一 CPU和GPU的区别

衡量处理器优劣的重要的两个指标:
延时性:同量的数据,所需要的处理时间
吞吐性:处理速度不快,但是每次处理量很大
GPU设计理念是最大化吞吐量,使用很小的控制单元对应很小的内存
cpu的设计理念:强大的控制单元和缓存单元
LocalCache将数据存储在内存中,因此可以快速访问缓存数据,提高应用程序的性能。LocalCache适用于许多不同的使用场景,特别是以下几种情况:
1.频繁访问的数据:如果应用程序中有一些频繁被访问的数据,将这些数据存储在LocalCache中可以大大提高访问速度。由于数据存储在内存中,相比于从磁盘或网络中读取数据,从本地缓存中获取数据的速度更快

CPU的理念:



二 cuda编程
1 cuda运行效率
h开头表示是在cpu上的数据,
d开头表示在GPU上的数据

线程块是GPU运行的最小单元,线程块里面的东西不好会被打散


数据读取速度的比较,基于此,如果读取的数据很少,但是处理的数据的计算量很大,这种情况的计算效率就是最高的


合并全局内存:推荐的数据读取方式是连读位置读取数据,速度是最快的;数据的存储也是连续位置

避免线程发散:
(1)避免同一个线程块或者kernel中执行不同的代码,因为不同代码之间的运行所需时间是不一样的,但是线程块又要求同步机制,程序之间彼此会相互等待,会影响程序效率
(2)循环长度不一致


2 理解同步性
前面提到,Block里面的线程运行是同步的,不同kernel各自运行是同步的,kenelA内的东西全部运行结束之后才会运行kernel B,Block的线程同步是需要使用者自己来控制,kernel上的同步运行是GPU自己来实现的


3 硬件和软件之间的对应关系
(1)SM是流处理器
kernel:核,可以理解为c/c++里面的一个函数function,紫色的就是一个个线程
一个GPU包含若干SM

4 kernel的不同加载方式
首先需要清楚自己电脑的性能,知道自己电脑的能承受的最大线程数,每个处理器的最大线程数,每个block的最大线程数,
也可以使用代码,自己去获取计算配置参数



