文章目录
- 1. C++11 简介
- 2. 常见的c++11特性
- 3.统一的列表初始化
- 3.1initializer_list
- 4. decltype与auto
- 4.1decltype与auto的区别
- 5.nullptr
- 6.右值引用和移动语义
- 6.1左值和右值
- 6.1.1左值的特点
- 6.1.2右值的特点
- 6.1.3右值的进一步分类
- 6.2左值引用和右值引用以及区别
- 6.2.1左值引用
- 6.2.2左值引用总结
- 6.2.3右值引用
- 6.2.4右值引用总结
- 6.2.5move函数
- 6.3右值引用的使用场景及其作用
- 6.3.1移动语义
- 6.3.2移动构造
- 6.3.3移动赋值函数
- 6.3.4右值本身也是一个左值
- 6.3.5STL容器中的移动构造和移动赋值
- 6.4完美转发
- 6.4.1完美转发的介绍
- 6.4.2forward函数的使用
- 7.新的类功能
- 7.1c++11新增了两个默认成员函数
- 7.2delete和dault
- 7.3final和override关键字
1. C++11 简介
c++11,即2011年发布的新c++标准。相比于c++98和03,c++11带来了很多变化,其中包含了约140多个新特性,以及对c++03标准中大约600多个缺陷的修正。这使得c++11更像是一个从c++98/03孕育出来的一个新版本。对比于之前的版本,c++11能更好的用于系统开发和库开发、语法更加的泛华和简单化、更加稳定和安全,不仅功能更加强大,而且能提升程序员的开发效率。这也是我们学习c++11的重要原因。下面介绍常见的一些c++11特性。
2. 常见的c++11特性
- 列表初始化
- 变量类型推导
- auto
- decltype
- 范围for循环
- final与override
- 智能指针
- 新增加容器—静态数组array、forward_list以及unordered系列
- 默认成员函数控制
- 右值引用
- lambda表达式
- 包装器
- 线程库
3.统一的列表初始化
使用列表对数组或者结构体进行初始化在c++98就已经被支持使用了,例如:
struct Point
{
int _x;
int _y;
};
int main()
{
int array1[] = { 1, 2, 3, 4, 5 };
int array2[5] = { 0 };
Point p = { 1, 2 };
return 0;
}
