
文章目录
- 前言
- 什么是集群
- 集群模式基本原理
- 哈希求余
- 一致性哈希算法
- 哈希槽分区算法
- docker模拟出一个集群
- 集群中节点挂了会怎么办
- 故障判定
- 故障迁移
- 集群扩容
前言
前面我们学习了 redis 哨兵机制,哨兵机制是为了解决当主节点挂了之后,能够自动进行故障转移的机制,该机制提高了系统的可用性,它并不能帮助 redis 节点存储更多的数据,要想使得我们的 redis 节点能够存储更多的数据,就需要用到集群。
什么是集群
这里集群有两种含义,一种是广义的集群,一种就是狭义的集群。只要你是多个机器构成的分布式系统,都可以称作是一个“集群”,这就是广义的集群,而狭义的集群则是 redis 提供的集群模式,在这个集群模式下主要解决的就是存储空间不足的情况。
Redis集群实现了对Redis的水平扩容,即启动多个Redis节点,将整个数据库分布存储在多个节点中,每个节点存储总数据的一部分。Redis集群将数据分成多个槽(slot),每个节点负责处理其中的一部分槽,通过哈希算法将键分配到不同的槽中,这样可以实现数据的分布式存储和负载均衡。
集群模式基本原理
既然集群模式是将数据分为多个部分,分别存储在多个 redis 节点中的,那么如何将数据分为多个部分呢?redis 是如何实现数据的分片的呢?
哈希求余
哈希求余的思想很简单,我们都知道任何一个数据经过哈希函数的计算都能得到一个整数,当我们插入数据的时候,因为 redis 中 key 是唯一的,所以就将 key 经过哈希函数的计算得到一个整数,然后再针对 redis 主节点的个数进行求余,然后根据这个余数讲数据插入到对应编号的 redis 节点中,这样就简单的实现了数据的分片。
当查询 key 的值的时候,还是首先将 key 经过哈希函数的计算得到一个整数,然后还是将这个整数与 redis 主节点的个数进行去余的操作,根据这个余数和 redis 节点的编号的对应关系就知道这个 key 存储在哪个 redis 节点上了。

通过哈希求余可以很简单的首先数据分片操作,但是这个做法有一个致命的缺点,就是当进行扩容操作,增加 redis 节点的时候,对应的取余的操作数就发生了变化了,对于扩容之前的数据进行查询操作,因为 redis 节点的数量变化了,所以取模之后得到的结果就不一样了,那么在该节点对应编号的 redis 节点上查询该数据就无法得到该 key 的值。
为了解决这个问题,就需要对不应该待在当前节点的数据进行重新分配:

可以发现,当进行扩容操作的时候,大部分的数据都需要进行数据迁移的操作,这是一个很大的工作量。所以为了解决这个问题,又出现了第二种分片的方式 —— 一致性哈希算法。
一致性哈希算法
相较于普通的哈希算法,一致性哈希算法在进行哈希之后当前 key 属于有哪个分片,这个交替出现的情况改为了连续的情况,比如一段数据经过哈希之后的结果是 0 1 2 3,那么这四个数据就分别属于 0、1、2、3 号编号所对应的 redis 节点,而一致性哈希算法将这种交替出现的情况改为了连续出现,一致性哈希算法,会将一个圆分成例如 2^ 32 -1 个哈希槽,当 key 经过哈希函数计算之后,拿这个计算之后的结果去余上 2^ 32 -1,然后按照顺时针或者逆时针去找分片。
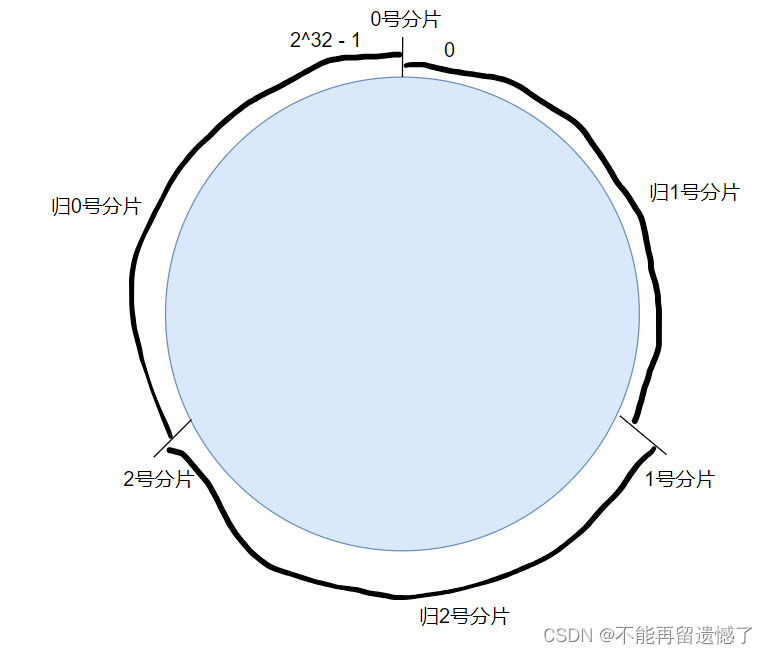
当进行扩容操作新增加 redis 节点之后,通过这个一致性哈希算法进行数据重新分配的时候就只用迁移小部分数据了:
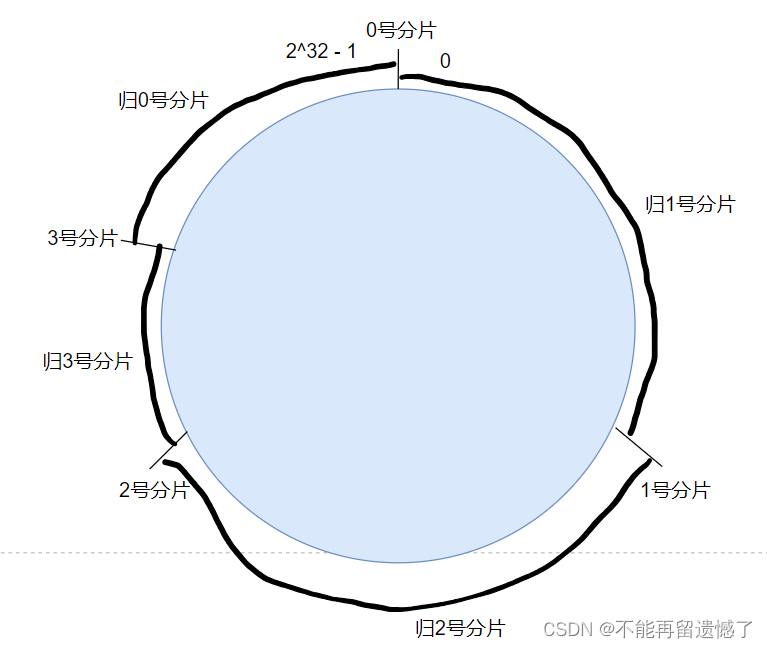
一致性哈希算法虽然解决了普通哈希算法扩容的时候需要重新分配大量数据的问题,但是这样又出现了新的问题,就是出现了可能各个 redis 节点上存储的数据量存在较大差异的情况,这样就导致了数据倾斜的问题,这就导致了某个服务器承受的压力很大而导致挂掉,而有节点中存储的数据太少,干的工作很少的情况。这样有解决方法吗?有的,可以在扩容的时候,一次添加多个 redis 节点,使得新数据在迁移到新的 redis 节点之后各个 redis 节点中存储的数据量基本相同的情况,但是这样做的话又存在不确定性,因为实际工作中可能一次扩容老板不会给你这么多机器。所以为了解决这个问题,又出现了另外一种算法 —— 哈希槽分区算法。
哈希槽分区算法
哈希槽分区算法才是 redis 真正采用的分片算法,这个算法本质上结合了普通哈希求余和一致性哈希算法。该算法会将一致性哈希算法中的哈希槽分配到不同的分片上。
该算法会将哈希槽的个数默认为 16384 个,这个数字是如何来的呢?8 * 2 * 1024,也就是 2kb 的大小,为什么会设置为 2kb 呢?我们都知道判断 redis 节点是否存活的方式是定时向这个 redis 节点发送心跳包,而这个心跳包则是通过网络来传输的,既然是通过网络传输的,就不可避免的需要网络带宽,而网络带宽是网络中最重要也是最贵的资源,所以心跳包的大小越大就需要占用越多的网络带宽,虽然 2 kb 不算大,但是顶不住多了 redis 节点每一段时间都需要这个心跳包,这个 2 kb 大小的槽位是符合现在的业务需求的,所以为了避免占用过多的网络带宽又保证能够满足需求,所以哈希槽分区算法的槽位就设置成了 16384 个。
该算法是如何将槽位分配到不同的分片中的呢?给大家举个例子:
假设有三个分片,可能的分配方式:
- 0号分片:[0, 5461],共 5462 个槽位
- 1号分片:[5462, 10923],共 5462 个槽位
- 2号分片:[10924, 16383],共 5460 个槽位
虽然不能做到绝对平均,但是每个节点所分得的槽位数量是大致相同的,并且每个分片为了区分哪个槽位是属于自己的,使用了位图这样的数据结构来记录。每个分片持有的槽位号可以是不连续的。
如果此时进行了扩容,有四个分片,那么每个分片所持有的槽位就会发生变化:
- 0号分片:[0, 4095],共 4096个槽位
- 1号分片:[5462, 9557],共 4096个槽位
- 2号分片:[10924, 15019],共 4096个槽位
- 3号分片:[4096, 5461] + [9558, 10923] + [15020, 16383]共 4096 个槽位
当进行扩容的时候,只是将每个分片上的槽位分一点给新的分片,这样就减少了大量的重新分配工作。
docker模拟出一个集群
同样,因为我条件有限,只有一个云服务器,而使用虚拟机的话,也需要创建出很多个虚拟机,就很吃主机的内存,所以这里就选择使用 docker 来模拟出来集群模式。
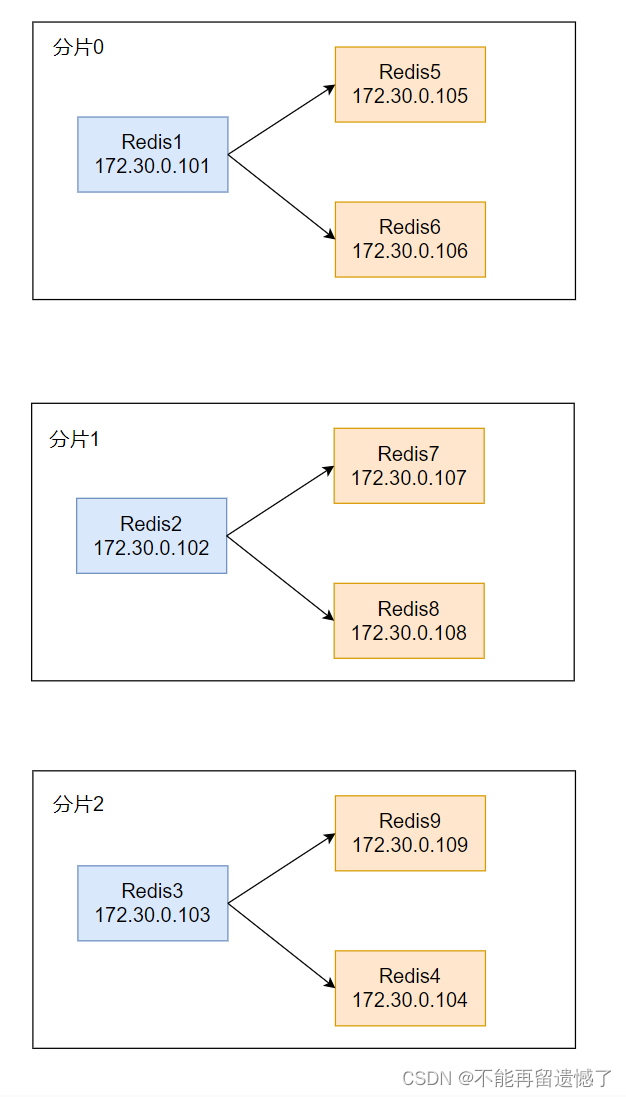
准备模拟出三个分片,也就是三个 redis 主节点,每个主节点有两个从节点,也就是说一共需要创建出 9 个 redis 节点,一个 redis 节点需要一个配置文件,这里一个一个手动创建的话就很麻烦,所以我们选择使用 shell 脚本的方式来创建多个 redis 配置文件。
先创建出下面目录结构的文件:
redis-cluster