5 cuda如何调用内存
(1)调用局部变量,也就是本地变量
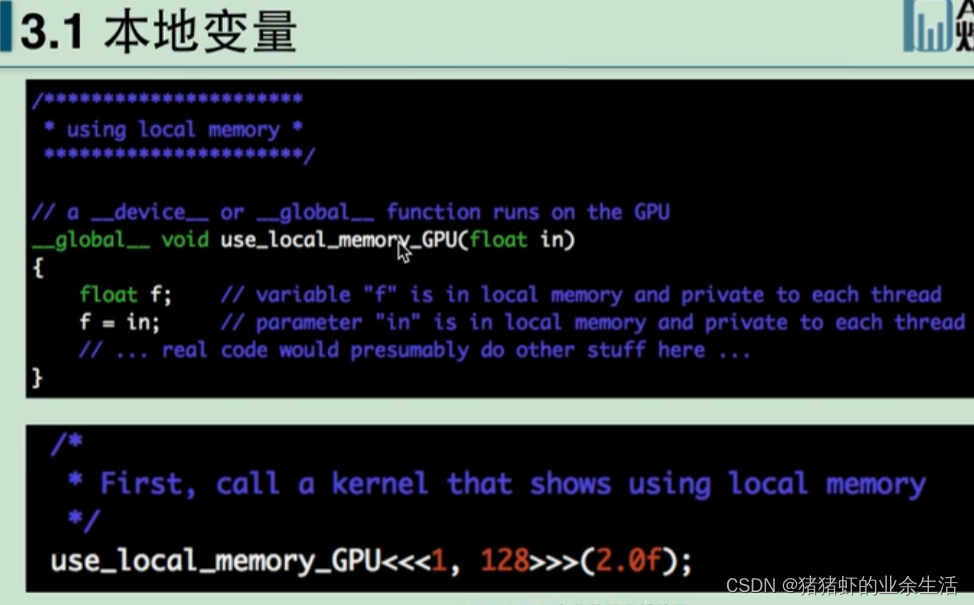
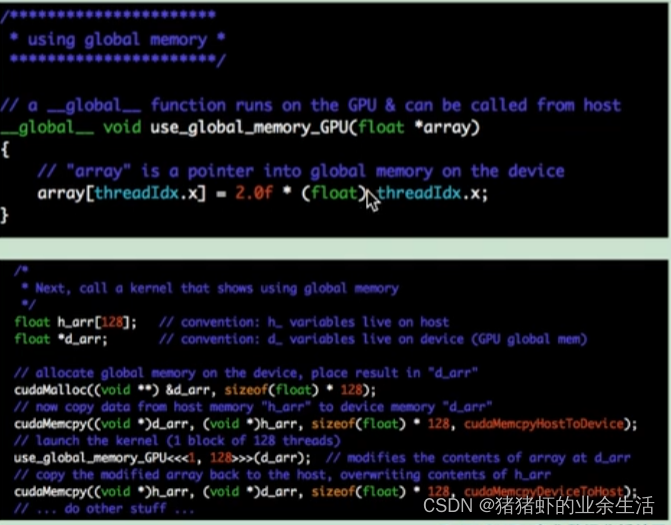
(2)调用全局变量
都是传递指针变量
前半段是自定义
后半段是使用,使用的时候,host表示主机,CPU,device表示GPU,使用的时候需要在GPU上先分配呢内存,然后将主机上的数据拷贝到GPU上,然后加载核函数进行运算,最后再将GPU上运算完毕的数据拷贝回CPU
(3)共享变量的调用
共享变量是每一个线程都在往里面的指定位置写数据,存在一个时间差的问题,就需要加同步机制
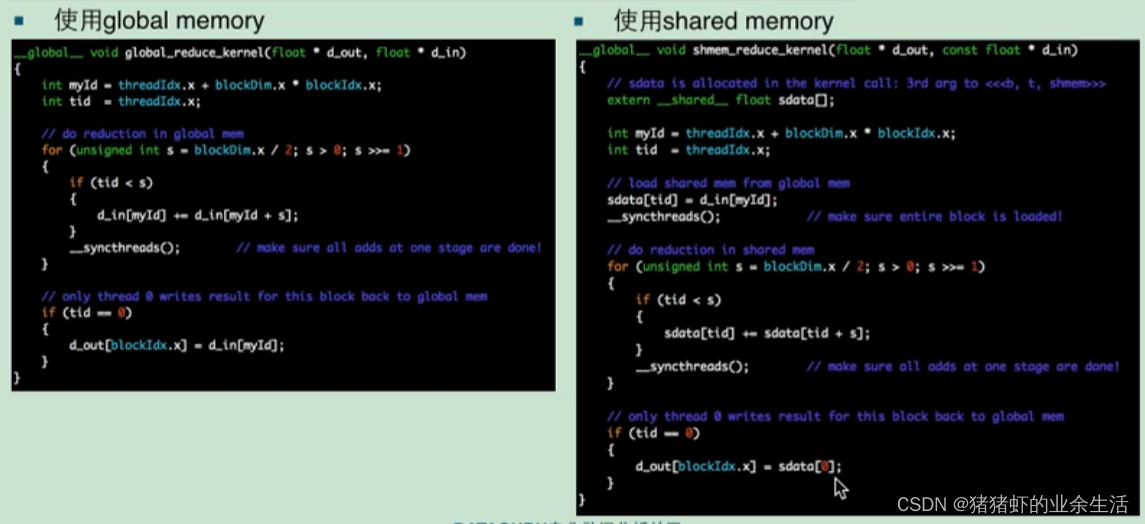
共享数据,三个参数,的含义依次如下

(4)同步操作----原子操作,有些系统不支持,需要自己去实现

(4)同步操作---- 同步函数: _syncthreads()
(5)同步操作---- 同步函数: _threadfence() 以及——threadfence_block()