但是c++98的列表初始化局限于对数组和聚合类型的初始化,限制比较多,且不支持类型推导。c++11扩大了用{}(初始化列表)的使用范围,使得所有的内置类型和自定义类型都能以一种统一方式进行初始化,包括SL容器等。使用初始化列表时,可以添加等号也可以不添加,类似于构造声明。
struct Point
{
int _x;
int _y;
};
int main()
{
int x1 = 1;
int x2{ 2 };
int array1[]{ 1, 2, 3, 4, 5 };
int array2[5]{ 0 };
Point p{ 1, 2 };
// C++11中列表初始化也可以适用于new表达式中
int* pa = new int[4]{ 0 };
return 0;
}
自定义类型能支持列表初始化的原因是因为,在其类体中重载了以初始化列表类模板为参数的构造函数。以至于我们能直接使用{}构造一个对象。
3.1initializer_list
initializer_list是一个C++11提供的一个轻量级容器,专门用来接收{}内的初始化列表。本质上是一个类模板,由于模板的特性,在构造initializer_list类时,会自动推导{}里的类型,从而完成对自定义类型的构造。这个容器其实在我之前的文章里有介绍过: initializer_list的介绍。
下面给出一个伪代码样例:
vector(initializer_list<T> l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
typename initializer_list<T>::iterator lit = l.begin();
while (lit != l.end())
{
*vit++ = *lit++;
}
//for (auto e : l)
// *vit++ = e;
}
上面自定义的vector类重载了以initializer_list模板为参数的一个构造函数,有了这个构造函数之后,就能使用{}的方式对自定义类型进行构造。分析下面代码构造过程:
vector<int> a = { 1,2,3 };
- 编辑器先是根据{}构造出一个initializer_list对象,然后再调用vector类的构造函数。
4. decltype与auto
decltype关键字是一个类型推导工具,可以将变量的类型声明为表达式指定的类型,比如:
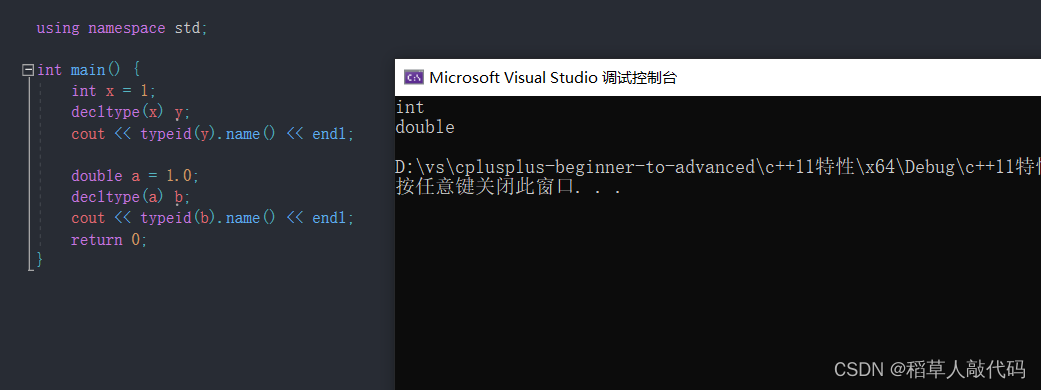
decltype表达式的基本用法就是后面跟上一个括号,编译器会自动推导出括号里面表达式的类型,但不执行该表达式。
4.1decltype与auto的区别
auto也是一个c++11更新的一个特性,也能用来做类型的推导,但是和decltype有很多不一样的地方:
- auto 忽略表达式的引用性质,而是推导出一个干净的类型。
- decltype完全保留表达式的类型,包括const属性和引用属性。
思考以下代码:
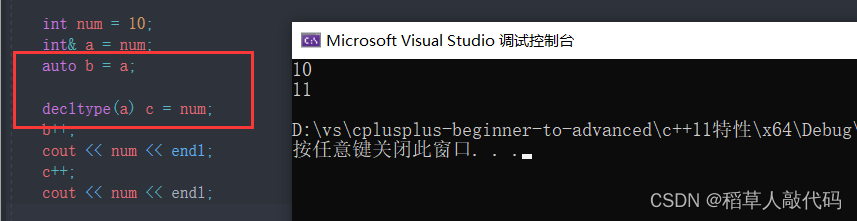
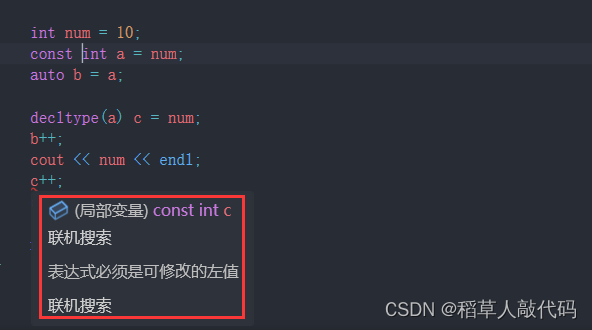
我们发现,auto并没有推导出引用属性,所以变量b++之后并不会影响num,本质上b只是一个int类型。而decltype能推导出引用属性,所以变量c实际上是一个int&类型,自增之后会影响num。这样证明了decltype推导类型比auto更为准确。同样,const类型的推导也是如此:
5.nullptr
nullptr是c++11新出的一个专门用来表示空属性的一个关键字。关于nullptr与NULL的区别,我在之前的文章中有介绍过。这里就不过多介绍。
6.右值引用和移动语义
6.1左值和右值
左值(Lvalue)和右值(Rvalue)不单单是指某个变量的属性,而是可以用来描述表达式的属性。
- 左值的定义:左值是具有持久存储位置的表达式。换句话说,左值是指那些在内存中具有明确地址的对象,且这个地址持久不变。左值可以出现在赋值表达式的左侧或者右侧。最直观的理解就是左值能用&取出地址。
- 右值的定义: 右值和左值相反,是指不具有持久存储位置的表达式。 右值通常都是临时的,生命周期非常短,比如匿名对象等临时值。最直观的理解就是右值不能用&取出地址。
给出代码样例观察对左值和右值取地址:
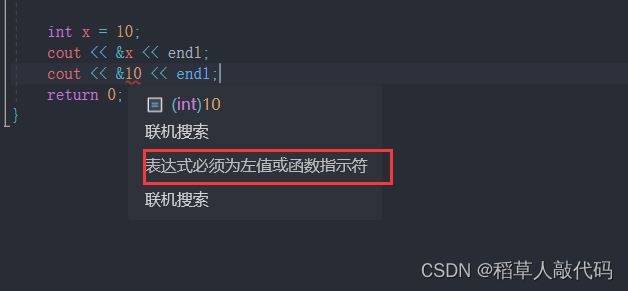
我们可以看到,由于10是一个字面量即右值,不能对其取地址。编译器也提示&只能对左值取地址。
6.1.1左值的特点
- 可以用&取地址
- 通常表示对象的身份如变量名
6.1.2右值的特点
- 不能用&取出地址
- 只能在赋值表达式的右边
- 表示的是数据的值,而不是身份
- 通常是临时值、字面量等
6.1.3右值的进一步分类
右值又可以分为存右值和将亡值:
- 纯右值:表示不对应任何对象的临时值,例如字面量或者表达式“1+2”这种。
- 将亡值:表示即将被摧毁、可以被移动的对象。
6.2左值引用和右值引用以及区别
6.2.1左值引用
左值引用使用一个&表示,通常只能绑定给左值。下面给出常见的左值引用左值的例子:
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}
6.2.2左值引用总结
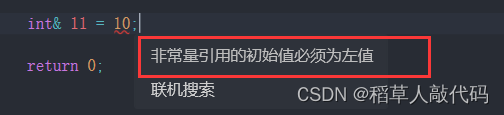
-
