文章目录
- 《深入对比:在大数据分析中的 ClickHouse和Elasticsearch》
- 1 介绍
- 2 深入非关系型数据库的世界
- 2.1 非关系型数据库的种类
- 2.2 列存储数据库(如ClickHouse)
- 2.3 搜索引擎(如Elasticsearch)
- 2.4 核心优势的归纳
- 3 ClickHouse架构深掘
- 3.1 列存储的内部机制
- 3.1.1 `列存储`?
- 3.1.2 稀疏索引(Sparse Index)?
- 3.2 向量引擎的工作原理
- 3.2.1 SIMD 技术如何优化查询性能 (ClickHouse)
- 3.2.2 ANN 流程 (Elasticsearch)
- 3.3 数据分片与复制
- 3.4 总结
- 工作机制
- 节点故障处理
- 4 Elasticsearch架构解析
- 4.1 倒排索引的底层原理:从文档到索引的转换过程
- 4.1.1 文档的预处理
- 4.1.2 创建倒排记录
- 4.2 分布式架构详解:节点、分片与负载均衡
- 4.3 实时数据分析的技术支持:如何处理海量数据流
- 分析器(Analyzer)
- Lucene 的索引过程
- Lucene 的查询过程
- 示例与工作机制 —— 搜索的核心技术是倒排索引和布隆过滤器
- 5 核心技术对比
- 5.1 查询对比实战:Elasticsearch vs ClickHouse
- 测试架构
- 测试数据和查询方法
- 测试结果与分析
- 总结与结论
- 5.2 总结
- 6 应用案例与场景匹配
- 如何根据业务需求选择技术平台
- 7 性能挑战与优化策略
- 7.1 面对大规模数据集的性能调优案例
- 7.2 高级功能:聚合与数据压缩技术详解
- 7.3 扩展性与生态系统的长期支持
- 8 结论与战略建议
- 8.1 总结两种技术的关键优势与局限
- 8.2 建议

《深入对比:在大数据分析中的 ClickHouse和Elasticsearch》
在现代大数据分析中,ClickHouse和Elasticsearch作为两大非关系型数据库的代表,各具特色与优势。本篇文章深入比较了两者的架构设计、查询性能、数据存储方式以及应用场景。通过详细的技术解析和实战案例,我们探讨了如何根据业务需求选择合适的平台,优化系统性能,并提出了针对大规模数据集的性能调优策略。无论您是需要高效分析和报表的ClickHouse,还是需要强大实时搜索和日志分析的Elasticsearch,本篇文章将为您提供全面的技术指导和战略建议。
1 介绍
- 主题:《深入对比:在大数据分析中的 ClickHouse和Elasticsearch》
- 概览
- 1 介绍
- 2 深入非关系型数据库的世界
- 3 ClickHouse架构深掘
- 4 Elasticsearch架构解析
- 5 核心技术对比
- 6 应用案例与场景匹配
- 7 性能挑战与优化策略
- 8 结论与战略建议
- 9 互动问答
2 深入非关系型数据库的世界
- 非关系型数据库的种类与核心优势
- ClickHouse与Elasticsearch的定位与核心功能
–
2.1 非关系型数据库的种类
| 类型 | 代表技术 | 存储方式 | 主要特点 | 适用场景 |
|---|---|---|---|---|
| 键值存储 | Redis | 键值对存储 | 读写性能高,支持数据持久化 | 缓存,高速查询场景 |
| 文档数据库 | MongoDB | 文档形式存储 | 数据模型灵活,支持复杂的嵌套数据结构 | 需频繁变更数据结构的应用 |
| 列存储数据库 | Clickhouse | 列式存储 | 优化读操作,高效进行大规模数据处理 | 大数据分析,在线分析处理(OLAP) |
| 搜索引擎 | ElasticSearch | 倒排索引 | 支持复杂查询和实时分析,优化文本搜索 | 全文搜索,实时数据分析 |
| 图数据库 | Neo4j | 图结构 | 优化路径查询,能高效处理复杂的网络结构 | 社交网络,推荐系统等 |
| 宽列存储 | Cassandra | 列族存储 | 扩展性强,高可用性,适合写密集型应用 | 分布式数据管理,实时监控系统 |
