刘老师群里,看到一位小友 问<MYSQL 45讲>林晓斌的回答
大意是一个组合索引 (a,b,c) 条件 a > 5 and a <10 and b='123', 这样的情况下是如何?
林老师给的回答是 A>5 ,然后下推B='123'
小友 问 "为什么不是先 进行范围查询,然后在索引下推 b='123'?"
然后就没有然后了....
说真的,不是我有意踩林老师, 我只是说<MYSQL 45 讲>吃个半饱, 大脑半醒半睡,好比晚上2点睡,早上被8点闹钟催醒. 上午在公司里梦游状态样.
极客这种课程,视乎给人感觉不全面,不细致.相对于等同价格的书来说,性价比太低了.
以前买了一本ORACLE ACE写的一本MYSQL入门的书.书中把BINLOG CACHE 归类于共享内存.
高鹏(八怪)说BINLOG CAHCE是线程的内存.
ACE 看来就是个荣誉技术编辑&总编.
MYSQL 产生大量数据的过程
我们做个实验,用上面链接的表和数据!
添加个组合索引
KEY `idx_age_income_education` (`age`,`income_year`,`top_education`)我们还是先讲下索引下推是什么鬼?
在很早很早以前 MYSQL 分为一阴一阳两面. SERVER层负责阳的一面,引擎层负责阴的一面.
在这里我们记住一点就是服务层server负责过虑结果集, 只要执行计划有WHERE字眼,说明服务层执行了过滤操作, 另外ROW+FILER % 也可以窥爱一下.
引擎层返回服务层要的数据! 一个SQL有多个WHERE 条件,我们看哪个条件能命中引擎层的二级索引. 我们就把这个条件传给引擎层.引擎层通过这个条件筛选数据,然后返回,服务层再用剩余的条件,进一步筛选过滤(FILTER)记录,积累到NET_BUF满后就发生给客户.
引擎层一般会预读,大约是100条件记录,然后一条,一条给服务层,服务层判断一条记录,再问引擎要一条.
上面一般过程,不必牢记! 重点是 为什么不把服务层过滤条件,全拿到引擎层做呢? 其实都是内存操作,在引擎层还是服务层差距不大.
那为什么要ICP呢? 所以重点是索引, 是服务层把更多的条件,下推到索引上.是引擎上的二级索引.
通过索引过滤掉更多不符合条件的记录. 这样减少去读聚集索引!
一般二级索引都被内存缓存,聚集索引相对较大,不易缓存在内存里.读聚集索引可能要发生IO操作. 能通过ICP优化,能更多减少不必要的IO操作!
MYSQL 专业叫法是 读聚集索引, ORACLE 叫法是 回表! 回表和读聚集索引功能是类似的, 回表操作是直接从索引获得物理ID,直接定位到表具体行.而MYSQL读二级索引获得逻辑ID,还要通过主键聚集索引,根节点,分支节点,再到页节点,多了两次IO操作. 每个逻辑ID都要多两次IO操作. 比回表多了很多次IO操作.再说MYSQL是16K一个页,ORACLE是8K一个页. 优化思路是一样的,实现细节是有区别的. 算法一样,数据结构不一样. 作为MYSQL DBA. 如果还有OCP,COM,ACE头衔,自然不能说"回表",太LOW!
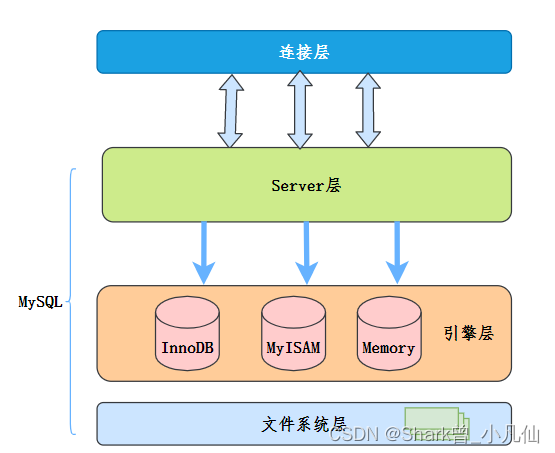
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
我们来具体看一下,在没有使用ICP的情况下,MySQL的查询:
-
存储引擎读取索引记录;
-
根据索引中的主键值,定位并读取完整的行记录;
-
存储引擎把记录交给
Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
-
存储引擎读取索引记录(不是完整的行记录);
-
判断
WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录; -
条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
-
存储引擎把记录交给
Server层,Server层检测该记录是否满足WHERE条件的其余部分。
我们还可以看一下执行计划,
看到Extra一列里Using index condition,这就是用到了索引下推。
-
只能用于
range、ref、eq_ref、ref_or_null访问方法; -
只能用于
InnoDB和MyISAM存储引擎及其分区表; -
对
InnoDB存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
我们使用下面SQL 看下执行计划 根据上面说只要EXTAR using index condition 使用索引条件 这英文取得让人误会. 为啥不多加个单词"using index pushdown condition "
select * from dba_test.personal_identity_info where age > 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
-- NO ICP key_len=10 rows=75 filtered=8.28 Extra=Using where
select * from dba_test.personal_identity_info where age >= 35 and age <= 65;
-- ICP key_len=1 rows=206 filtered=100 Extra=Using index condition
select * from dba_test.personal_identity_info where age > 35 and age < 65;
-- ICP key_len=1 rows=196 filtered=100 Extra=Using index condition
select * from dba_test.personal_identity_info where age > 35 and age < 65 and top_education='大学';
-- NO ICP key_len=10 rows=75 filtered=19.6 Extra=Using where
select * from dba_test.personal_identity_info where age > 35 and age < 65 and income_year > 10000 ;
-- ICP key_len=1 rows=196 filtered=33.33 Extra=Using index condition
select * from dba_test.personal_identity_info where age >= 35 and age <= 65 and income_year > 10000;
-- ICP key_len=6 rows=206 filtered=33.33 Extra=Using index condition
select * from dba_test.personal_identity_info where age = 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
-- ICP key_len=6 rows=1 filtered=7.50 Extra=Using index condition
select * from dba_test.personal_identity_info where income_year > 10000 and income_year < 20000 and top_education='大学' ;
-- NO ICP key_len=10 rows=75 filtered=11.11 Extra=Using where从上面八种情况,或许可以推导出,只要WHERE条件命中了组合索引第一个字段.