左值引用只能引用左值,不能引用右值,比如
-
const左值引用可以引用右值

-
不能延长临时对象的生命周期,可能会导致悬空引用。
int& getTemporary() {
int temp = 10;
return temp; // 返回局部变量的引用
}
int main() {
int& ref = getTemporary(); // 悬空引用
std::cout << "ref: " << ref << std::endl; // 未定义行为
return 0;
}
6.2.3右值引用
右值引用通常只能绑定右值,使用两个连续的&&表示。下面给出右值引用右值的几个例子:
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
return 0;
}
对于右值引用绑定常量右值,必须使用const修饰符,这样引用的内容是不会被修改的。如果右值引用绑定非常量右值,我们是可以修改其内容的:
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; // 报错
return 0;
}
6.2.4右值引用总结
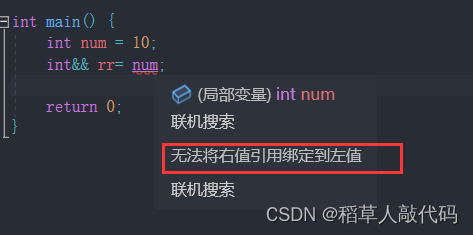
-
右值引用只能引用右值,不能引用左值,比如:
-
右值引用可以引用move以后的左值,比如

-
右值本身也是一个左值
-
右值引用是实现移动语义的关键,这一点下面会具体解释
-
右值引用能延长临时对象的生命周期,这一点下面也会具体解释
6.2.5move函数
move函数是c++标准提供的一个库函数,用于将左值转换为右值引用
6.3右值引用的使用场景及其作用
右值引用是为了提高程序性能和优化资源管理而设计的,以下是右值引用常见的场景及其作用:
6.3.1移动语义
在c++98中,当对象被传递,返回或者赋值时通常会进行深拷贝。对于一些比较大的对象,这种拷贝操作就非常耗时且低效。比如:
#include <iostream>
#include <cstring> // For memcpy
class Buffer {
public:
size_t size;
int* data;
// 构造函数
Buffer(size_t s=10) : size(s), data(new int[s]) {
std::cout << "构造 " << size * sizeof(int) << " bytes" << std::endl;
}
// 复制构造函数
Buffer(const Buffer& other) : size(other.size), data(new int[other.size]) {
