Boosting方法的基本元素与基本流程💫

在Boosting集成算法当中,我们逐一建立多个弱评估器(基本是决策树),并且下一个弱评估器的建立方式依赖于上一个弱评估器的评估结果,最终综合多个弱评估器的结果进行输出。
这个过程相当于有意地加重“难以被分类正确的样本”的权重,同时降低“容易被分类正确的样本”的权重,而将后续要建立的弱评估器的注意力引导到难以被分类正确的样本上。
不同的Boosting算法之间的核心区别就在于上一个弱评估器的结果具体如何影响下一个弱评估器的建立过程。此外,Boosting算法在结果输出方面表现得十分多样。早期的Boosting算法的输出一般是最后一个弱评估器的输出,当代Boosting算法的输出都会考虑整个集成模型中全部的弱评估器。一般来说,每个Boosting算法会其以独特的规则自定义集成输出的具体形式。
💥由此,我们可以确立任意boosting算法的三大基本元素以及boosting算法自适应建模的基本流程:
- 损失函数L(x,y) :用以衡量模型预测结果与真实结果的差异
- 弱评估器f(x) :(一般为)决策树,不同的boosting算法使用不同的建树过程
- 综合集成结果H(x):即集成算法具体如何输出集成结果
几乎所有boosting算法的原理都围绕这三大元素构建。在此三大要素基础上,所有boosting算法都遵循以下流程进行建模:

💢正如之前所言,Boosting算法之间的不同之处就在于使用不同的方式来影响后续评估器的构建。无论boosting算法表现出复杂或简单的流程,其核心思想一定是围绕上面这个流程不变的。
梯度提升树GBDT的基本思想

梯度提升树(Gradient Boosting Decision Tree,GBDT)是提升法中的代表性算法,它即是当代强力的XGBoost、LGBM等算法的基石,也是工业界应用最多、在实际场景中表现最稳定的机器学习算法之一。在最初被提出来时,GBDT被写作梯度提升机器(Gradient Boosting Machine,GBM),它融合了Bagging与Boosting的思想、扬长避短,可以接受各类弱评估器作为输入,在后来弱评估器基本被定义为决策树后,才慢慢改名叫做梯度提升树。
作为一个Boosting算法,GBDT中自然也包含Boosting三要素,并且也遵循boosting算法的基本流程进行建模,不过需要注意的是,GBDT在整体建树过程中有几个关键点:
- 弱评估器💯
- GBDT的弱评估器输出类型不再与整体集成算法输出类型一致。对于基础的Bagging和Boosting算法来说,当集成算法执行的是回归任务时,弱评估器也是回归器,当集成算法执行分类任务时,弱评估器也是分类器。但对于GBDT而言,无论GBDT整体在执行回归/分类/排序任务,弱评估器一定是回归器。GBDT通过sigmoid或softmax函数输出具体的分类结果,但实际弱评估器一定是回归器。
- 损失函数💯
-
在GBDT算法中,可以选择的损失函数非常多(‘deviance’, ‘exponential’),是因为这个算法从数学原理上做了改进——损失函数的范围不在局限于固定或者单一的某个损失函数,而是推广到了任意可微的函数。
-
GBDT分类器损失函数:‘deviance’, ‘exponential’
GBDT回归器损失函数:‘squared_error’, ‘absolute_error’, ‘huber’, ‘quantile’ - 拟合残差💯
GBDT依然自适应调整弱评估器的构建,但不再通过调整数据分布来间接影响后续弱评估器,而是通过修改后续弱评估器的拟合目标来直接影响后续弱评估器的结构。
具体地来说,在GBDT当中,我们不修改样本权重,但每次用于建立弱评估器的是样本以及当下集成输出与真实标签的差异()。这个差异在数学上被称之为残差(Residual),因此GBDT不修改样本权重,而是通过拟合残差来影响后续弱评估器结构。
GBDT加入了随机森林中随机抽样的思想,在每次建树之前,允许对样本和特征进行抽样来增大弱评估器之间的独立性(也因此可以有袋外数据集)。虽然Boosting算法不会大规模地依赖于类似于Bagging的方式来降低方差,但由于Boosting算法的输出结果是弱评估器结果的加权求和,因此Boosting原则上也可以获得由“平均”带来的小方差红利。当弱评估器表现不太稳定时,采用与随机森林相似的方式可以进一步增加Boosting算法的稳定性
梯度提升树GBDT的快速实现

