⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。
如果觉得本文能帮到您,麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
Qt5.9专栏定期更新Qt的一些项目Demo
项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。

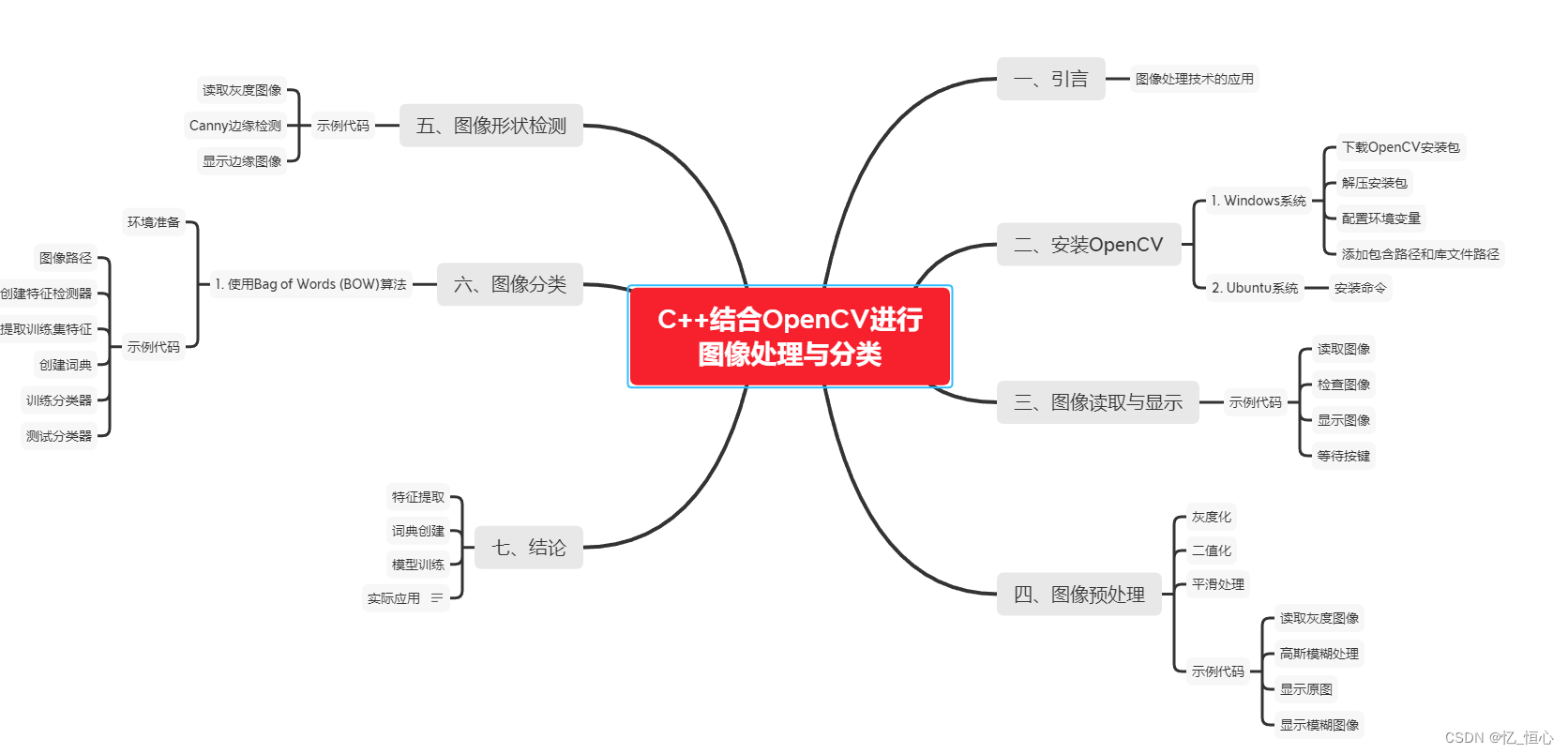
一、引言
在当今数字化时代,图像处理技术在各个领域得到了广泛应用。无论是自动驾驶、医学影像分析,还是安防监控、虚拟现实,图像处理都扮演着重要角色。OpenCV(Open Source Computer Vision Library)作为一个开源的计算机视觉库,提供了丰富的图像处理函数和工具,使得图像处理变得更加简单和高效。本文将介绍如何使用C++结合OpenCV进行基础的图像处理操作。
在C++领域中,openCV同时也是使用yolo的必备配置环境。
结合yolo可以完成图像分类和目标检测
除了进行目标检测,也可以将这个应用在图像分类中。
使用C++实现YOLO图像分类:从环境搭建到性能评估的完整指南


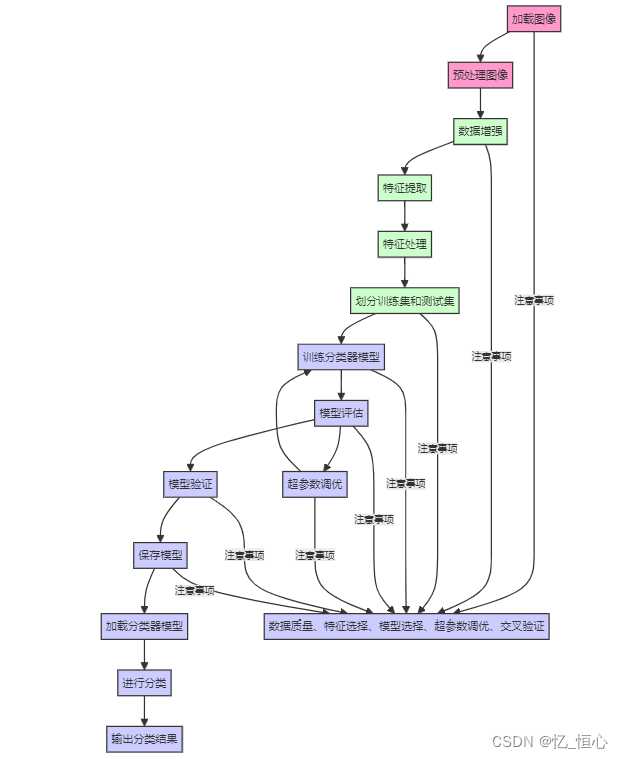
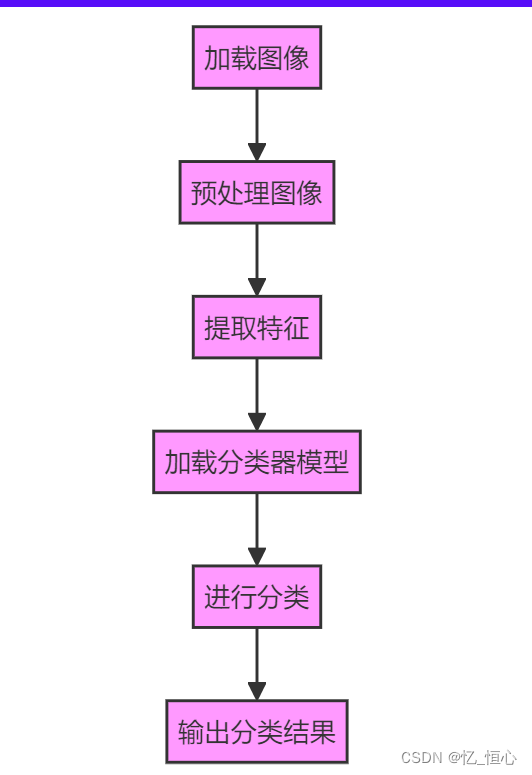
模型的图像分类的流程:
- 加载图像:从文件系统或其他来源加载图像数据。 预处理图像:对图像进行预处理操作,如缩放、归一化、去噪等,以便于后续处理。
- 特征提取:从图像中提取有意义的特征,如边缘、纹理、形状等。常用的方法包括SIFT、SURF、ORB等。
- 处理:对提取的特征进行处理,如特征选择、特征缩放等,以减少维度和提高分类器的性能。
- 加载分类器模型:加载预先训练好的分类器模型,如支持向量机(SVM)、神经网络、随机森林等。
- 进行分类:使用分类器对处理后的特征进行分类,得到图像的类别。 输出分类结果:将分类结果输出或展示。
二、 安装OpenCV
Windows系统详细的环境安装,可以参考我之前写的这一篇文章。
VS2019中配置C++ OpenCV 4.5.4完整指南
在使用OpenCV之前,我们需要先在开发环境中安装OpenCV库。以下是Windows和Ubuntu系统中安装OpenCV的基本步骤:
1. Windows系统:
- 下载OpenCV安装包:OpenCV官网
- 解压安装包到指定目录。
- 配置环境变量,将OpenCV的
bin目录添加到系统的PATH中。 - 在C++项目中添加OpenCV库的包含路径和库文件路径。
2. Ubuntu系统:
sudo apt update
sudo apt install libopencv-dev
三、 图像读取与显示
首先,我们来看一个简单的图像读取与显示的示例程序:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 读取图像
cv::Mat image = cv::imread("example.jpg");
// 检查图像是否读取成功
if(image.empty()) {
std::cout << "无法打开图像文件" << std::endl;
return -1;