├── docker-compose.yml
└── generate.sh
编写 generate.sh 文件中的内容:
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-anounce-port 6379
cluster-announce-bus-poet 16379
EOF
done
- seq 1 9:生成[1,9]之间的数字
- ${}:表示得到执行 {} 中的命令的返回值
- for port in ${seq 1 9};:循环 port 的取值为1-9
- \:续航符,将下面一行的内容将当前一行的内容合并为一行
- do:循环开始的标志,Linux shell 中不是用 {} 来表示循环体
- EOF:文件内容结束的标志
- cat >:将下面的内容重定向到文件中
- done:循环结束的标志
写完 shell 脚本之后,使用 bash .sh 来运行 shell 脚本,运行之后当前目录结构就变成了:
redis-cluster
├── docker-compose.yml
├── generate.sh
├── redis1
│ └── redis.conf
├── redis2
│ └── redis.conf
├── redis3
│ └── redis.conf
├── redis4
│ └── redis.conf
├── redis5
│ └── redis.conf
├── redis6
│ └── redis.conf
├── redis7
│ └── redis.conf
├── redis8
│ └── redis.conf
└── redis9
└── redis.conf
为了展示后面的扩容的情况,我们再创建出两个额外的节点:
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
redis-cluster
├── docker-compose.yml
├── generate.sh
├── redis1
│ └── redis.conf
├── redis10
│ └── redis.conf
├── redis11
│ └── redis.conf
├── redis2
│ └── redis.conf
├── redis3
│ └── redis.conf
├── redis4
│ └── redis.conf
├── redis5
│ └── redis.conf
├── redis6
│ └── redis.conf
├── redis7
│ └── redis.conf
├── redis8
│ └── redis.conf
└── redis9
└── redis.conf
当生成这样的目录结构之后,我们来看看 redis.conf 文件中的详细配置项:
- cluster-enabled yes:表示开启集群模式
- cluster-config-file nodes.conf:在Redis集群中,节点需要知道其他节点的信息以便能够互相通信和协作。这种信息通常保存在一个配置文件中,该选项指定的就是该配置文件的名称
- cluster-node-timeout:集群中的节点之间心跳包响应的超时时间
- cluster-announce-ip:该redis节点所在主机的ip,因为这里使用的是docker容器,所以就写的是对应容器的ip地址
- cluster-announce-port:该redis节点所在主机的端口号
- cluster-announce-bus-port:该redis节点的管理端口
说到管理端口就又不得不说业务端口,业务端口就是负责处理客户端请求的端口,而管理端口是指当前服务如果出现问题的话,就需要对其做出维修管理,这个操作就是由这个端口来完成。
当创建出 redis 的对应配置文件之后,接下来就来创建出 redis 容器:
version: '3.7'
networks:
mynet:
ipam:
config:
- subnet: 172.30.0.0/24
services:
redis1:
image: 'redis:6.0.16'
container_name: redis1
restart: always
volumes:
- ./redis1:/etc/redis/
ports:
- 6371:6379
- 16371:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.101
- networks:为了后续能够创建出静态IP,此时要手动创建出网络,同时给这个网络分配IP
- 172.30.0.0/24:24 表示子网掩码,此处是 24 个比特位中前 24 位为 1,也就是 172.30.0 为网络号
- ipv4_address:这个配置配置的就是静态IP,该配置的网络号需要和前面配置的网段号保持一致
配置的网段不可以和已存在的网段冲突,可以使用 ifconfig 来查看当前主机的网段使用情况。
这里集群中的 redis 节点占用的端口不应该和其他端口冲突,所以我们在配置 redis.conf 和 docker-compose.yml 文件的时候就需要多加注意。
配置完成 docker-compose.yml 文件之后,就可以使用 docker-compose up -d 后台启动容器:
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
249ebfca17fb redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6376->6379/tcp, :::6376->6379/tcp, 0.0.0.0:16376->16379/tcp, :::16376->16379/tcp redis6
eea78107ef2f redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6377->6379/tcp, :::6377->6379/tcp, 0.0.0.0:16377->16379/tcp, :::16377->16379/tcp redis7
864d60bc1fc5 redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 10 seconds 0.0.0.0:6371->6379/tcp, :::6371->6379/tcp, 0.0.0.0:16371->16379/tcp, :::16371->16379/tcp redis1
f35869951ab7 redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 10 seconds 0.0.0.0:6374->6379/tcp, :::6374->6379/tcp, 0.0.0.0:16374->16379/tcp, :::16374->16379/tcp redis4