它一定会走索引! 其它条件命中组合索引其它字段,也能走索引.
ICP条件1:WHERE条件命中索引第一个字段.
ICP条件2:WHERE其它条件能命中组合索引其它字段,不过不能有等值查询
select * from dba_test.personal_identity_info where age >= 35 and age <= 65 and top_education='大学';
-- NO ICP key_len=10 rows=75 filtered=20.60 Extra=Using where
select * from dba_test.personal_identity_info where age between 35 and 65 and top_education='大学';
-- NO ICP key_len=10 rows=75 filtered=20.60 Extra=Using where另外两个情况下,还是其它WHERE条件命中组合索引且等值 ICP就失效 我的MYSQL 是 8.0.24. 索引下推是开启的
select @@optimizer_switch;
/*
index_merge=on,index_merge_union=on,index_merge_sort_union=on,
index_merge_intersection=on,engine_condition_pushdown=on,
index_condition_pushdown=on,mrr=on,
mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,
materialization=on,semijoin=on,
loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,
use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,
use_invisible_indexes=off,skip_scan=on,hash_join=on,
subquery_to_derived=off,prefer_ordering_index=on,
hypergraph_optimizer=off,derived_condition_pushdown=on
*/
set optimizer_switch="index_condition_pushdown=off";
set optimizer_switch="index_condition_pushdown=on";我们还可以explain format=tree 看的更清楚
explain FORMAT=tree select * from dba_test.personal_identity_info where age > 35 and age < 65 and top_education='大学' and income_year > 10000;
/*
-> Filter: ((personal_identity_info.age > 35) and (personal_identity_info.age < 65) and (personal_identity_info.income_year > 10000)) (cost=7.24 rows=5)
-> Index lookup on personal_identity_info using idx_personal_identity_info_top_education (top_education='大学') (cost=7.24 rows=75)
*/
explain FORMAT=tree select * from dba_test.personal_identity_info where age >= 35 and age <= 65 and top_education='大学' and income_year > 10000;
/*
-> Filter: ((personal_identity_info.age >= 35) and (personal_identity_info.age <= 65) and (personal_identity_info.income_year > 10000)) (cost=7.26 rows=5)
-> Index lookup on personal_identity_info using idx_personal_identity_info_top_education (top_education='大学') (cost=7.26 rows=75)
*/
explain FORMAT=tree select * from dba_test.personal_identity_info where age > 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
/*
-> Filter: ((personal_identity_info.age > 35) and (personal_identity_info.income_year > 10000) and (personal_identity_info.income_year < 20000)) (cost=7.37 rows=6)
-> Index lookup on personal_identity_info using idx_personal_identity_info_top_education (top_education='大学') (cost=7.37 rows=75)
*/
explain FORMAT=tree select * from dba_test.personal_identity_info where age = 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
/*
-> Index range scan on personal_identity_info using idx_age_income_education, with index condition: ((personal_identity_info.age = 35) and (personal_identity_info.income_year > 10000) and (personal_identity_info.income_year < 20000) and (personal_identity_info.top_education = '大学')) (cost=0.71 rows=1)
*/
explain FORMAT=tree select * from dba_test.personal_identity_info where age > 35 and age < 65;
/*
-> Index range scan on personal_identity_info using idx_age_income_education, with index condition: ((personal_identity_info.age > 35) and (personal_identity_info.age < 65)) (cost=88.46 rows=196)
*/
explain FORMAT=tree select * from dba_test.personal_identity_info where age = 35 and income_year > 10000 ;
/*
-> Index range scan on personal_identity_info using idx_age_income_education, with index condition: ((personal_identity_info.age = 35) and (personal_identity_info.income_year > 10000)) (cost=3.86 rows=8)
*/前三个没有下推,后三个下推了,从中可推导出,ICP可以推进多个条件.
另外 推导出
ICP条件3:WHER条件命中组合索引第一个字段且是等值也生效.
看起来条件2和条件3有点冲突,其实不冲突!
一般来说,命中索引的只有一个WHER条件.
这个经验来自ORACLE,MYSQL通过EXPLAIN FORMAT=TREE是看不出来的.
这样只能跟踪源码才可知,跟踪源码是件很累的事情,成本高收益低!
以上胡说八道
此刘老师,不是那个刘老师! 那个刘老师太那个了,200号人捐款4.2万.
说是他自己用个脚本换来的,然后捐给武汉.自己独占了荣誉.
也没感谢大家捐款,也没在公号列出感谢名单.培训也就是培训脚本
如何使用! 说白了就是PPT宣传你的脚本有多么多么厉害.
online脚本套用ORACLE官方脚本SQLHC.
好像 搞得大家200号人 没有良心没有善心,就冲着你的牛X脚本来的?
还搞个PDF污蔑我. 只能忽悠没有脑子的小年轻!
脚本有鸟用,谁敢把来历不明的脚本,用在生产环境中?
8千行再套用个SQLHC,我没有精力去分析代码,
早就扔在上上家公司的办公电脑里!