CRUD
所有的 CRUD 操作,必须在 session 的前提下进行。
构建 session 对象(实例)
所有和数据库的 ORM 操作都必须通过一个叫做 session 的会话对象来实现。
from sqlalchemy.orm import sessionmaker
# 构建 session 对象
# engine 为之前创建的数据库连接引擎
session = sessionmaker(bind=engine)()
解释:
sessionmaker(bind=engine): 这部分创建了一个session工厂,这个工厂被配置成使用我们之前创建的engine作为连接源。engine对象负责实际的数据库通信。(): 这部分实际上调用了我们刚刚创建的session工厂,生成了一个session实例。这个session实例表示一个“会话”,它是我们进行数据库操作的主要接口。
添加对象
一个对象
# 添加一个对象
# 创建一个对象
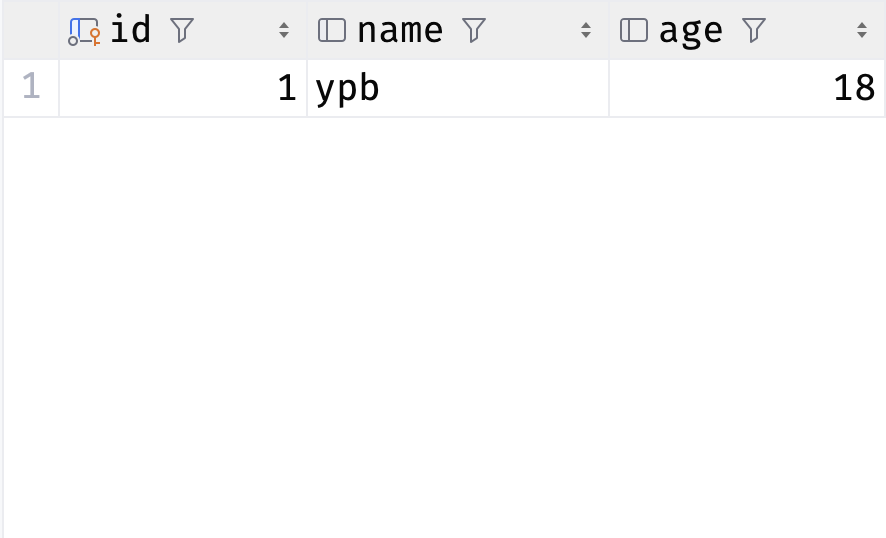
p1 = User(name='ypb', age=18)
# 将对象添加到 session 会话对象中
session.add(p1)
# 将 session 中的对象做 commit(提交)
session.commit()
数据库表
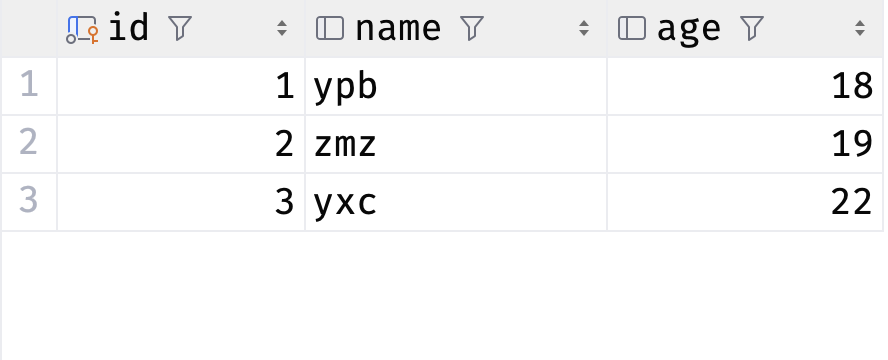
多个对象
# 一次性添加多个对象
p2 = User(name='zmz', age=19)
p3 = User(name='yxc', age=22)
session.add_all([p2, p3])
session.commit()
数据库表

查找对象
查找某个模型对应的表中的所有数据
# 查找某个模型对应的那个表中所有的数据
all_users = session.query(User).all()
for user in all_users:
print(user)
'''
print(user) 输出的内容:
<SqlAIchemy.model.main.User object at 0x104b1c2e0>
<SqlAIchemy.model.main.User object at 0x104b1c340>
<SqlAIchemy.model.main.User object at 0x104b1c220>
'''
这样的查询时,得到的结果是一个 User 对象的列表,而不是原始的数据库数据。
如果想看到原始的数据库数据,需要在 User 类中定义一个 __repr__() 方法来指定 User 对象的字符串表示形式。
class User(Base):