std::memcpy(data, other.data, size * sizeof(int));
std::cout << "拷贝构造 " << size * sizeof(int) << " bytes" << std::endl;
}
// 析构函数
~Buffer() {
delete[] data;
std::cout << "析构 " << size * sizeof(int) << " bytes" << std::endl;
}
};
void processBuffer(Buffer buf) {
// 对缓冲区进行处理
}
int main() {
Buffer buf1(100);
processBuffer(buf1); // 调用复制构造函数
return 0;
}
在上述例子中,将buf1传给processBuffer函数时,会调用拷贝构造,这导致整个对象都被多拷贝一次,浪费了资源:

为了避免类似上述情况这种不必要的拷贝,c++11提出了移动语义。即不拷贝资源,而是“移动”资源。
移动语义通过引入右值引用来实现。右值引用允许我们区分那些可以被移动的资源,从而避免不必要的复制。那么怎样通过右值引用来实现移动语义呢?移动构造函数和移动赋值函数是实现移动语义的核心机制。下面介绍移动构造函数和移动赋值函数。
6.3.2移动构造
移动构造和普通的拷贝构造的区别在于,普通的拷贝构造的参数是同类对象的左值引用,而移动构造的参数是同类对象的右值引用。移动构造的功能是为了实现资源的移动而不是复制。结合上面的例子,给出一个Buffer类的移动构造函数:
// 移动构造函数
Buffer(Buffer&& other) : size(other.size), data(other.data) {
other.size = 0;
other.data = nullptr;
std::cout << "移动构造 " << size * sizeof(int) << " bytes" << std::endl;
}
拷贝构造:
// 复制构造函数
Buffer(const Buffer& other) : size(other.size), data(new int[other.size]) {
std::memcpy(data, other.data, size * sizeof(int));
std::cout << "拷贝构造 " << size * sizeof(int) << " bytes" << std::endl;
}
