文章目录
- 软件测试-mysql快速入门
- sql主要划分
- mysql常用的数据类型
- sql基本操作
- 常用字段的约束:
- 连接查询
- mysql内置函数
- 存储过程
- 视图
- 事务
- 索引
软件测试-mysql快速入门
sql主要划分
sql语言主要分为:
- DQL:数据查询语言,用于对数据进行查询,select
- DDL:数据定义语言,进行数据库,表的管理,create、drop
- DML:数据操作语言,对数据进行增删改,insert,update,delete
- TPL:事务处理语言,对事物进行处理,包括begin transaction,commit,rollback
mysql常用的数据类型
- 整数:int
- 小整数:tinyint 8位(-128,127)(0-255)
- 小数:decimal,如decimal(5,2)表示共存5位数,小数占2位,不能超过2为,整数3位不能超过三位
- 字符串:varchar , 一个中文和一个字母都占一个字符
- 日期时间:datetime, (1000-01-01 00:00:00~9999-12-31 23:59:59)
--书写格式
create table 表名(
字段名 数据类型,
字段名 数据类型
...
);
sql基本操作
- Insert 添加数据
sql语句中,字符串用单引号‘’或者双引号“”引起来,数字可以忽略引号
insert into 表名 values(…);-- 插入表所有字段
insert into 表名(…) values(…);-- 插入表中指定字段
insert into 表名 values(…),(…);-- 插入多条数据
- update 修改数据
update 表名 set 字段1=值,字段2=值2… where 条件;
- Delete删除表中的记录
delete from 表名 where 条件;
- truncate 删除表中的记录
truncate table 表名;(删除表的所有数据,保留表结构)
delete 和truncate的区别?
- 在速度上,truncate》delete;
- 如果想删除部分数据用delete,注意带上where子句
- 如果想保留表而将所有数据删除,自增长字段恢复从1开始,用truncate
drop table 删除表
drop table 表名;
drop table if exists 表名;
常用字段的约束:
-
主键(primary key):值不能重复,Auto_increment代表值自动增长
-
非空(not null):字段不允许为空
-
唯一(unique):字段的值不允许重复
-
默认值(default):当不填写此值时会使用默认值
语法格式:
create table 表名(
字段名 数据类型 约束,
字段名 数据类型 约束
...
);
-
带有 primary key(主键)的字段,值不能重复;
-
Auto_increment 为自增长
-
语法
create table 表名( 字段名 数据类型 primary key auto_increment, 字段名 数据类型 约束 ... ); -
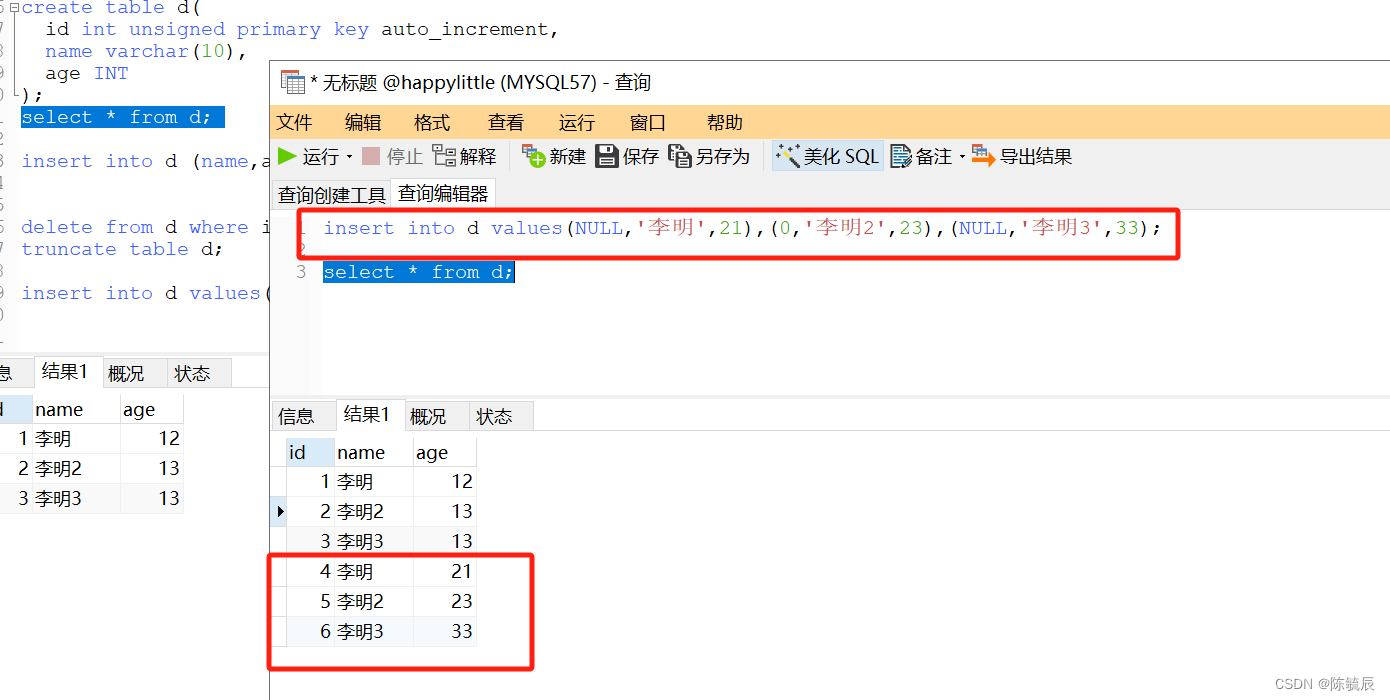
insert into d (name,age)values('李明',12),('李明2',13),('李明3',13); # 主键并且自增长字段的表,insert语句插入数据,如果不指定id字段,id字段的值会自动增长 -
如果插入数据时,插入所有字段,但又没写自增长字段的值,insert语句会出错
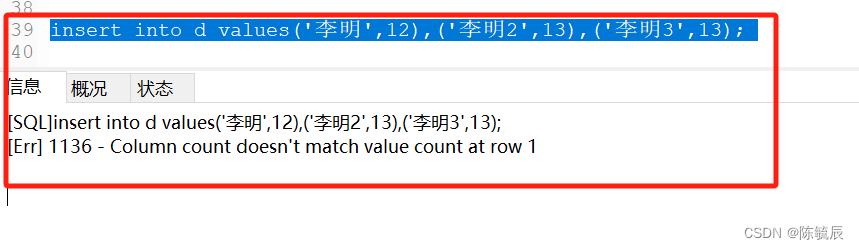
解决方案 -
使用占位符,通常使用0或者null来占位。从而实现自增长。
-
-
非空
- 带有not null
-
唯一
- unique,字段值不能重复
-
default