| 时间序列数据库 | InfluxDB | 时间序列数据 | 高效处理时间标记数据,优化时间序列查询和存储 | 监控,物联网,实时分析 |
| 对象存储 | Ceph | 对象存储 | 数据自动分散,支持大规模存储 | 大数据存储,云存储服务 |
note: 对应于上表每种数据库的“现实应用举例”列内容:
- 文档数据库 (MongoDB):社交媒体内容存储,电商平台的用户数据和产品目录
- 列存储数据库 (ClickHouse):金融行业的交易分析,互联网公司的用户行为日志分析
- 键值存储 (Redis):高访问负载的网站的会话管理,实时排行榜
- 图数据库 (Neo4j):欺诈检测系统,知识图谱的构建和查询
- 搜索引擎 (Elasticsearch):新闻网站的文章搜索引擎,电商平台的商品搜索和筛选
- 宽列存储 (Cassandra):通信公司的呼叫记录分析,大型社交网络的消息数据存储
- 时间序列数据库 (InfluxDB):能源监测系统的实时数据分析,物联网设备的数据监控
- 对象存储 (Ceph):云服务提供商的大规模文件存储,医疗影像的存储和备份
OLAP (Online Analytical Processing)
对应于上表每种数据库的“现实应用举例”列内容:
- 文档数据库 (MongoDB):社交媒体内容存储,电商平台的用户数据和产品目录
- 列存储数据库 (ClickHouse):金融行业的交易分析,互联网公司的用户行为日志分析
- 键值存储 (Redis):高访问负载的网站的会话管理,实时排行榜
- 图数据库 (Neo4j):欺诈检测系统,知识图谱的构建和查询
- 搜索引擎 (Elasticsearch):新闻网站的文章搜索引擎,电商平台的商品搜索和筛选
- 宽列存储 (Cassandra):通信公司的呼叫记录分析,大型社交网络的消息数据存储
- 时间序列数据库 (InfluxDB):能源监测系统的实时数据分析,物联网设备的数据监控
- 对象存储 (Ceph):云服务提供商的大规模文件存储,医疗影像的存储和备份
–
2.2 列存储数据库(如ClickHouse)
定义与底层原理: 列存储数据库将数据按列而非行存储,这意味着每一列的数据都被存放在一起。这种存储方式使得数据库可以高效地进行大规模的读操作,尤其是在执行聚合查询如计数、求和等操作时非常高效。
区别突出点: 列存储的优势在于IO优化和数据压缩方面,特别适合用于OLAP和大数据分析,与传统的行存储数据库在性能上有显著差异。
–
2.3 搜索引擎(如Elasticsearch)
定义与底层原理: 搜索引擎数据库使用倒排索引技术来优化文本搜索查询。它们支持全文搜索、复杂查询以及数据的实时分析,常见于需要处理大量文本数据的应用场景。
区别突出点: 搜索引擎的特点是能够处理和索引大量非结构化文本,提供复杂的搜索查询能力,与传统的关系数据库在文本处理上有本质的区别。
–
2.4 核心优势的归纳
- 可扩展性:大多数非关系型数据库支持水平扩展,易于处理大规模数据集。
- 灵活性:不严格要求固定的数据模式,可以动态调整数据属性。
- 专用性能:每种类型的非关系型数据库都针对特定的数据操作或查询优化,如文档数据库优化了文档的读写,列存储数据库优化了列间的聚合查询等。
- 高可用性与容错性:通过数据分片和复制,提高了数据的可用性和服务的稳定性。
3 ClickHouse架构深掘
- 列存储的内部机制:数据存储、读取优化
- 向量引擎的工作原理:如何提高查询处理速度
- 数据分片与复制:保证数据的高可用性与扩展性
–
–
3.1 列存储的内部机制
- 数据存储:
- ClickHouse将数据以列的形式存储,每一列的数据独立存放,这样可以大幅减少读取不需要的数据的情况,尤其是在执行大规模的分析查询时。列存储和行存储有什么区别?
- 列存储允许使用不同的数据压缩技术,针对每种类型的数据选择最优的压缩方法,从而减少存储空间需求并提高读取效率。
- 读取优化:
- 在查询执行时,只需读取相关的列数据,避免了传统行存储数据库中的无用数据读取,显著提高查询性能。
- 利用先进的索引策略(如稀疏索引),进一步提高查询速度,尤其在处理大数据集时更显优势。什么是稀疏索引? 和密集索引的区别?
–
3.1.1 列存储?
