本文来自社区投稿,作者李剑锋
MMPreTrain 是一款基于 PyTorch 的开源深度学习预训练工具箱,本文将从数据采集到部署,手把手带大家使用 MMPreTrain 算法库训练一个高质量的图像分类模型。
MMPreTrain 项目链接:
https://github.com/open-mmlab/mmpretrain
环境配置
对于MMPreTrain的环境配置我们可以通过官方的教程来实现
首先,我们要创建一个MMPreTrain的虚拟环境并安装Pytorch。安装GPU版本我们可以选择CPU或者GPU进行预测,而安装CPU版本就只能使用CPU进行预测。而我之所以采用下面这个方式是因为有些时候通过官方的这个代码安装GPU版本,但是实际安装的是CPU版本,因此我便在官网选择了pip的方式进行安装。假如CUDA版本比较低的话,也可以到官网查找到对应的下载代码。
#创建并激活环境
conda create --name mmpretrain python=3.8 -y
conda activate mmpretrain
#安装Pytorch
#在GPU平台
conda install pytorch torchvision -c pytorch
#在CPU平台
conda install pytorch torchvision cpuonly -c pytorch
#我所使用的安装GPU版本的方式
#pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118然后我们需要在终端的git下载源码并进行安装。
git clone https://github.com/open-mmlab/mmpretrain.git
cd mmpretrain
pip install -U openmim && mim install -e .假如我们的网络并不支持的话,可以考虑通过登录上MMPreTrain的GitHub官网来直接下载压缩包文件,然后将内容安装到指定位置即可。接下来还是和上面一样进入该文件目录然后在终端输入pip install -U openmim && mim install -e .即可。

我们可以通过下面的代码验证是否已经安装。
python demo/image_demo.py demo/demo.JPEG resnet18_8xb32_in1k --device cpu当我们看到命令行中输出了结果字典,包括 pred_label,pred_score 和 pred_class 三个字段时就代表我们已经成功配置好MMPreTrain的环境了。
数据采集
图像分类任务中,数据集的获取相对容易。我们既可以通过本地采集数据,也可以利用网络上众多的开源数据集。因为分类任务只需要将图片放入对应类别的文件夹中,所以通常我们能获得的数据集都十分庞大且种类繁多。即便是像VOC或YOLO这样的数据集,它们可能不会直接按类别提供图片,但我们仍然可以通过脚本提取。比如,在一个标注有车辆和行人的数据集中,如果我们只需要车辆图片,我们可以编写脚本筛选出仅标注有车辆的图片,并将它们统一转移到一个文件夹里。这样一来,我们就可以轻松创建出一个按类别组织的图像数据集。
在下面的介绍当中,我将主要采用的是开源的数据集来进行测试并训练。一般而言,我们能够在几个渠道获取开源的数据集,包括国外的GitHub、HuggingFace、Kaggle以及国内的的飞浆AI Studio。我常用的平台就是Kaggle和AI studio,因为上面的数据集格式都是能够直接下载并使用的。下面我将下载一个Kaggle上的汽车和单车的图像分类数据集进行测试。具体页面链接为:https://www.kaggle.com/datasets/utkarshsaxenadn/car-vs-bike-classification-dataset
打开该链接后,我们能够查看到该数据集的一些基本信息,包括文件大小,文件内容,以及数据集等信息。我们点击下载按钮并放到MMPreTrain的文件夹里解压即可(我这里就选择把文件下载到MMPreTrain下的data文件夹里,没有的话可以新建一个)。


这样我们的数据集就准备好了。
数据处理
数据集格式
一般来讲,对于分类数据集而言,最重要的处理方式就是删除不相关的图片或者是特征比较不明显的图片来提升准确度。除此之外,还有很重要的一点就是将图片的格式改成适合于模型训练的格式。我们可以在mmpretrain/datasets文件夹里看到几类常见的数据集格式:
-
imagenet.py
-
in1k
-

-
in21k

-
voc.py

-
calthech101.py

-
food101.py
我们可以打开配置文件看到该模型所需要的文件格式:

除此之外也有很多的类型,我们都可以根据config文件来选择适合的数据集格式去制作。
之所以我们要按照dataset里要求的格式去制作的主要原因是为了方便后期调整。当我们按照数据集的要求修改了名称,我们就能够直接进行训练而不需要再修改配置文件来实现了。这样就能够大大加快我们的上手速度以及简化了整体的流程。
修改数据集格式
下面我们可以将解压好的数据集做成最常见的imagenet格式。
首先我们把文件解压后可以达到要给名为archive的文件夹,然后我们可以把里面的Car-Bike-Dataset文件夹复制到data文件夹的最外面,然后删掉archive的相关文件。这样处理完成后就应该显示的是下面的状态。

我们现在得到的是两个包含了所有图片文件的文件夹。那我们现在要模仿imagenet(in1k)的图片格式来进行转换。我们可以不通过手动修改的方式实现,而是设计一套提示词然后输入到大语言模型(比如说ChatGPT)中让其为我们生成脚本。由于我们不需要进行test,所以我们只需要制作val和train文件即可。
提示词如下:
请你作为一名python的脚本专家,辅助我完成接下来的任务:首先我在data/Car-Bike-Dataset该文件夹下有Bike和Car两个子文件夹,里面分别存放了大量的相关照片。现在我希望你能够在data这个文件夹里创建一个名为imagenet的文件夹,然后在里面创建两个个子文件夹train和val,然后在这些子文件夹里再分别创建两个子文件夹Bike和Car。然后按照80%,20%的比例把data/Car-Bike-Dataset/Bike里面的图片和data/Car-Bike-Dataset/Car这里的图片分别放到train和val这两个个文件夹下对应名称的子文件夹内。请一步步的进行思考并给出我完整的最终脚本代码。
下面是ChatGPT所给出的答复:
要完成您的任务,我们将使用Python的标准库来创建文件夹、移动文件,并使用随机分割来按照80%和20%的比例划分数据集。以下是完成这一任务的步骤和相应的Python脚本代码。
首先,我们需要导入必要的模块,并且设置好源文件夹和目标文件夹的路径。
import os
import shutil
from random import shuffle
# 源文件夹路径
source_dataset_dir = 'data/Car-Bike-Dataset'
# 目标文件夹路径
target_dataset_dir = 'data/imagenet'
# 创建目标文件夹及其子文件夹
os.makedirs(os.path.join(target_dataset_dir, 'train', 'Bike'), exist_ok=True)
os.makedirs(os.path.join(target_dataset_dir, 'train', 'Car'), exist_ok=True)
os.makedirs(os.path.join(target_dataset_dir, 'val', 'Bike'), exist_ok=True)
os.makedirs(os.path.join(target_dataset_dir, 'val', 'Car'), exist_ok=True)接下来,我们将定义一个函数来处理文件的分割和移动。函数将遍历源文件夹中的图片,随机打乱,然后按照80%和20%的比例分配到训练和验证文件夹中。
def split_data(source_folder, target_train_folder, target_val_folder, split_size=0.8):
# 获取所有文件的路径
files = [os.path.join(source_folder, f) for f in os.listdir(source_folder) if os.path.isfile(os.path.join(source_folder, f))]
shuffle(files) # 随机打乱文件顺序
# 分割点计算
split_point = int(len(files) * split_size)
# 分配文件到训练集和验证集
train_files = files[:split_point]
val_files = files[split_point:]
# 复制文件到目标文件夹
for f in train_files:
shutil.copy(f, target_train_folder)
for f in val_files:
shutil.copy(f, target_val_folder)最后,我们调用split_data函数,并为Bike和Car两个分类分别进行操作。
# 对Bike和Car文件夹执行数据集分割
split_data(os.path.join(source_dataset_dir, 'Bike'), os.path.join(target_dataset_dir, 'train', 'Bike'), os.path.join(target_dataset_dir, 'val', 'Bike'))
split_data(os.path.join(source_dataset_dir, 'Car'), os.path.join(target_dataset_dir, 'train', 'Car'), os.path.join(target_dataset_dir, 'val', 'Car'))这个脚本将完成以下任务:
-
在
data文件夹下创建imagenet文件夹以及其子文件夹train和val。 -
在
train和val文件夹下各创建Bike和Car子文件夹。 -
从
data/Car-Bike-Dataset/Bike和data/Car-Bike-Dataset/Car中随机选择80%的图片放入train对应子文件夹,剩下的20%放入val对应子文件夹。
我们可以在MMPretrian文件夹下新建一个test.py文件,并把代码都复制进去并下载对应的库,然后在终端运行python test.py这样我们就能够创建出以下的内容:

这样我们就把imagenet(in1k)的格式创建完成了。其他格式的创建方式也可以参考我的提示词进行修改使用。
模型配置及训练
在准备好了imagenet的数据集后,我们就可以去config文件夹里寻找我们想要用来分类的模型。我们可以在GitHub的官网以及中文文档上看到详细的模型库信息

这里我们选择比较常见的res2net模型进行训练。我们可以看到该模型有三个配置文件,其主要区别在于w和s的值,我们可以进入README.md文件中查看模型更加详细的信息。包括Top-1和Top-5的准确率以及参数量等。我们可以根据自己的硬件或者部署环境进行选择。


由于数据量比较小,在这里我们选择一个最小的模型进行测试并训练(即configs/res2net/res2net50-w14-s8_8xb32_in1k.py),假如大家有更大的数据集想要训练效果更好的模型,也可以考虑采用参数量更大且更深的模型。
当我们点击进入该文件后,可以看到以下内容:
_base_ = [ # 此配置文件将继承所有 `_base_` 中的配置
'../_base_/models/res2net50-w14-s8.py', # 模型配置
'../_base_/datasets/imagenet_bs32_pil_resize.py', # 数据配置
'../_base_/schedules/imagenet_bs256.py', # 训练策略配置
'../_base_/default_runtime.py' # 默认运行设置
]
由于我们可能要修改模型,为不影响其他模型的使用,我们可以在MMPreTrain的project文件夹下创建一个新的文件夹Car_Bike_Classification,根据文件地址找到对应文件后,按照以下的格式将文件内容进行保存。

并对以下两个文件里的num_classes进行修改(由于我现在只是Car和Bike二分类,因此修改成2即可)。


当然我们也可以对学习率、损失函数之类超参数进行修改以提升效果。但是由于我们只是测试,现在我们就按照默认的情况来进行运行。

在完成了配置文件的设置后,我们可以到config文件里将文件地址进行修改以确保不会出错。

最后在这一切都修改妥当后,我们可以在终端输入python tools/train.py projects/Car_Bike_Classification/config/res2net50-w14-s8_8xb32_in1k.py即可进行训练。
但是我们一旦运行程序就会发现程序报错了,具体报错内容为:“ValueError: Top-5 accuracy is unavailable since the number of categories is 2. Please check the val_evaluator and test_evaluator fields in your config file.”。这个报错意味着我们二分类问题而言不能用Top-5来计算,只有用Top-1来计算。并且在val_evaluator和test_evaluator里删掉Top-5的内容。那我们就需要到下图的位置把topk=(1,5)改为topk=(1,):


这样我们再次运行python tools/train.py projects/Car_Bike_Classification/config/res2net50-w14-s8_8xb32_in1k.py
当我们看到下面的内容就代表模型正式开始训练了。并且模型的权重文件将保存在work_dirs/res2net50-w14-s8_8xb32_in1k,假如我们要修改保存的地址,就可以在上面的代码中假如“--work-dir xxx”。这里面。这里面还展示了其他的信息,包括eta(预计完成时间)、loss(当前模型的损失值)以及accuracy/top1(模型预测的准确率)。

模型测试
查看运行情况
在模型训练完后,我们可以点开work_dirs/res2net50-w14-s8_8xb32_in1k进入查看内部的文件。在vis_data里的json文件将存放着模型训练过程中的各种信息,而config.py文件里存放的是模型结构文件,.log文件里存放的是完整的训练信息(从开始到结束在终端里显示的信息)。再下面就是所有的训练出来的权重文件(这个模型有100个)。

我们可以通过MMPreTrain里自带的可视化文件来讲模型的准确度以及损失值可视化出来查看模型整体训练的效果。
-
损失值可视化
python tools/analysis_tools/analyze_logs.py plot_curve work_dirs/res2net50-w14-s8_8xb32_in1k/20231107_155535/vis_data/20231107_155535.json --keys loss -
python- 这是启动Python解释器的命令。 -
tools/analysis_tools/analyze_logs.py- 这是用来分析日志文件的Python脚本的路径。 -
plot_curve- 这是analyze_logs.py脚本的一个子命令,用于生成损失或者其他度量的曲线图。 -
work_dirs/res2net50-w14-s8_8xb32_in1k/20231107_155535/vis_data/20231107_155535.json- 这是包含训练日志数据的JSON文件的路径。该文件记录了模型在训练过程中的性能指标,如损失和准确率等。 -
--keys loss- 这是一个命令行参数,指定了要在曲线图中显示的关键字,这里是loss。意味着脚本将会提取日志文件中记录的损失值,并将其绘制成曲线图。但是我们同样可以添加其他比如说准确度的信息。
可以看到损失值在40批次的时候损失值已经在一个比较低的位置了。

