各个网站上找的各位大神的优秀回答,记录再此。
首先是石塔西大佬的回答:工业界推荐系统中有哪些召回策略?
万变不离其宗:用统一框架理解向量化召回前言常读我的文章的同学会注意到,我一直强调、推崇,不要孤立地学习算法,而是要梳理算法的脉络+框架,唯有如此,才能真正融会贯通,变纸面上的算法为你的算法,而不是狗熊掰棒子,被层出不穷的新文章、新算法搞得疲于奔命。之前,我在《推荐算法的"五环之歌"》梳理了主流排序算法常见套路:
- 特征都ID化。类别特征天然是ID型,而实数特征需要经过分桶转化。
- 每个ID特征经过Embedding变成一个向量,以扩展其内涵。
- 属于一个Field的各Feature Embedding通过Pooling压缩成一个向量,以减少DNN的规模
- 多个Field Embedding拼接在一起,喂入DNNDNN通过多层Fully Connection Layer (FC)完成特征之间的高阶交叉,增强模型的扩展能力。
- 最后一层FC的输出,就是最终的logit,与label(e.g., 是否点击?是否转化)计算binary cross-entropy loss。
相比于排序那直白的套路,召回算法,品类众多而形态迥异,看似很难找出共通点。如今比较流行的召回算法,比如:item2vec、DeepWalk、Youtube的召回算法、Airbnb的召回算法、FM召回、DSSM、双塔模型、百度的孪生网络、阿里的EGES、Pinterest的PinSAGE、腾讯的RALM和GraphTR、......
- 从召回方式上分,有的直接给user找他可能喜欢的item(user-to-item,简称u2i);有的是拿用户喜欢的item找相似item(item-to-item,简称i2i);有的是给user查找相似user,再把相似user喜欢的item推出去(user-to-user-to-item,简称u2u2i)
- 从算法实现上分,有的来自“前深度学习”时代,老当益壮;有的基于深度学习,正当红;有的基于图算法,未来可期(其实基于图的,又可细分为游走类和卷积类)。从优化目标上分,有的属于一个越大规模的多分类问题,优化softmax loss;
- 有的基于Learning-To-Rank(LTR),优化的是hinge loss或BPR loss
但是,如果我告诉你,以上这些召回算法,其实都可以被一个统一的算法框架所囊括,惊不惊奇、意不意外?本文就介绍我归纳总结的NFEP(Near, Far, Embedding, Pairwie-loss)框架,系统化地理解向量化召回算法。在详细介绍之前,我首先需要强调,这么做的目的,并非要将本来不相干的算法“削足适履”硬塞进一个框架里,哗众取宠,而是有着两方面的重要意义:
一是为了开篇所说的“融会贯通”。借助NFEP,你学习的不再是若干孤立的算法,而是一个算法体系,不仅能加深对现有算法的理解,还能轻松应对未来出现的新算法;
二是为了“取长补短”。大多数召回算法,只是在NFEP的某个维度上进行了创新,而在其他维度上的做法未必是最优的。我们在技术选型时,没必要照搬某个算法的全部,而是借助NFEP梳理的脉络,博采多家算法之所长,取长补短,组成最适合你的业务场景、数据环境的算法。
接下来,我首先介绍NFEP框架,然后逐一介绍如何从NFEP的框架视角来理解Airbnb召回、Youtube召回、Facebook EBR、Pinterest的PinSAGE、微信GraphTR、FM召回这几种典型的召回算法。
NFEP:理解向量化召回的统一框架
向量化召回简介
NFEP框架关注的是“向量化召回”算法,也就是将召回建模成在向量空间内的近邻搜索问题。传统的ItemCF/UserCF那种基于统计的召回方式,和阿里TDM那种基于树模型层次化划分搜索空间的召回算法,不在讨论范围之内。
假设向量化召回,是拿X概念下的某个x,在向量空间中搜索Y概念下与之最近的y。其serving的套路就是:
- 离线时,将几百万、上千万的y,通过模型获得它们的embedding,将这些y embedding灌入FAISS并建立索引
- 在线时,拿请求中的x,或提取、或生成x embedding,在FAISS中查找最近的y embedding,将对应的y作为召回结果返回
为了达成以上目标,我们在训练的时候,需要考虑四个问题:(1)如何定义X/Y两概念之间的“距离近”?(2)如何举反例,即如何定义X/Y之间的“距离远”?(3)如何获取embedding?(4)如何定义loss来优化?
这4个问题,对应着NFEP框架的4个维度,接下来将会逐一详细分析。
Near:如何定义“近”?
这取决于不同的召回方式
- i2i召回:x,y都是item,我们认为同一个用户在同一个session交互过的两个item在向量空间是相近的,体现两个item之间的“相似性”。
- u2i召回:x是user,y是item。一个用户与其交互(e.g., 点击、观看、购买)过的item应该是相近的,体现user与item之间的“匹配性”。
- u2u召回:x,y都是user。比如使用孪生网络,则x是user一半的交互历史,y是同一用户另一半交互历史,二者在向量空间应该是相近的,体现“同一性”。
无论哪种召回方式,为了能够与FAISS兼容,我们都拿x embedding和y embedding之间的“点积”或"cosine"来衡量距离。显然,点积或cosine越大,代表x与y在向量空间越接近。
Far:如何定义“远”?