}
// 显示图像
cv::imshow("Display Image", image);
cv::waitKey(0); // 等待按键按下
return 0;
}
在这个示例中,我们使用cv::imread函数读取一张图像,并使用cv::imshow函数显示图像。cv::waitKey(0)函数用于等待用户按键,以便窗口不会立即关闭。
四、 图像预处理
图像预处理是图像处理中的重要步骤,包括图像的灰度化、二值化、平滑处理等。以下是一个简单的图像预处理示例:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("example.jpg", cv::IMREAD_GRAYSCALE); // 读取灰度图像
if(image.empty()) {
std::cout << "无法打开图像文件" << std::endl;
return -1;
}
cv::Mat blurredImage;
cv::GaussianBlur(image, blurredImage, cv::Size(5, 5), 1.5); // 高斯模糊处理
cv::imshow("Original Image", image);
cv::imshow("Blurred Image", blurredImage);
cv::waitKey(0);
return 0;
}
在这个示例中,我们使用cv::imread函数以灰度模式读取图像,并使用cv::GaussianBlur函数对图像进行高斯模糊处理。
五、图像形状检测
OpenCV还提供了丰富的形状检测功能,例如边缘检测和轮廓检测。以下是一个简单的边缘检测示例:
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("example.jpg", cv::IMREAD_GRAYSCALE);
if(image.empty()) {
std::cout << "无法打开图像文件" << std::endl;
return -1;
}
cv::Mat edges;
cv::Canny(image, edges, 50, 150); // Canny边缘检测
cv::imshow("Edges", edges);
cv::waitKey(0);
return 0;
}
在这个示例中,我们使用cv::Canny函数进行边缘检测,并显示结果图像。
六、图像分类
图像分类是计算机视觉中的重要任务,常用于自动驾驶、安防监控、医疗诊断等领域。通过对图像内容进行分类,我们可以实现对不同类别物体的识别和区分。
1.1 使用Bag of Words (BOW)算法进行图像分类
Bag of Words (BOW)算法是一种经典的图像分类方法,通过将图像表示为特征词袋进行分类。下面是使用OpenCV和C++实现BOW算法进行图像分类的示例代码。
1.2 环境准备
首先,确保已安装OpenCV库,并配置好C++开发环境。需要安装额外的库如opencv_contrib,以便使用BOW相关模块。
1.3 示例代码
以下是实现BOW算法进行图像分类的代码:
#include <opencv2/opencv.hpp>
#include <opencv2/xfeatures2d.hpp>
#include <opencv2/ml.hpp>