(5)同步操作---- 同步函数: CPU和GPU同步
主要在主代码里面使用



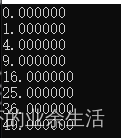
案例1 计算1-7的各自平方
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void square(float* d_out, float* d_in)
{
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc, char** argv)
{
const int ARRAY_SIZE = 8;
const int ARRAY_BITE = ARRAY_SIZE * sizeof(float);
//**************************在cpu上输入数据 *********************
float h_in[ARRAY_SIZE]; //h_in表示存在cpu上的输入数据,
for (int i = 0; i < ARRAY_SIZE; i++)
{
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE]; //h_out用来存储GPU处理完之后传回cpu上的数据
//**************************在GPU上分配内容空间,空间和CPU上数据空间大小一样 *********************
float* d_in; //用来存储从CPU传到GPU上的待处理数据
float* d_out; //用来存储GPU最终处理完的数据
cudaMalloc((void**)&d_in, ARRAY_BITE);
cudaMalloc((void**)&d_out, ARRAY_BITE);
**************************把cpu上的待处理数据复制到GPU上 *********************
cudaMemcpy(d_in, h_in, ARRAY_BITE, cudaMemcpyHostToDevice);
//*****启动加载kernel到GPU,所谓kernel,在这里就是square函数,这个函数是要在GPU上进行实现的 *********************
square << <1, ARRAY_SIZE >> > (d_out, d_in); //使用1个线程块,每个线程块有 ARRAY_SIZE个线程,(d_out, d_in)是函数square的输入参数
//**************************将在GPU上处理完的数据复制到CPU上 *********************
cudaMemcpy(h_out, d_out, ARRAY_BITE, cudaMemcpyDeviceToHost);
for (int i = 0; i < ARRAY_SIZE; i++)
{
printf("%f", h_out[i]);
printf("%\n");
}
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
案例2 归约,求和运算,对1+2+3+…
归约:多个输入但是最后只有一个输出
**
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
//#include <device_functions.h>
using namespace std;
__global__ void global_reduce_kernel(float* d_out, float* d_in)
{
int myId = threadIdx.x + blockDim.x * blockIdx.x; //有多个block.在所有线程里面的位置,全局变量的位置
int tid = threadIdx.x; //在当前block里面的位置
// do reduction in global mem
// //循环的条件是 s 大于 0,每次循环迭代结束后,s 的值右移一位(相当于将其除以 2),以便在下一次迭代中处理更小的数据块
// //这里是实现每一个block里面线程的对半累加
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1)
{
if (tid < s)
{
d_in[myId] += d_in[myId + s];
}
__syncthreads(); // make sure all adds at one stage are done! //每个线程块每次循环结束之后才进行下一次运行
}
//最后要的是线程块的所有计算的求和结果
// only thread 0 writes result for this block back to global mem
if (tid == 0) //等于0说明当前block的所有线程对折运算结束
{
d_out[blockIdx.x] = d_in[myId];
}
}
使用共享内存实现归约
__global__ void shmem_reduce_kernel(float* d_out, const float* d_in)
{
// sdata is allocated in the kernel call: 3rd arg to <<<b, t, shmem>>>
extern __shared__ float sdata[]; //给每一个block定义他们各自的内存;
int myId = threadIdx.x + blockDim.x * blockIdx.x; //有多个block.在所有线程的位置
int tid = threadIdx.x;
// load shared mem from global mem
// //然后将全局内存的数据复制给共享内存, 之后就不需要再从全局内存读数据,
// //共享数据读取的速度快于全局内存
sdata[tid] = d_in[myId];
__syncthreads(); // make sure entire block is loaded!
// do reduction in shared mem
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1)
{
if (tid < s)
{
sdata[tid] += sdata[tid + s];
}
__syncthreads(); // make sure all adds at one stage are done!
}
// only thread 0 writes result for this block back to global mem
if (tid == 0)
{
d_out[blockIdx.x] = sdata[0];
}
}
void reduce(float* d_out, float* d_intermediate, float* d_in,
int size, bool usesSharedMemory)
{
// assumes that size is not greater than maxThreadsPerBlock^2
// and that size is a multiple of maxThreadsPerBlock
const int maxThreadsPerBlock = 1024;
int threads = maxThreadsPerBlock;
int blocks = size / maxThreadsPerBlock;
if (usesSharedMemory)
{
shmem_reduce_kernel << <blocks, threads, threads * sizeof(float) >> >
(d_intermediate, d_in);
}
else
{
global_reduce_kernel << <blocks, threads >> >
(d_intermediate, d_in);
}
// now we're down to one block left, so reduce it
// //这里的blocks设为1使因为,假设有1024个线程块,每个线程块有1024个线程,之前在每个线程块里面完成了各自的对半加,最后每个线程块将得到
// //一个数据,总的得到1024个数据,刚好放置在一个block里面完成最后的对半累加
threads = blocks; // launch one thread for each block in prev step
blocks = 1;
if (usesSharedMemory)
{
shmem_reduce_kernel << <blocks, threads, threads * sizeof(float) >> >
(d_out, d_intermediate);
}
else
{
global_reduce_kernel << <blocks, threads >> >
(d_out, d_intermediate);
}
}
int main(int argc, char** argv)
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount == 0) {
fprintf(stderr, "error: no devices supporting CUDA.\n");
exit(EXIT_FAILURE);
}
int dev = 0;
cudaSetDevice(dev);
cudaDeviceProp devProps;
if (cudaGetDeviceProperties(&devProps, dev) == 0)
{
printf("Using device %d:\n", dev);
printf("%s; global mem: %dB; compute v%d.%d; clock: %d kHz\n",
devProps.name, (int)devProps.totalGlobalMem,
(int)devProps.major, (int)devProps.minor,
(int)devProps.clockRate);
}
const int ARRAY_SIZE = 1 << 10;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
float sum = 0.0f;
for (int i = 0; i < ARRAY_SIZE; i++) {
// generate random float in [-1.0f, 1.0f]
h_in[i] = -1.0f + (float)rand() / ((float)RAND_MAX / 2.0f);
printf("%f ", h_in[i]);
sum += h_in[i];
}
// declare GPU memory pointers
float* d_in, * d_intermediate, * d_out;
// //在GPU上创建存储待处理数据和处理结果的数组
// allocate GPU memory
cudaMalloc((void**)&d_in, ARRAY_BYTES);
cudaMalloc((void**)&d_intermediate, ARRAY_BYTES); // overallocated
cudaMalloc((void**)&d_out, sizeof(float));
// //将CPU输入数据输入到GPU
// transfer the input array to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
int whichKernel = 0;
if (argc == 2) {
whichKernel = atoi(argv[1]);
}
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// launch the kernel
switch (whichKernel) {
case 0:
printf("Running global reduce\n");
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
reduce(d_out, d_intermediate, d_in, ARRAY_SIZE, false);
}
cudaEventRecord(stop, 0);
break;
case 1:
printf("Running reduce with shared mem\n");
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
reduce(d_out, d_intermediate, d_in, ARRAY_SIZE, true);
}
cudaEventRecord(stop, 0);
break;
default:
fprintf(stderr, "error: ran no kernel\n");
exit(EXIT_FAILURE);
}
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
elapsedTime /= 100.0f; // 100 trials
// copy back the sum from GPU
float h_out;
cudaMemcpy(&h_out, d_out, sizeof(float), cudaMemcpyDeviceToHost);
printf("average time elapsed: %f\n", elapsedTime);
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_intermediate);
cudaFree(d_out);
return 0;
}
**
案例3 扫描并行,也是实现求和运算,但是使用场景不同,使用场景是每输入一个数,完成当数和之前所有数据的累加 ??
算法思想:从n = 0,1,2,…依次以0,2^n 然后为间隔做累加,如下图,第一次累加是以0为间隔,相邻两个数做累加,
0前面没有可以和他直接相加的数,所以直接搬下去,第二次累加是以1为间隔的两个数做累加,0,1,前面没有和累加的数,所以,0,1,直接搬下去