-
准确度
python tools/analysis_tools/analyze_logs.py plot_curve work_dirs/res2net50-w14-s8_8xb32_in1k/20231107_155535/vis_data/20231107_155535.json --keys accuracy/top1 可以看到模型准确度在接近30批次的时候发生了一次剧烈的震荡,但是在30批次后就开始稳定在97.5%的准确度上。

总结上面两个数据我们可以看出,模型在40批次的时候已经训练好了,后面继续训练的内容就是过拟合后的内容。过拟合会使得模型专注于训练的数据集而丢失了泛化的能力,因此我们应该要选择的是40批次的权重来作为最终的权重来进行测试。
查看模型效果
我们可以在网上找几张车和单车的照片进行测试(不能使用训练集里的数据测试,因为模型训练学习过这些图片的内容,假如拿这些图片计算得到的结果是不准确的)。下面是找的几张测试的照片,我将其放到了MMPreTrain下的demo文件夹里(例如demo/bike.jfif):



我们可以通过调用demo/image_demo.py这个文件进行测试,具体的代码如下:
#python <脚本位置> image.jpg model_config.py --checkpoint checkpoint.pth --show --device cpu
#单车图片
python demo/image_demo.py demo/bike.jfif work_dirs/res2net50-w14-s8_8xb32_in1k/20231107_155535/vis_data/config.py --checkpoint work_dirs/res2net50-w14-s8_8xb32_in1k/epoch_40.pth --show --device cpu
#汽车图片
python demo/image_demo.py demo/car.jfif work_dirs/res2net50-w14-s8_8xb32_in1k/20231107_155535/vis_data/config.py --checkpoint work_dirs/res2net50-w14-s8_8xb32_in1k/epoch_40.pth --show --device cpu-
python- 这是用来启动Python解释器的命令。 -
demo/image_demo.py- 这是你要运行的Python脚本的路径。这个脚本预计是MMPreTrain库的一部分,用于演示如何使用该库进行图像分类的推断。 -
demo/bike.jfif- 这是输入图像文件的路径,你想要对它进行分类预测。 -
work_dirs/res2net50-w14-s8_8xb32_in1k/20231107_155535/vis_data/config.py- 这是用于初始化模型的配置文件的路径。配置文件包含了模型的结构和其他参数设置。 -
--checkpoint- 这是一个命令行参数,告诉脚本使用特定的权重文件来加载训练好的模型。 -
work_dirs/res2net50-w14-s8_8xb32_in1k/epoch_40.pth- 这是模型权重文件的路径,包含了模型训练过程中学习到的参数。 -
--show- 这个选项告诉脚本在推断完成后显示图像和预测结果。 -
--device cpu- 这个参数指定了推断运行的设备。在这个例子中,它指定了使用CPU来进行推断,如果你有GPU且配置了相应的CUDA环境,通常可以用--device cuda来加速推断过程。
得到的结果为:
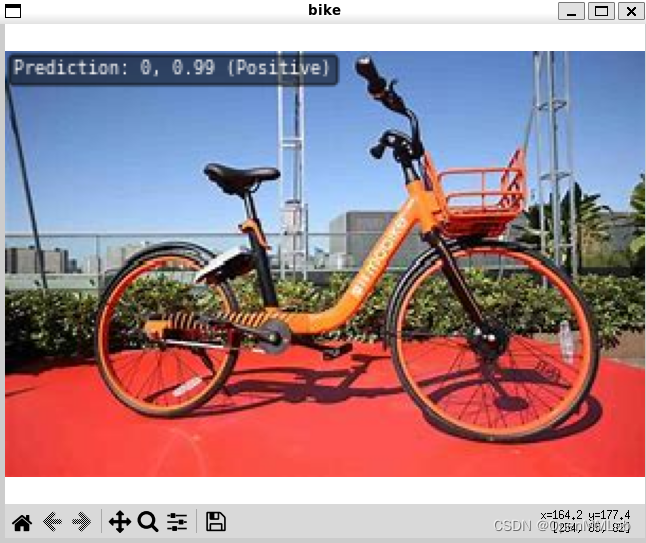


