声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请联系作者立即删除!
前言
别问为什么这么写文章。
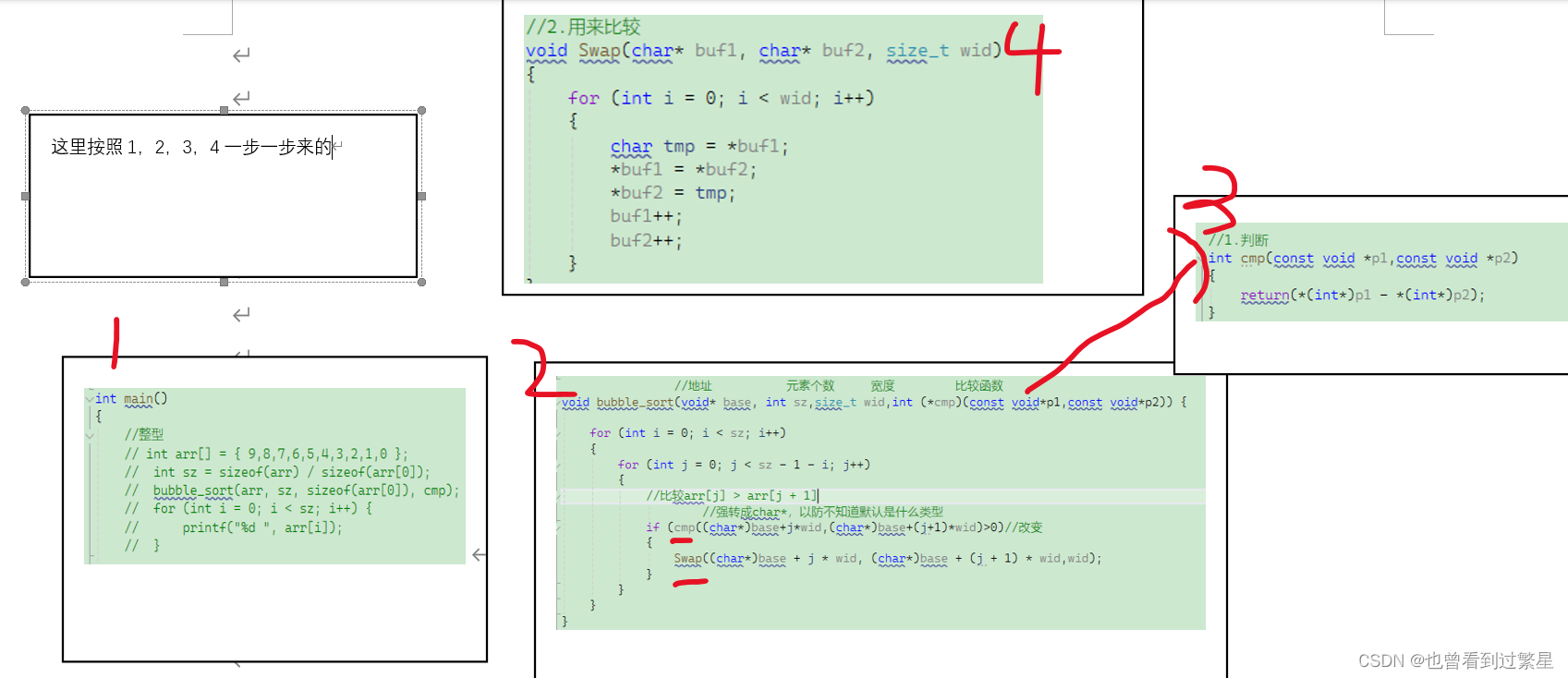
1.逆向过程
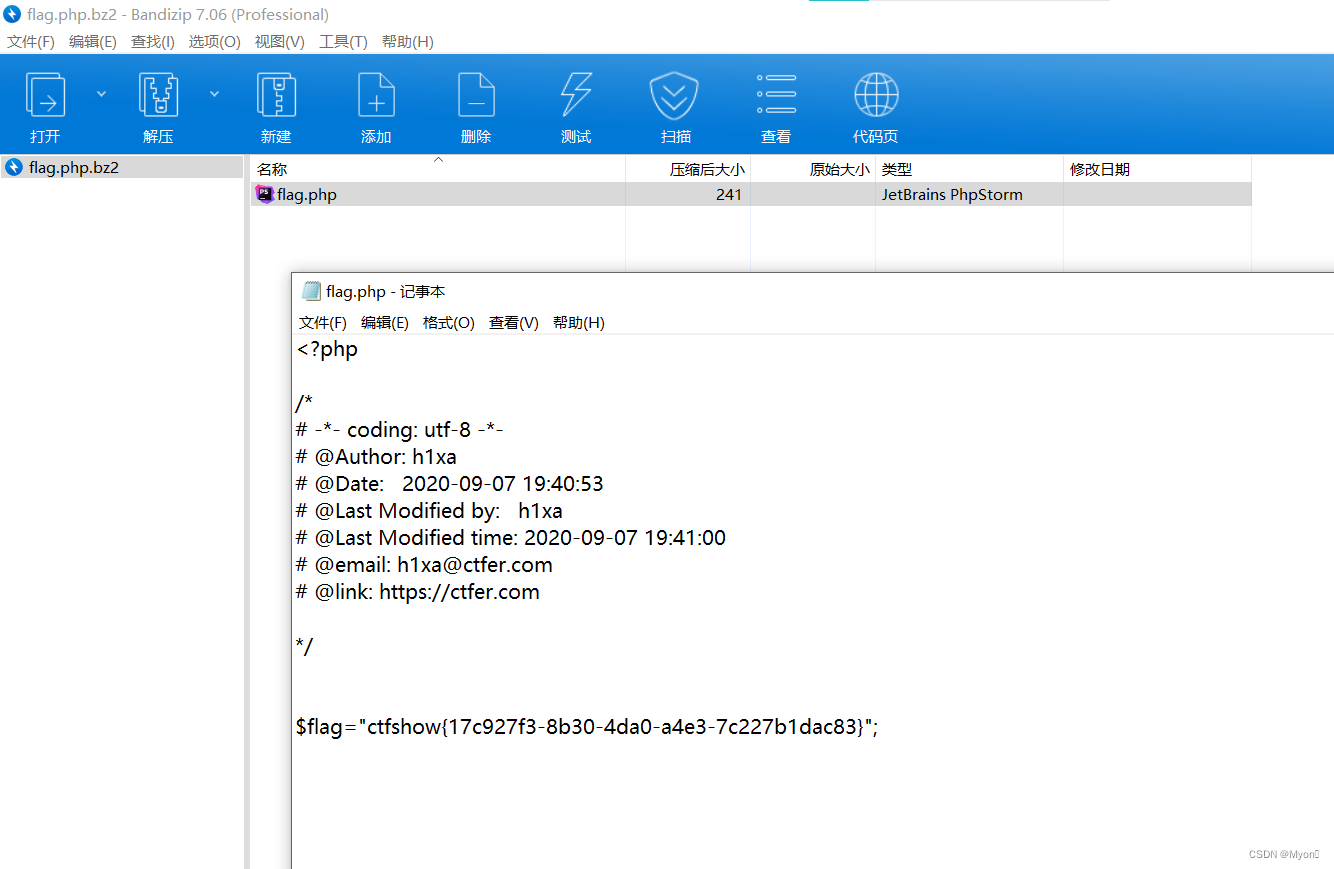
2.后缀怎么来的
3.演示
4.部分代码
def fetch(self, url, apiUrl, pageNum, itemId, timestamp,searchValue):
headers = {}
session = requests.Session()
response = session.get(url, headers=headers)
# print(response.text)
tree = etree.HTML(response.text)
ts_url = tree.xpath('//script/@src')[0]
# print(ts_url)
ts_resp = session.get(urljoin(response.url, ts_url), headers=headers).text
netloc_ = urlparse(response.url)[1]
if not os.path.exists(f'./run/webSite/{netloc_}'):
os.mkdir(f'./run/webSite/{netloc_}')
filename = re.compile(r'[\\/](?P<group>[^\\/?]+)(?:\?|$)').search(ts_url).group('group').replace('.js', '')[
0:-8] + '.js'
# print(filename)
with open(f'./run/webSite/{netloc_}/{filename}', 'w', encoding='utf-8') as f:
f.write(ts_resp)
b64conent = base64.b64encode(response.content)
resp_ = requests.post('######/cookie',
data={'boUrl': url, 'boHtml': b64conent, 'apiUrl': apiUrl, 'pageNum': pageNum,
