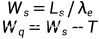数据挖掘,计算机网络、操作系统刷题笔记36
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记36
- @[TOC](文章目录)
- 数据挖掘
- 可视化分析
- 在TCP/IP体系结构中,直接为ICMP提供服务的协议是()。
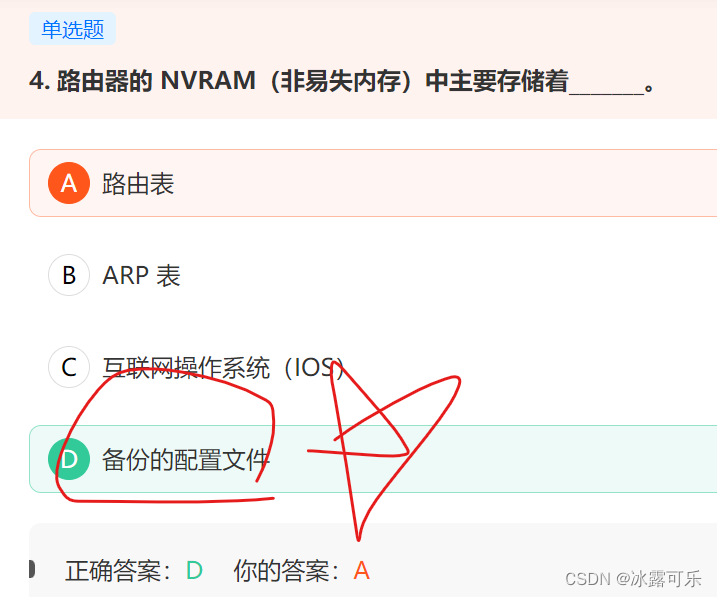
- NVRAM是路由器用来保存配置文件的地方。
- hub和中继器一样,都属于物理层设备,共享带宽和冲突域,是可以用来构建局域网的。
- MAC地址通常存储在计算机的网卡ROM中,固化在网卡上串行EEPROM中的物理地址
- 统一帧的长度比可变帧长度吞吐量要高
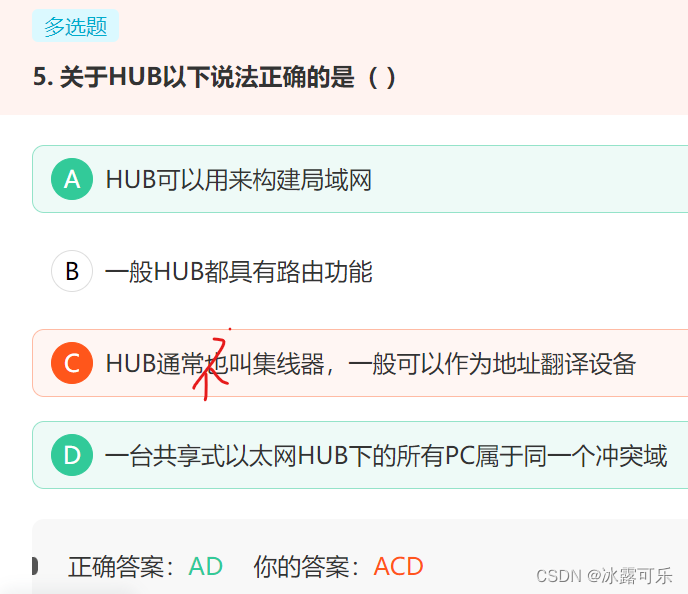
- 下列哪些协议与发送电子邮件有关( )
- 流式文件是指无结构的文件,这种说法正确
- 虚拟存储管理的调页技术有( )
- 从功能上讲,计算机硬件主要由________部件组成。
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记36
- @[TOC](文章目录)
- 数据挖掘
- 可视化分析
- 在TCP/IP体系结构中,直接为ICMP提供服务的协议是()。
- NVRAM是路由器用来保存配置文件的地方。
- hub和中继器一样,都属于物理层设备,共享带宽和冲突域,是可以用来构建局域网的。
- MAC地址通常存储在计算机的网卡ROM中,固化在网卡上串行EEPROM中的物理地址
- 统一帧的长度比可变帧长度吞吐量要高
- 下列哪些协议与发送电子邮件有关( )
- 流式文件是指无结构的文件,这种说法正确
- 虚拟存储管理的调页技术有( )
- 从功能上讲,计算机硬件主要由________部件组成。
- 总结
数据挖掘
可视化分析
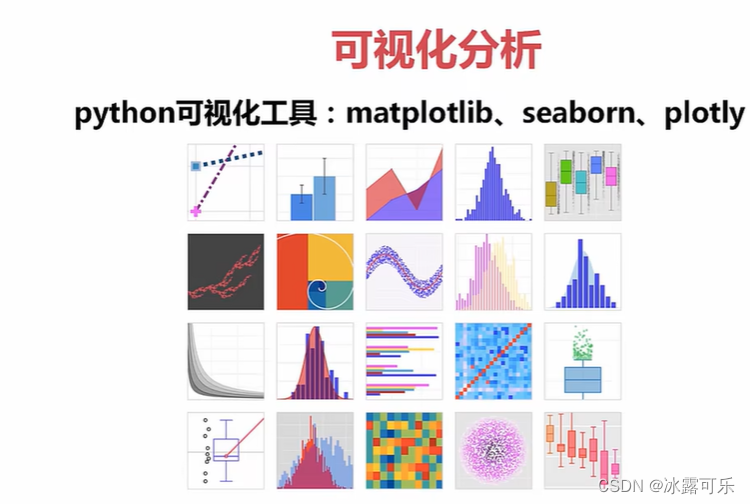
其实数据分析,是需要人直观的理解数据的内涵
那就需要可视化哦!!!