由于我们这里没有设置标签,所以显示的是Positive和Negative。但是可以看出的是Positive代表的是单车,Negative代表的是汽车。并且输入的照片分类都是准确的,所以可以看出MMPreTrain里提供的模型的准确度还是非常高的。
模型转换部署
在确定模型效果符合预期后,我们可以将模型进行部署到本地环境里。这里我们将使用OpenMMLab官方的MMDeploy实现。具体的环境安装以及模型的转换可以查看这篇文章。下面我就直接进入MMDeploy环境开始进行部署的指导。
首先在MMDeploy里创建一个名为project的文件夹,然后新建一个名为Car_Bike_Classification的文件夹,然后把训练好的config文件和checkpoint文件以及一张图片文件放入。

然后我们需要在configs/mmpretrain这个文件夹里找到我们要转换的模型以及对应需要的尺寸。这里我就选择configs/mmpretrain/classification_onnxruntime_dynamic.py转为ONNXRuntime模型并且尺寸并不固定的。接下来我们就需要调用tools/deploy.py里的部署文件在终端进行部署,具体代码如下:
python tools/deploy.py configs/mmpretrain/classification_onnxruntime_dynamic.py project/Car_Bike_Classification/config.py project/Car_Bike_Classification/epoch_40.pth project/Car_Bike_Classification/bike.jfif --work-dir output/Car_Bike_Classification --device cpu --dump-info-
python tools/deploy.py:运行deploy.py脚本,这通常是用于部署工作流的主脚本。 -
configs/mmpretrain/classification_onnxruntime_dynamic.py:指定了部署配置文件的路径,这个配置文件定义了如何将模型转换为ONNXRuntime的动态版本。 -
project/Car_Bike_Classification/config.py:指定了模型的配置文件路径,这个文件包含了模型结构和训练过程中使用的各种参数。 -
project/Car_Bike_Classification/epoch_40.pth:指定了模型权重文件的路径,这是一个训练好的模型检查点文件。 -
project/Car_Bike_Classification/bike.jfif:指定了用于模型转换的图片文件路径,这张图片将用于转换过程中的测试或者量化校准。 -
--work-dir output/Car_Bike_Classification:设置工作目录为output/Car_Bike_Classification,转换的模型和日志将保存在这个目录下。 -
--device cpu:指定转换和测试过程中使用的设备是CPU。建议都安装CPU版本,时间虽然长一点的但是会方便很多。 -
--dump-info:这个参数表示需要导出SDK(软件开发工具包)相关的信息,便于部署到特定的设备或平台上。
完成后我们可以到output里查看结果。

可以看到模型成功被转换了,现在我们就能够直接调用这个SDK包进行预测了(这一整个文件夹,调用的话可以output/Car_Bike_Classification这样进行调用)。
我们可以用官方给的demo模板进行测试(demo/python/image_classification.py):
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import cv2
from mmdeploy_runtime import Classifier
def parse_args():
parser = argparse.ArgumentParser(
description='show how to use sdk python api')
parser.add_argument('device_name', help='name of device, cuda or cpu')
parser.add_argument(
'model_path',
help='path of mmdeploy SDK model dumped by model converter')
parser.add_argument('image_path', help='path of an image')
args = parser.parse_args()
return args
def main():
args = parse_args()
img = cv2.imread(args.image_path)
classifier = Classifier(
model_path=args.model_path, device_name=args.device_name, device_id=0)
result = classifier(img)
for label_id, score in result:
print(label_id, score)
if __name__ == '__main__':
main()在终端调用的代码为:
python demo/python/image_classification.py cpu output/Car_Bike_Classification project/Car_Bike_Classification/bike.jfif可以看到,结果就是分为第一类且有高达99%的准确率。