其实就是举反例。举出的<x,y_>反例,要能够让模型见识到形形色色、五花八门、不同角度的“x,y_之间差异性”,达到让模型“开眼界,见世面”的目的。特别是在训练u2i召回模型时,一个非常重要的原则就是,千万不能(只)拿“曝光未点击”做负样本。否则,正负样本都来自“曝光”样本,都是与user比较匹配的item,而在上百万的候选item中,绝大部分item都是与user兴趣“八杆子打不着”的。这种训练数据与预测数据之间的bias,将导致召回模型上线后“水土不服”。具体原理解释,请参考我的另一篇文章《负样本为王》。为了达到以上目标,获得y_最重要的方式就是在整个y的候选集中随机采样:
- 有同学担心,随机采样得到的y_有可能与x是相近的。不排除这种可能性,但是在一个实际的推荐系统中,候选的y一般是成百上千万,而每次随机采样的y_不会超过100,这种false negative的概率极低。
- 随机采样并非uniform sampling,那样会导致热门item霸占召回结果,从而失去个性化。因此在采样时,需要打压热门item。比较有效的一种方式就是学习word2vec中打压高频词的方法,降低热门item成为正样本的概率,提升热门item成为负样本的概率。具体公式细节,见的我的知乎回答《推荐系统传统召回是怎么实现热门item的打压?》。
但是,只通过随机采样获得y_也有问题,就是会导致模型的精度不足。假如,你要训练一个“相似图片召回”算法。当x是一只狗时,y+是另外一只狗。y−在所有动物图片中随机采样得到,大概率是到猫、大象、乌鸦、海豚、...。这些随机负样本,对于让模型“开眼界,见世面”十分重要,能够让模型快速“去伪存真”。但是猫、大象、乌鸦、海豚、...这样随机的负样本,与正样本相比相差太大,使得模型只观察到粗粒度就足够了,没有动力去注意细节,所以这些负样本被称为easy negative。为了能给模型增加维度,迫使其关注细节,我们需要让其见识一些hard negative,比如狼、狐狸、...这种与x、y+还有几分相似的负样本不同的算法,采取不同的方式获得hard negative,在下文中将会详细分析。
Embedding:如何生成向量?
用哪些特征学出embedding?
- 有的算法只使用UserId/DocId
- 有的算法除此之外,还使用了画像、交互历史等side information
- 图卷积算法还使用了user节点、item节点在图上的连接关系
通过什么样的模型学习出embedding?
- 只使用ID特征的算法,模型就只有一个embedding矩阵,通过id去矩阵相应行提取embedding
- 有的模型,将特征(id+side information)喂入DNN,逐层让特征充分交互,DNN最后一层的输出就是我们需要的embedding
- 基于图卷积的模型中,目标节点(user或item)的embedding,是由其邻居节点的embedding,加上节点本身信息,聚合而成。一来,图上的节点不仅有user/item,还可以包括性别、年龄、职业等属性节点;二来,邻居节点也有自己的邻居。图的这种性质,使得节点embedding能够利用的信息更加广泛,并且兼具本地与全局视角。
召回模型的特点:解耦
u2i召回,与排序,虽然都是建模user与item的匹配(match)关系,但是在样本、特征、模型上都有显著不同。在之前的文章中,我详细论述了二者在样本选择上的区别,这一节将论述二者在特征、模型上的区别。简言之,就是:排序鼓励交叉,召回要求解耦。
排序鼓励交叉
- 特征上,排序除了利用user feature(包括context)、item feature,最重要还使用了大量的交叉统计特征,比如“user tag与item tag的重合度”。这类交叉统计特征是衡量“user与item匹配性”的最强信号,但是也将user feature与item feature紧密耦合在一起。
- 模型上,排序一般将user feature、item feature、交叉统计特征拼接成一个大向量,喂入DNN,让三类特征通过多层全连接层(Fully Connection, FC)进行充分交叉。从第一层FC之后,你就已经无法分辨,FC的输出中哪些属于user信息?哪些属于item信息?
召回要求解耦
排序之所以允许、鼓励交叉,还是因为它的候选集比较小,最多不过几千个。换成召回那样,要面对百万、千万级别的海量候选item,如果让每个user与每个候选item都计算交叉统计特征,都过一遍DNN那样的复杂操作,是无论如何也无法满足线上的实时性要求的。所以,召回要求解耦、隔离user与item特征。
- 特征上,尽管信号强,但是召回不允许使用“交叉统计特征”。(放弃这么强的信号,的确可惜。如何在不使用交叉统计特征的情况下,仍然达到使用了它们的效果?有一种方法是使用蒸馏,详情见《Privileged Features Distillation at Taobao Recommendations》)
- 模型上,禁止user feature与item feature出现DNN那样的多层交叉,二者必须独立发展,i.e., user子模型,利用user特征,生成user embedding;item子模型,利用item特征,生成item embedding。唯一一次user与item的交叉,只允许出现在最后拿user embedding与item embedding做点积计算匹配得分的时候。只有这样,才能允许我们离线时,在user未知的情况下,独立生成item embedding灌入faiss;在线时,能独立生成user embedding,避免与每个候选item进行“计算交叉特征”和“通过DNN”这样复杂耗时的操作
Pairwise-loss:如何成对优化?