#include <iostream>
#include <vector>
using namespace cv;
using namespace cv::ml;
using namespace std;
using namespace cv::xfeatures2d;
void extractFeatures(const vector<string>& imagePaths, vector<Mat>& features, Ptr<SIFT> detector) {
for (const auto& path : imagePaths) {
Mat image = imread(path, IMREAD_GRAYSCALE);
vector<KeyPoint> keypoints;
Mat descriptors;
detector->detectAndCompute(image, noArray(), keypoints, descriptors);
features.push_back(descriptors);
}
}
int main() {
// 图像路径
vector<string> trainImages = {"image1.jpg", "image2.jpg", "image3.jpg"};
vector<string> testImages = {"test1.jpg", "test2.jpg"};
// 创建SIFT特征检测器
Ptr<SIFT> detector = SIFT::create();
// 提取训练集特征
vector<Mat> trainFeatures;
extractFeatures(trainImages, trainFeatures, detector);
// 聚类,创建词典
BOWKMeansTrainer bowTrainer(100); // 词典大小
for (const auto& feature : trainFeatures) {
bowTrainer.add(feature);
}
Mat dictionary = bowTrainer.cluster();
// 创建BOW图像描述器
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create("FlannBased");
BOWImgDescriptorExtractor bowDE(detector, matcher);
bowDE.setVocabulary(dictionary);
// 训练分类器
Ptr<SVM> svm = SVM::create();
Mat trainData, labels;
for (size_t i = 0; i < trainImages.size(); ++i) {
Mat bowDescriptor;
bowDE.compute(imread(trainImages[i], IMREAD_GRAYSCALE), bowDescriptor);
trainData.push_back(bowDescriptor);
labels.push_back((float)i); // 假设每个图像都有不同的标签
}
svm->train(trainData, ROW_SAMPLE, labels);
// 测试分类器