只有通过图表,展示规律,人们才能看懂,懂吧
seaborn绘图,表格
我见过
matplotlib:python绘图
plotly网页绘图
引入库:
seaborn
matplotlib
然后将薪水字段【HR.csv文件在文章34我说过哦】
的直方图高做个图
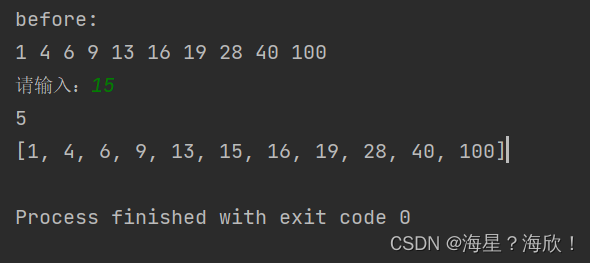
import pandas as pd
import numpy as np
import seaborn as sb
import matplotlib.pyplot as plt # 是它里面的函数
def f1():
df = pd.read_csv('HR_comma_sep.csv')
x = np.arange(len(df['salary'].value_counts()))
y = df['salary'].value_counts()
plt.bar(x, y)
plt.show()
if __name__ == '__main__':
f1()
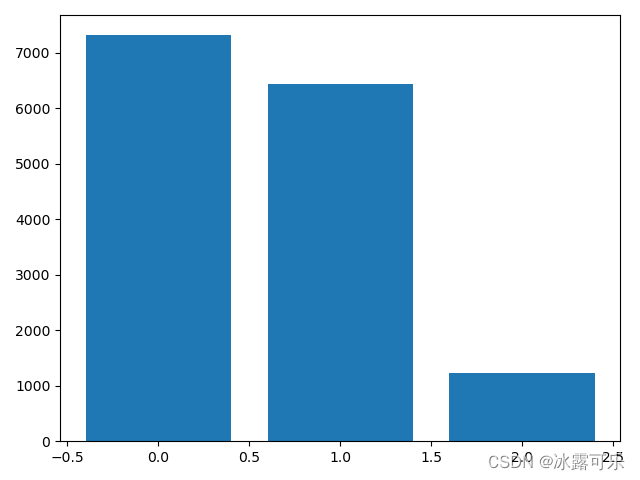
因为value_counts是一个序列
所以统计一个长度即可
可以加点标题啥的
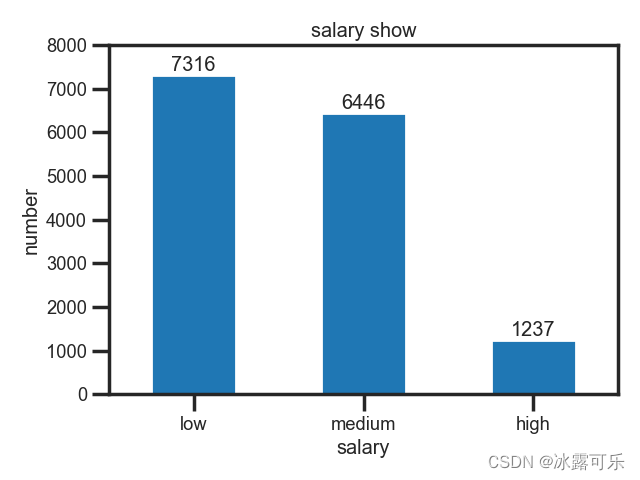
y长这样
low 7316
medium 6446
high 1237
Name: salary, dtype: int64
所以横坐标,我们需要标注为低中高仨字段
刻度长度就是我们统计的y的长度
import pandas as pd
import numpy as np
import seaborn as sb
import matplotlib.pyplot as plt # 是它里面的函数
def f1():
df = pd.read_csv('HR_comma_sep.csv')
x = np.arange(len(df['salary'].value_counts()))
y = df['salary'].value_counts()
print(y)
plt.bar(x, y)
plt.title('salary show')
plt.xlabel("salary")
plt.ylabel("number")
plt.xticks(x, y.index) # 将x轴的刻度,标注为y的index
plt.show()
if __name__ == '__main__':
f1()
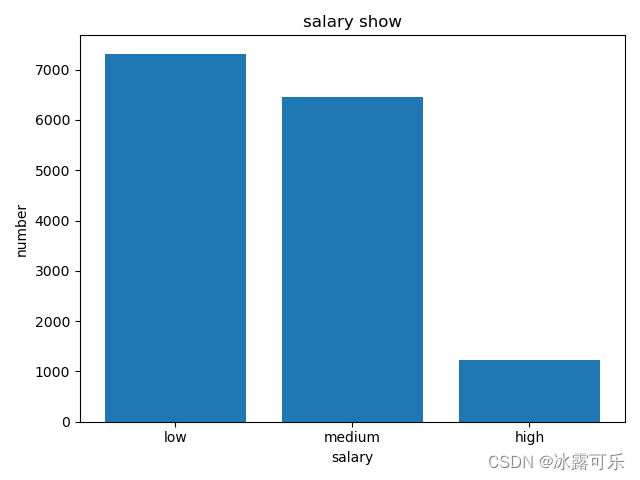
这样的话,一目了然
工薪低中高三种情况下
员工的人数
美滋滋
是不就发现高薪的人并不多
而底薪的人很多
都是这样的
当然,我们可以设置显示范围
plt.axis([0, 3, 0, 8000]) # 横轴范围,纵轴范围
plt.show()
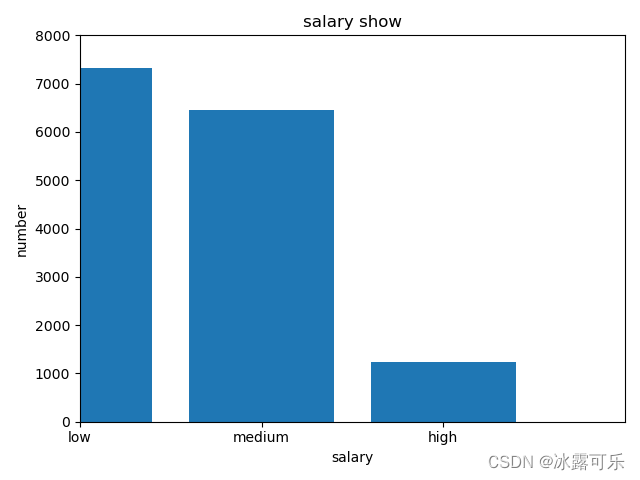
但是这个bar和xticks的位置就跑到了0点
因此我们需要将其向右平移0.5
直接在原来横坐标那加
import pandas as pd
import numpy as np