fe346e709b4d redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6372->6379/tcp, :::6372->6379/tcp, 0.0.0.0:16372->16379/tcp, :::16372->16379/tcp redis2
0e8ddecf23ec redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6378->6379/tcp, :::6378->6379/tcp, 0.0.0.0:16378->16379/tcp, :::16378->16379/tcp redis8
980d6c53a206 redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp, 0.0.0.0:16379->16379/tcp, :::16379->16379/tcp redis9
bdaf777fa66a redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6375->6379/tcp, :::6375->6379/tcp, 0.0.0.0:16375->16379/tcp, :::16375->16379/tcp redis5
34bc5b70a0c3 redis:6.0.16 "docker-entrypoint.s…" 13 seconds ago Up 11 seconds 0.0.0.0:6373->6379/tcp, :::6373->6379/tcp, 0.0.0.0:16373->16379/tcp, :::16373->16379/tcp redis3
redis 容器全部启动成功之后,就可以来搭建集群了,搭建集群需使用 redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2
创建集群的时候需要列出需要搭建集群的 redis 节点的ip和端口。–cluster-relicas 2 表示每个主节点有两个从节点。
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster# redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2
>>> Performing hash slots allocation on 9 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.30.0.105:6379 to 172.30.0.101:6379
Adding replica 172.30.0.106:6379 to 172.30.0.101:6379
Adding replica 172.30.0.107:6379 to 172.30.0.102:6379
Adding replica 172.30.0.108:6379 to 172.30.0.102:6379
Adding replica 172.30.0.109:6379 to 172.30.0.103:6379
Adding replica 172.30.0.104:6379 to 172.30.0.103:6379
M: 7e572aec6621732f1c2079e67694038045e148d9 172.30.0.101:6379
slots:[0-5460] (5461 slots) master
M: ca69a1ec58658f16c5cf7514cfe0004c29c0054c 172.30.0.102:6379
slots:[5461-10922] (5462 slots) master
M: d3b899e31fca22807b12e8f12e552f1ba7469c43 172.30.0.103:6379
slots:[10923-16383] (5461 slots) master
S: df407eb6c61fc10dddbbecc93b85e9e4f5ffd0ed 172.30.0.104:6379
replicates d3b899e31fca22807b12e8f12e552f1ba7469c43
S: 6765977995b4c5cacc8fa83a6f332d00c56ccc3a 172.30.0.105:6379
replicates 7e572aec6621732f1c2079e67694038045e148d9
S: 0489a48c6530d45852afa8a337e234b7d7488835 172.30.0.106:6379
replicates 7e572aec6621732f1c2079e67694038045e148d9
S: e026a0a37eba8db56e77db443a8d7f56f2f268b5 172.30.0.107:6379
replicates ca69a1ec58658f16c5cf7514cfe0004c29c0054c
S: b13fe464da77bd5d313debb0dc6bc68226ad221f 172.30.0.108:6379
replicates ca69a1ec58658f16c5cf7514cfe0004c29c0054c
S: 693d7295247bb56fd27951c46c96c181ce430185 172.30.0.109:6379
replicates d3b899e31fca22807b12e8f12e552f1ba7469c43
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 172.30.0.101:6379)
M: 7e572aec6621732f1c2079e67694038045e148d9 172.30.0.101:6379
slots:[0-5460] (5461 slots) master
2 additional replica(s)
S: 693d7295247bb56fd27951c46c96c181ce430185 172.30.0.109:6379
slots: (0 slots) slave
replicates d3b899e31fca22807b12e8f12e552f1ba7469c43
S: 6765977995b4c5cacc8fa83a6f332d00c56ccc3a 172.30.0.105:6379
slots: (0 slots) slave
replicates 7e572aec6621732f1c2079e67694038045e148d9
M: ca69a1ec58658f16c5cf7514cfe0004c29c0054c 172.30.0.102:6379
slots:[5461-10922] (5462 slots) master