MySQL 行存储模式: 在 MySQL 中,数据是按行存储的。假设有一个用户表 users,包含如下字段:
CREATE TABLE users (
user_id INT,
user_name VARCHAR(50),
age INT,
email VARCHAR(100)
);
在行存储模式下,每一行的数据会被存储在一起:
| user_id | user_name | age | |
|---|---|---|---|
| 1 | Alice | 25 | alice@example.com |
| 2 | Bob | 30 | bob@example.com |
| 3 | Carol | 22 | carol@example.com |
–
ClickHouse 列存储模式: 在 ClickHouse 中,数据是按列存储的。相同的用户表 users 会存储为独立的列:
user_id: [1, 2, 3]
user_name: ["Alice", "Bob", "Carol"]
age: [25, 30, 22]
email: ["alice@example.com", "bob@example.com", "carol@example.com"]
-
优势一 —— 更好压缩: 同类型的数据存储在一起,压缩效果更好
- 比如年龄列中的数据都是整数,容易压缩
-
优势二 —— 高效的 I/O 操作: 读取列数据时,只需读取相关的列,而不需要读取整个行。
- 如,要查询所有用户的年龄,只需读取
age列,不需要读取其他列的数据。vs 在MySQL中, ‘SELECT user_name, age FROM users;’, 当业务需要频繁查询用户基本信息时, 需要读取整行数据,然后提取出user_name和age列,这会涉及大量的 I/O 操作。
- 如,要查询所有用户的年龄,只需读取
–
MongoDB 的数据存储方式不同,它是文档存储,即每个文档是一个独立的 JSON 对象:
{
"_id": 1,
"user_name": "Alice",
"age": 25
}
–
3.1.2 稀疏索引(Sparse Index)?
假设我们有一个表 users,其中包含 user_id, user_name, 和 age 列。数据按列存储, 假设数据存储在磁盘上的文件结构如下:
user_id文件:包含 [1, 2, 3, …]user_name文件:包含 [“Alice”, “Bob”, “Carol”, …]age文件:包含 [25, 30, 22, …]
为了查找 user_id = 1 的 user_name 和 age,
‘SELECT user_name, age FROM users WHERE user_id = 1;’
查询步骤如下:
- 查找
user_id列:- 读取
user_id列的文件,从头开始查找user_id = 1。 - 找到
user_id = 1位于第 0 行。
- 读取
- 定位其他列的数据:
- 使用找到的行号(第 0 行),从
user_name列和age列的文件中读取相应行的数据。 - 读取
user_name列的第 0 行,得到 “Alice”。 - 读取
age列的第 0 行,得到 25。
- 使用找到的行号(第 0 行),从
–
| 特性 | 密集索引(MySQL) | 稀疏索引(ClickHouse) |
|---|---|---|
| 定义描述 | 密集索引是为数据库表中的每个记录创建一个索引条目。每个键值在索引中都有一一对应的条目,提供非常快速的查找速度 | 稀疏索引仅为每个数据块(或页)的第一个记录创建索引条目。查找时先通过稀疏索引找到数据块,然后在块内顺序查找 |
| 索引特点 | 每行数据都有索引项 | 每隔一定数量的行记录一个索引项 |
| 查找速度 | 精确查找,B+ 树通常为 O(logF N) 时间复杂度,F 是分支因子 | 通过稀疏索引定位范围,然后进行范围扫描 |
| 存储开销 | 索引存储开销大 | 索引存储开销小 |
| 适用场景 | 高频率点查询和单行查询 | 大规模数据查询和批量分析 |
| 数据定位 | 通过索引直接定位到具体的数据行 | 先通过稀疏索引定位范围,再进行扫描 |
| 查询性能 | 点查询性能高 | 批量查询性能高 |
| 实现复杂性 | 实现和维护简单 | 实现和维护较为复杂 |
| 批量查询性能 | 批量查询性能较低,需要读取大量不相关数据 | 批量查询性能高,只读取相关列数据 |
| 存储结构 | 索引文件按主键排序,每个索引项指向具体的数据行 | 索引文件记录某个行的关键值及其在数据文件中的位置 |
| 点查询示例 | 查询 user_id = 1 的 user_name 和 age,通过主键索引直接定位到行 | 查询 user_id = 1 的 user_name 和 age,先通过稀疏索引定位范围,然后扫描具体行 |
| 批量查询示例 | 统计所有用户的平均年龄,需要读取所有行数据,包括不相关列数据 | 统计所有用户的平均年龄,只读取 age 列数据,通过向量化处理加速计算 |
| I/O 操作 | I/O 操作较多,特别是批量查询时 | I/O 操作较少,只读取相关列数据 |
–
“Dense indexes have an index entry for every search key value (and hence every record) in the file.”
“Sparse indexes have index entries for only some of the search values, usually the first record of each block.”