import seaborn as sb
import matplotlib.pyplot as plt # 是它里面的函数
def f1():
df = pd.read_csv('HR_comma_sep.csv')
x = np.arange(len(df['salary'].value_counts()))
y = df['salary'].value_counts()
print(y)
plt.bar(x + 0.5, y)
plt.title('salary show')
plt.xlabel("salary")
plt.ylabel("number")
plt.xticks(x + 0.5, y.index) # 将x轴的刻度,标注为y的index
plt.axis([0, 3, 0, 8000]) # 横轴范围,纵轴范围
plt.show()
if __name__ == '__main__':
f1()
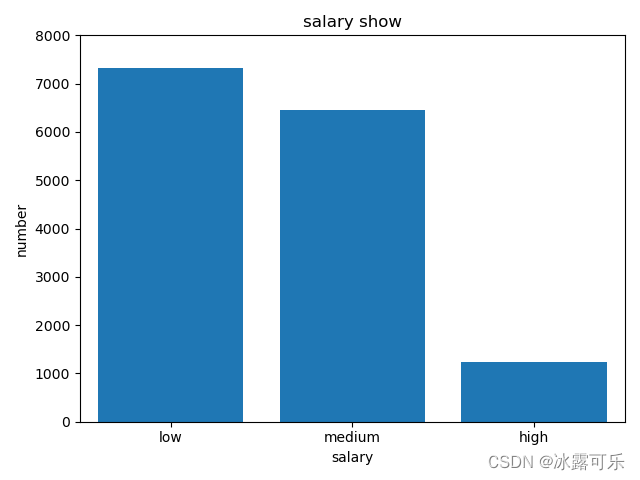
妥了
plt.bar(x + 0.5, y, width=0.5) # 设置条形图的宽度
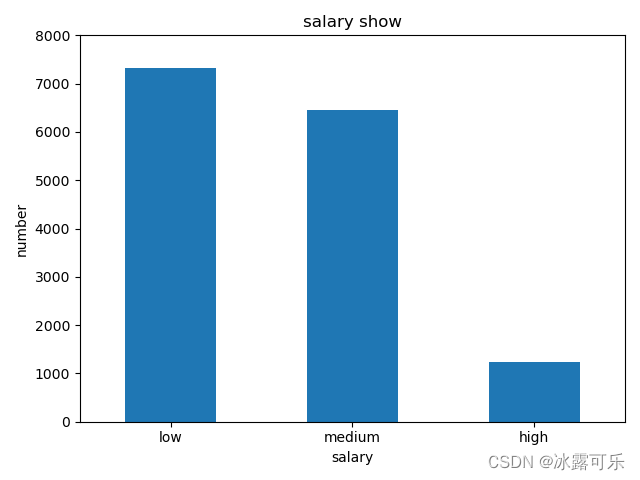
你还能把数据,放在图表上
用text把y放进去,但是需要你封装xy为坐标ab,方便挨个打印
坐标,是x+0.5和y
for a, b in zip(x+0.5, y):
plt.text(a, b, b, ha='center', va='bottom') # 按照ab这个坐标,挨个打印
看懂了吗
zip就是将x和y封装为坐标
打印的也是这个y坐标,因为它是数量
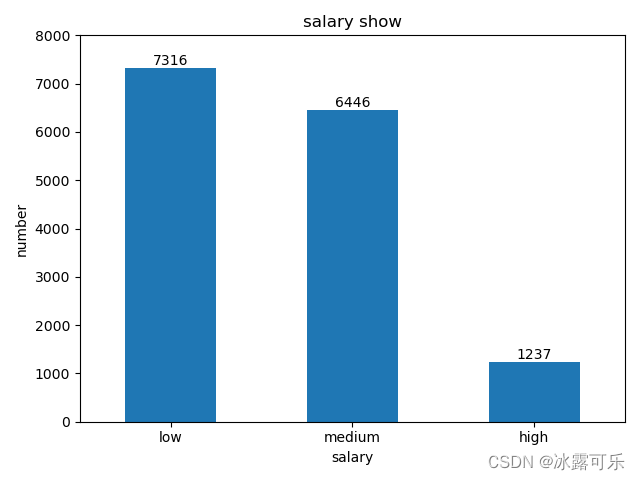
这就是matplotlib的用法
下面我们看看seaborn的用法
比如用seaborn把这个图表的格式改改
把表格风格设置为darkgrid暗网格
import pandas as pd
import numpy as np
import seaborn as sb
import matplotlib.pyplot as plt # 是它里面的函数
def f1():
df = pd.read_csv('HR_comma_sep.csv')
x = np.arange(len(df['salary'].value_counts()))
y = df['salary'].value_counts()
# print(y)
sb.set_style(style='darkgrid')
plt.bar(x + 0.5, y, width=0.5) # 设置条形图的宽度
plt.title('salary show')
plt.xlabel("salary")
plt.ylabel("number")
plt.xticks(x + 0.5, y.index) # 将x轴的刻度,标注为y的index
plt.axis([0, 3, 0, 8000]) # 横轴范围,纵轴范围
for a, b in zip(x+0.5, y):
