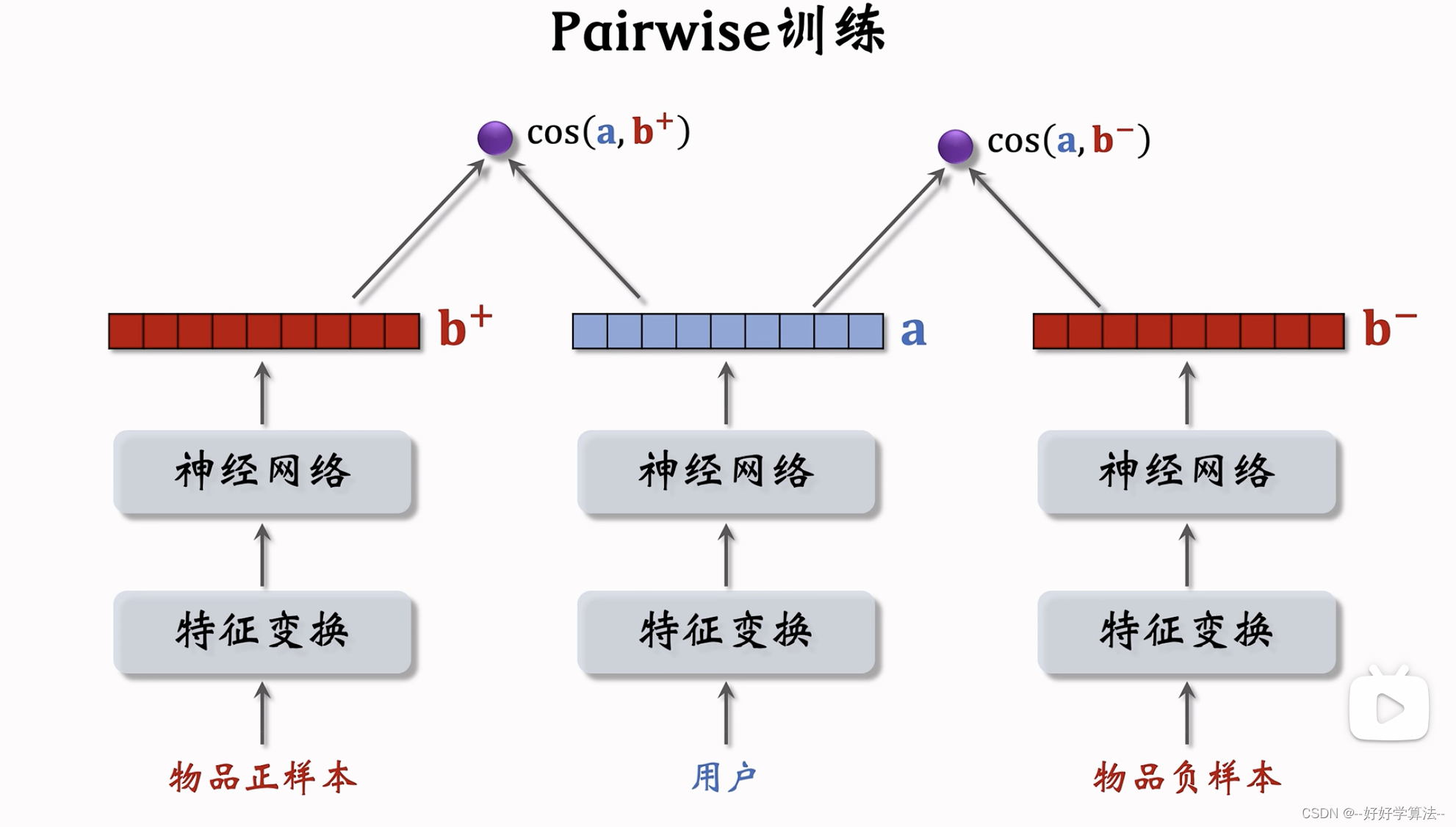
损失:鼓励cos(a,b+)大于cos(a,b-)
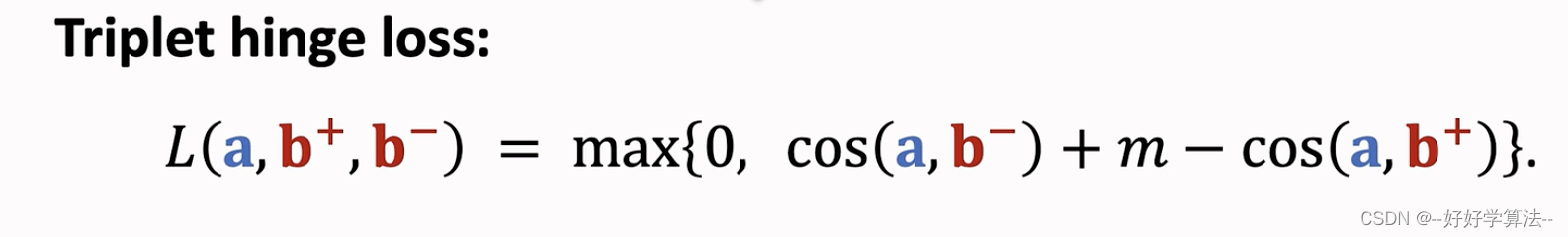

listwise训练

最小化交叉熵