'itemId': itemId, 'timestamp': timestamp,'searchValue':searchValue}).json()
# print(resp_)
cookie_dict = dict(item.split('=') for item in resp_['cookie'].split('; '))
for cookie_name, cookie_value in cookie_dict.items():
session.cookies.set(cookie_name, cookie_value)
resp2 = session.get(url)
# data = {
# 'searchParamModel': '{"ObjectType":1,"SearchKeyList":[],"SearchExpression":null,"BeginYear":null,"EndYear":null,"UpdateTimeType":null,"JournalRange":null,"DomainRange":null,"ClusterFilter":"","ClusterLimit":0,"ClusterUseType":"Article","UrlParam":"K=计算机","Sort":"0","SortField":null,"UserID":"10615816","PageNum":"200","PageSize":20,"SType":null,"StrIds":null,"IsRefOrBy":0,"ShowRules":" 关键词=计算机 ","IsNoteHistory":0,"AdvShowTitle":null,"ObjectId":null,"ObjectSearchType":0,"ChineseEnglishExtend":0,"SynonymExtend":0,"ShowTotalCount":568287,"AdvTabGuid":""}',
# }
# response3 = session.post(resp_['rsurl'], headers=headers,data=data)
if timestamp != '111':
print('entry')
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'enable_NfBCSins2Oyw=true; NfBCSins2OywO=60JodeCUOoayQbpx7sBsVDV5dIhyn8Kvz52PZMTXbPvV8wGUlXeGfk28g7JgH_vosJwuh7ctdKpwkTvlMQZFx33G; STEP_TIPS_INDEX=true; STEP_TIPS_RESULT=true; arialoadData=true; token=; acw_tc=276aedc117179475002218113e1ca83526bfeb1a766f5473058b13f2616d1a; NfBCSins2OywP=0yg7MTucTPtzsOmQxbRS2eD5EOg9ALKnnT8E0stQRs_i4lENCm1L.d_zJOBmuAz339Mpj0TgN8Q4oZJfvJAGpVZYjdoYxEByJAMJT2MkdnC.CZ5G41._8QursSYsUKqcbM9fjXN_3s0Turu43ZkJVLlC4WwSMnY2cpSQdGG.wkkui.NUuMUAb4AggSm11RU4S8sQG9ySmL5BTKsnT7tGewLDsNLDCh73yBC4Mi8lnr.TTsl3P.9mfvfBOfv6a_S.djZ1bZvZTUvt2wiN0d6DL3XJXHkSzH9rDjVcksa6xdG29jJ1GEbxp57Z3ffmrRM5FRUmuJMKKvDvSJlPXh_QHV3i89nN_nTzDBeR_8JKQfVG',
'Pragma': 'no-cache',
'Referer': "",
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sign': resp_['sign'],
'timestamp': str(timestamp),
'token': 'false',
}
response3 = session.get(
resp_['rsurl'],
headers=headers,
)
return json.loads(response3.text)
response3 = session.get(
resp_['rsurl'],
headers=headers,
)
print("end")
return response3.headers['Date']5.结果