plt.text(a, b, b, ha='center', va='bottom') # 按照ab这个坐标,挨个打印
plt.show()
if __name__ == '__main__':
f1()
把代码放前面哦
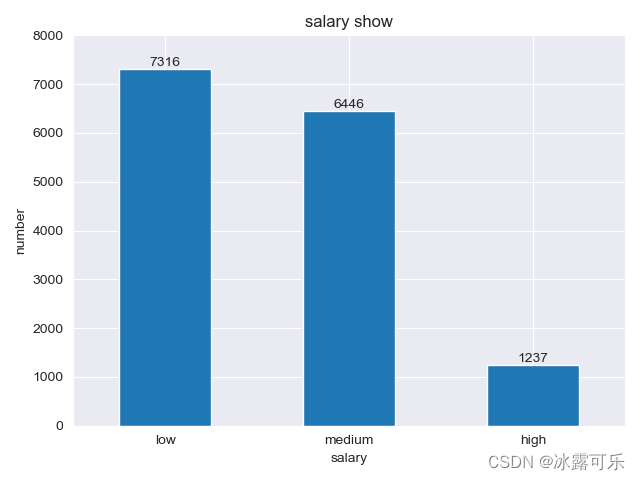
咋样,逼格是否高一些???
你可以去看看函数set_style,它的取值有这些
Parameters
----------
style : dict, None, or one of {darkgrid, whitegrid, dark, white, ticks}
A dictionary of parameters or the name of a preconfigured set.
白色,ticks是啥我看看
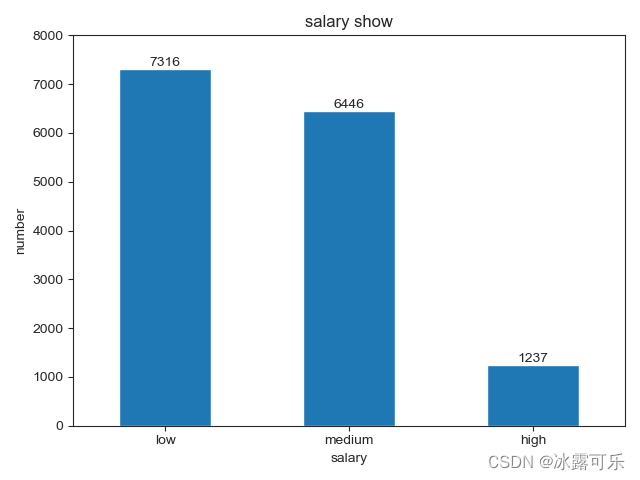
貌似就这样
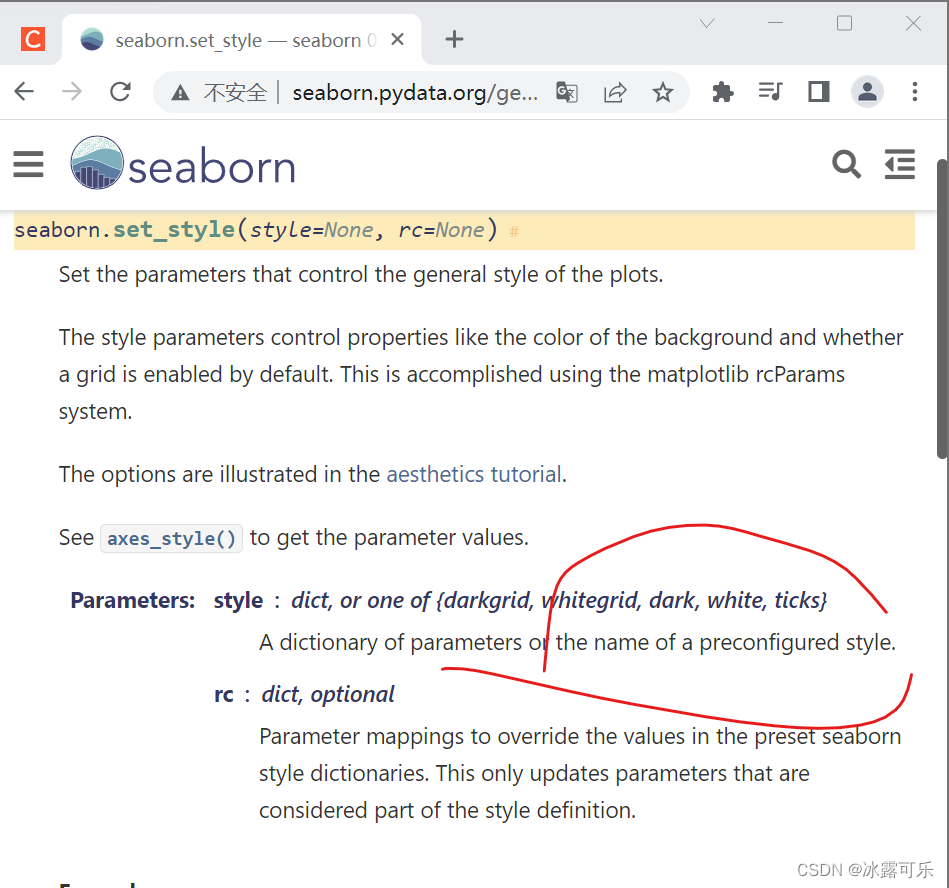
烦着不会就可以去官网上查一波
easy
设置字体的话,gg
反正不同的字体都可以设置
sb.set_context(context='poster',) # 设置字体的
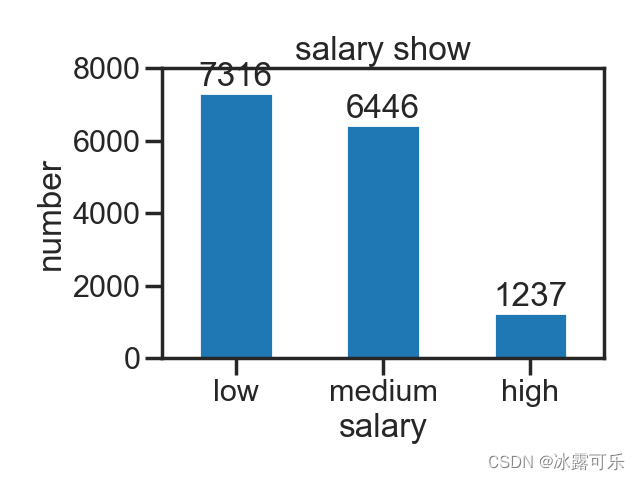
那是因为参数中的font_scale大小为1,或者1.5
放大了
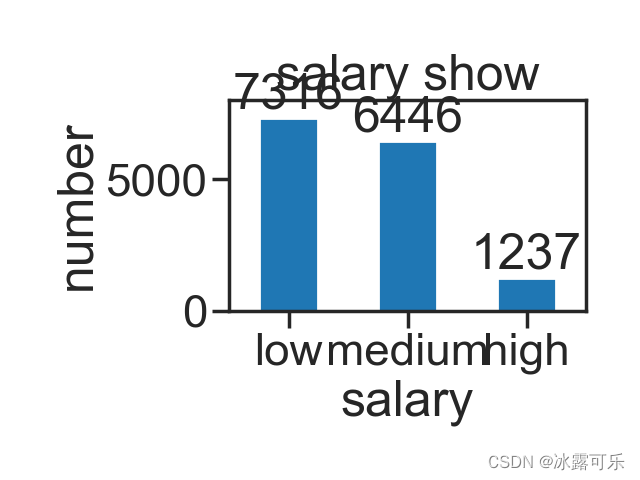
咱可以将其设置为0.8试试
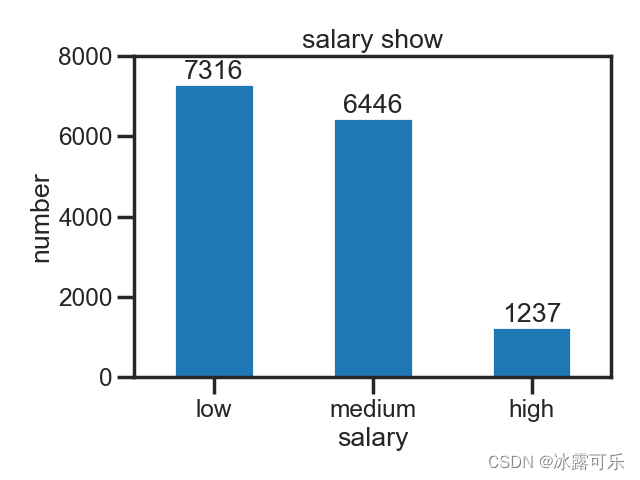
这是0.6的
这样看着就爽了
当然我们还可以设置颜色
它英文是调色板
所以就函数叫这个,懂?
seaborn.set_palette(palette, n_colors=None, desat=None, color_codes=False)
Set the matplotlib color cycle using a seaborn palette.
Parameters:
paletteseaborn color paltte | matplotlib colormap | hls | husl
Palette definition. Should be something color_palette() can process.
n_colorsint
Number of colors in the cycle. The default number of colors will depend on the format of palette, see the color_palette() documentation for more information.
desatfloat
Proportion to desaturate each color by.
color_codesbool
If True and palette is a seaborn palette, remap the shorthand color codes (e.g. “b”, “g”, “r”, etc.) to the colors from this palette.