2 additional replica(s)
S: df407eb6c61fc10dddbbecc93b85e9e4f5ffd0ed 172.30.0.104:6379
slots: (0 slots) slave
replicates d3b899e31fca22807b12e8f12e552f1ba7469c43
S: b13fe464da77bd5d313debb0dc6bc68226ad221f 172.30.0.108:6379
slots: (0 slots) slave
replicates ca69a1ec58658f16c5cf7514cfe0004c29c0054c
S: e026a0a37eba8db56e77db443a8d7f56f2f268b5 172.30.0.107:6379
slots: (0 slots) slave
replicates ca69a1ec58658f16c5cf7514cfe0004c29c0054c
S: 0489a48c6530d45852afa8a337e234b7d7488835 172.30.0.106:6379
slots: (0 slots) slave
replicates 7e572aec6621732f1c2079e67694038045e148d9
M: d3b899e31fca22807b12e8f12e552f1ba7469c43 172.30.0.103:6379
slots:[10923-16383] (5461 slots) master
2 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
slots:表示当前主节点分得的槽位
这里的主从关系是如何形成的呢?前面我们在生成 redis.conf 配置文件的时候不是没有指定主从关系吗?这里搭建集群的时候,主从关系是随机形成的,谁是主节点、谁是从节点、谁和谁属于一个分片都是随机的,因为本身从集群的角度来看,提供的这些节点的价值都是等价的。
集群大家成功之后,我们可以进入对应的 redis 客户端来查看集群的信息:
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster# redis-cli -h 172.30.0.101
172.30.0.101:6379> cluster nodes
693d7295247bb56fd27951c46c96c181ce430185 172.30.0.109:6379@16379 slave d3b899e31fca22807b12e8f12e552f1ba7469c43 0 1715223551000 3 connected
6765977995b4c5cacc8fa83a6f332d00c56ccc3a 172.30.0.105:6379@16379 slave 7e572aec6621732f1c2079e67694038045e148d9 0 1715223551000 1 connected
ca69a1ec58658f16c5cf7514cfe0004c29c0054c 172.30.0.102:6379@16379 master - 0 1715223552109 2 connected 5461-10922
df407eb6c61fc10dddbbecc93b85e9e4f5ffd0ed 172.30.0.104:6379@16379 slave d3b899e31fca22807b12e8f12e552f1ba7469c43 0 1715223551107 3 connected
b13fe464da77bd5d313debb0dc6bc68226ad221f 172.30.0.108:6379@16379 slave ca69a1ec58658f16c5cf7514cfe0004c29c0054c 0 1715223551000 2 connected
e026a0a37eba8db56e77db443a8d7f56f2f268b5 172.30.0.107:6379@16379 slave ca69a1ec58658f16c5cf7514cfe0004c29c0054c 0 1715223552008 2 connected
0489a48c6530d45852afa8a337e234b7d7488835 172.30.0.106:6379@16379 slave 7e572aec6621732f1c2079e67694038045e148d9 0 1715223550607 1 connected
7e572aec6621732f1c2079e67694038045e148d9 172.30.0.101:6379@16379 myself,master - 0 1715223551000 1 connected 0-5460
d3b899e31fca22807b12e8f12e552f1ba7469c43 172.30.0.103:6379@16379 master - 0 1715223552000 3 connected 10923-16383
我们在进入 redis 客户端的时候,可以使用 -p 选项指定本机端口来进入,这里的端口就是我们前面 docker-compose.yml 文件中设置的端口映射,也可以使用 -h 选项指定 ip 和端口号来进入对应的 redis 客户端。
然后我们来测试一下集群功能:
172.30.0.101:6379> set key1 111
(error) MOVED 9189 172.30.0.102:6379
这里报了 error 错误是为什么呢?这是因为 key1 经过哈希计算然后求余之后得到的结果对应的不是当前我们进入的这个 101 redis 主机,那么这是否意味着,我们只能进入到对应的客户端才能进行相关槽操作呢?不必这么麻烦,我们只需要在进入客户端的时候加上 -c 选项就可以了:
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster# redis-cli -h 172.30.0.101 -c
172.30.0.101:6379> set key1 111
-> Redirected to slot [9189] located at 172.30.0.102:6379
OK
172.30.0.102:6379>
当在进入客户端的时候加上 -c 选项的时候,就算操作的 key 不在当前分片上,这个集群也会自动转换到 key 所在的分片的客户端然后在这个客户端上执行该操作。可以看到,当我们创建 key 的时候,发现 key1 经过哈希然后求余的操作之后,所在的槽位在 9189 这个槽位上,该槽位属于 102 分片上,所以就会自动进入到 102 redis 主机上,然后执行该操作。
101、102和103 的角色都是主节点,那么我们是否能在从节点上设置 key 呢?