对比移动构造和拷贝构造,我们发现,调用移动构造函数并没有重新开辟空间,而是移动了指向资源的指针,使得构造出来的对象占有参数对象的资源。通过移动构造,往后我们在使用匿名对象这种右值构造对象时,就不会再去拷贝一份一模一样的资源,而是直接使用匿名对象的资源。这也能理解为什么说右值引用能延长将亡对象的生命周期。
将移动构造函数加入到Buffer类中,继续上面代码的运行观察结构:
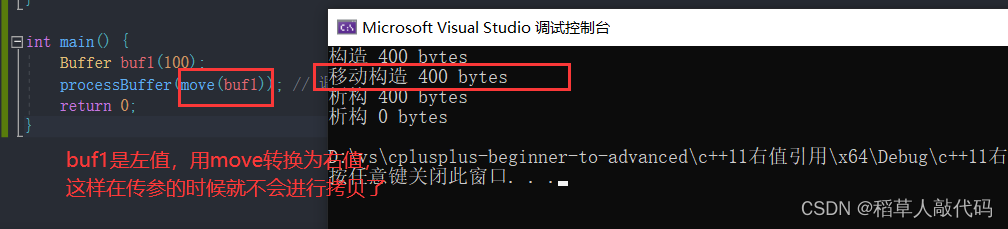
显然,在传参的过程中确实没有进行拷贝,这也是为什么说移动语义能优化效率的原因:不拷贝资源,只移动资源。移动的动作由移动构造和移动赋值函数完成,而移动构造和移动赋值函数又依赖于右值引用。值得注意的是,由于移动了资源,原来拥有这些资源的对象就不能再使用这些资源了。
6.3.3移动赋值函数
移动赋值函数其实就是重载了一个赋值运算符,只不过跟移动构造类似,移动赋值函数同样依赖于右值引用。传统的赋值运算重载其实就是一次深拷贝,而移动赋值运算符重载允许在对象赋值时,通过转移资源而不是复制资源来实现赋值操作。
对于上述代码样例添加重载赋值运算符函数,并提供移动赋值版本和普通赋值版本:
//移动赋值
Buffer& operator=(Buffer&& other) {
if (this != &other) {
delete[] data;//释放当前资源
size = other.size;
data = other.data;
other.data = nullptr;
other.size = 0;
cout << "移动赋值" << endl;
}
return *this;
}
//传统赋值拷贝
Buffer& operator=(const Buffer& other) {
if (this != &other) {
Buffer temp(other);//构造一个临时对象
delete[] data;//释放自己的资源
swap(temp.data, data);
swap(size, temp.size);
}
return *this;
}
左值赋值演示:
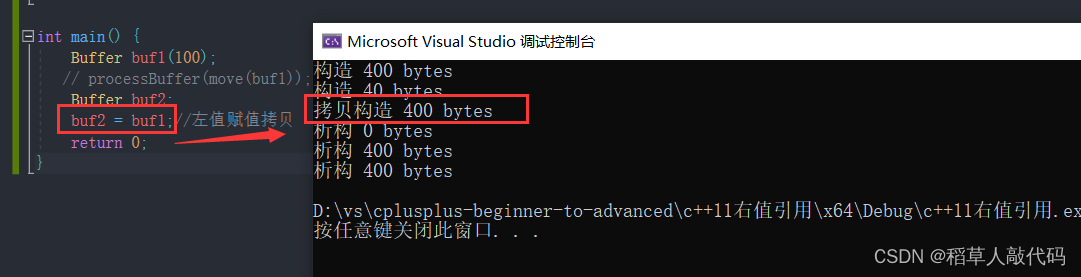
右值赋值演示:
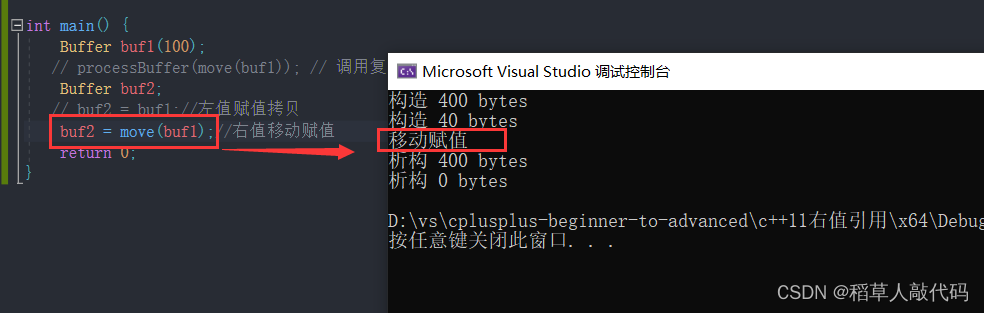
当使用左值赋值时调用的是传统的赋值拷贝,而实现了移动赋值运算符函数后,我们用右值赋值给对象时,将buf1的资源转移给buf2,中间没有深拷贝。值得注意的是,由于将资源给了buf2,buf1将不再拥有之前的资源。
6.3.4右值本身也是一个左值