sklearn当中集成了GBDT分类与GBDT回归,我们使用如下两个类来调用它们:
- class
sklearn.ensemble.GradientBoostingClassifier - class
sklearn.ensemble.GradientBoostingRegressor -
GBDT算法的超参数看起来很多,但是仔细观察的话,你会发现GBDT回归器与GBDT分类器的超参数高度一致。并且所有超参数都给出了默认值,需要人为输入的参数为0。所以,就算是不了解参数的含义,我们依然可以直接使用sklearn库来调用GBDT算法。
使用GBDT完成分类任务
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.ensemble import GradientBoostingClassifier as GBC
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
X,y = load_wine(return_X_y=True,as_frame=True)
# 切分训练集和测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=0)
# 使用GBDT完成对红酒数据集的预测
clf = GBC() #实例化GBDT分类器,并使用默认参数
clf = clf.fit(Xtrain,Ytrain)
train_score = clf.score(Xtrain,Ytrain)
test_score = clf.score(Xtest,Ytest)
print(f"GBDT在训练集上的预测准确率为{train_score}")
print(f"GBDT在测试集上的预测准确率为{test_score}")- GBDT在训练集上的预测准确率为1.0
- GBDT在测试集上的预测准确率为0.9629629629629629
梯度提升分类与其他算法的对比
dtc = DTC(random_state=0) #实例化单棵决策树
dtc = dtc.fit(Xtrain,Ytrain)
score_dtc = dtc.score(Xtest,Ytest)
rfc = RFC(random_state=0) #实例化随机森林
rfc = rfc.fit(Xtrain,Ytrain)
score_rfc = rfc.score(Xtest,Ytest)
gbc = GBC(random_state=0) #实例化GBDT
gbc = gbc.fit(Xtrain,Ytrain)
score_gbc = gbc.score(Xtest,Ytest)
# 默认使用准确度(accuracy)作为评分方式,即预测正确的样本数占总样本数的比例
print("决策树:{}".format(score_dtc))
print("随机森林:{}".format(score_rfc))
print("GBDT:{}".format(score_gbc))- 决策树:0.9444444444444444
- 随机森林:0.9814814814814815
- GBDT:0.9629629629629629
💥画出决策树、随机森林和GBDT在十组五折交叉验证下的效果对比
score_dtc = []
score_rfc = []
score_gbc = []
for i in range(10):
dtc = DTC()
cv1 = cross_val_score(dtc,X,y,cv=5)
score_dtc.append(cv1.mean())
rfc = RFC()
cv2 = cross_val_score(rfc,X,y,cv=5)
score_rfc.append(cv2.mean())
gbc = GBC()
cv3 = cross_val_score(gbc,X,y,cv=5)
score_gbc.append(cv3.mean())
plt.plot(range(1,11),score_dtc,label = "DecisionTree")
plt.plot(range(1,11),score_rfc,label = "RandomForest")
plt.plot(range(1,11),score_gbc,label = "GBDT")
plt.legend(bbox_to_anchor=(1.4,1))
plt.show()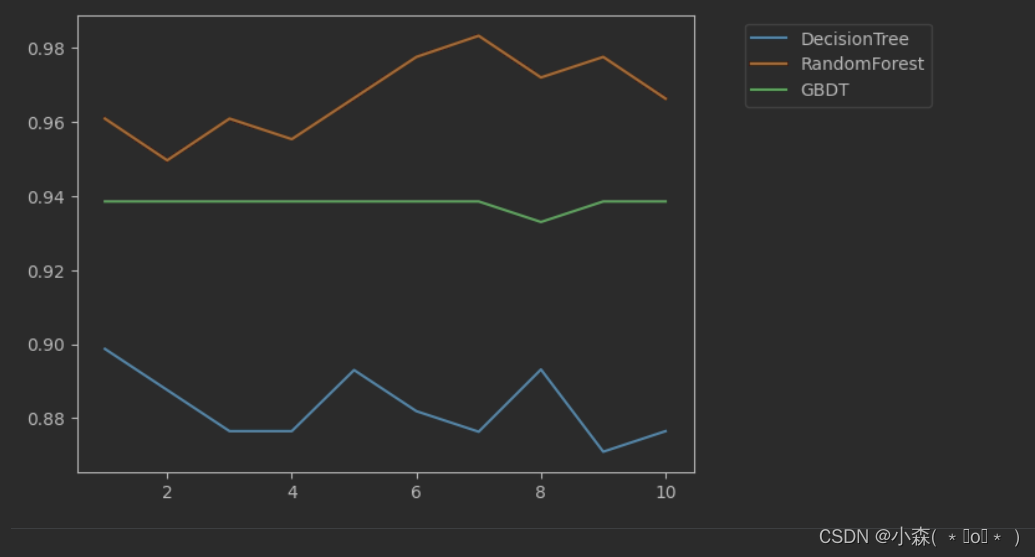
使用GBDT完成回归任务

