查询性能优化
MySQL查询优化器的局限性
MySQL的万能"嵌套循环"并不是对每种查询都是最优的。不过还好,MySQL查询优化器只对少部分查询不适用,而且我们往往可以通过改写查询让MySQL高效地完成工作。还有一个好消息,MySQL5.6版本正式发布后,会消除很多MySQL原本的限制,让更多的查询能够以尽可能高的效率完成。
关联子查询
MySQL的子查询实现得非常糟糕。最糟糕的一类查询是WHERE条件中包含IN()的子查询语句。例如,我们希望找到Sakila数据库中,演员Penelope Guinness(他的actor_id为1)参演过的所有影片信息。很自然的,我们会按照下面的方式用子查询实现:
mysql> SELECT * FROM sakila.film WHERE film_id IN(SELECT film_id FROM sakila.film_actor WHERE actor_id =1);
因为MySQL对IN()列表的选项有专门的优化策略,一般会认为MySQL会先执行子查询返回所有包含actor_id为1的film_id。一般来说,IN()列表查询速度很快,所以我们会认为上面的查询会这样执行:
-- SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id=1;
-- Result :1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980
SELECT * FROM sakila.film WHERE film_id IN(1,23.....................,980);
很不幸,MySQL不是这样做的。MySQL会讲相关的外层表压到子查询中,它认为这样可以更高效率地查找到数据行。也就是说,MySQL会将查询改写成下面的样子:
SELECT * FROM sakila.film WHERE EXISTS (SELECT * FROM sakila.film_actor WHERE actor_id = 1 AND film_actor.film_id = film.film_id)
这时,子查询需要根据film_id来关联外部表film,因为需要film_id字段,所以MySQL认为无法先执行这个查询。通过EXPLAIN可以看到子查询是一个相关子查询(DEPENDENT SUBQUERY)(可以使用EXPLAIN EXTENDED来查看这个查询被改写成了什么样子)
mysql> EXPLAIN SELECT * FROM sakila.film WHERE EXISTS (SELECT * FROM sakila.film_actor WHERE actor_id = 1 AND film_actor.film_id = film.film_id)
-> ;
+----+--------------------+------------+------------+--------+------------------------+---------+---------+---------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+--------+------------------------+---------+---------+---------------------------+------+----------+-------------+
| 1 | PRIMARY | film | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | film_actor | NULL | eq_ref | PRIMARY,idx_fk_film_id | PRIMARY | 4 | const,sakila.film.film_id | 1 | 100.00 | Using index |
+----+--------------------+------------+------------+--------+------------------------+---------+---------+---------------------------+------+----------+-------------+
2 rows in set (0.10 sec)
根据EXPLAIN的输出我们可以看到,MySQL先选择对flim表进行全表扫描,然后根据返回的film_id逐个进行子查询。如果是一个很小的表,这个查询的糟糕的性能可能还不会引起注意,但是如果外层的表是一个非常大的表,那么这个查询的性能会非常糟糕。当然我们很容易用下面的办法来重写这个查询:
mysql>SELECT film.* FROM sakila.film INNER JOIN sakila.film_actor USING(film_id) WHERE actor_id = 1;
另一个优化的办法是使用函数GROUP_CONCAT()在IN()中构造一个由逗号分割的列表,有时这比上面的使用关联改写更快。因为使用IN()加子查询,性能经常会非常糟,所以通常建议使用EXISTS()等效的改写查询来获取更好的效率。下面是另一种改写IN()加子查询的办法:
mysql>SELECT * FROM sakila.film WHERE EXISTS (SELECT * FROM sakila.film_actor WHERE actor_id = 1 AND film_actor.film_id = film.film_id)
如何用好关联子查询
并不是所有关联子查询的性能都回很差。如果有人跟你说:“别用关联子查询”,那么不要理他。先测试,然后做出自己的判断。很多时候关联子查询是一种非常合理、自然,甚至是性能最好的写法,看看下面的例子:
mysql> EXPLAIN SELECT film_id,language_id FROM sakila.film
-> WHERE NOT EXISTS(SELECT * FROM sakila.film_actor WHERE film_actor.film_id=film.film_id)\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: film
partitions: NULL
type: index
possible_keys: NULL
key: idx_fk_language_id
key_len: 1
ref: NULL
rows: 1000
filtered: 100.00
Extra: Using where; Using index
*************************** 2. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: film_actor
partitions: NULL
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 5
filtered: 100.00
Extra: Using index
2 rows in set, 2 warnings (0.00 sec)
一般回建议使用左外连接(LEFT OUTER JOIN)重写该查询,以代替子查询。理论上,改写后MySQL的执行计划完全不会改变。我们来看这个例子
mysql> EXPLAIN SELECT film.film_id,film.language_id
-> FROM sakila.film
-> LEFT OUTER JOIN sakila.film_actor USING(film_id)
-> WHERE film_actor.film_id IS NULL\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: index
possible_keys: NULL
key: idx_fk_language_id
key_len: 1
ref: NULL
rows: 1000
filtered: 100.00
Extra: Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 5
filtered: 100.00
Extra: Using where; Not exists; Using index
2 rows in set, 1 warning (0.00 sec)
可以看到,这里的执行计划基本上是一样,下面是一些微小的区别:
- 1.表film_actor的访问类型是一个DEPENDENT SUBQUERY,而另一个是SIMPLE.这个不同是由于语句的写法不同导致的,一个是普通查询,一个是子查询。这对底层存储引擎接口来说,没有任何不同
- 2.对film表,第二个查询的Extra中没有"Using where",但这并不重要,第二个查询的USING子句和第一个查询的WHERE子句实际上是完全一样的。
- 3.在第二个表film_actor的执行计划的Extra列有"Not exists"。这是前面提到的提前终止算法(early-termination algorithm),MySQL通过使用"Not exists"优化来避免在表film_actor的索引中读取任何额外的行。这完全等效于直接编写NOT EXISTS子查询,这个执行计划中也是一样,一旦匹配到一行数据,就立刻停止扫描
所以,从理论上来讲,MySQL将使用完全相同的执行计划来完成这个查询。现实世界中,建议通过一些测试来判断使用哪种写法速度会更快。针对上面的案例,测试结果也是不同的,如表所示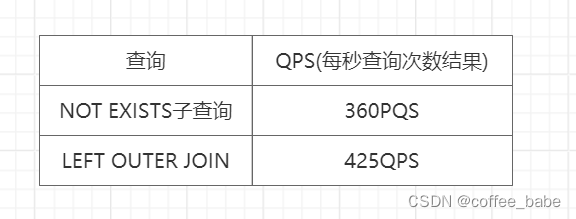
.测试结果显示,使用子查询的写法要略微慢些!不过每个具体的案例会各有不同,有时候子查询写法也会快些。例如,当返回结果中只有一个表中的某些列的时候。听起来,这种情况对于关联查询效率也会更好。具体情况具体分析,例如下面的关联,我们希望返回所有演员参演的电影,因为一个电影会有很多演员参演,所以可能会返回一些重复的记录:
mysql> SELECT film.film_id FROM sakila.film INNER JOIN sakila.film_actor USING(film_id);
我们需要使用DISTINCT和GROUP BY来移除重复的记录:
mysql> SELECT DISTINCT film.film_id FROM sakila.film INNER JOIN sakila.film_actor USING(film_id);
但是,回头看看这个查询,到底这个查询返回的结果集意义是什么?至少这样的写法回访SQL的意义很不明显。如果使用EXISTS则很容易表达"有演员参演"的逻辑,而且不需要使用DISTINCT和GROUP BY,也不会产生重复的结果集,我们知道一旦使用了DISTINCT和GROUP BY,那么在查询的执行过程中,通常需要产生临时中间表。下面我们用子查询的写法替换上面的关联:
mysql> SELECT film_id FROM sakila.film WHERE EXISTS(SELECT * FROM sakila.film_actor WHERE film.film_id = film_actor.film_id);
再一次,我们需要通过测试来比对这两种写法,哪个更快一些,测试结果如表所示.在这个案例中,我们看到子查询速度要比关联查询更快些。通过上面这个案例,主要想说明两点:一时不需要听取那些关于子查询的"绝对真理",二十应该用测试来验证对子查询的执行计划和相应时间的假设。我们应该通过测试来验证猜想