里面的参数
matplotlib colormap
我们去matplotlib官网瞅瞅
里面有很多色系,你可以选择不同的名字展示
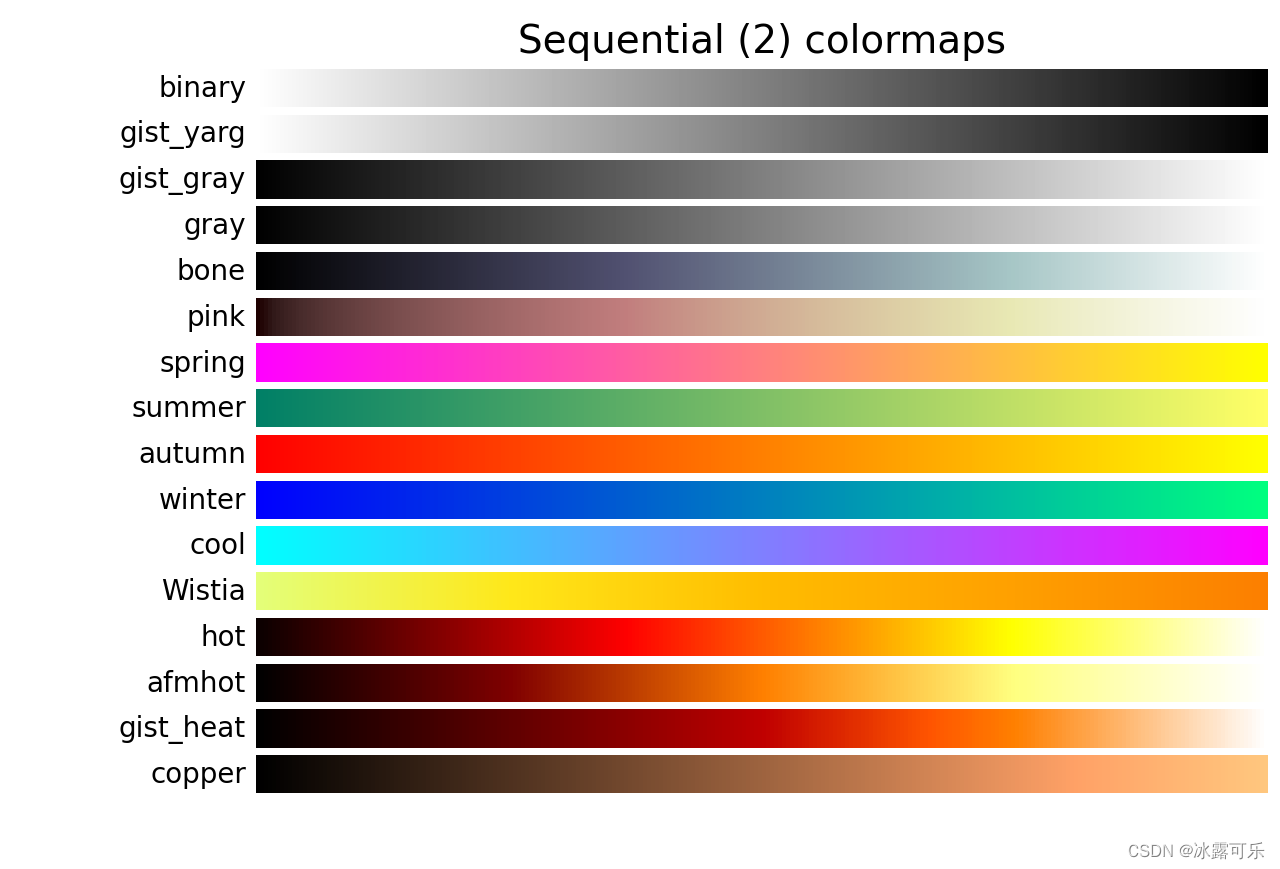
比如
sb.set_palette(palette='summer') # 调色板
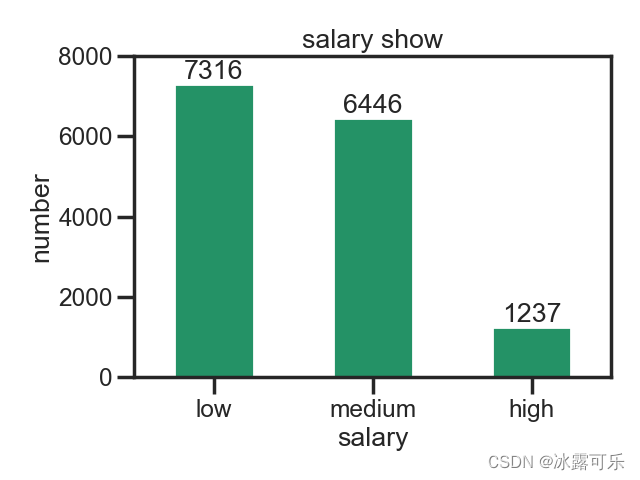
得到了一波绿色,骚啊
这是matplotlib的色板
我们去看看seaborn的呢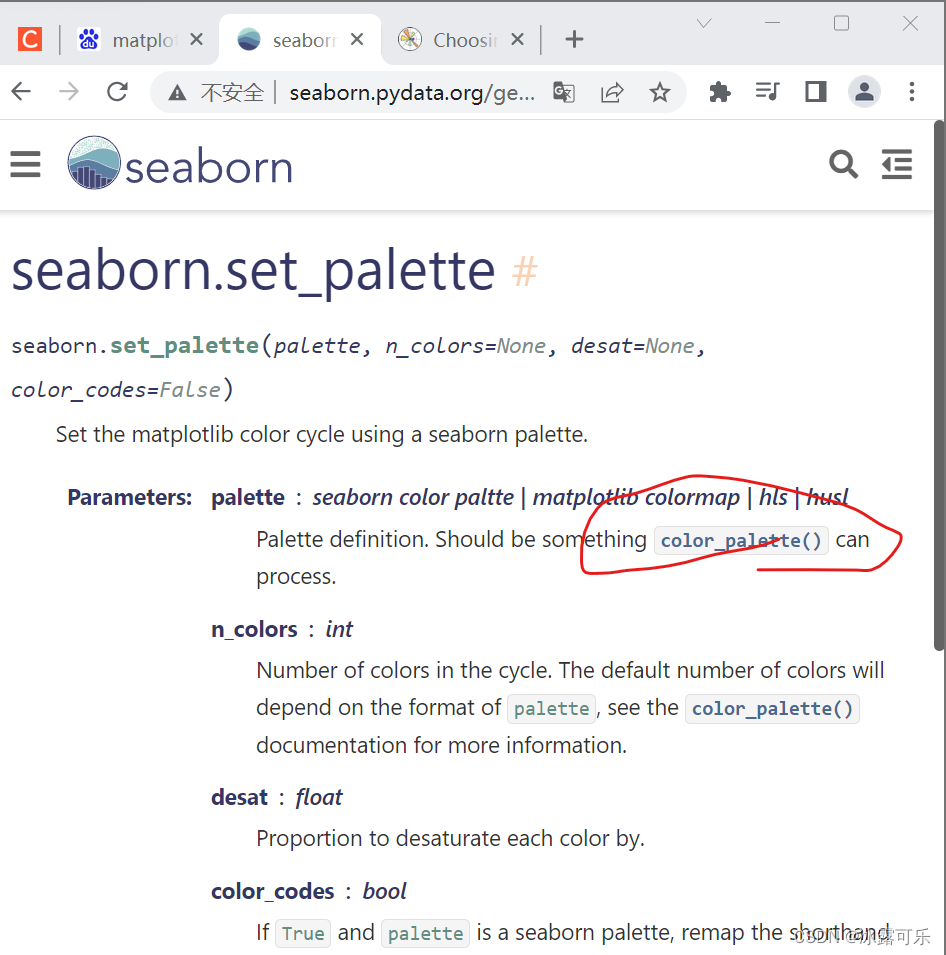
我们可以用这种默认的调色板,选择第几号n颜色
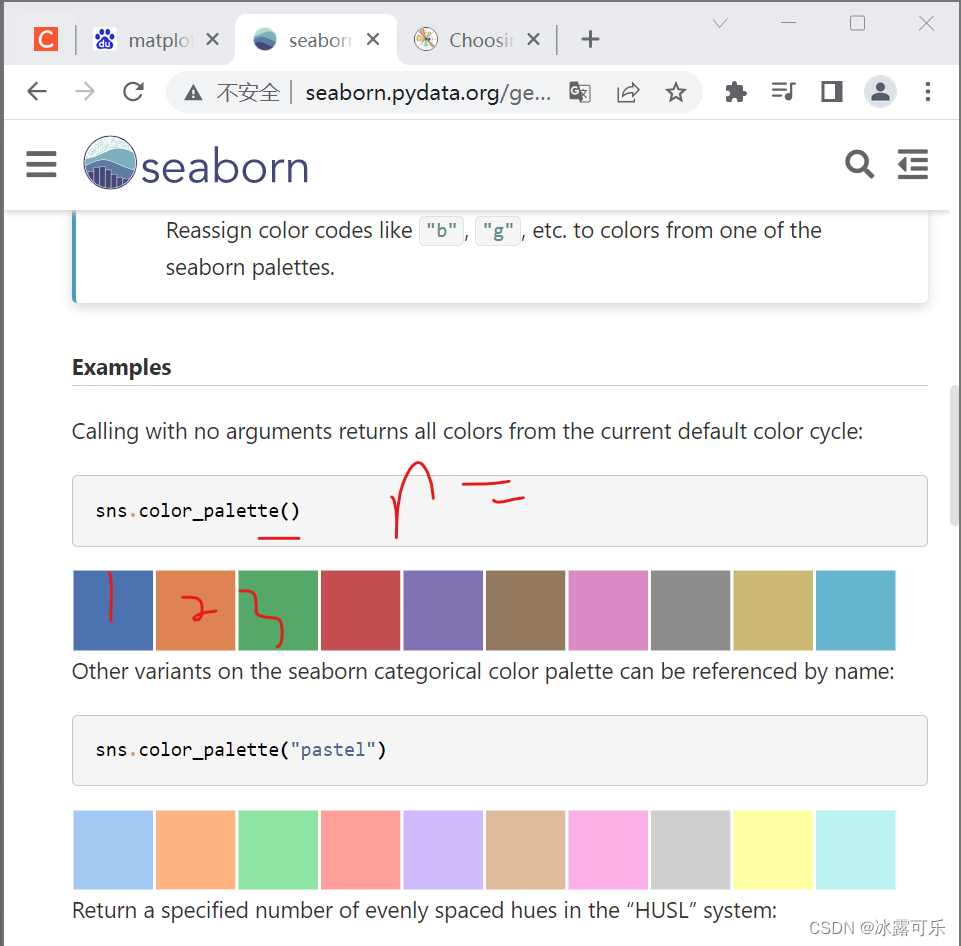
sb.set_palette(sb.color_palette(n_colors=1)) # seaborn调色板
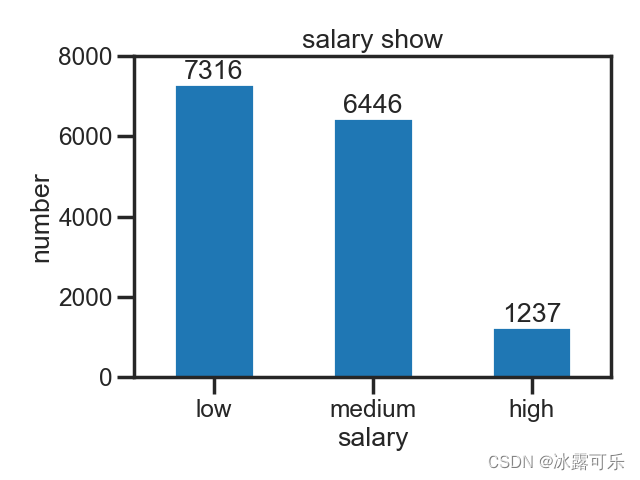
然后这个图就出来了懂吧?
你可以换一个
sb.set_palette(sb.color_palette("pastel", n_colors=4)) # seaborn调色板
这样得到数组,默认用0
需要下面这样
sb.set_palette([sb.color_palette("pastel", 4)[3]]) # seaborn调色板
返回一个数组,用3号颜色,也就是第4个
然后放进[]数组中,这样它才能识别
一定要小心哦
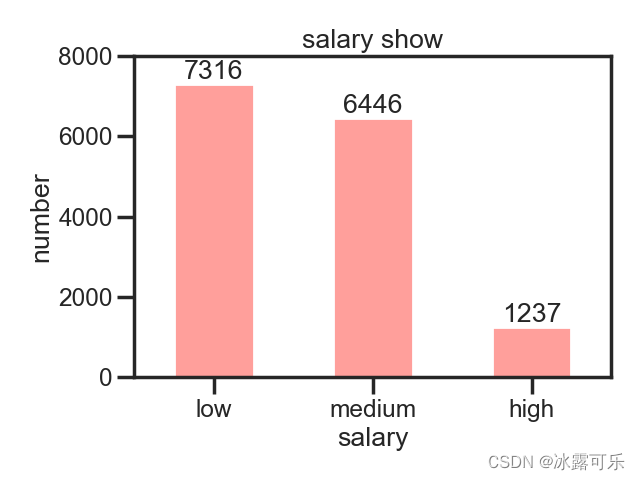
这样就对上了
OK吧
所有代码:
import pandas as pd
import numpy as np
import seaborn as sb
import matplotlib.pyplot as plt # 是它里面的函数
def f1():
df = pd.read_csv('HR_comma_sep.csv')
x = np.arange(len(df['salary'].value_counts()))
y = df['salary'].value_counts()
# print(y)
sb.set_style(style='ticks')
sb.set_context(context='poster', font_scale=0.8) # 设置字体的
# sb.set_palette(palette='summer') # matplotlib调色板
sb.set_palette([sb.color_palette("pastel", 4)[3]]) # seaborn调色板
plt.bar(x + 0.5, y, width=0.5) # 设置条形图的宽度
plt.title('salary show')