#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
//#include <device_functions.h>
using namespace std;
__global__ void global_scan_kernel(float* d_out, float* d_in)
{
int idx = threadIdx.x; //在当前block里面的位置
float out = 0.00f;
d_out[idx] = d_in[idx];
__syncthreads(); //这里同步是希望上面的赋值操作全部完成之后,才能开始下面的操作,这是扫描计算的前提,所有数据都要准备好
for (int interval = 1; interval < sizeof(d_in); interval *= 2)
{
if (idx - interval >= 0)
{
out = d_out[idx] + d_out[idx - interval];
}
__syncthreads(); //当前所有数据计算完毕,才能进入下一轮的计算,也就是要求每一轮的数据都是准备完毕的
if (idx - interval >= 0)
{
d_out[idx] = out;
out = 0.00f;
}
}
}
__global__ void shmem_scan_kernel(float* d_out, const float* d_in)
{
// sdata is allocated in the kernel call: 3rd arg to <<<b, t, shmem>>>
extern __shared__ float sdata[]; //给每一个block定义他们各自的内存;
int idx = threadIdx.x; //在当前block里面的位置
sdata[idx] = d_in[idx];
float out = 0.00f;
__syncthreads(); // make sure entire block is loaded!
for (int interval = 1; interval < sizeof(d_in); interval *= 2)
{
if (idx - interval >= 0)
{
out = sdata[idx] + sdata[idx - interval];
}
__syncthreads(); //当前所有数据计算完毕,才能进入下一轮的计算,也就是要求每一轮的数据都是准备完毕的
if (idx - interval >= 0)
{
//这里为什么能直接把out赋值到idx索引,因为在此之前加了同步语句,
// 也就是多个线程同时运行,同时执行out = sdata[idx] + sdata[idx - interval];语句,
//然后计算完毕就同时存在多个out,所以才能把各自的out赋值到idx,至于为什么要存到idx索引,
//是因为算法需要它存到对应的位置
sdata[idx] = out;
out = 0.00f;
//????????????????????????? 为什么打印不了中间过程
//printf("*************\n");
//printf("%f ", sdata[idx]);
//printf("*************\n");
}
}
d_out[idx] = sdata[idx];
}
int main(int argc, char** argv)
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount == 0) {
fprintf(stderr, "error: no devices supporting CUDA.\n");
exit(EXIT_FAILURE);
}
int dev = 0;
cudaSetDevice(dev);
cudaDeviceProp devProps;
if (cudaGetDeviceProperties(&devProps, dev) == 0)
{
printf("Using device %d:\n", dev);
printf("%s; global mem: %dB; compute v%d.%d; clock: %d kHz\n",
devProps.name, (int)devProps.totalGlobalMem,
(int)devProps.major, (int)devProps.minor,
(int)devProps.clockRate);
}
const int ARRAY_SIZE = 8; //数字1 << 左移,1 << i = pow(2,i)
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
printf("-------------input-----------\n ");
for (int i = 0; i < ARRAY_SIZE; i++) {
// generate random float in [-1.0f, 1.0f]
h_in[i] = i;
printf("%f ", h_in[i]);
}
// declare GPU memory pointers
float* d_in, * d_out;
//在GPU上创建存储待处理数据和处理结果的数组
// allocate GPU memory
cudaMalloc((void**)&d_in, ARRAY_BYTES);
cudaMalloc((void**)&d_out, ARRAY_BYTES);
// //将CPU输入数据输入到GPU
// transfer the input array to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
cudaEvent_t start, stop;
cudaEventCreate(&start); //用于创建事件,用于测量GPU操作的时间
cudaEventCreate(&stop);
int whichKernel = 1;
if(!whichKernel)
//global_scan_kernel << <blocks, threads >> > (d_in);
global_scan_kernel << <1, ARRAY_SIZE >> > (d_out,d_in);
else
shmem_scan_kernel << <1, ARRAY_SIZE,ARRAY_SIZE*sizeof(float) >> > (d_out, d_in);
// copy back the sum from GPU
float h_out[ARRAY_SIZE];
cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
elapsedTime /= 100.0f; // 100 trials
printf("\n");
if (whichKernel == 0)
{
printf("global_scan_kernel\n");
}
else
{
printf("share_scan_kernel\n");
}
printf("-------------out-----------\n ");
for (int i = 0; i < ARRAY_SIZE; i++) {
// generate random float in [-1.0f, 1.0f]
printf("%f ", h_out[i]);
}
printf("-------------out-----------\n ");
printf("\n");
printf("average time elapsed: %f\n", elapsedTime);
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_out);
return 0;
}