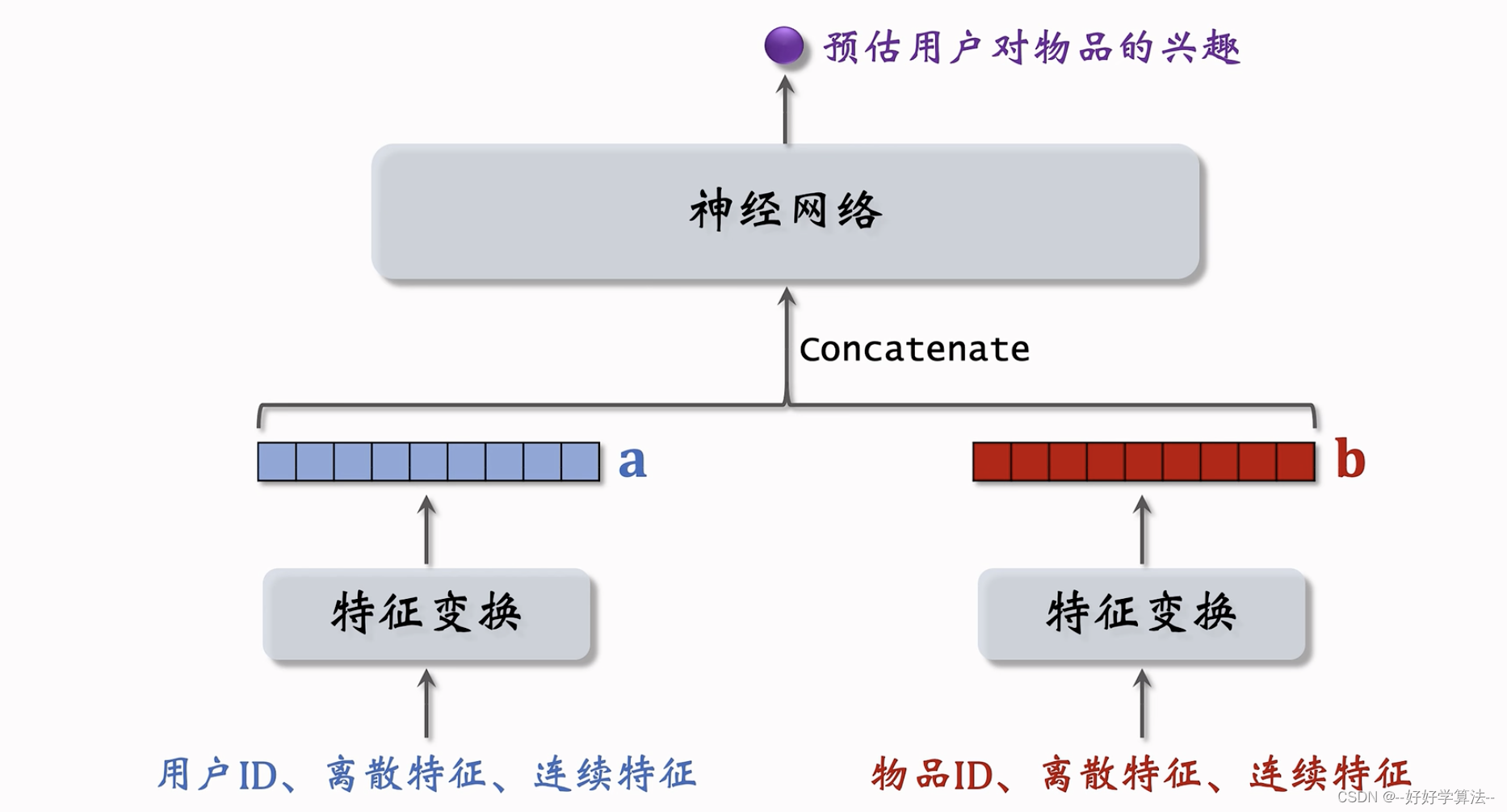
错误设计:下面的模型不用于召回,前期融合(进入神经网络前就融合了),不是双塔模型,可以用作精排和粗排,计算量不会太大,召回只能用后期融合(神经网络之后)的模型
(未完待续)