- 设置字段默认值
-
别名 — as(也可以用空格代替)
-
去重 — distinct
-
比较运算符
- 等于 =
- 大于 >
- 小于 <
- 小于等于 <=
- 不等于 != 或者<>
-
逻辑运算符
- and
- or
- not
-
模糊查询
-
like
-
%表示任意多个字符
-
_表示一个任意字符
-
select * from students where name like '孙%' select * from student where name like ‘孙_’
-
-
范围查询
-
in 在一个非连续的范围内
-
select * from student where home in ('北京','上海','天津') -
between … and … 表示在一个连续的范围内
-
select * from student where age between 25 and 30;
-
-
空判断
-
注意:
null 与 ‘’ 是不同的
null 代表什么都没有
''代表长度为0的字符串
-
判断空 is null
-
非空 is not null
-
-
排序
-
asc(默认,升序)
-
desc (降序)
-
select * from 表名 order by 字段1
-
-
聚合
- count() 计算总记录数
- max() 最大值
- min()最小值
- sum()求和
- avg()求平均
-
数据分组
-
分组
-
select 字段,聚合函数.. from 表名 group by 字段 -
分组后筛选
-
select 字段,聚合函数.. from 表名 group by 字段 having 字段
-
-
注意:
对比where与having
- where是对from后面指定的表进行数据筛选,属于对原始数据的筛选
- having是对group by的结果进行筛选
- having后面的条件中可以用聚合函数,where后面的条件不可以使用聚合函数
-
数据分页显示
-
获取部分行
-
select * from 表名 limit start,count; 从start开始,获取count条数据 select * from 表名 limit num num表示获取数据的条数,默认从第一行开始 -
分页
-
select * from students limit(n-1)*m,m; 已知每页m条数据,查询第n页数据
-
连接查询
-
定义
- 当查询结果来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的结果返回;
- 连接查询可以通过连接运算符(连接条件)可以实现多个表查询
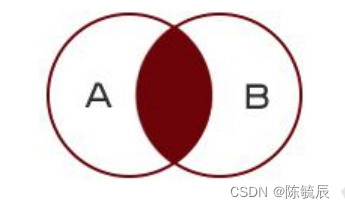
- 内连接:查询的结果只显示两个表中满足连接条件的部分
-
左连接:查询的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用null填充

-
右连接:查询的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用null填充

-
内连接
-
语法1
select * from 表1 inner join 表2 on 表1.字段=表2.字段 -
语法2
select * from 表1,表2 where 表1.字段=表2.字段select * from 表1 inner join 表2 on 表1.字段=表2.字段 where 表1.字段=?select * from 表1 inner join 表2 on 表1.字段=表2.字段 where 表1.字段1=?and 表1.字段2=?select * from 表1 inner join 表2 on 表1.字段=表2.字段 inner join 表3 on 表3.字段=表2.字段 where 表1.字段=?