案例4 直方图的并行计算
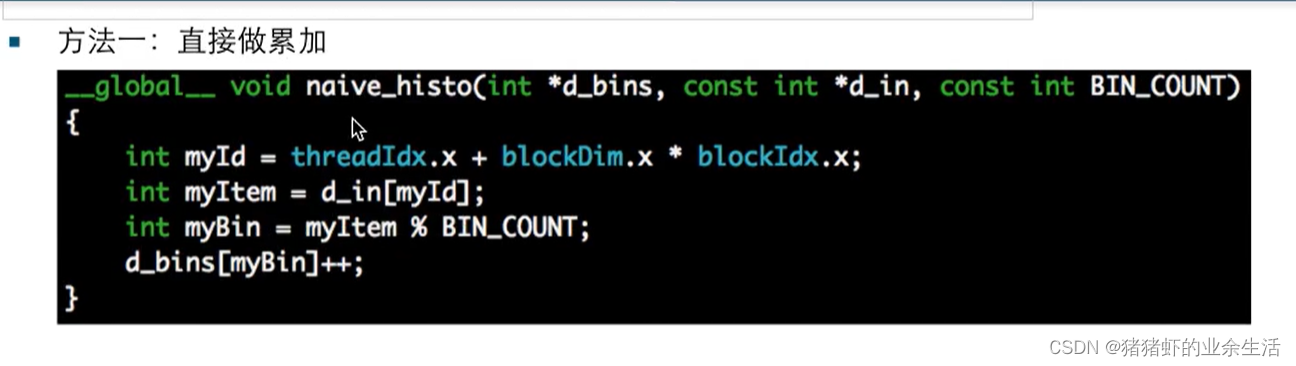
(1)错误1:对数据同时操作读和写 ??
下面这种写法,对于第一个bin来说,假设输入数据是1:66655,数据1和17都会同时读bin里面的初始计数,然后进行累加,正常来说应该是两个数据同时读了bin1的0,然后同时写一个1进去,最后结果总是1,但是可能机器会出问题,导致最多也就写一个2,先后加了1.

