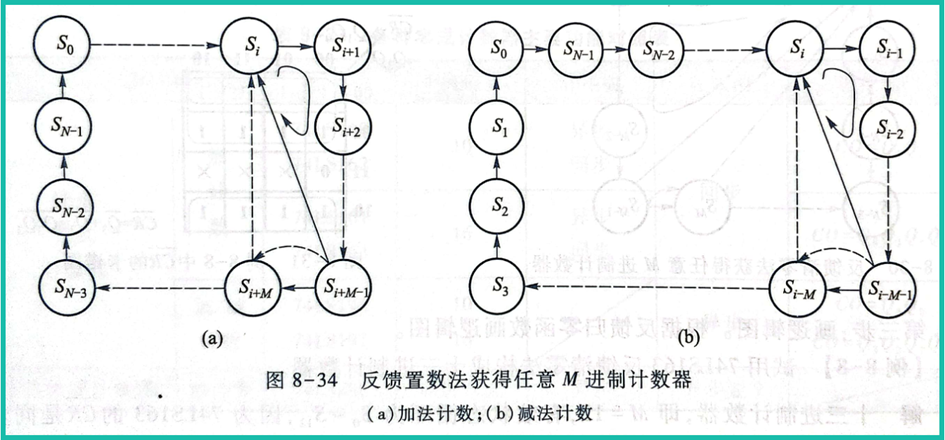
多种预训练任务解决NLP处理SMILES的多种弊端,代码:Knowledge-based-BERT,原文:Knowledge-based BERT: a method to extract molecular features like computational chemists,代码解析继续K_BERT_WCL_pretrain。模型框架如下:

文章目录
- 1.load_data_for_pretrain
- 1.1.build_pretrain_selected_tasks
- 1.2.build_maccs_pretrain_data_and_save
- 2.loss
- 3.K_BERT_WCL
args['pretrain_data_path'] = '../data/pretrain_data/CHEMBL_maccs'
pretrain_set = build_data.load_data_for_pretrain(
pretrain_data_path=args['pretrain_data_path'])
print("Pretrain data generation is complete !")
pretrain_loader = DataLoader(dataset=pretrain_set,
batch_size=args['batch_size'],
shuffle=True,
collate_fn=collate_pretrain_data)
1.load_data_for_pretrain
def load_data_for_pretrain(pretrain_data_path='./data/CHEMBL_wash_500_pretrain'):
tokens_idx_list = []
global_labels_list = []
atom_labels_list = []
atom_mask_list = []
for i in range(80):
pretrain_data = np.load(pretrain_data_path+'_{}.npy'.format(i+1), allow_pickle=True)
tokens_idx_list = tokens_idx_list + [x for x in pretrain_data[0]]
global_labels_list = global_labels_list + [x for x in pretrain_data[1]]
atom_labels_list = atom_labels_list + [x for x in pretrain_data[2]]
atom_mask_list = atom_mask_list + [x for x in pretrain_data[3]]
print(pretrain_data_path+'_{}.npy'.format(i+1) + ' is loaded')
pretrain_data_final = []
for i in range(len(tokens_idx_list)):
a_pretrain_data = [tokens_idx_list[i], global_labels_list[i], atom_labels_list[i], atom_mask_list[i]]
pretrain_data_final.append(a_pretrain_data)
return pretrain_data_final
- 和之前的load_data_for_contrastive_aug_pretrain一模一样,只是最后文件载入的不一样,没有_contrastive_,文件是在build_pretrain_selected_tasks中构造的
1.1.build_pretrain_selected_tasks
from experiment.build_data import build_maccs_pretrain_data_and_save
import multiprocessing
import pandas as pd
task_name = 'CHEMBL'
if __name__ == "__main__":
n_thread = 8
data = pd.read_csv('../pretrain_data/'+task_name+'.csv')
smiles_list = data['smiles'].values.tolist()
# 避免内存不足,将数据集分为10份来计算
for i in range(10):
n_split = int(len(smiles_list)/10)
smiles_split = smiles_list[i*n_split:(i+1)*n_split]
n_mol = int(len(smiles_split)/8)
# creating processes
p1 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[:n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+1)+'.npy'))
p2 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[n_mol:2*n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+2)+'.npy'))
p3 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[2*n_mol:3*n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+3)+'.npy'))
p4 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[3*n_mol:4*n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+4)+'.npy'))
p5 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[4*n_mol:5*n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+5)+'.npy'))
p6 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[5*n_mol:6*n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+6)+'.npy'))
p7 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[6*n_mol:7*n_mol],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+7)+'.npy'))
p8 = multiprocessing.Process(target=build_maccs_pretrain_data_and_save, args=(smiles_split[7*n_mol:],
'../data/pretrain_data/'+task_name+'_maccs_'+str(i*8+8)+'.npy'))
# starting my_scaffold_split 1&2
p1.start()
p2.start()
p3.start()
p4.start()
p5.start()
p6.start()
p7.start()
p8.start()
# wait until my_scaffold_split 1&2 is finished
p1.join()
p2.join()
p3.join()
p4.join()
p5.join()
p6.join()
p7.join()
p8.join()
# both processes finished
print("Done!")