排序阶段经常遵循"CTR预估"的方式
- 样本上,<user,item+,1>和<user,item−,0>是两条样本
- loss上使用binary cross-entropy这样的pointwise loss
能够这么做的前提是,其中的<user,item−,0>是“曝光过但未点击”的“真负”样本,label的准确性允许我们使用pointwise loss追求“绝对准确性”。
但是在召回场景下,以上前提并不成立。以常见的u2i召回为例,绝大多数item从未给user曝光过,我们再从中随机采样一部分作为负样本,这个negative label是存在噪声的。在这种情况下,再照搬排序使用binary cross-entropy loss追求“预估值”与“label”之间的“绝对准确性”,就有点强人所难了。所以,召回算法往往采用Pairwise LearningToRank(LTR),建模“排序的相对准确性”:
- 样本往往是<user,item+,item−>的三元组形式
- 模型的优化目标是,针对同一个user,item+与他的匹配程度,要远远高于,item−与他的匹配程度。所以Loss中没有label,而存在“<user,item+>的匹配分”与“<user,item−>的匹配分”相互比较的形式。
为了实现Pairwise LTR,有几种Loss可供选择。一种是sampled softmax loss。
- 这种loss将召回看成一个超大规模的多分类问题,优化的目标是使,user选中item+的概率最高。
- user选中item+的概率=
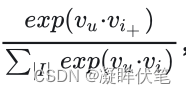 其中Vu是user embedding,vi代表item embedding,|I|代表整个item候选集。
其中Vu是user embedding,vi代表item embedding,|I|代表整个item候选集。 - 为使以上概率达到最大,要求分子,即user与item+的匹配度,尽可能大;而分母,即user与除item+之外的所有item的匹配度之和,尽可能小。体现出上文所说的“不与label比较,而是匹配得分相互比较”的特点。
- 但是,由于计算分配牵扯到整个候选item集合|I|,计算量大到不现实。所以实际优化的是sampled softmax loss,即从|I|中随机采样若干item−,近似代替计算完整的分母。
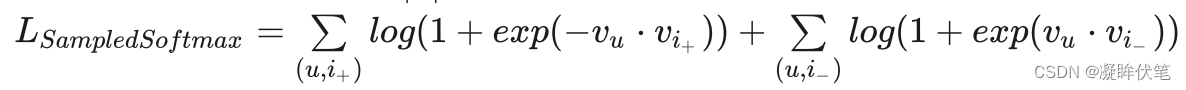
另一种loss是margin hinge loss
优化目标是:user与正样本item的匹配程度,要比,user与负样本item的匹配程度,高出一定的阈值。即:
![]()
因为margin hinge loss多出一个超参margin需要调节,因此我主要使用如下的BPR Loss。
- 其思想是计算"给user召回时,将item+排在item-前面的概率",
![]()
- 因为<user, item+, item->的ground-truth label永远是1,所以将所以将pCorrectOrder喂入binary cross-entropy loss的公式,就有
![]()
![]()
注意,为了方便行文,以上公式都是针对u2i召回的举例,但是u2u, i2i召回也具备类似的公式。
Airbnb召回算法
《Real-time Personalization using Embeddings for Search Ranking at Airbnb》是一篇经典论文,其中介绍了listing embedding和user/listing-type embedding两种召回算法。
listing embedding召回
listing就是Airbnb中的房源,所以基于listing embedding的召回,本质就是一个i2i召回。
Near
本来是想照搬word2vec,将用户的点击序列看成一个句子,认为一个滑窗内的两个相邻listing是相似的,它们的embedding应该接近。
但是仔细想想,以上想法存在严重问题
- word2vec建模的是语言模型的“共现性”,即哪些词语经常一起出现,因此需要一个滑动窗口限制距离
- 而这里,我们建模的是listing之间的相似性,难道只有相邻listing之间存在相似性?一个点击序列首尾的两个listing就不相似了吗?
所以,理想情况下,一个序列中任意两个listing,它们的embedding都应该是相近的。但是在实践中发现,这样的组合太多,所以Airbnb还是退回到word2vec的老路,即还是只拿一个滑窗内的中心listing与邻居listing组成正样本对。但是由于“最终成功预订”的那个listing有最强的业务信号,所以我们拿它与点击序列中的每个listing组成正样本对。这也就是Airbnb论文中“增加final booked listing作为global context加入每个滑窗”的原因。
Far
绝大部分负样本还是随机采样生成的。但是,Airbnb发现,用户点击序列中的listing多是同城的,导致正样本多是同城listing组成,而随机采样的负样本多是异地的,这其中存在的bias容易让模型只关注“地域”这个粗粒度特征。
为此,Airbnb在全局随机采样生成的负样本之外,还在与中心listing同城的listing中随机采样一部分listing作为hard negative,以促使模型能够关注除“地域”外的更多其他细节。