for (const auto& path : testImages) {
Mat testImage = imread(path, IMREAD_GRAYSCALE);
Mat bowDescriptor;
bowDE.compute(testImage, bowDescriptor);
float response = svm->predict(bowDescriptor);
cout << "Image: " << path << " classified as: " << response << endl;
}
return 0;
}
result
Image: test1.jpg classified as: 0
Image: test2.jpg classified as: 1
七、适合图像分类的优秀的仓库
我可以为您提供一些图片的链接,您可以使用这些图片作为博客中的例子。以下是一些公共领域图片资源网站的链接,您可以从这些网站下载适合用于图像分类任务的图片:
-
Pixabay - 提供大量免费图片,适用于个人和商业用途。
- 链接: Pixabay
-
Unsplash - 一个提供高分辨率照片的平台,所有照片均可免费使用。
- 链接: Unsplash
-
Pexels - 提供免费且高质量的图片,可用于商业用途,无需署名。
- 链接: Pexels
-
Open Images Dataset - Google 提供的一个大规模图片数据集,可用于图像识别和分类。
- 链接: Open Images Dataset
- 链接: Open Images Dataset
-
MNIST Database - 手写数字的图片数据集,常用于图像分类和机器学习任务。
- 链接: MNIST Database


- 链接: MNIST Database
-
CIFAR-10 and CIFAR-100 - 包含多种类别的图片数据集,适用于图像分类。
- 链接: CIFAR-10/CIFAR-100
-
ImageNet - 一个非常大的图像数据库,用于视觉对象识别研究。
- 链接: ImageNet
-
Flickr - 通过Flickr的Creative Commons搜索,您可以找到许多可用于非商业或商业用途的图片。
- 链接: Flickr Creative Commons
-
Getty Images - 虽然Getty Images主要是版权图片,但它们也提供了一些免费图片的集合。
- 链接: Getty Images
-
NASA Image and Video Library - NASA提供的图片和视频资源,适合用于科学和教育目的。
- 链接: NASA Image and Video Library
请注意,使用图片时,您应遵守每个网站的使用条款和版权信息。对于商业用途,建议仔细检查图片的许可证,确保合法使用。
八、 结论
通过以上步骤,我们使用C++和OpenCV实现了基于BOW算法的图像分类。本文介绍了从特征提取、词典创建到模型训练和分类的全过程。这仅仅是图像分类的入门,OpenCV还支持更多复杂的算法和深度学习模型,读者可以进一步探索,以便在实际项目中更好地应用这些技术。希望本文对您在学习和应用图像分类技术方面有所帮助。
最后,最后
如果觉得有用,麻烦三连👍⭐️❤️支持一下呀,希望这篇文章可以帮到你,你的点赞是我持续更新的动力