-
-
左连接
-
select * from 表1 left join 表2 on 表1.字段=表2.字段
-
-
右连接
-
select * from 表1 right join 表2 on 表1.字段=表2.字段
-
-
自关联:
- 设计省信息的表结构provinces
- proid:省编码
- pname:省名称
- 设计市信息的表结构citys
- cityid:市编号
- cname:市名称
- proid:市所属的省编号
- citys表的proid表示城市所属的省,对应着provinces表的proid值
- 问题:能不能将两个表合成一张表呢?
- 思考:两个表之间字段类型都是一样,就相差一个proid
- 意义:存储的都是地区信息,而且每种信息数据都是数量有限的,没必要增加一个新表,或者将来还要新增区乡信息,加表会增大开销。
- 答案:
- 可以定义个areas表,结构如下:
- id
- name
- pid
- 表中的一条记录,可以记录省,也可以记录市
- 记录省的时候,字段说明
- id:代表省id
- name:省名
- pid:因为省没有所属省份,所以pid写为null
- 记录为市时,字段说明
- id 代表市
- name 代表市名称
- pid:代表市所属的省id
- ==这就是自关联,表中某个字段,关联表中另一个子弹,但是他们的业务逻辑含义不一样,城市信息pid引用的是省信息的id
- 表的结构不变,也可扩充县,镇,区信息
- 可以定义个areas表,结构如下:
- 设计省信息的表结构provinces
-
子查询
-
定义:在一个select语句中,嵌入了另一个select语句,那么被嵌入的select语句被称为子查询
-
主查询
- 外层第一条select语句为主查询
-
格式1
select avg(age) from stu;-- 结果只有一行一列,一个值 select * from stu where age>(select avg(age) from stu); 称为标量子查询 -
格式2
select studentNo from students where age=30;-- 一列(一列多行) select score from sc where studentNo in (select studentNo from students where age=30); 称为列子查询 -
表级子查询:子查询返回的结果是多行多列(一个表),这种为表级子查询 select * from (select * from stu where sex='女') stu inner join sc on stu。studentNo = sc.studentNo
-
mysql内置函数
- 字符串函数
- 拼接字符串函数 从concat(str1,str2,…)
- 返回字符个数 length(str)
- 如果字符串中包含utf8格式汉字,一个汉字length返回3
- select length(‘陈’);-- 3
- 截取字符串 left(str,len);返回字符串str的左端len个字符,中文与英文字母个数len一致
- right(str,len)返回字符串str的右端len个字符,中文与英文字母个数len一致
- 去除空格 ltrim(str);删除左侧str中的空格
- 去除空格 rtrim(str);删除右侧str中的空格
- 去除空格 trim(str);删除左右侧str中的空格
- 四舍五入 round(n,d);n为原数,d为小数,默认为0
- 随机数 rand() 值为0-1.0之间的浮点数
- 日期时间函数
- current_date()当前日期
- 当前时间current_time()
- 当前日期时间now()
存储过程
-
定义
- 存储过程procedure,也称为存储程序,是一条或者多条sql语句的集合
-
创建存储过程
-
语法
-
create procedure 存储过程名称(参数列表)
begin
sql 语句
end
例1:创建查询过程stu(),查询students表所有学生信息
第一步:设置分割符(Navicat中不需要)delimiter//
第二步:创建存储过程 create procedure stu()
begin
select * from students;
end
第三步:还原分割符(Navicat中不需要)
//
delimiter
-
-
使用存储过程
-
语法
-
call 存储过程(参数列表);
使用存储过程stu()
call stu();
-
-
删除存储过程
-
语法
-
drop procedure 存储过程
drop procedure if exists 存储过程;
例1:删除存储过程stu
drop procedure stu;
drop procedure if exists stu;
-
视图
-
定义
- 对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦;
- 解决:定义视图;
- 视图本质就是对查询的封装;
-
创建视图
-
语法
-
create view 视图名称 as select语句;
例1:创建视图,名叫stu_nan,查询所有男生信息
create view stu_nan as select * from students where sex=‘男’;
-
-
使用视图
-
语法:
select * from 视图名;
例1:使用视图stu_nan
select * from stu_nan;