Embedding
特征只用了listing ID,模型也只不过是一个大的embedding矩阵而已。缺点是对于新listing,其id不在embedding矩阵中,无法获得embedding。
Pairwise-loss
使用sampled softmax loss。
user/listing-type embedding召回
Near
这个所谓的用user-type去召回listing-type,实际上就是u2i召回,只不过Airbnb觉得预订行为太稀疏,所以将相似的user聚类成user-type,把相似的listing聚类成listing-type。
既然如此,"Near"步骤与一般的u2i召回,别无二致。即,如果某user预订过某listing,那么该user所属的user-type,与该listing所属的listing-type就应该是相近的。
Far
绝大部分负样本还是随机采样生成的。除此之外,增加“被owner拒绝”作为hard negative,表达一种非常强烈的“user~item不匹配”。
Embedding
特征只有user-type ID和listing-type ID,模型也只不过拿ID当行号去embedding矩阵中抽取embedding。
Pairwise-loss
使用sampled softmax loss。
点评
Airbnb的两个算法,在Embedding和Pairwise-loss两个步骤上,都是标准操作,平淡无奇。
由于Airbnb论文的话术向word2vec“生搬硬套”,给人一种感觉,在学习listing embedding时增加final booked listing作为global context加入每个滑窗,在学习user/listing-type embedding时将user-type和listing-type组成异构序列,都是脑洞大开的创新。但是从Near的角度来看
- word2vec建模的是词语间的“共现性”,listing embedding建模的是一个session中任意两个listing之间的“相似性”,而user/listing-type embedding建模的是user和listing之间的“匹配性”,三者的目标截然不同。
- 序列、滑窗只是word2vec刻画“共现性”所独有的概念,完全没必要出现在学习listing embedding和user/listing-type embedding的过程中。
- 学习listing embedding时增加final booked listing作为global context,与其说是创新,不如说是考虑计算量之后的一种折中方案。
- 让user type和其预订过的listing type组成正样本对,从“匹配性”的角度来看,天经地义,完全没必要像论文中那样组成user+listing异构序列,从“共现性”的角度来解释。
在Far这个维度,Airbnb增加“同城负样本”和“owner拒绝负样本”,是根据业务逻辑增加hard negative的典型代表。
Youtube召回算法
Youtube在《Deep Neural Networks for YouTube Recommendations》一文中介绍的基于DNN的召回算法,非常经典,开DNN在召回中应用之先河,被业界模仿。
Near
u2i召回的典型思路:user与其观看过的视频,在向量空间中是相近的。
Far
论文中只提到了随机负采样,没有提到如何打压热门视频,也没有提到如何增加hard negative。
Embedding
- user embedding
- 用户看过的视频的embedding,pooling成一个向量
- 用户搜索的关键词的embedding,pooling成一个向量
- 以上两个向量,加上一些用户的基本属性,拼接成一个大向量,喂入多层全连接(FC)进行充分交叉
- 最后一层FC的输出就是user embedding
- video embedding
- 特征只用了video id,模型也只不过是一个大的embedding矩阵
- 整个模型在两个地方要用到video embedding,一个自然是最后计算user embedding与video embedding点积作为匹配分的时候要用到,另一处是用户看过的视频的embedding要参与生成user embedding
- 这两处video embedding是否需要共享?原文中没有详细说明。我是偏向于共享的,一来降低模型规模,二来增加一些冷门video得到训练的机会。
Pairwise-loss
使用sampled softmax loss。
Facebook的EBR算法
《Embedding-based Retrieval in Facebook Search》一文中介绍的算法。如果想了解更多的技术细节,请参考我的另一篇文章《负样本为王:评Facebook的向量化召回算法》
Near
u2i召回的典型思路:user与其观看过的视频,在向量空间中是相近的。
Far
绝大部分负样本依然是通过随机采样得到的。论文明确提出了,召回算法不应该拿“曝光未点击”做负样本。
另外,本文最大的贡献是提供了两种挑选hard negative的方案。Facebook的EBR与百度Mobius的作法非常相似,都是用上一版本的召回模型筛选出"没那么相似"的<user,item>对,作为额外负样本,来增强训练下一版本召回模型。具体做法上,又分online和offline两个版本