X,y = fetch_california_housing(return_X_y=True,as_frame=True)
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=0)
# 使用GBDT完成对加利福尼亚房屋数据集的预测
gbr = GBR(random_state=0) #实例化GBDT
gbr = gbr.fit(Xtrain,Ytrain)
r2_gbdt = gbr.score(Xtest,Ytest) # 回归器默认评估指标为R2
r2_gbdt
# 0.7826346388949185
# 计算GBDT回归器的评估指标:均方误差MSE
from sklearn.metrics import mean_squared_error
pred = gbr.predict(Xtest)
MSE = mean_squared_error(Ytest,pred)
MSE
# 0.28979949770874125梯度提升回归与其他算法的对比
import time
modelname = ["DecisionTree","RandomForest","GBDT","RF-D"]
models = [DTR(random_state=0)
,RFR(random_state=0)
,GBR(random_state=0)
,RFR(random_state=0,max_depth=3)]
for name,model in zip(modelname,models):
start = time.time()
result = cross_val_score(model,X,y,cv=5,scoring="neg_mean_squared_error").mean()
end = time.time()-start
print(name)
print("\t MSE:{:.3f}".format(abs(result)))
print("\t time:{:.2f}s".format(end))
print("\n")结果:
DecisionTree
MSE:0.818
time:0.66s
RandomForest
MSE:0.425
time:70.69s
GBDT
MSE:0.412
time:16.84s
RF-D
MSE:0.639
time:11.49s
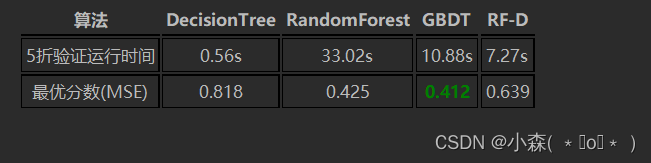
对比决策树和随机森林来说,GBDT默认参数状态下已经能够达到很好的效果。
梯度提升树GBDT的重要参数和属性

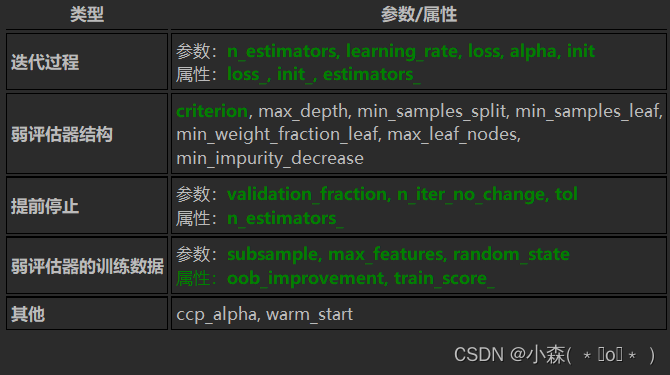
由于GBDT超参数数量较多,因此我们可以将GBDT的参数分为以下5大类别,其他属性我们下次再进行分析验证💨