例2:在视图stu_nan 中查找年龄大于25岁的学生信息
select * from stu_nan where age>25;
-
-
删除视图
-
语法
-
drop view 视图名称;
drop view if exists 视图名称;
-
事务
-
一、为什么要有事务
事务广泛的运用于订单系统、银行系统等多种场景;
例如:A用户和 B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
1、检查 A的账户余额>500 元;
2、A 账户中扣除 500 元;
3、B 账户中增加 500 元;
正常的流程走下来,A 账户扣了 500,B 账户加了 500,皆大欢喜。那如果 A账户扣了钱之后,系统出故障了呢?A白白损失了 500,而B也没有收到本该属于他的 500。以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败,事务的需求就在于此。 -
二、什么是事务
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
例如:银行转帐工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。所以,应该把他们看成一个事务
事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性 -
三、事务命令
-
开启事务
- begin;
说明:开启事务后执行修改 UPDATE 或删除 DELETE 记录语句,变更会写到缓存中而不会立刻生效。
- begin;
-
回滚事务
-
rollback;
说明:放弃修改。
-
-
提交事务
-
commit;
说明:将修改的数据写入实际的表中。
-
-
例 1:开启事务,删除 students 表中 studentNo 为 001 的记录,同时删除 scores表中 studentNo 为 001 的记录,回滚事务,两个表的删除同时放弃
begin;
delete from students where studentNo='001',
delete from scores where studentNo = '001'.
rollback;
例 2:开启事务,删除 students 表中 studentNo 为 001 的记录,同时删除 scores表中 studentNo 为 001 的记录,提交事务,使两个表的删除同时生效
begin;
delete from students where studentNo ='001';
delete from scores where studentNo ='001';
commit;
索引
-
一、思考:
看一本书,怎么快速知道要查看的内容在多少页?给书建立一个目录;通过目录的索引,快速找到内容对应的页。 -
当表中数据量很大时,查找数据会变得很慢;可以给表建议一个类似书籍中的目录,从而加快数据查询效率,这在数据库中叫索引(index)
-
创建索引
-
create index 索引名称 on 表名(字段名称(长度));
如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致;
字段类型如果不是字符串,可以不填写长度部分。例 1:为表 students 的 age 字段创建索引,名为 age index
create index age_index on students(age);
例 2:为表 students 的 name 字段创建索引,名为 name_index
create index name index on students(name(10));
例 3:查询表中 age 等于 30 的学生
select * from students where age=30
-
例 3中的 SELECT 语句 mysql 会自动调用索引age_index,从而提升查询效率
例 4:查询表中 name 等于’张飞’的学生
select * from students where name=‘张k’;例4中的 SELECT 语句 mysql会自动调用索引name index,从而提升查询效率
例 5:查询表中 sex 等于’男’的学生
select* from students where sex=‘男’,例5 中的 SELECT 语句查询效率不会提升,因为没有为字段 sex 建立任何索引
-
-
三、查看索引
- show index from 表名;
- 例 1:查看 students 表的所有索引
show index from students;
-
四、删除索引:
- drop index 索引名称 on 表名;
例 1:删除 students 表的索引 age index
drop index age_index on students;
- drop index 索引名称 on 表名;
-
五、索引优缺点
优点:
索引大大提高了 SELECT 语句的查询速度:
缺点:
虽然索引提高了查询速度,同时却会降低更新表的速度,例如对表进行INSERT、UPDATE 和 DELETE 操作。因为更新表时,不仅要保存数据,还要保存索引文件;
在实际应用中,执行 SELECT 语句的次数远远大于执行 INSERT、UPDATE 和DELETE 语句的次数,甚至可以占到 80%~90%,所以为表建立索引是必要的。在大量数据插入时,可以先删除索引,再批量插入数据,最后再添加索引,这样就可以提高数据插入的效率,