(2)对于(1)的改进,用原子相加,将读写并行做成串口,数据1读写完成之后,17才能进行读写。这样处理的并行化程度是取决于bin的数量的(2)的并行主要在累加的地方,写入的时候是串行,如果bin很多,平摊下来的时间就短,并行化程度就高了。
AtomicAdd就是原子操作,原子操作就相当于各个线程排队操作。 bin的数量就相当于队列的数量,队列多了,肯定就快了,队列多,等待是并行的。
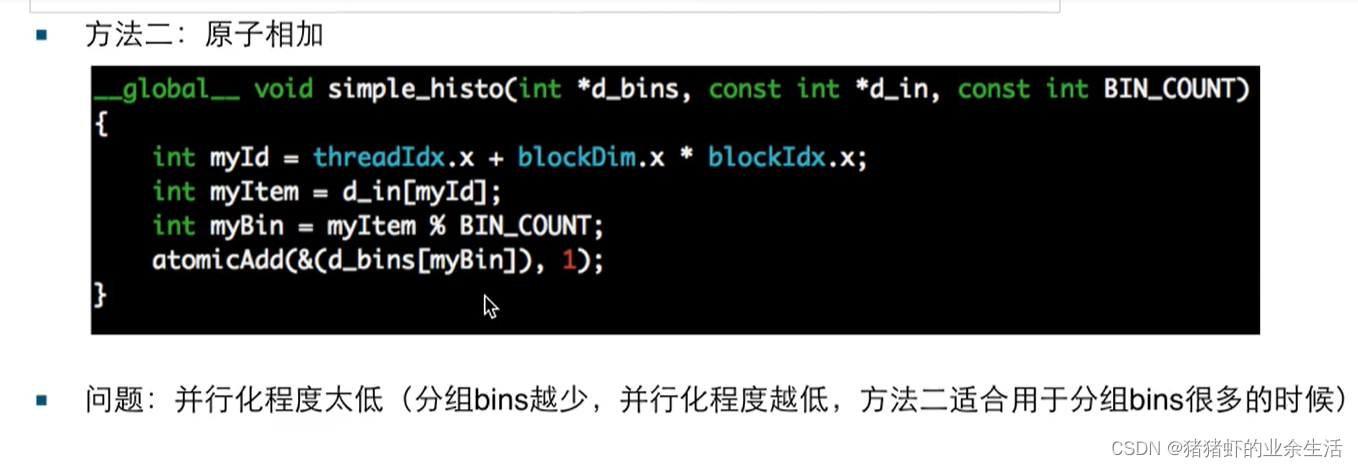
(3)局部直方图,读写本身就是串行的,