总结
- 密集索引(
Dense Index):适合点查询和高频率的单行查询,查找速度快,但索引存储开销大,批量查询性能较低。 - 稀疏索引(
Sparse Index):适合大规模数据查询和批量分析,存储效率高,但点查询性能相对较低。
–
3.2 向量引擎的工作原理
- 向量化查询:
- ClickHouse的向量引擎允许在单个操作中处理数据列的多个值,而非逐行处理。这种向量化的处理方式可以充分利用现代CPU的SIMD功能,实现数据处理的并行化。
- 通过减少CPU周期中的闲置和上下文切换,向量引擎大幅提升了查询处理速度。
–
3.2.1 SIMD 技术如何优化查询性能 (ClickHouse)
SIMD(Single Instruction, Multiple Data) 技术允许在一个 CPU 指令周期内对多个数据进行并行处理。ClickHouse 利用 SIMD 技术实现高效的向量化查询。以下是一个形象的解释:
- 数据加载:
- ClickHouse 从列式存储中加载数据,例如一列包含1000个整数。
- 向量化处理:
- 传统查询处理方式是逐行处理,即一个循环处理一个数据项。SIMD 技术则通过加载多个数据到寄存器中,并对这些数据执行相同的操作。
- 例如,使用 AVX2 指令集,一个 256 位寄存器可以容纳 8 个 32 位整数。这样可以在一个指令周期内对 8 个整数进行加法运算,而不是逐个处理。
- 并行计算:
- 在 SIMD 技术的支持下,ClickHouse 的查询处理器可以同时对多个数据进行计算,比如过滤、聚合等操作,大大提升了查询性能。
–
示例:
假设有一个查询需要对一列数值进行求和,传统方式是逐行累加:
int sum = 0;
for (int i = 0; i < n; i++) {
sum += data[i];
}
使用 SIMD 技术,可以一次处理 8 个数值:
#include <immintrin.h> // 包含 AVX 指令集的头文件
int sum_array(int* data, int n) {
// 初始化一个 256 位的寄存器 sum,用于存储最终的结果, `_mm256_setzero_si256` 函数将寄存器所有位设为 0。
__m256i sum = _mm256_setzero_si256();
// 使用 AVX2 指令集一次处理 8 个 32 位整数
for (int i = 0; i < n; i += 8) {
// 将 8 个整数加载到寄存器 values 中
__m256i values = _mm256_loadu_si256((__m256i*)&data[i]);
// 对寄存器 `values` 中的 8 个整数进行并行加法运算,将 values 中的值累加到 sum 中
sum = _mm256_add_epi32(sum, values);
}
// 将寄存器 sum 中的 8 个整数合并为一个结果, 存储到数组 `result` 中
// 将寄存器 sum 中的 8 个整数合并为一个结果 // 使用 256 位寄存器分解成 128 位寄存器进行水平加和
__m128i sum_low = _mm256_castsi256_si128(sum);
__m128i sum_high = _mm256_extracti128_si256(sum, 1);
sum_low = _mm_add_epi32(sum_low, sum_high);
// 使用 128 位寄存器分解成 64 位寄存器进行水平加和
sum_low = _mm_add_epi32(sum_low, _mm_shuffle_epi32(sum_low, 0x0E));
sum_low = _mm_add_epi32(sum_low, _mm_shuffle_epi32(sum_low, 0x01));
// 提取最终的和
int total_sum = _mm_cvtsi128_si32(sum_low);
return total_sum;
}
–
3.2.2 ANN 流程 (Elasticsearch)