这样我们就成功完成了模型的部署了,下面我们可以用这个模型任何地方进行本地化运行了。
模型可视化
本地部署Gradio
我们甚至可以用这里面的end2end.onnx文件利用ONNXRuntime和Gradio部署在HuggingFace平台上。之所以没有用MMDeploy的SDK包进行部署的主要原因是在HuggingFace上配置MMDeploy的环境比较困难,需要对Linux非常熟悉,所以我们可以采取利用ONNXRuntime的方式运行。当然在本地部署我们也可以采用MMDeploy的SDK包来实现,但是考虑到要在HuggingFace上部署,还是用ONNXRuntime比较合适。
那么首先我们需要先将代码写下。这部分我们可以靠着大语言模型来帮我们完成,假如遇到Bug让其进行修改即可。我的提示词如下:
你可以作为Gradio的专家,帮我写一个gradio界面吗。现在我有一个分类模型的.onnx文件在本地(文件名为end2end.onnx),该模型分为两类,第一类是单车bike,第二类是汽车car,然后我希望这个gardio界面能够左边是上传图片的,右边展示两类的可能性,然后用一个矩形图展示出来,并且根据判断的结果下面加一个文本框告诉大家说“该图片里是汽车或者单车”。 你写好这个代码,只需要给我留一个传入onnx文件地址的入口即可。清一步步的进行思考,记得详细的考虑Gradio的注意事项,不要添加太多没有意义的东西。
但是一般来说第一次生成的代码都会有一些问题,我们只需要把问题反映给ChatGPT后面让其进行修改后得到下面的最终代码:
import gradio as gr
import onnxruntime as ort
import numpy as np
from PIL import Image
# 替换成你的 ONNX 模型文件路径
ONNX_MODEL_PATH = 'end2end.onnx'
# 加载模型
ort_session = ort.InferenceSession(ONNX_MODEL_PATH)
# 定义预测函数
def classify_image(image):
# 确保image是一个PIL图像对象
if not isinstance(image, Image.Image):
image = Image.fromarray(image)
# 预处理输入图片
image = image.resize((224, 224))
image = np.array(image).astype('float32')
image = np.transpose(image, (2, 0, 1)) # Change data layout from HWC to CHW
image = np.expand_dims(image, axis=0)
# 使用 ONNX 运行推理
inputs = {ort_session.get_inputs()[0].name: image}
outputs = ort_session.run(None, inputs)
# 获取预测结果
predictions = outputs[0]
# 创建一个矩形图展示可能性
pred_probs = predictions[0].tolist() # 假设模型输出是一个概率列表
pred_probs = [float(i)/sum(pred_probs) for i in pred_probs] # 归一化概率值
class_names = ['Bike', 'Car']
result = {class_name: prob for class_name, prob in zip(class_names, pred_probs)}
# 生成结果文本
pred_text = f"该图片里是{'汽车' if np.argmax(predictions) else '单车'}。"
return result, pred_text
# 根据Gradio新的API更新了导入和组件
from gradio import Interface, components
# 创建 Gradio 界面
iface = Interface(
fn=classify_image,
inputs=components.Image(shape=(224, 224)),
outputs=[
components.Label(num_top_classes=2),
components.Textbox(label="分类结果")
],
title="单车与汽车图像分类",
description="上传一张图片,模型将预测图片是单车还是汽车。"
)
# 启动界面
iface.launch(share=True)这个代码只需要我们在本地安装以下几个库便可使用:
pip install gradio onnxruntime numpy Pillow运行后可以显示这样的效果,我们可以上传图片以获得结果。

HuggingFace上部署Gradio
那假如我们不想单单在本地部署,而是希望能够一直分享给别人(本地分享的话只有72h的保留时间),那我们就需要把模型部署在HuggingFace上然后分享出去。
首先我们需要登录到HuggingFace上,并且在右上角找到+ new spaces。

进入后创建自己Space的名字,然后再选择下面的Gradio平台。硬件的话就按默认的就可以,我们都可以免费使用CPU来进行推理,假如要高级一点的硬件的话就需要花费了。最后我们选择公开(Public)或者私有(Private)模型后,就可以点击创建Space(Create Space)了。

然后我们需要点击右上角的Files并把end2end.onnx文件上传到HuggingFace平台上。

然后我们要新建一个文件并把命名为app.py后,将代码复制进去。


然后再新建一个名为requirements.txt的文件,并把需要安装的库放入。

最后我们点击一下右上角的APP,等待一段时间配置环境,我们就能够把模型部署在HuggingFace上了。

我们上传之前的图片看看效果如何。

可以看到模型真的被运行在了云端上了,并且能够基于免费的硬件资源进行长期的部署!大家也可以通过这个链接来进行尝试。