所有的引用在c++中都是左值,右值引用本身也是一个左值。这是因为右值引用本身也是一个具有名称和地址的变量,只不过引用的是一个右值。可以理解为,要想使用右值的资源就需要一个具有地址的载体。思考下面例子:
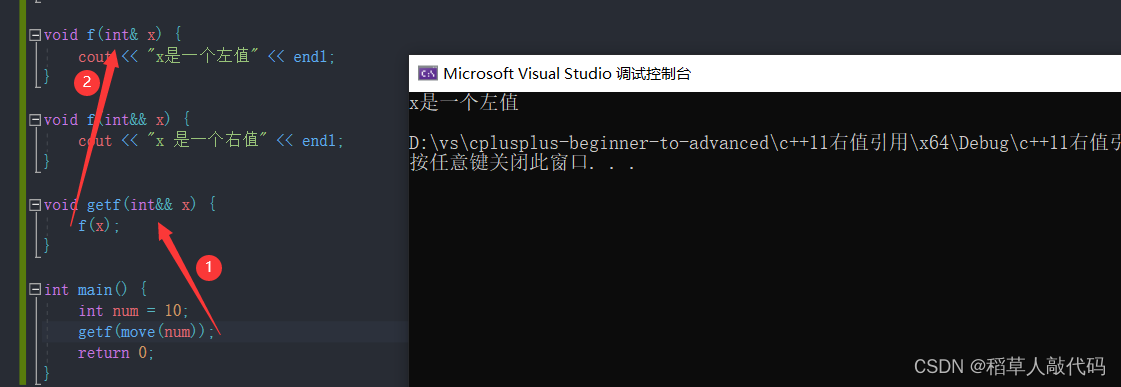
我们可以看到,在getf函数中x是一个右值引用变量,因为右值引用本身也是一个左值,于是调用了左值的f函数版本。
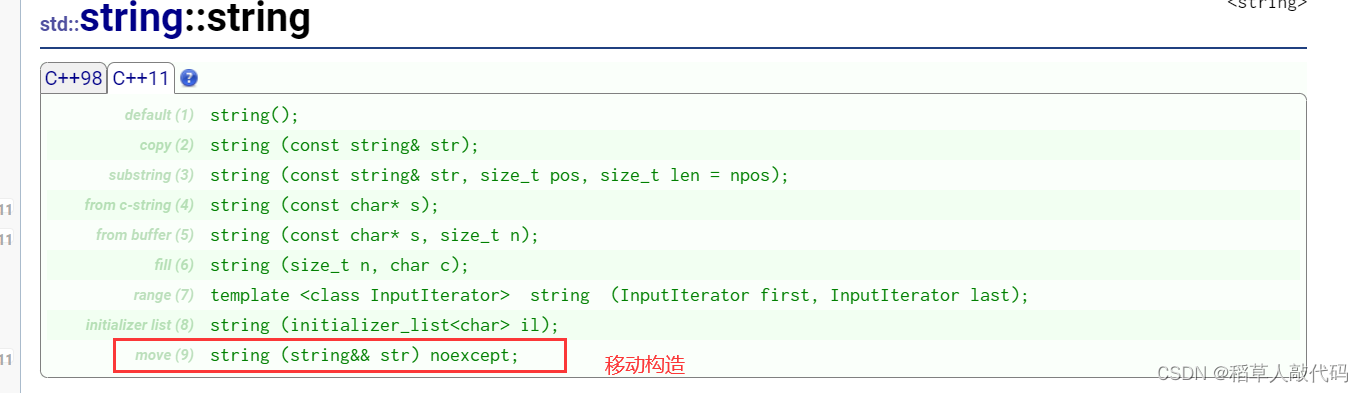
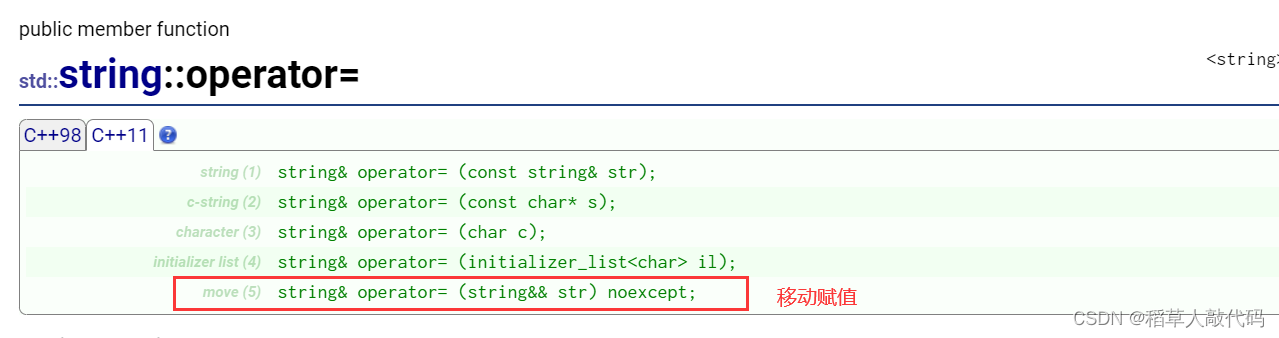
6.3.5STL容器中的移动构造和移动赋值
有了移动语义之后,c++11给STL容器都添加了移动构造和移动赋值函数,在cplusplus网站中可以看到这些函数的声明:
6.4完美转发
思考下面代码样例:
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)//T为万能引用
{
Fun(t);
}
int main()
{
PerfectForward(10); //右值
int a;
PerfectForward(a); //左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); //const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
为了能更好的将右值引用结合到模板中,c++11提供了万能引用这一概念。万能引用用于模板编程,可以绑定到任何类型的值,无论是右值还是左值。这也就使得模能支持实现移动语义。可是当我们运行上面的代码:
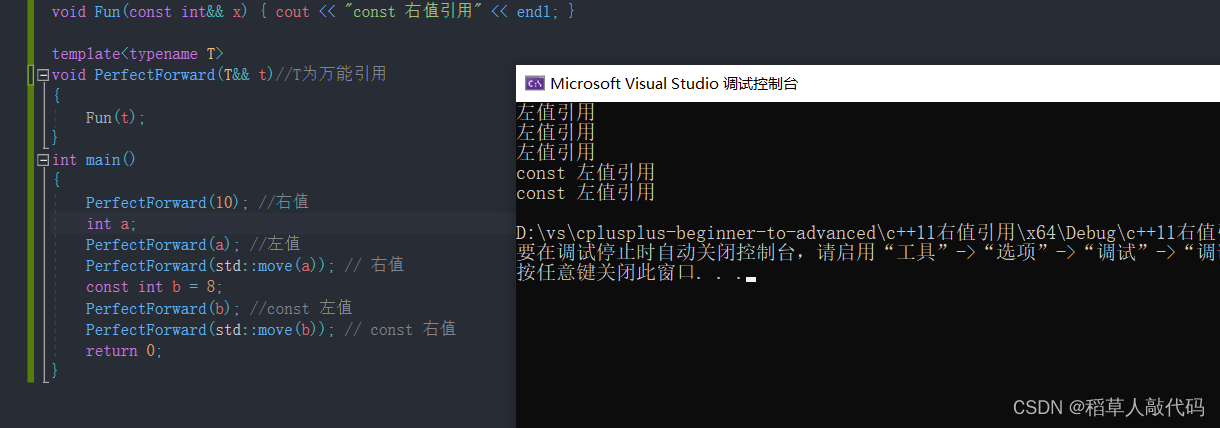
即使编译器能通过万能引用推断出PerfectForward函数参数是左值引用还是右值引用,可是由于右值引用本身也是一个左值,只会调用左值版本的Fun函数。也就是说另一个函数并不能识别左值引用和右值引用,统统当左值处理。那如何使左值引用和右值引用匹配到正确的函数呢?这里的正确性是指达到我们想要的目的,即传递右值引用调用右值版本的Fun函数。完美转发就可以很好的解决这一问题。
6.4.1完美转发的介绍
完美转发是C++11引入的一种技术,用于在模板函数中将参数完美的转发给另一个函数,无论是左值还是右值。完美转发的机制依赖于两个概念:
-
右值引用折叠:其实就是万能引用的机制,在模板实例化时两个 引用类型的组合如何折叠成最终的类型,具体的折叠方式有以下几种:
T& &和T& &&折叠成T&T&& &和T&& &&折叠成T&&
-
forward函数:用于实现完美转发。
6.4.2forward函数的使用