ANN(Approximate Nearest Neighbor) 是一种用于快速找到与查询向量最相似的向量的方法。Elasticsearch 使用 ANN 技术进行向量化查询,例如使用 HNSW(Hierarchical Navigable Small World)算法。
- 向量索引构建:
- 首先,对所有文档中的向量进行索引构建,创建一个近似最近邻索引结构,例如 HNSW 图。
- HNSW 图包含多个层,每一层都有较少的边,最高层是稀疏图,底层是稠密图。
- 查询阶段:
- 当有一个查询向量时,算法从最高层开始搜索,逐层向下。
- 每层中,算法会找到距离查询向量最近的几个向量(节点),然后在这些节点的邻居中继续搜索,直到达到底层。
- 近似搜索:
- 通过逐层搜索和局部优化,快速找到与查询向量最相似的几个向量。这种方法比精确最近邻搜索更快,适合处理大规模向量数据。
–
假设我们有一组文档向量,构建 HNSW 图如下:
Level 2: A--B--C
Level 1: D--E--F--G
Level 0: H--I--J--K--L
查询向量 Q 的搜索过程:
- 从最高层 Level 2 开始,找到与 Q 最接近的节点,例如 A。
- 从 A 的邻居开始搜索,找到与 Q 最接近的节点,例如 B。
- 转到 Level 1,继续从 B 的邻居中找到最接近 Q 的节点,例如 E。
- 逐层向下,直到 Level 0,找到最终的近似最近邻节点。
–
3.3 数据分片与复制
- 数据分片:
- ClickHouse通过将数据水平划分为多个分片来实现扩展性。每个分片可以部署在不同的服务器上,从而分散负载和优化资源利用。
- 分片机制允许并行处理查询,各分片同时处理数据查询的不同部分,极大提高了处理速度和系统的扩展性。
- 数据复制:
- 为了保证高可用性,ClickHouse支持数据的自动复制。在多个节点之间同步相同的数据分片,即使在部分节点发生故障时也能保证数据不丢失,并继续提供查询服务。
- 复制机制基于ZooKeeper来协调数据一致性和状态同步,确保系统的稳定性和数据的一致性。
–
3.4 总结
–
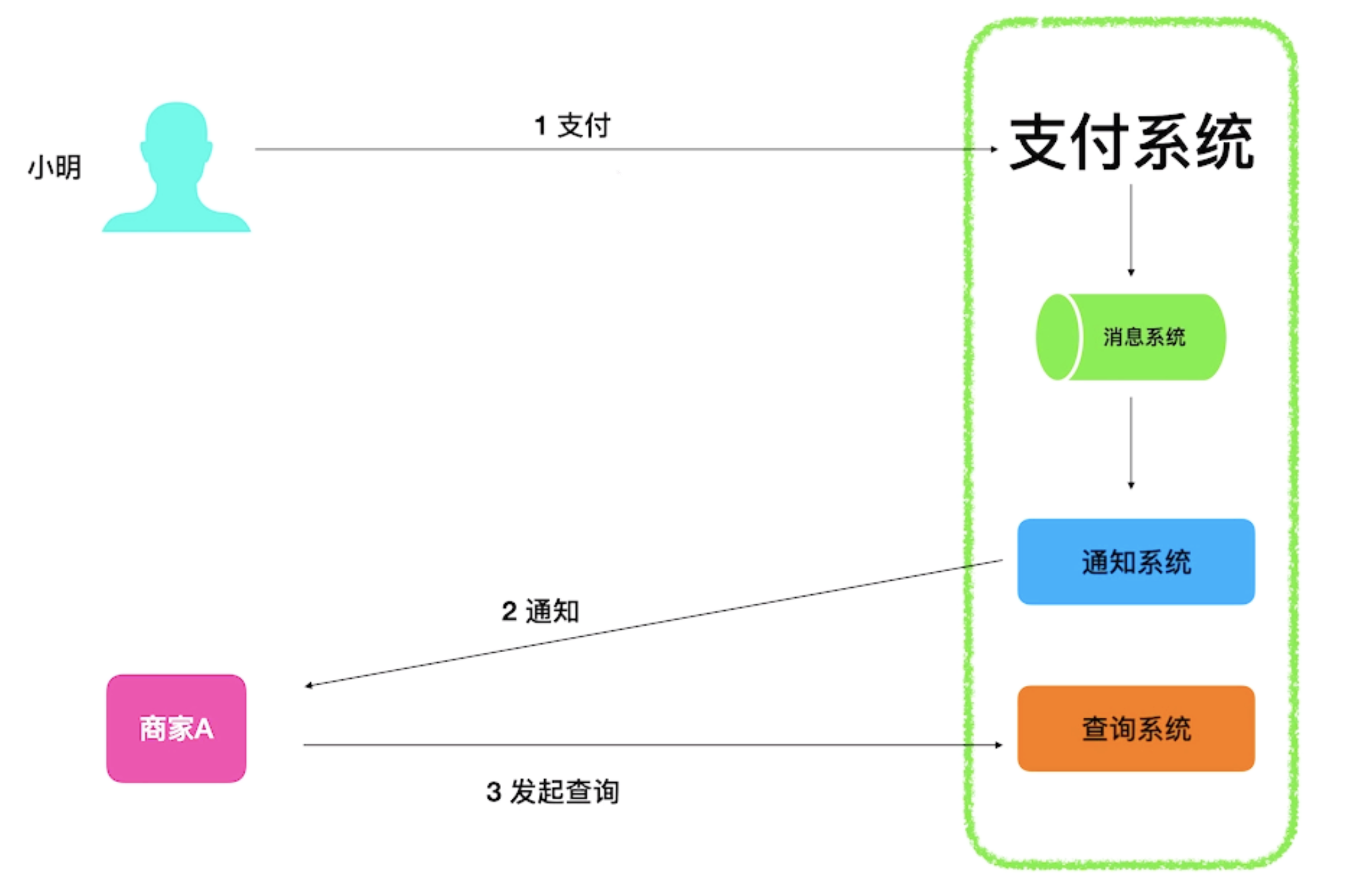
Clickhouse 使用Zookeeper进行分布式节点之间的协调
![[Pasted image 20240522011618.png]]
note: ZooKeeper 是一个分布式协调服务,主要用于分布式应用中的数据管理和节点协调。它提供了高可用性、一致性和分布式锁服务,通常用于分布式系统中的元数据管理和状态同步。
ZooKeeper 基于 ZAB 协议(ZooKeeper Atomic Broadcast)实现,其核心包括以下几点:
- 领导者选举:保证集群中只有一个主节点(Leader)来处理所有写请求。
- 原子广播:确保所有节点(Follower)都能以相同的顺序接收到写请求,从而保证数据一致性。
工作机制
- 节点状态跟踪:ClickHouse 节点通过 ZooKeeper 了解集群中其他节点的状态。
- 数据复制:当数据写入 ClickHouse 时,ZooKeeper 记录写入操作,并协调各节点之间的数据复制,确保所有副本同步。
- 故障恢复:ZooKeeper 监控节点的健康状态,如果某个节点故障,ZooKeeper 协调将该节点上的数据重新分配到其他健康节点。
节点故障处理
当一个 ZooKeeper 节点故障时:
- 选举新领导者:剩余的 ZooKeeper 节点会通过 ZAB 协议快速选举出新的领导者,继续处理写请求。
- 数据冗余:由于 ZooKeeper 的设计是至少有多数节点(超过半数)正常运行即可继续提供服务,集群中常常至少部署 3 个节点,以保证高可用性。
- 故障节点恢复:故障节点恢复后,会重新加入集群,同步数据并恢复正常服务。
4 Elasticsearch架构解析
Elasticsearch 是一个基于 Apache Lucene 构建的开源搜索引擎,广泛用于全文检索、日志聚合等多种场景。下面详细解析 Elasticsearch 的架构,包括倒排索引的底层原理、分布式架构以及实时数据分析的技术支持:
- 倒排索引的底层原理:从文档到索引的转换过程
- 分布式架构详解:节点、分片与负载均衡
- 实时数据分析的技术支持:如何处理海量数据流
–
4.1 倒排索引的底层原理:从文档到索引的转换过程
倒排索引是 Elasticsearch 最核心的数据结构,它使得全文搜索变得极为高效。以下是其基本的转换过程:
–
4.1.1 文档的预处理
在创建倒排索引之前,首先需要对文档进行预处理,这一步骤通常包括以下几个方面:
- 分词(Tokenization): 分词是将文本从连续的字符串分解为有意义的单元(词语)的过程。例如,句子 “Elasticsearch is powerful” 可以被分词为 “Elasticsearch”, “is”, “powerful”。这一步是搜索过程中非常关键的,因为搜索查询同样会被分词,以便与索引中的词语匹配。
- 标准化(Normalization): 包括转换所有字符到小写,以及可能的字符替换(例如,把德语中的 “ß” 替换为 “ss”),以减少字词形式的多样性,提高搜索的一致性。
- 去停用词(Removing Stop Words): 停用词如“是”,“和”等,在文档中非常常见,但对搜索贡献很小。移除这些词可以提高索引的效率。
- 词干提取(Stemming): 这一过程是将词汇还原为词根形式。例如,“running”, “ran”, 和 “runner” 都可能被还原到 “run”。这有助于增强搜索的灵活性。
- 建立索引:
- 对每一个词语,记录其出现在哪些文档中以及出现的位置。这种“词语-文档”对应关系就构成了倒排索引。
- 倒排索引中,对于每一个词语,都有一个索引项(或称“倒排记录”),其中列出了包含该词语的所有文档。通常,这还会包括词语在每个文档中的位置,甚至可能包括词频(即词语在文档中出现的次数)。
–
对于搜索引擎的倒排索引建立过程,通常有两种模式:实时(或近实时)和离线。在 Elasticsearch 这样的系统中,索引的建立通常是近实时的,这意味着新文档一旦被加入,它们几乎可以立即被搜索到。
–
4.1.2 创建倒排记录
倒排索引的基本结构如下:
- 词汇表:记录所有出现过的词汇。
- 倒排列表:对于每个词汇,记录该词汇出现在哪些文档中。
一旦文档被预处理并分词,每个词语将用来构建倒排索引:
- 词语到文档的映射: 对于索引中的每一个词语,系统都会创建一个倒排记录,记录每个词语出现在哪些文档中。例如,如果词语 “Elasticsearch” 出现在文档1和文档2中,倒排索引会记录这一信息。
- 记录位置信息: 索引不仅记录词语出现在哪些文档中,还记录了词语在文档中的具体位置。这对于支持短语搜索和近似匹配非常有用。
- 词频统计: 每个词在每个文档中出现的次数(词频)也会被记录下来。词频是评估词语在文档中重要性的一个重要指标,对于排名计算尤其关键。
–
![[image-20240520210325951.png||900x1000]]
–
4.2 分布式架构详解:节点、分片与负载均衡
Elasticsearch 的分布式架构允许它处理大规模数据集并提供高可用性和扩展性:
- 节点和集群:
- 一个 Elasticsearch 集群由多个节点组成,每个节点是一个 Elasticsearch 实例。
- 节点可以具有不同的角色,如主节点负责集群管理和元数据处理,数据节点负责数据存储和查询处理等。
- 集群和节点结构图:
–
- 分片:
- 数据在 Elasticsearch 中以索引的形式存储,而每个索引可以被分割为多个分片。每个分片本质上是一个独立的全功能搜索引擎。
- 分片可以进一步细分为主分片和副本分片。主分片负责数据的存储和索引,副本分片提供数据的冗余备份,同时可以处理读请求,增加查询性能。
- 索引与分片图:一个索引如何被分割成多个分片,包括主分片和副本分片。
–
- 负载均衡:
- Elasticsearch 自动在各节点间分配分片,以平衡负载和提高容错能力。
- 在处理查询时,查询可以在有副本分片的任何节点上并行执行,这样可以提高查询效率和吞吐量。