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster# redis-cli -h 172.30.0.104 -c
172.30.0.104:6379> set key2 222
-> Redirected to slot [4998] located at 172.30.0.101:6379
OK
可以看到,就算我们在从节点的客户端上进行 set 操作,他不会报错,而是会自动转换到对应的主节点上然后执行该操作。
在集群中之前学习的 redis 的命令基本上都可以使用,但是还是有例外:
172.30.0.101:6379> mset key3 333 key4 444
(error) CROSSSLOT Keys in request don't hash to the same slot
当我们进行 mset 和 mget 等一次设置或者查询多个 key 的操作的时候,之后这多个 key 经过哈希计算然后求余之后属于同一个分片的时候才可以执行成功,否则就执行失败。
集群中节点挂了会怎么办
上面为大家演示了设置和查询 key 的操作,那么如果集群中国如果有节点挂了该怎么办呢?挂了的情况分两张:从节点挂了和主节点挂了,从节点挂了影响不大,集群还可以正常工作,而如果是主节点挂了,那么集群就会进行故障转移操作:
我们把 redis1 这个主节点容器给手动停止:
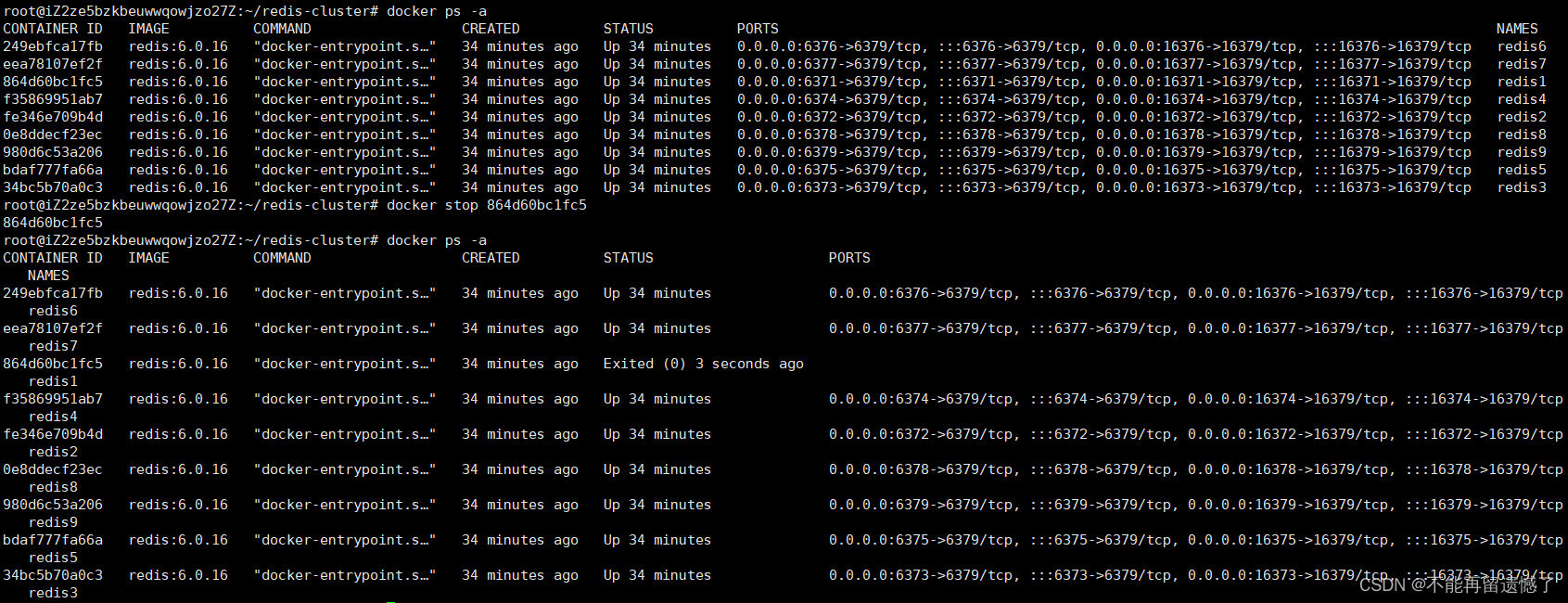
然后进入集群中的某一个客户端查看当前集群的信息:
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster# redis-cli -h 172.30.0.102 -c
172.30.0.102:6379> cluster nodes
ca69a1ec58658f16c5cf7514cfe0004c29c0054c 172.30.0.102:6379@16379 myself,master - 0 1715225034000 2 connected 5461-10922
e026a0a37eba8db56e77db443a8d7f56f2f268b5 172.30.0.107:6379@16379 slave ca69a1ec58658f16c5cf7514cfe0004c29c0054c 0 1715225033000 2 connected
693d7295247bb56fd27951c46c96c181ce430185 172.30.0.109:6379@16379 slave d3b899e31fca22807b12e8f12e552f1ba7469c43 0 1715225034500 3 connected
7e572aec6621732f1c2079e67694038045e148d9 172.30.0.101:6379@16379 master,fail - 1715224900105 1715224897600 1 connected
df407eb6c61fc10dddbbecc93b85e9e4f5ffd0ed 172.30.0.104:6379@16379 slave d3b899e31fca22807b12e8f12e552f1ba7469c43 0 1715225034600 3 connected
b13fe464da77bd5d313debb0dc6bc68226ad221f 172.30.0.108:6379@16379 slave ca69a1ec58658f16c5cf7514cfe0004c29c0054c 0 1715225034000 2 connected
d3b899e31fca22807b12e8f12e552f1ba7469c43 172.30.0.103:6379@16379 master - 0 1715225033000 3 connected 10923-16383