plt.xlabel("salary")
plt.ylabel("number")
plt.xticks(x + 0.5, y.index) # 将x轴的刻度,标注为y的index
plt.axis([0, 3, 0, 8000]) # 横轴范围,纵轴范围
for a, b in zip(x+0.5, y):
plt.text(a, b, b, ha='center', va='bottom') # 按照ab这个坐标,挨个打印
plt.show()
if __name__ == '__main__':
f1()
美滋滋吧,舒服,官网瞅瞅,学习就是了
seaborn和matplotlib一样,可以画柱状图
def f2():
df = pd.read_csv('HR_comma_sep.csv')
sb.set_style(style='ticks')
sb.set_context(context='poster', font_scale=0.8) # 设置字体的
# sb.set_palette(palette='summer') # matplotlib调色板
sb.set_palette([sb.color_palette("pastel", 4)[3]]) # seaborn调色板
# plt.bar(x + 0.5, y, width=0.5) # 设置条形图的宽度
sb.countplot(x='salary', data=df)
plt.show()
它自动对其,美滋滋啊
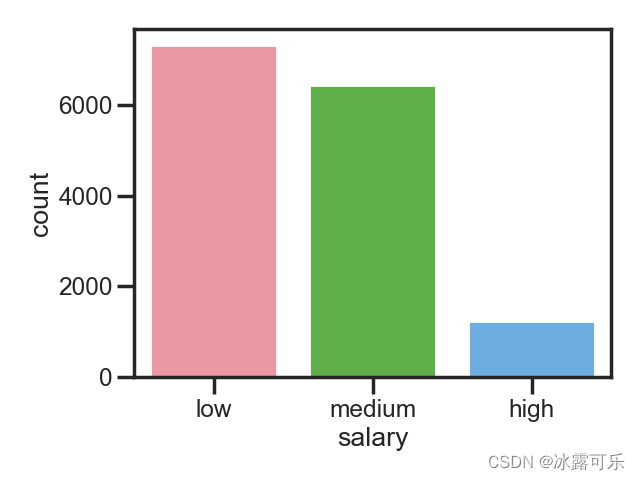
这countplot还有分组聚合的功能
比如,咱们按照部门分组,再去统计的话,就会有单独的几个表
def f2():
df = pd.read_csv('HR_comma_sep.csv')
sb.set_style(style='ticks')
sb.set_context(context='poster', font_scale=0.8) # 设置字体的
# sb.set_palette(palette='summer') # matplotlib调色板
sb.set_palette([sb.color_palette("pastel", 4)[3]]) # seaborn调色板
# plt.bar(x + 0.5, y, width=0.5) # 设置条形图的宽度
sb.countplot(x='salary', data=df, hue='department') # 按照部门分组看看
plt.show()
if __name__ == '__main__':
f2()
很牛的
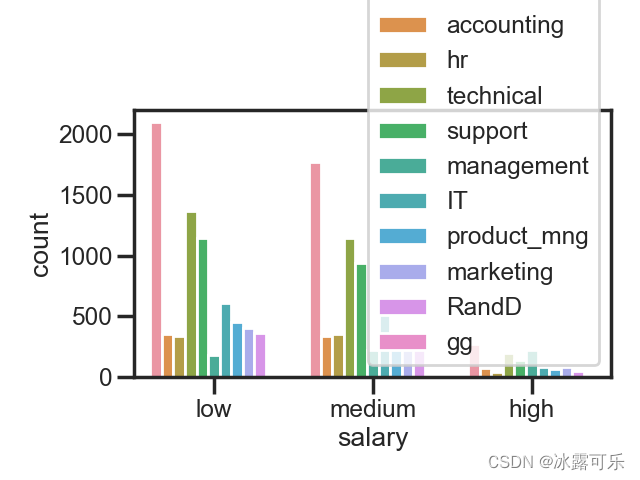
这波就按照不同的部门分组展示了
骚吧?