- 负载均衡和查询处理图:展示负载如何在不同的节点和分片之间分配,以及查询是如何在这种结构中执行的。
–
Elasticsearch中索引、分片与各个节点的关系:
–
POST /orders/_doc?routing=merchant_123
{
"order_id": "12345",
"merchant_id": "merchant_123",
"amount": 100.0,
"timestamp": "2024-05-21T10:00:00"
}
假设想要确保某个商户 merchant_123 的订单总是落到同一个分片上,这样做的好处包括:
- 提高查询效率:针对特定商户的查询只需要查询固定的分片。
- 简化数据管理:容易进行分片的负载均衡和扩展。
- 优化性能:减少跨分片的查询,提高查询速度。
–
通常实现步骤
- 创建索引并配置映射(可选,视具体需求而定):
PUT /orders
{
"mappings": {
"properties": {
"order_id": { "type": "keyword" },
"merchant_id": { "type": "keyword" },
"amount": { "type": "double" },
"timestamp": { "type": "date" }
}
}
}
- 索引文档时指定路由键:
POST /orders/_doc?routing=merchant_123
{
"order_id": "12345",
"merchant_id": "merchant_123",
"amount": 100.0,
"timestamp": "2024-05-21T10:00:00"
}
- 查询时指定路由键:
GET /orders/_search?routing=merchant_123
{
"query": {
"term": {
"merchant_id": "merchant_123"
}
}
}
–
4.3 实时数据分析的技术支持:如何处理海量数据流
对于实时数据分析,Elasticsearch 提供了强大的支持:
- 近实时(NRT)索引:
- Elasticsearch 的索引操作几乎是实时的,这意味着文档一旦被索引,几秒内就可以被搜索到。
- 这是通过 Lucene 的索引刷新机制实现的,定期将新索引的数据刷新到硬盘。
- 数据聚合:
- 除了搜索,Elasticsearch 还提供复杂的数据聚合功能,允许用户实时分析和汇总数据。
- 比如,可以快速计算聚合指标(如平均值、最大值、最小值等),或者进行更复杂的统计分析,如直方图、桶分割等。
- 流式处理:
- 通过与像 Logstash 和 Beats 这样的工具集成,Elasticsearch 能够处理连续的数据流。
- 这些工具帮助在数据进入 Elasticsearch 之前进行预处理,如格式化、丰富或过滤数据。
分析器(Analyzer)
分析器在创建索引时处理文档文本,将文本分解为词汇单元(token),并进行标准化处理,如小写化、去除停用词等。常见的分析器有标准分析器、简洁分析器等。
Lucene 的索引过程
- 文档添加到索引:
- 新文档被添加到内存中的数据结构(文档缓冲区)。
- 分析器将文档的文本分解为词汇单元,并将这些词汇单元添加到倒排索引。
- 段(Segment)创建:
- 定期将内存中的文档刷新到磁盘,形成段(segment)。
- 每个段是一个独立的、不可变的倒排索引。
- 段合并:
- 为了提高查询性能,Lucene 定期将多个小段合并成一个大段。
Lucene 的查询过程
- 解析查询:
- 用户输入的查询被解析为 Lucene 的查询对象。
- 查询对象可以是单个词、短语、布尔查询等。
- 搜索段:
- Lucene 遍历所有段文件,使用倒排索引快速定位包含查询词汇的文档。
- 对每个段的查询结果进行评分和排序。
- 合并结果:
- 将不同段的查询结果合并,最终返回给用户。
–
- 将不同段的查询结果合并,最终返回给用户。
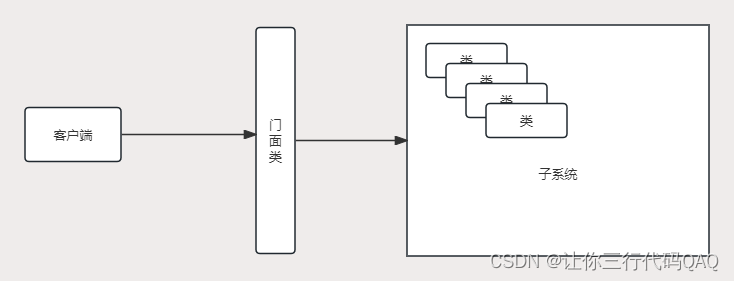
示例与工作机制 —— 搜索的核心技术是倒排索引和布隆过滤器