0489a48c6530d45852afa8a337e234b7d7488835 172.30.0.106:6379@16379 slave 6765977995b4c5cacc8fa83a6f332d00c56ccc3a 0 1715225033999 10 connected
6765977995b4c5cacc8fa83a6f332d00c56ccc3a 172.30.0.105:6379@16379 master - 0 1715225033000 10 connected 0-5460
redis1 这里标记的是 fail,也就表示该节点是挂掉了,再看可以发现,之前属于 redis1 分片的从节点 redis5 的身份变成了 master,也就是 redis5 节点由从节点的身份变成了主节点的身份。
再将这个 redis1 节点启动起来,该节点也不会重新恢复为主节点的身份,而是会成为 redis5 节点的从节点:
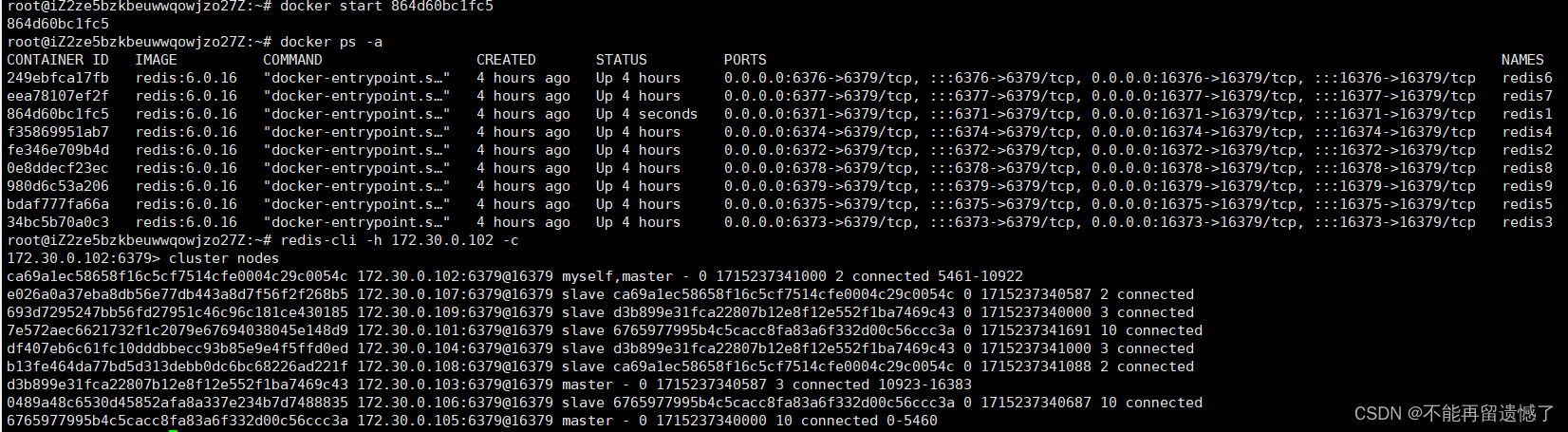
那么 redis 集群的这个故障转移是如何实现的呢?
故障判定
首先就是这个集群是如何发现某个主节点挂了呢?
- 在集群的节点中,节点 A 会给节点 B 发送一个 ping 包,B 接收到这个 ping 包之后就会向 A 返回一个 pong 包,ping 和 pong 除了 message type 属性之外,其他部分是一样的,这里包含了集群的配置信息(该节点的id,该节点从属于哪个分片,是主节点还是从节点,从属于哪个主节点,持有哪些slots位图)
- 每个节点,每秒中国,都会给一些随机的节点发送 ping 包,而不是全部节点都发一遍,这样设定是避免在节点很多的时候,心跳包也非常多(比如如果有9个节点,集群中每秒就会有 9 * 8 72个心跳包在进行网络传输了,而且这是按照N^2这样的级别增长的)
- 当节点 A 向节点 B 发送 ping 包之后,节点 B 不能按时返回 pong 包的话,节点 A 就会重置和节点 B 的 tcp 连接,看能否连接成功,如果连接失败,那么 A 就会把 B 的状态设置为 PFAIL(相当于主管下线)
- A 判定 B 为 PFAIL 之后,会通过 redis 内置的 Gossip 协议,和其他节点进行沟通,向其他节点确认 B 的状态(每个节点都会维护自己的“下线列表”,由于视角不同,所以每个节点的下线列表可能也不同)
- 此时 A 发现其他很多节点也认为 B 节点为 PFAIL 状态,并且数目超过集群节点的一半,那么 A 就会把 B 节点的状态设置为 FAIL(客观下线),并且把这个消息同步给其他节点,其他节点收到这个消息之后也会把 B 的状态设置为 FAIL
故障迁移
如果 B 节点是从节点,那么就不需要进行故障转移,但是如果 B 节点是主节点的话,那么就会由 B 的从节点 C 或者 D 来触发故障转移了。
- 从节点会先判断自己是否具有参选资格,如果当前从节点太久没有和自己的主节点进行通信了(也就是此从节点和主节点之间的数据同步差异太大了),时间超过阈值,就会失去竞选资格
- 具有资格的节点,比如 C 和 D,就会先休眠一定的时间。休眠时间 = 500ms 基础时间 + [0, 500ms]随机时间 + 排名 * 1000ms。offset 的值越大,排名越靠前,休眠时间就越短,意思就是从节点和主节点的同步程度越高休眠时间越短
- 如果某一个节点的休眠时间到了,那么该节点就会给集群中的其他节点进行通信,进行拉票操作,但是只有主节点才具有投票资格
- 主节点就会决定是否把票投给该节点,每个主节点只有一票,当该节点收到的票数超过主节点数目的一半的时候,该节点就会晋升为主节点(该节点会自己执行 slaveof no one的操作,然后剩下的从节点就会执行 slaveof 该节点的操作)
- 同时该节点会把自己成为主节点的信息同步给集群中的其他节点,大家也就会更新自己保存的集群的结构信息