在TCP/IP体系结构中,直接为ICMP提供服务的协议是()。
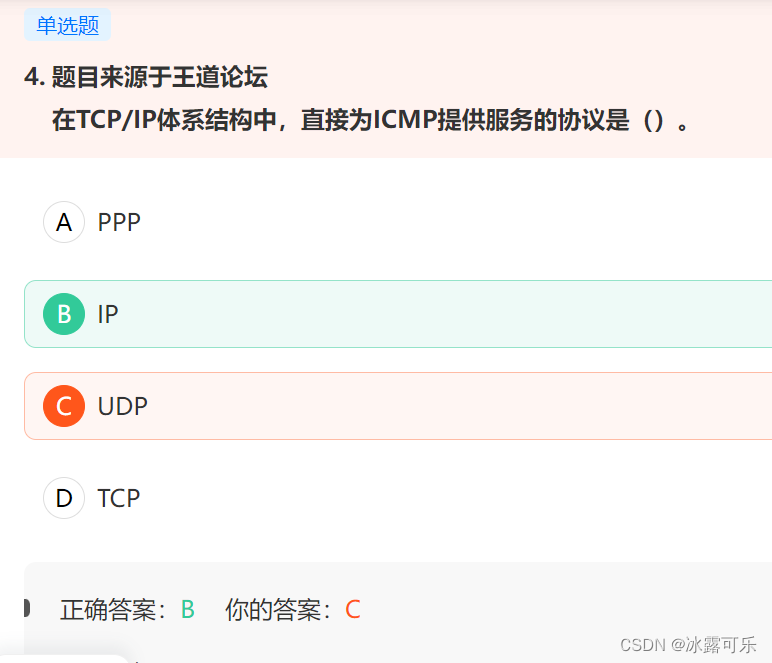
ICMP报文作为数据字段封装在IP分组中,因此,IP协议直接为ICMP提供服务。
UDP和TCP都是传输层协议,为应用层提供服务。
PPP协议是链路层协议,为网络层提供服务。
NVRAM是路由器用来保存配置文件的地方。
hub和中继器一样,都属于物理层设备,共享带宽和冲突域,是可以用来构建局域网的。
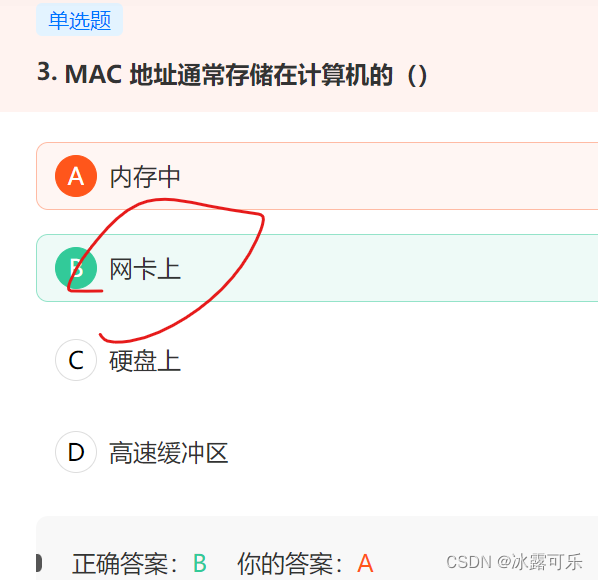
MAC地址通常存储在计算机的网卡ROM中,固化在网卡上串行EEPROM中的物理地址
牛逼
统一帧的长度比可变帧长度吞吐量要高
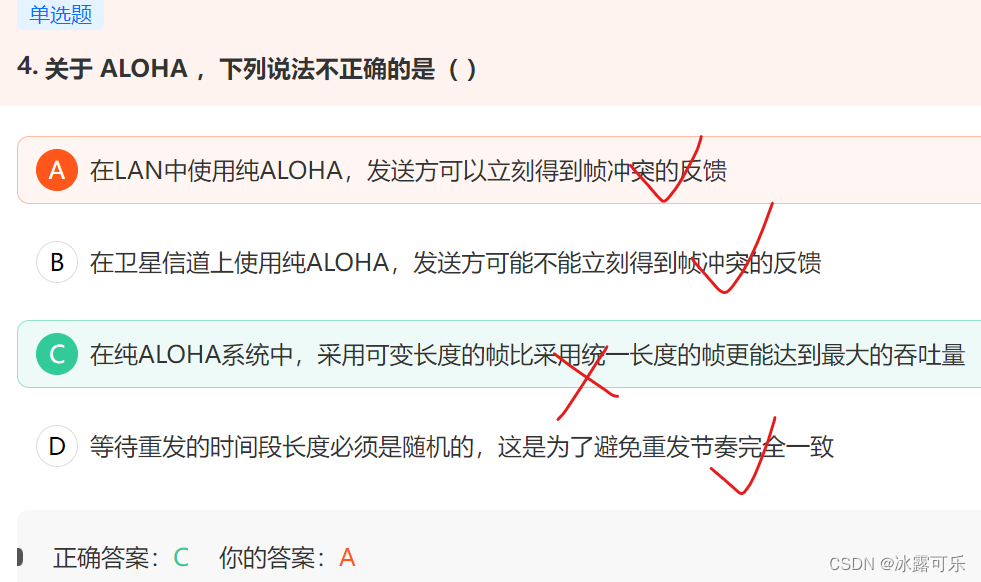
因为ALHOA冲突等待的时隙就是根据发送一帧所需的时间设定的,如果帧长度不固定,那样时隙也无法确定,那样就无法确定等待多久合适,如果等待时间短了其他帧还没发送完,则此时发送会冲突,等待长了浪费信道