在线筛选
- 假如一个batch有n个正样本对,<u(i),t+(i)>,那么u(i)的hard negative是利用上一轮迭代得到的召回模型,评估u(i)与同一个batch的除t+(i)之外的所有t+的匹配度,再选择一个与u(i)最相似的作为hard negative。
- 文章还提到,一个正样本最多配置2个这样的hard negative,配置多了反而会有负向效果。
- 缺点是仅仅采用一个batch中的item作为hard negative的候选集,规模太小,可能还不足够hard。
离线筛选
- 拿当前的召回模型,为每个候选item生成item embedding,灌入FAISS
- 拿当前的召回模型,为每个user生成user embedding,在FAISS中检索出top K条近邻item
- 这top K条近邻item中,排名靠前的是positive,排名靠后的是easy negative,只有中间区域(Facebook的经验是101-500)的item可以作为hard negative。
- 将hard negative与随机采样得到的easy negative混合。毕竟线上召回时,候选库里还是以easy negative为主,所以作者将比例维持在easy:hard=100:1
- 拿增强后的负样本,训练下一版召回模型。
Embedding
模型采用经典的双塔模型。双塔模型鲜明体现了前文所述的“召回要求解耦”的特点:
- 模型不会将user feature与item feature接入一个DNN,防止它们在底层就出现交叉
- user特征,通过user tower独立演进,生成user embedding
- item特征,通过item tower独立演进,生成item embedding
- 唯一一次user与item的交叉,只允许出现在最后拿user embedding与item embedding做点积计算匹配得分的时候
只有这样,才能允许我们
- 离线时,在user未知的情况下,只使用item tower,独立生成item embedding灌入faiss;
- 在线时,只使用user tower独立生成user embedding,避免与每个候选item进行“计算交叉特征”和“通过DNN”这样复杂耗时的操作
Pairwise-loss
使用margin hinge loss
Pinterest的PinSAGE
Pinterest 推出的基于 GCN 的召回算法 PinSAGE,被誉为"GCN 在工业级推荐系统上的首次成功运用"。对技术细节感兴趣的同学,推荐读我的另一篇文章《PinSAGE 召回模型及源码分析》。
Near
和Airbnb一样,我们可以认为被同一个user消费过的两个item是相似的,但是这样的排列组合太多了。
为此,PinSAGE采用随机游走的方式进行采样:在原始的user-item二部图上,以某个item作为起点,进行一次二步游走(item→user→item),首尾两端的item构成一条边。将以上二步游走反复进行多次,就构成了item-item同构图。
在这个新构建出来的item-item同构图上,每条边连接的两个item,因为被同一个user消费过,所以是相似的,构成了训练中的正样本。
Far
PinSAGE提供了一种基于随机游走筛选hard negative的方法。
在训练开始前,
- 从item-item图上的某个节点u,随机游走若干次。
- 游走过程中遍历到的每个节点v,都被赋予一个分数L1-normalized visit count=该节点被访问到的次数 / 随机游走的总步数。
- 这个分数,被视为节点v针对节点u的重要性,即所谓的Personal PageRank(PPR)。
训练过程中:
- 针对item-item同构图上的某一条边u→v,u和v就构成了一条正样本,它们的embedding应该相近
- 在图上所有节点中随机采样一部分ne,u和每个ne就构成了一条负样本,它们的embedding应该比较远。因为是随机采样得到的,所以ne是easy negative。
- 除此之外,还将u所有的邻居,按照它们对u的重要性(PPR)从大到小排序,筛选出排名居中(e.g.论文中是2000~5000名)的那些item。这些item与u有几分相似,但是相似性又没那么强,从中再抽样一批item,作为"u"的hard negative。
Embedding
每个item embedding通过图卷积的方式生成。图卷积的核心思想就是:利用边的信息对节点信息进行聚合从而生成新的节点表示。多层图卷积的公式如下所示。
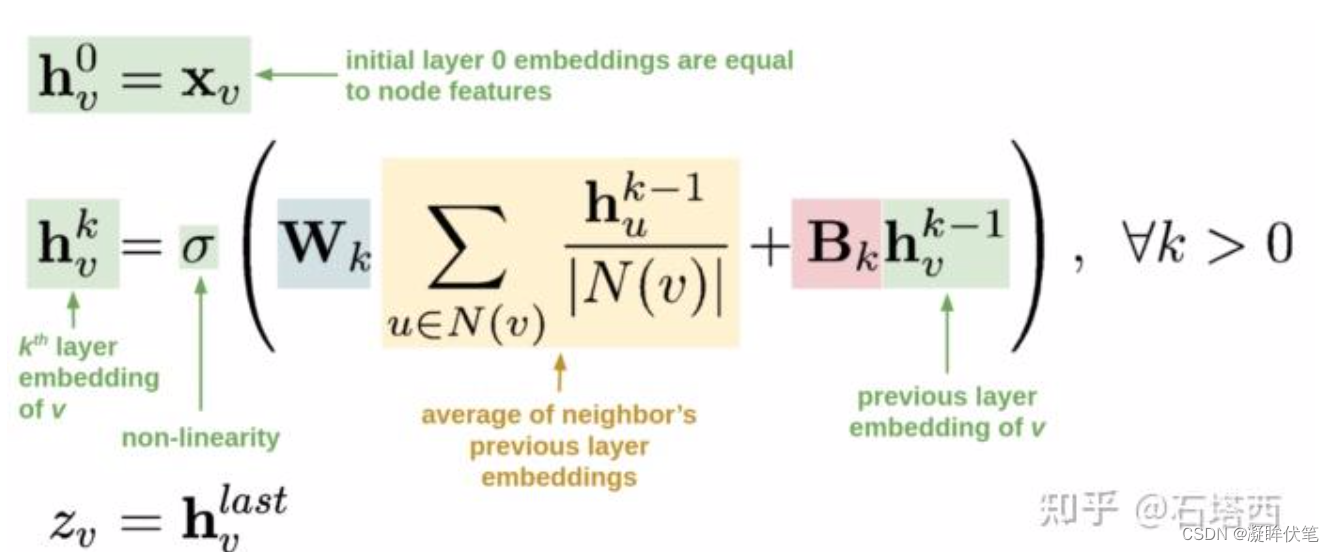
· 第一行,说明各节点hv0的初始表示,就等同于各节点自身的特征。这时还没有用上任何图的信息。
· 第二行,第 k 层卷积后,各节点的表示h_v^k, 和两部分有关。第一部分,括号中蓝色+色部分,即先聚合当前节点的邻居的第 k-1 层卷积结果(![]()
再做线性变换。这时就利用上了图的信息,即某节点的邻居节点上的信息沿边传递到该节点并聚合(也就是卷积)
第二部分,括号中红色+绿色部分,即拿当前节点的第 k-1 层卷积结果(hvk−1),做线性变换
可以看到,如果不考虑括号中的第一部分,这个公式简化为
![]()
是不是很眼熟?这不就是传统的 MLP 公式吗?所以,图卷积的思想很简单,就是每层在做非线性变换之前,每个节点先聚合一次邻居的信息。