一般情况下,哪个节点的休眠时间短,那么该节点很大概率就是新的主节点了,而且这个主节点是谁并不重要,重要的是需要选出来一个主节点。这里选出新的主节点的过程跟前面的哨兵选出新的主节点不同,哨兵机制是先在哨兵节点中选出一个 leader,然后由这个 leader 来选出主节点,集群中选出主节点的方式则是从节点自己拉票。
以上是集群能够正常进行故障转移的问题,一下几种情况集群可能无法完成故障转移,而导致集群出现宕机:
- 某个分片,所有的主节点和从节点都挂了
- 某个分片,主节点挂了,但是该主节点没有从节点
- 超过半数的master都挂了
第一种情况和第二种情况其实属于一种情况,就是某一个分片中的所有节点都挂了,那么该分片中的所有数据都无法进行增加和查询了,那么就可能会认为这个集群出现了问题,超过半数的 master 都挂了,很可能是因为比较严重的问题。
集群扩容
前面我们使用 3 个分片,每个分片中一个主节点,两个分分节点构成了一个集群,那么接下来我们再向该集群中添加进来两个节点,实现集群的扩容:

启动完成两个新的 redis 节点之后,使用 redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:79 来将新节点添加进去集群中,172.3.0.110:79 是需要添加的节点的 ip 地址和端口号,172.30.0.101:79 是要添加进去的所在集群其中一个节点的 ip 地址和端口号。
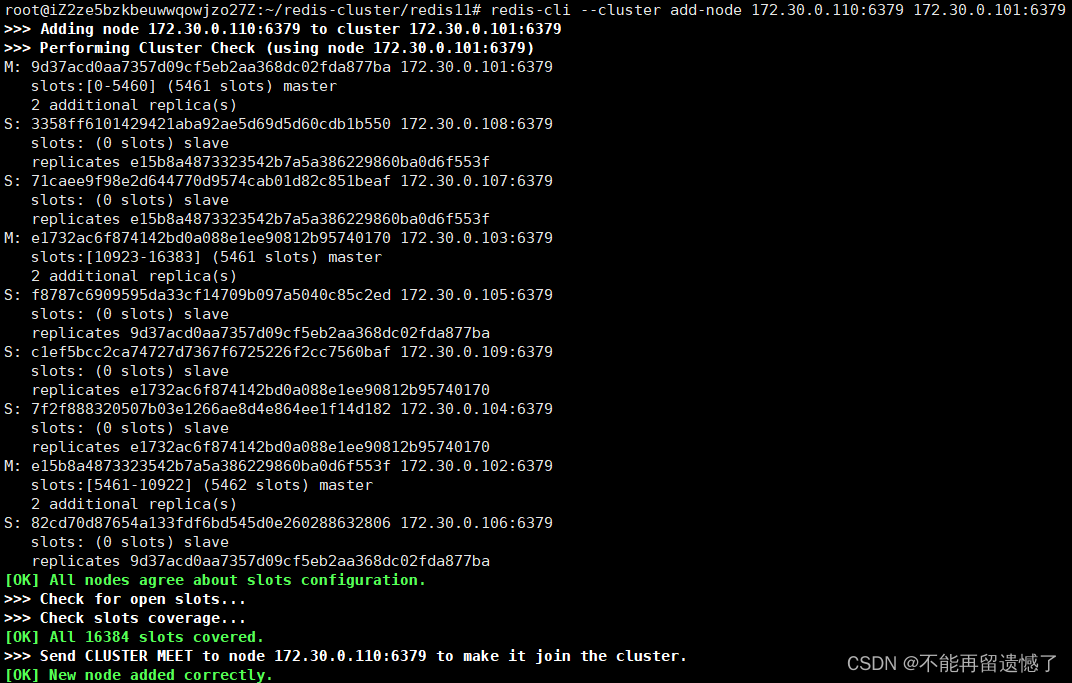
添加完成之后,我们进入任意一个该集群中的客户端,然后查看集群信息:

虽然 redis10 这个节点成功加入集群中了,并且身份是 master,但是仔细观察可以发现:该主节点没有分配槽点,要想新添加的节点可以分配操作,还需要进行重新分配操作的操作:
redis-cli --cluster reshard 172.30.0.101:6379 后面的 ip 地址和端口号是集群中任何一个节点的 ip 和端口号:
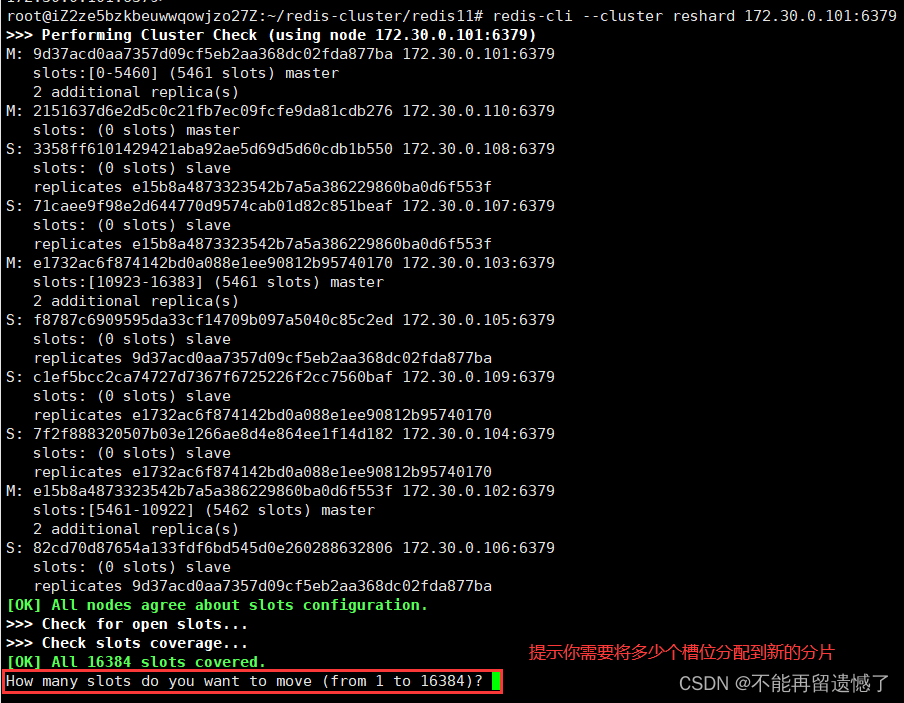
这里因为是四个分片,所以每个分片的槽位大致就为 16384 / 4 = 4096个:
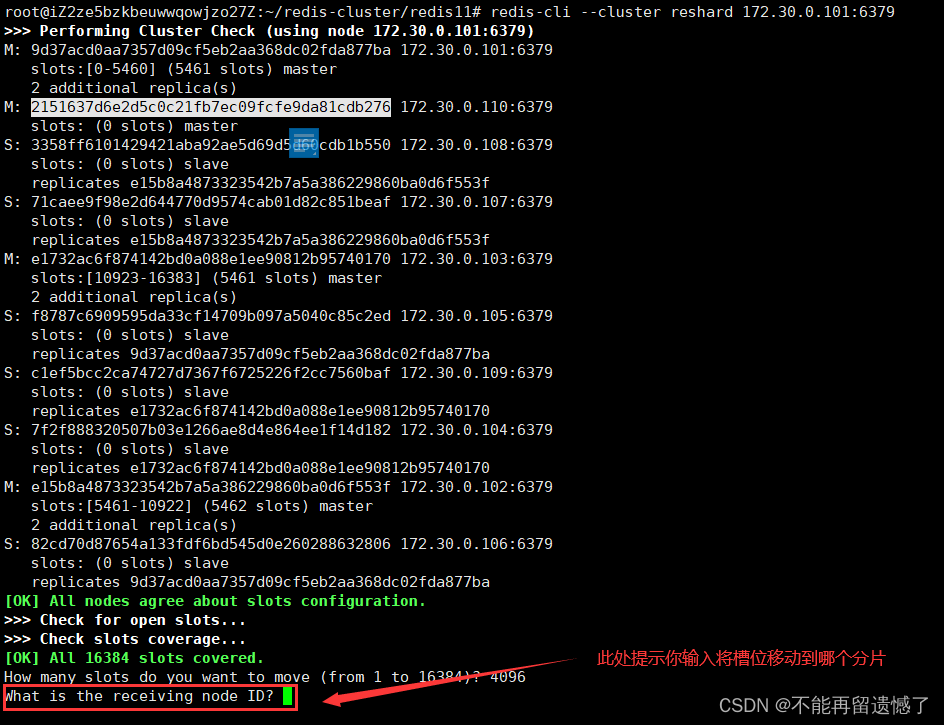
输入 redis10 节点的 id:

输入从哪里哪些节点来移动槽点:
- all:表示从其他每个持有操槽点的节点分来一点槽点
- 手动指定:从某一个或者多个节点分来槽点
我们这里选择 all:
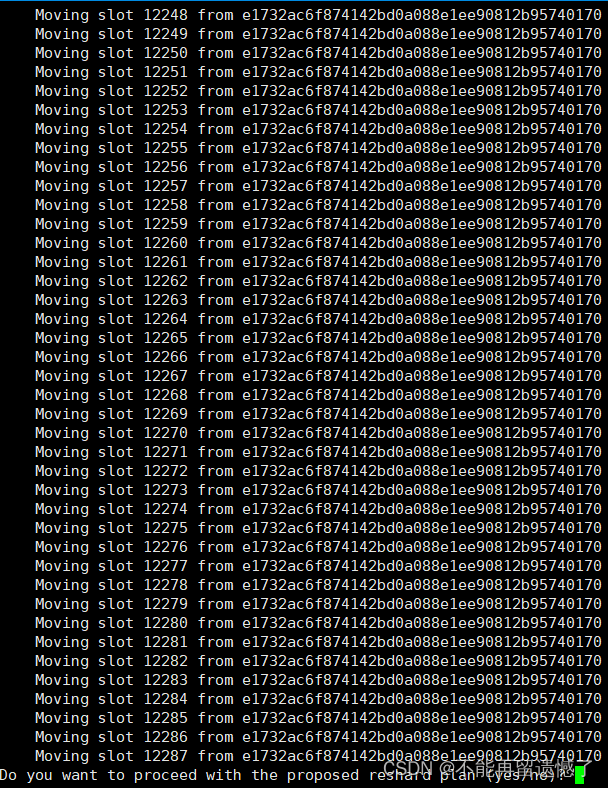
输入 all 之后,会将槽位将要移动的过程显示出来(这里还没有开始移动),输入 yes 之后才开始移动。
完成移动之后,我们再进入集群中某个节点的客户端,然后查看集群信息:

可以看到新加入的节点从其他的分片中获取到了槽位,所以这时才真正完成了集群的扩容操作。
在搬运 槽位/key 的过程中是否可以进行查询操作呢?
如果这个 key 没有发生搬运,或者已经搬运完成之后,是可以成功查询到的,但是如果该 key 正在搬运的话,就会出现问题。
然后我们再将 redis11 添加到 redis10 这个分片中:
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id 2151637d6e2d5c0c21fb7ec09fcfe9da81cdb276
–cluster-master-id 就是该节点需要加入集群的分片中主节点的 nodeId。
添加完成之后,再查看集群信息:
root@iZ2ze5bzkbeuwwqowjzo27Z:~/redis-cluster/redis11# redis-cli -h 172.30.0.101
172.30.0.101:6379> cluster nodes