- 和之前的一样,只是调用的函数不同,这里是build_maccs_pretrain_data_and_save,这里文件没有 _5_contrastive_aug,应该只有一个smiles列
1.2.build_maccs_pretrain_data_and_save
def build_maccs_pretrain_data_and_save(smiles_list, output_smiles_path, global_feature='MACCS'):
smiles_list = smiles_list
tokens_idx_list = []
global_label_list = []
atom_labels_list = []
atom_mask_list = []
for i, smiles in enumerate(smiles_list):
tokens_idx, global_labels, atom_labels, atom_mask = construct_input_from_smiles(smiles,
global_feature=global_feature)
if tokens_idx != 0:
tokens_idx_list.append(tokens_idx)
global_label_list.append(global_labels)
atom_labels_list.append(atom_labels)
atom_mask_list.append(atom_mask)
print('{}/{} is transformed!'.format(i+1, len(smiles_list)))
else:
print('{} is transformed failed!'.format(smiles))
pretrain_data_list = [tokens_idx_list, global_label_list, atom_labels_list, atom_mask_list]
pretrain_data_np = np.array(pretrain_data_list)
np.save(output_smiles_path, pretrain_data_np)
- 读入的smiles只有一个,与之前调用的函数一样
2.loss
global_pos_weight = torch.tensor([884.17, 70.71, 43.32, 118.73, 428.67, 829.0, 192.84, 67.89, 533.86, 18.46, 707.55, 160.14, 23.19, 26.33, 13.38, 12.45, 44.91, 173.58, 40.14, 67.25, 171.12, 8.84, 8.36, 43.63, 5.87, 10.2, 3.06, 161.72, 101.75, 20.01, 4.35, 12.62, 331.79, 31.17, 23.19, 5.91, 53.58, 15.73, 10.75, 6.84, 3.92, 6.52, 6.33, 6.74, 24.7, 2.67, 6.64, 5.4, 6.71, 6.51, 1.35, 24.07, 5.2, 0.74, 4.78, 6.1, 62.43, 6.1, 12.57, 9.44, 3.33, 5.71, 4.67, 0.98, 8.2, 1.28, 9.13, 1.1, 1.03, 2.46, 2.95, 0.74, 6.24, 0.96, 1.72, 2.25, 2.16, 2.87, 1.8, 1.62, 0.76, 1.78, 1.74, 1.08, 0.65, 0.97, 0.71, 5.08, 0.75, 0.85, 3.3, 4.79, 1.72, 0.78, 1.46, 1.8, 2.97, 2.18, 0.61, 0.61, 1.83, 1.19, 4.68, 3.08, 2.83, 0.51, 0.77, 6.31, 0.47, 0.29, 0.58, 2.76, 1.48, 0.25, 1.33, 0.69, 1.03, 0.97, 3.27, 1.31, 1.22, 0.85, 1.75, 1.02, 1.13, 0.16, 1.02, 2.2, 1.72, 2.9, 0.26, 0.69, 0.6, 0.23, 0.76, 0.73, 0.47, 1.13, 0.48, 0.53, 0.72, 0.38, 0.35, 0.48, 0.12, 0.52, 0.15, 0.28, 0.36, 0.08, 0.06, 0.03, 0.07, 0.01])
atom_pos_weight = torch.tensor([4.81, 1.0, 2.23, 53.49, 211.94, 0.49, 2.1, 1.13, 1.22, 1.93, 5.74, 15.42, 70.09, 61.47, 23.2])
loss_criterion_global = torch.nn.BCEWithLogitsLoss(reduction='none', pos_weight=global_pos_weight.to('cuda'))
loss_criterion_atom = torch.nn.BCEWithLogitsLoss(reduction='none', pos_weight=atom_pos_weight.to('cuda'))
- loss与之前一致
3.K_BERT_WCL
model = K_BERT_WCL(d_model=args['d_model'], n_layers=args['n_layers'], vocab_size=args['vocab_size'],
maxlen=args['maxlen'], d_k=args['d_k'], d_v=args['d_v'], n_heads=args['n_heads'], d_ff=args['d_ff'],
global_label_dim=args['global_labels_dim'], atom_label_dim=args['atom_labels_dim'])
class K_BERT_WCL(nn.Module):
def __init__(self, d_model, n_layers, vocab_size, maxlen, d_k, d_v, n_heads, d_ff, global_label_dim, atom_label_dim,
use_atom=False):
super(K_BERT_WCL, self).__init__()
self.maxlen = maxlen
self.d_model = d_model
self.use_atom = use_atom
self.embedding = Embedding(vocab_size, self.d_model, maxlen)
self.layers = nn.ModuleList([EncoderLayer(self.d_model, d_k, d_v, n_heads, d_ff) for _ in range(n_layers)])
if self.use_atom:
self.fc = nn.Sequential(
nn.Dropout(0.),
nn.Linear(self.d_model + self.d_model, self.d_model),
nn.ReLU(),
nn.BatchNorm1d(self.d_model))
self.fc_weight = nn.Sequential(
nn.Linear(self.d_model, 1),
nn.Sigmoid())
else:
self.fc = nn.Sequential(
nn.Dropout(0.),
nn.Linear(self.d_model, self.d_model),
nn.ReLU(),
nn.BatchNorm1d(self.d_model))
self.classifier_global = nn.Linear(self.d_model, global_label_dim)
self.classifier_atom = nn.Linear(self.d_model, atom_label_dim)
def forward(self, input_ids):
output = self.embedding(input_ids)
enc_self_attn_mask = get_attn_pad_mask(input_ids)
for layer in self.layers:
output = layer(output, enc_self_attn_mask)
h_global = output[:, 0]
if self.use_atom:
h_atom = output[:, 1:]
h_atom_weight = self.fc_weight(h_atom)
h_atom_weight_expand = h_atom_weight.expand(h_atom.size())
h_atom_mean = (h_atom*h_atom_weight_expand).mean(dim=1)
h_mol = torch.cat([h_global, h_atom_mean], dim=1)
else:
h_mol = h_global
h_embedding = self.fc(h_mol)
logits_global = self.classifier_global(h_embedding)
return logits_global
-
只有分子水平的global一个任务,没有对比学习任务,也没有原子特征水平的global任务
-
其他部分差不多,这里不在详细分析