· 第三行,最后一层卷积的结果,成为各节点的向量表示,用于计算两节点存在边的可能性。
Parwise-loss
使用margin hinge loss。
微信的GraphTR
这是我见过的最复杂的生成embedding的算法,没有之一。
Near
就是传统i2i召回的思路,在一个session内被观看的多个video之间是相似的,它们的embedding接近。
Far
就是随机负采样那一套,文中没有涉及打压热门视频,也没有涉及筛选hard negative。
Embedding
与上边介绍过的PinSAGE建立在item-item的同构图上有所不同,GraphTR建立在包括了user, video, tag, media (视频来源)这4类节点(每类称作一个域)的异构图上。每个节点要聚合来自多个领域的异构消息。
为了防止异构消息相互抵销而引入信息损失,GraphTR利用了三种聚合方式,从三种不同粒度对于不同类型的邻居节点上的信息进行聚合
- 将各域邻居节点的embedding拼接成一个大向量,按照传统的GraphSAGE方式聚合。这种聚合方式,不区分域,粒度最粗。
- 接下来的FM聚合,细致了一些,让不同域的邻居信息之间的两两交叉。
- 最后的Transformer聚合方式,粒度最细,不仅考虑了不同域之间的交叉,还考虑了一个域内部多个邻居节点之间的交叉。
为了生成item embedding,使用了GraphSAGE+FM+Transformer三种大杀器,是我见过的最复杂的向量化召回算法。对技术细节感兴趣的同学,可以参考我的另一篇文章《GraphSAGE+FM+Transformer强强联手:评微信的GraphTR模型》。
Pairwise-loss
sampled softmax loss
FM召回
与风头正劲的众多基于DNN/GNN的召回算法相比,FM召回算法,如今不太引人注目。但是,FM召回性能优异,便于上线和解释,而且对冷启动新用户或新物料都非常友好,仍然不失为召回算法中的一把利器。
Near
u2i召回的典型思路:user与其消费过的item,在向量空间中是相近的。
Far
绝大部分负样本还是随机采样生成的。同时在随机采样的过程中,要注意打压热门item,具体细节,见的我的知乎回答《推荐系统传统召回是怎么实现热门item的打压?》
至于如何增加hard negative来提高模型的精度,可以参考Facebook EBR中在线与离线筛选hard negative的做法。
Embedding
以上介绍的所有u2i召回(e.g, Youtube召回、Facebook EBR),召回的依据都只是user embedding与item embedding的点积,即只考虑了user与item的匹配程度。但是,在一个实际的推荐系统中,用户喜欢的未必一定是与自身最匹配的,也包括一些自身性质极佳的item(e.g.,热门视频、知名品牌的商品、著名作者的文章)。所以,我们在给某对儿<user,item>打分时,除了user/item的匹配度,还需要考虑item本身的受欢迎程度。
在FM召回中增加item自身得分非常简单,只需要将user embedding和item embedding都增广一维,如下图所示。其中E_{user}是某user包含的所有特征embedding之和,EitemE_{item}是某Item包含的所有特征embedding之和。
具体公式细节,请参考我的文章《FM:推荐算法中的瑞士军刀》中的FM召回一节。需要特别指出的是,这种通过向量增广考虑“item本身的受欢迎程度”的做法,同样适用于其他u2i召回算法(e.g.,e.g, Youtube召回、Facebook EBR),有助于提高它们的精度。
Pairwise-loss
在我的实现中,我使用了BRP loss。
总结
从NFEP框架视角来理解向量化召回算法,各算法的特点梳理如下表所示。
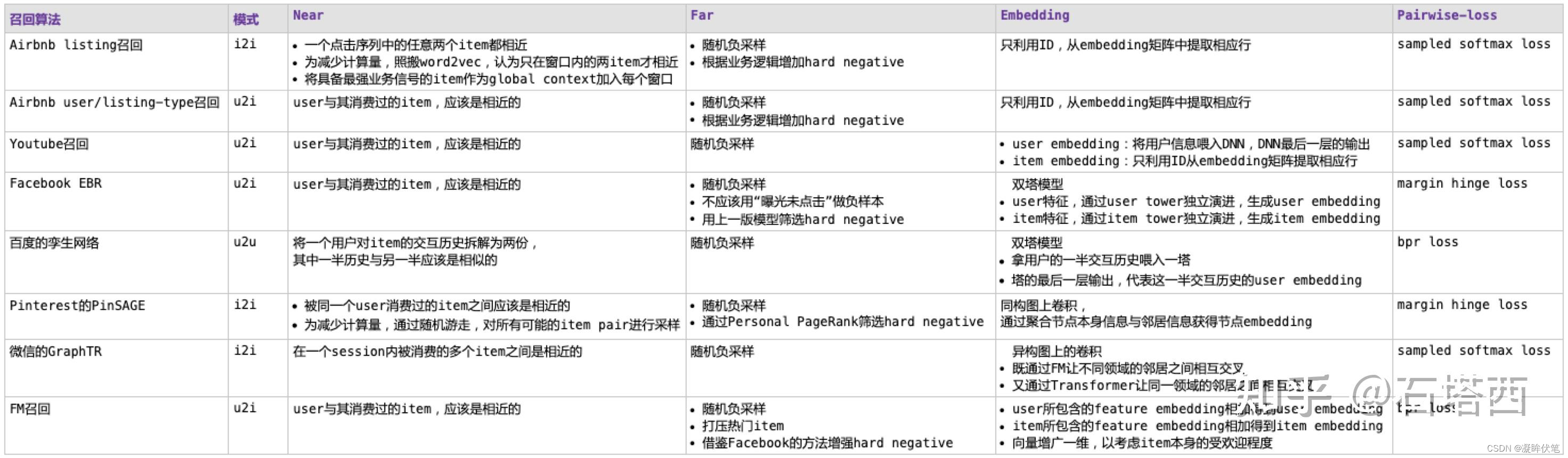
可以看到,通过NFEP框架的梳理,各召回算法间的异同变得清晰,便于我们加深理解,融会贯通。
而当你为自己的召回项目选型的时候,你可能希望实现双塔模型,还希望模仿Facebook的做法来增强hard negative,同时还要像FM召回一样将“item本身受欢迎程度”考虑在内。借助NFEP框架的梳理,我们可以更好地取长补短,设计出最适合你的业务场景、数据环境的召回算法。
IWTBS的回答
1. 工业界召回的基本思路
大家都知道,推荐系统基本上由召回-粗排-精排组成,其中召回的主要作用是,在海量的候选中找到用户可能感兴趣的内容,由于召回位置靠前且输入空间较大,所以时延要求较高。
在工业界一般是多路召回并发调用,多路merge之后是小几千或者几百的量级,常见的有以下几大类:
- 基础属性召回:简单来讲就是人主观觉得有效的策略,比如热门召回、地域召回、家乡召回、标题召回等
- 产品&运营策略召回:比如节日、活动等定制场景
- 试探类召回:由于推荐系统容易产生“信息茧房”,瓶颈主要就在召回端,像EE等方式均属于试探类的典型应用
- 社交类召回:典型例子就是微信视频号,会把你好友点赞的视频推给你
- 模型类召回:用模型来做召回,一般来讲效果最好迭代时间也较长,本文主要介绍的就是该类召回
下面会罗列工业界常用的召回模型,像NLP+策略、协同过滤等我就懒得赘述了,本文主要介绍基础的向量化召回、行为序列建模召回、图召回和一些自己的感想看法。