2151637d6e2d5c0c21fb7ec09fcfe9da81cdb276 172.30.0.110:6379@16379 master - 0 1715243382093 10 connected 0-1364 5461-6826 10923-12287
3358ff6101429421aba92ae5d69d5d60cdb1b550 172.30.0.108:6379@16379 slave 2151637d6e2d5c0c21fb7ec09fcfe9da81cdb276 0 1715243382000 10 connected
71caee9f98e2d644770d9574cab01d82c851beaf 172.30.0.107:6379@16379 slave e15b8a4873323542b7a5a386229860ba0d6f553f 0 1715243383596 2 connected
e1732ac6f874142bd0a088e1ee90812b95740170 172.30.0.103:6379@16379 master - 0 1715243383000 3 connected 12288-16383
f8787c6909595da33cf14709b097a5040c85c2ed 172.30.0.105:6379@16379 slave 9d37acd0aa7357d09cf5eb2aa368dc02fda877ba 0 1715243383596 1 connected
c1ef5bcc2ca74727d7367f6725226f2cc7560baf 172.30.0.109:6379@16379 slave e1732ac6f874142bd0a088e1ee90812b95740170 0 1715243382000 3 connected
9d37acd0aa7357d09cf5eb2aa368dc02fda877ba 172.30.0.101:6379@16379 myself,master - 0 1715243382000 1 connected 1365-5460
7f2f888320507b03e1266ae8d4e864ee1f14d182 172.30.0.104:6379@16379 slave e1732ac6f874142bd0a088e1ee90812b95740170 0 1715243382000 3 connected
e15b8a4873323542b7a5a386229860ba0d6f553f 172.30.0.102:6379@16379 master - 0 1715243383596 2 connected 6827-10922
9cdaf7b88d7b8655cbf63bf83f97f45fb8151480 172.30.0.111:6379@16379 slave 2151637d6e2d5c0c21fb7ec09fcfe9da81cdb276 0 1715243383096 10 connected
82cd70d87654a133fdf6bd545d0e260288632806 172.30.0.106:6379@16379 slave 9d37acd0aa7357d09cf5eb2aa368dc02fda877ba 0 1715243382000 1 connected
从节点添加成功。

![[2024-06]-[大模型]-[DEBUG]- ollama webui 11434 connection refused](https://img-blog.csdnimg.cn/direct/b3e2eea302d64b04a52afde4f26d32c2.png)




![[论文阅读] (33)NDSS2024 Summer系统安全和恶意代码分析方向相关论文汇总](https://img-blog.csdnimg.cn/direct/f615cf28f3084158957e6d5f6e0d1384.png#pic_center)