针对上面的代码样例,使用forward函数实现完美转发:
template<typename T>
void PerfectForward(T&& t)//T为万能引用
{
Fun(forward<T>(t));
}
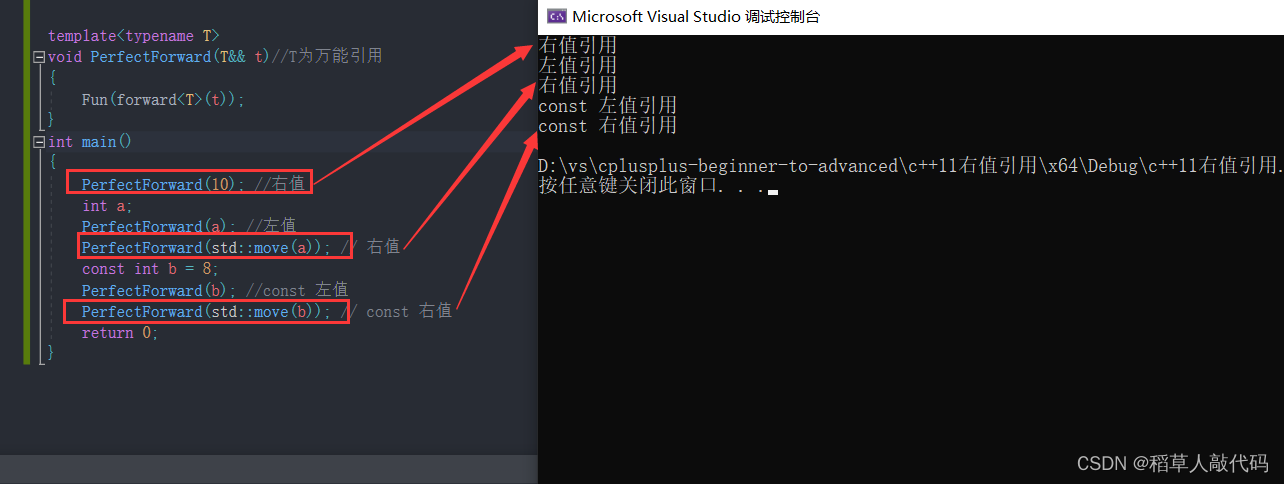
PerfectForward函数模板接受一个·万能引用T&&,并使用forward将参数完美的转发给Fun函数。
7.新的类功能
原来的c++类中有 六个默认成员函数:
- 构造
- 拷贝构造
- 析构
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
7.1c++11新增了两个默认成员函数
- 移动构造函数
- 移动赋值运算符重载
编译器会在以下条件下 自动生成移动构造函数和移动赋值运算符重载:
- 移动构造函数:如果在类中没有显式定义移动构造、拷贝构造、拷贝赋值重载、移动赋值重载或者析构中的任何一个,编译器就会自动生成一个默认的移动构造函数。默认生成的移动构造函数,对于内置类型进行浅拷贝,对于自定义类型有则调用其移动构造,没有则调用其拷贝构造。
- 移动赋值重载:如果在类中没有显示实现移动赋值重载、拷贝构造、拷贝赋值重载中的任意一个·,那么编译器会自动生成一个移动赋值重载函数。默认生成的移动赋值重载函数,对于内置类型进行浅拷贝。对于自定义类型有则调用其移动赋值重载函数,无则调用其拷贝赋值重载函数。
7.2delete和dault
如果不想让编译器自动生成默认函数,可以在该函数后面添加=delete,该语法指示编译器不再生成该函数的默认版本。
比如:
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p) = delete;//编译器不再自动生成拷贝构造函数
private:
bit::string _name;
int _age;
};
相反default关键字则是告诉编译器强制生成默认版本函数,比如:
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p) = default;//强制生成拷贝构造函数
private:
bit::string _name;
int _age;
};
7.3final和override关键字
- final:可以用来修饰类与虚函数。修饰虚函数,表示该虚函数不能被重写。修饰类,则表示该类不能被继承。
- override:检查派生类虚函数是否重写了基类某个虚函数,如果没有重写编译报错
具体用法在之前关于继承多态那一章博客里有介绍:一眼就爱上了多态