介于篇幅和时间所限,我只列举了我所知的在一线大厂有落地的经典算法,各类算法我会提纲挈领地阐述思想,一些具体细节可以看我引用的论文或者博客。
2. 基础的向量化召回
本质上讲是将召回建模成在向量空间内的近邻搜索问题,将用户和物品均由向量表示,离线构建索引,在serving时模糊近邻查找。
2.1 YoutubeDNN
Deep Neural Networks for YouTube Recommendations是一篇做推荐必读的论文,王喆的两篇文章也让我受益很多
王喆:重读Youtube深度学习推荐系统论文,字字珠玑,惊为神文
王喆:YouTube深度学习推荐系统的十大工程问题
简单总结一下,输入用户属性特征和历史行为序列,经过NN网络做softmax,在当时有价值的一点是最终softmax之前的网络层可以当作是u_vec,且使用了负采样加速训练,线上使用ANN做serving加速。即将group的embedding离线构建好,线上只需要计算user的embeeding并查找就好,充分发挥了NN网络的拟合能力,还不影响速度
2.2 DSSM双塔召回
DSSM全称是Deep Structured Semantic Model ,最开始是解决搜索问题,后来在推荐召回阶段被广泛使用,基本结构就是user和group侧分别用NN网络来拟合,最上层的神经元可认为是user和group的向量表征。CTR召回可以直接用点积+sigmod得到loss,时长模型可以用cos距离+mse计算loss
双塔模型结构简单效果好,经过了工业界的考验,也有一些技巧:
- 双塔模型在工程上一般离线提前构建好group侧的embedding,线上只计算user_emd,然后通过ANN的方式进行快速查找
- 双塔一般不使用u-g交叉特征,因为一旦使用就很难离线提前构建好group_emd的查找图
- ANN的构建方法也会影响双塔结构,比如使用HNSW建图依赖欧氏距离,双塔使用点积作为loss和目标并不一致,可以做归一化
- 双塔只是一种结构范式,其本身有很多可以根据业务场景创新的点:比如使用短期和长期兴趣构建长短期兴趣建模;通过胶囊网络建模用户多兴趣;使用泛化特征优化用户冷启动等
- 双塔存在的一个问题是,只有最后的MLP层才能进行ug的交互,比较细粒度的特征可能无法表征。之前在某手实习的时候是采用下层和上层拼接后再点积解决的,前段时间看俊林老师也写了一篇文章介绍他们的做法,简单来讲是通过SENet动态抑制无效特征张俊林:SENet双塔模型:在推荐领域召回粗排的应用及其它
2.3 FM召回
这个我之前写过一篇文章,介绍了FM召回的原理和实践,以及常用的ANN算法,这里就不多介绍了,主体思路依旧是构建向量,然后离线建group_emd,线上计算user_emd再近邻查找。从原理上来讲,我觉得双塔比起FM有更强的泛化拟合能力,且方便怼特征,也一定程度上比FM能更好地缓解bias现象。
iwtbs:聊聊向量化召回的一些工程经验
iwtbs:向量召回—近邻快速查找算法总结
3. 行为序列建模召回
3.1 RNN序列召回
建模用户单一的短期兴趣,最简单的就是直接把rgid做pooling或者attention,这里介绍一个比较经典的序列召回方法GRU4REC。相应的网络结构其实很简单,使用用户session中的点击序列作为模型输入,输出则为用户下次点击的item相应的得分
3.2 MIND多兴趣召回
文章名为Multi-Interest Network with Dynamic routing论文链接,其基本思想是用户兴趣多样,仅用一个向量表征用户兴趣是有偏的,如果能构建多个user_emd某种程度上就能召回出更全的候选,该论文采用胶囊网络来建模用户多种兴趣。
将历史行为序列输入动态路由网络层输出N个兴趣表征向量,每个兴趣向量分别和用户画像的Embedding concat,输入到relu神经网络,输出多个经过非线性变换的兴趣向量,输出的多个兴趣向量再和 Label Item做个Label-aware Attention,从多个兴趣向量中选择一个,最后通过 Softmax 层构建ug_emd。MIND 模型的线上部署可以分成两部分内容,一部分是生成用户的多兴趣向量,另一部分是通过多个兴趣向量进行向量检索。
实践中要根据业务来评估建模多兴趣的收益,比如阿里的电商业务做多兴趣就非常必要。从模型角度来评估是否有必要,可以离线打印一下各个u_emd的召回内容和向量距离,如果召回内容有显著差距且向量距离大则说明有价值,如果本身距离很近则说明用一个向量表征用户兴趣已经绰绰有余。
3.3 SDM长期兴趣建模
SDM 论文链接并非直接取用户近期行为(长度 50~100)进行建模,而是将用户行为进行session化。定义当前行为的session为用户的短期兴趣,发生在该session之前到一周内的历史行为为长期兴趣。并且把短期兴趣Embedding和长期兴趣Embedding做融合,代表用户兴趣向量。这个insight在电商场景我觉得肯定有价值,因为我购物就是短期和长期并不一致,但是长期兴趣对短期的推荐有很大价值。如果是长短期兴趣差距并不大的场景,比如听音乐我觉得就没什么作用,我自己的音乐品类在数年前和今天差距都变化不大。
回到论文本身,Session 定义主要包括:系统后台标识相同的 Session Id 的;两次行为在10分钟以内的;长度在50以内的。大致上本文和爱彼迎、DSIN等的划分思路基本差不多,有一些阈值需要根据业务进行分析调整。
对用户长短期数据,分不同方式处理:
- 对于长期行为序列:使用item_id,cate_id,cate_level1_id,shop_id,brand_id 等行为序列。以用户画像embedding 作为 query 向量分别做 user attention。
- 对于短期行为序列,借鉴 GRU4REC。具体做法:拿最近一个Session的行为序列,同时考虑到即使用户行为在一个session内仍然会表现出用户的多兴趣倾向。使用multi-head attention将RNN表达的用户动态兴趣投影到不同兴趣空间,然后通过一个矩阵进行聚合,最后做个User Attention。
代码复现可以参考一袋米抗三楼:SDM(Sequential Deep Matching Model)的复现之路
4. 图召回
4.1 通用Graph Embedding模型
如果对DeepWalk等基础图嵌入算法没有了解,建议先阅读相关资料。这里推荐浅梦的github,里面有文章介绍原理https://github.com/shenweichen/GraphEmbedding。
以DeepWalk为例,利用用户的行为数据构造出item的有向图。再通过随机游走的方式生成item序列,然后把item序列当成句子,以word2vec的方式进行训练,最终生成每个item的embedding。至于具体用物品图、还是用户-物品图、随机采样还是概率采样等都可以根据业务实验效果来定。
4.2 EGES
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba,在EGES中为了解决冷启动问题引入了side information的概念。将商品的商店、价格、类型等特征放入到模型里面训练。因此输入不仅是item的embedding, 还包括item对应的商店,价格,分类的embedding。
由于对于不同的商品,每个side information对商品的影响程度是不一样的。因此为不同的商品的side information赋予了不一样的权重,整体结构如下图所示。
其中SI 0表示商品,SI 1到SI n表示商品的各个side information。a0,a1到an表示embedding做averge pooling时候的的权重因子,相关实现可参考wangzhegeek/EGES
4.3 图卷积网络
与DeepWalk等不同在于使用了卷积的方式,而这里卷积算子和CV中有所不同,但本质也是学习某个节点周边其他节点信息。GCN是谱图卷积的一阶局部近似,是一个多层的图卷积神经网络,每一个卷积层仅处理一阶邻域信息,通过叠加若干卷积层可以实现多阶邻域的信息传递。
但是GCN要求在一个确定的图中去学习顶点的embedding,无法直接泛化到在训练过程没有出现过的顶点,GraphSAGE则是一种能够利用顶点的属性信息高效产生未知顶点embedding的一种归纳式学习的框架,其核心思想是通过学习一个对邻居顶点进行聚合表示的函数来产生目标顶点的embedding向量。GraphSage论文链接
步骤主要是:1. 对图中每个顶点邻居顶点进行采样 ;2. 根据聚合函数聚合邻居顶点蕴含的信息 ;3. 得到图中各顶点的向量表示供下游任务使用。
PinSage底层算法就是 GraphSAGE,只不过为了将其落地做了一系列的改进,我自己没有深入研究过,感兴趣的可以自己看论文Graph Convolutional Neural Networks for Web-Scale Recommender Systems
4.4 知识图谱召回
利用知识图谱作为辅助信息生成推荐可以缓解冷启动和泛化不足的问题,而且可以对推荐的结果进行解释,尤其是一些泛化内容仅仅通过自身数据是学不到的。由于知识图谱我没有深入做过,也就没什么经验和感悟可谈了,这里仅列一篇2020年关于知识图谱+推荐综述。
BELIEVE:一文概览知识图谱在推荐系统的发展现状
5. 深度检索召回模型
不再是离线训练并构建group_emd线上计算user_emd然后ANN的方式,而是端到端地做召回。
5.1 阿里TDM
Learning Tree-based Deep Model for Recommender Systems
内积表征偏好的方式表达能力有限,阿里提出了基于树的检索算法 TDM, 将索引建模成一棵树结构,候选集的每个 Item 为树中的叶子结点,并将模型的参数学习和树结构的参数学习结合起来训练。
索引的构建方式就是绿色方框中的树形结构,评分规则就是红框中的复杂DNN网络(用于输出用户对树节点的偏好程度,其中叶子节点表征每一个商品,非叶子节点是对商品的一种抽象化表征,可以不具有具体的物理意义),检索算法是beam search算法。
5.2 字节Deep Retrieval
Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations
TDM树结构的部分叶子结点可以会因为稀疏数据而导致学习不充分,候选集只属于一个叶子节点也不符合常理。
字节提出了一种端到端的模型训练框架“深度检索” DR,该模型使用 D*K 维的矩阵来作为索引结构。每个 Item 都需要走 D 步,每一步有 K 种选择。走到最后会有 K^D 可能的路径,每一条路径可以代表一个包含多个 Item。每个 Item 可以被这样编码一次或多次,所以 Item 也可以属于多条路径。Item 和 Embedding 之间是多对多的编码范式,故其可以表达更复杂的关系,最终实验证明,DR 模型时间复杂度接近线性,同时可以取得与暴力枚举相当的结果。