下列哪些协议与发送电子邮件有关( )
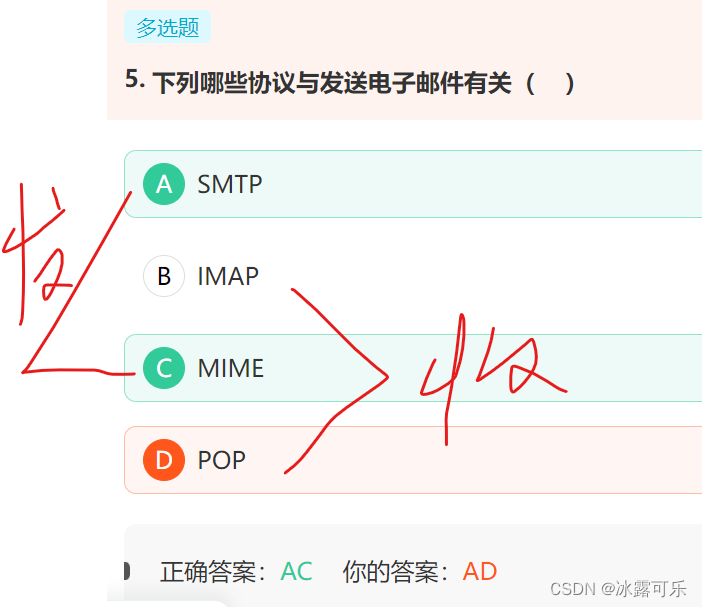
SMTP(简单邮件传送协议)【发】、POP(邮局协议)【收】、
MIME(通用互联网邮件扩充)【发】、IMAP(网际报文存取协议)【收】
第二次错误了,一发一收,别整错了
流式文件是指无结构的文件,这种说法正确
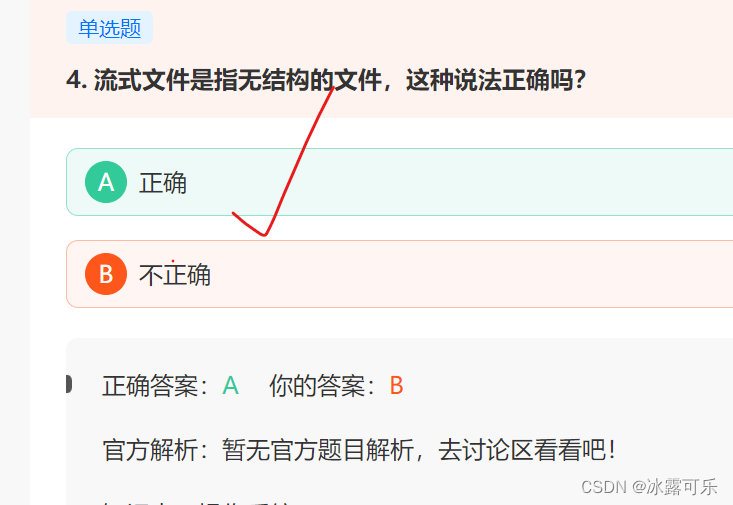
有结构叫记录式文件
虚拟存储管理的调页技术有( )
调页技术而不是调度算法
页面置换算法:选择要换出的页面。 调页技术:将页面从外存调入内存。
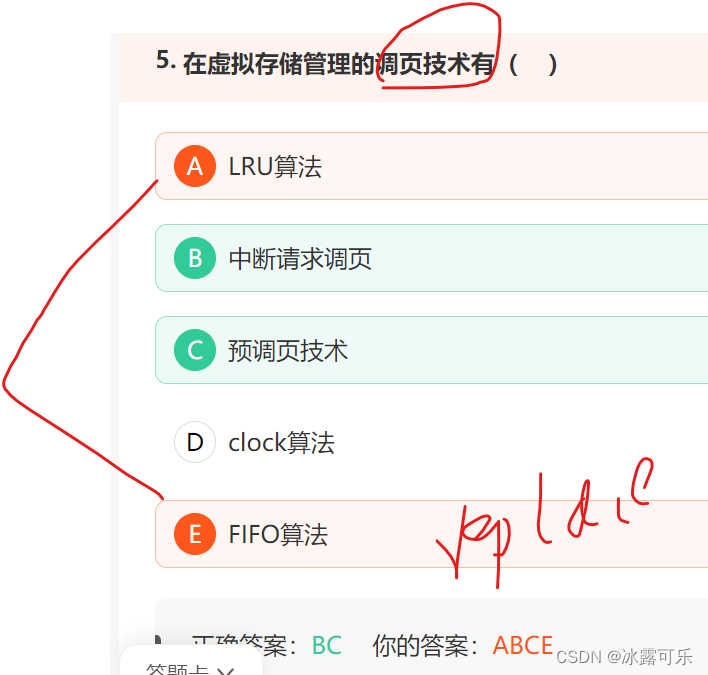
LRU和FIFO是内存替换算法,换出去
而调页是调入
骚
恶心人的题目
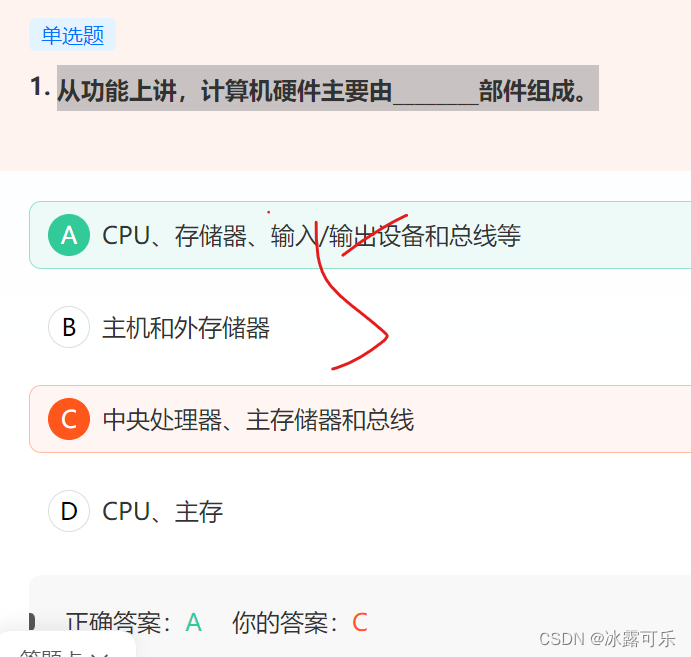
从功能上讲,计算机硬件主要由________部件组成。
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。