# ...
def __repr__(self):
return f"<User(name={self.name}, age={self.age})>"
然后当你打印 User 对象时,将会看到类似 <User(name=ypb, age=18)> 这样的输出,这就是这个 User 对象对应的数据库数据。
查询输出结果:
<User(name=ypb, age=18)>
<User(name=zmz, age=18)>
<User(name=yxc, age=22)>
filter_by 来做条件查询
# filter_by 进行条件查询
all_users = session.query(User).filter_by(age=18).all()
for user in all_users:
print(user)
查询输出结果:
<User(name=ypb, age=18)>
<User(name=zmz, age=18)>
使用 filter 来做条件查询
# filter 进行 条件查询
all_users = session.query(User).filter(User.age == 18).all()
for user in all_users:
print(user)
查询输出结果:
<User(name=ypb, age=18)>
<User(name=zmz, age=18)>
filter 与 filter_by 的对比
filter_by() 和 filter() 都是用来进行条件查询的方法,但是它们在语法和使用上有一些差异。
-
filter_by()方法使用关键字参数来表示查询条件,它的参数是以属性名=值的形式给出的。比如session.query(User).filter_by(age=18).all(),这个查询表示的是 “找出User表中所有age等于18的记录”。 -
filter()方法则更加通用和灵活,它支持更多种类的查询条件。你可以使用 Python 的比较运算符(如==,!=,>,<等)来定义查询条件,并且可以使用and_(),or_()等函数来组合多个查询条件。比如session.query(User).filter(User.age == 18).all(),这个查询的含义与上面的filter_by()查询是一样的,但你还可以写出更复杂的查询,比如session.query(User).filter(User.age > 18, User.name == 'ypb').all()。
filter_by() 更适合简单的查询,而 filter() 则更适合复杂的查询。
get进行主键查找
# 使用 get 方法查找数据, 根据主键进行查找(使用一下方法可能存在兼容性问题)
user = session.query(User).get(1)
# 建议使用 user = session.get(User, 1)
print(user)
查询输出结果:
<User(name=ypb, age=18)>
first 返回第一条数据
# 使用 first 返回表中的第一条数据
user = session.query(User).first()
print(user)
查询输出结果:
<User(name=ypb, age=18)>
修改对象
首先从数据库中查找对象,然后将这条数据修改为想要的数据,最后做 commit 操作就可以修改数据了。
# 修改对象
user = session.query(User).filter_by(name='zmz').all()
for u in user:
u.age = 19
session.commit()
数据库表
删除对象
将需要删除的数据从数据库中查找出来,然后使用 session.delete 方法将这条数据从 session 中删除,最后做 commit 操作就可以了。
# 删除对象
user = session.query(User).filter_by(name='zmz').first()
if user is not None:
session.delete(user)
session.commit()
数据库表

注意
- 在 SQLAlchemy 中,
Session是操作数据库的主要接口。你需要保证在每次数据库操作后正确地关闭Session。如果你使用的是 Flask-SQLAlchemy,它会自动帮你管理Session,但如果你直接使用 SQLAlchemy,你需要自己管理。 - 事务处理:在进行
CRUD操作时,你需要注意事务的处理。如果你在一个事务中进行了多个操作,那么你需要保证这些操作要么全部成功,要么全部失败。你可以使用 SQLAlchemy 的session.commit()和session.rollback()来控制事务。 - 数据安全:在进行
CRUD操作时,你需要注意防止 SQL 注入攻击。SQLAlchemy 的查询方法默认会帮你防止 SQL 注入,但如果你使用 raw SQL 或者text()方法来执行查询,你需要自己确保 SQL 的安全。