#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
//假设是8个block,8个线程,也就是每个block要处理16个数据
__global__ void local_histo(float* d_out, float* d_in, const int BIN_COUNYT, const int Threads_count) {
int idx = threadIdx.x + blockDim.x*blockIdx.x; //有多个block.在所有线程里面的位置
int tid = threadIdx.x; //在当前block里面的位置
//总共128个数,分成3个bin,但是先要分成8组同时用8个线程来对数据进行处理,也就是说每个线程处理16个数据,处理的结果最后各自形成各自的3个bin,
//d_out里面,相连的三个数据认为是一组不重复且不连续的16个数的统计直方图,依次存储
for (int interpre = 1; interpre < sizeof(d_in)/ Threads_count; interpre +=8)
{
int binID = d_in[idx] % BIN_COUNYT;
d_out[tid] ++;
}
}
int main(int argc, char** argv) {
//**********************************
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount == 0) {
fprintf(stderr, "error: no devices supporting CUDA.\n");
exit(EXIT_FAILURE);
}
int dev = 0;
cudaSetDevice(dev);
cudaDeviceProp devProps;
if (cudaGetDeviceProperties(&devProps, dev) == 0)
{
printf("Using device %d:\n", dev);
printf("%s; global mem: %dB; compute v%d.%d; clock: %d kHz\n",
devProps.name, (int)devProps.totalGlobalMem,
(int)devProps.major, (int)devProps.minor,
(int)devProps.clockRate);
}
//**********************************
const int ARRAY_SIZE = 128;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float* d_in;
float* d_out;
// allocate GPU memory
cudaMalloc((void**)&d_in, ARRAY_BYTES);
cudaMalloc((void**)&d_out, ARRAY_BYTES);
// transfer the array to GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
// launch the kernel
int USED_threadNum = 8;
int USED_BLOCK = 8;
/*local_histo << <1, ARRAY_SIZE >> > (d_out, d_in);*/
local_histo << < USED_BLOCK, threadNum >> > (d_out, d_in, 3, USED_threadNum)
// copy back the result array to the GPU
cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost);
// print out the resulting array
for (int i = 0; i < ARRAY_SIZE; i++) {
printf("%f", h_out[i]);
printf(((i % 4) != 3) ? "\t" : "\n");
}
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
案例5 压缩与分配

稀疏型:52个线程同时运行,进行判读,不满足条件的就终止运算了,也就是说52个线程的运行时间是不相同的,有些线程中途会被闲置
密集型:先52个线程一起判断是不是方块;然后再用13个线程完成卡片的计算

案例6 分段扫描
对每个数据段里面的数据,实现各自的扫描

分段扫描的应用案例:稀疏矩阵的处理

案例7 排序

归并排序





![【已解决】FileNotFoundError: [Errno 3] No such file or directory: ‘xxx‘](https://img-blog.csdnimg.cn/direct/6782c1b287b449b6b9ef1fb273ac7e34.png)