假设有一个 Elasticsearch 集群,用于存储和搜索电商平台的商品信息。每个商品文档包含多个字段,如 product_id、category、description 等。我们需要快速判断某个 product_id 是否存在。
![[Pasted image 20240522005540.png]]
5 核心技术对比
- 数据模型的差异与各自优势
- 查询与索引机制的深度比较
- 写入与更新流程的效率对比
–
5.1 查询对比实战:Elasticsearch vs ClickHouse
–
测试架构
- Elasticsearch Stack:
- 由单节点的 Elasticsearch 容器和 Kibana 容器组成,Elasticsearch 用于搜索和分析,Kibana 用于验证和辅助工具。
- ClickHouse Stack:
- 包含单节点的 ClickHouse 服务容器和 TabixUI 作为 ClickHouse 的客户端。
- 数据导入 Stack:
- 使用 Vector.dev 工具生成和导入数据,类似于 Fluentd,实现灵活的数据管道。
- 测试控制 Stack:
- 通过 Jupyter 使用 ES 和 ClickHouse 的 Python SDK 进行查询测试。
–
测试数据和查询方法
- 数据生成与导入:
- 使用 Vector 的 generator 功能生成 10 万条 syslog 模拟数据,导入到 Elasticsearch 和 ClickHouse 中。
- 在 ClickHouse 中创建对应的表,定义结构和分区策略。
- 查询类型:
- 返回所有记录
- 单字段匹配
- 多字段匹配
- 单词查找
- 范围查询
- 存在字段查询
- 正则表达式查询
- 聚合计数
- 聚合不重复值
- 性能测试:
- 使用 Python SDK 在两个 Stack 上各运行上述查询 10 次,统计查询性能。
–
测试结果与分析
- 返回所有记录:
- Elasticsearch 使用
match_all查询,ClickHouse 使用SELECT *语句。ES{ "query":{ "match_all":{} }}Clickhouse"SELECT * FROM syslog"
- Elasticsearch 使用
- 单字段匹配:
- Elasticsearch 使用
match查询,ClickHouse 使用WHERE条件。ES{ "query":{ "match":{ "hostname":"for.org" } }}Clickhouse"SELECT * FROM syslog WHERE hostname='for.org'"
- Elasticsearch 使用
- 多字段匹配:
- Elasticsearch 使用
multi_match查询,ClickHouse 使用OR条件。ES{ "query":{ "multi_match":{ "query":"up.com ahmadajmi", "fields":[ "hostname", "application" ] } }}Clickhouse、"SELECT * FROM syslog WHERE hostname='for.org' OR application='ahmadajmi'"
- Elasticsearch 使用
–
- 单词查找:
- Elasticsearch 使用
term查询,ClickHouse 使用LIKE操作。ES{ "query":{ "term":{ "message":"pretty" } }}Clickhouse"SELECT * FROM syslog WHERE lowerUTF8(raw) LIKE '%pretty%'"
- Elasticsearch 使用
- 范围查询:
- Elasticsearch 使用
range查询,ClickHouse 使用>=条件。ES{ "query":{ "range":{ "version":{ "gte":2 } } }}Clickhouse "SELECT * FROM syslog WHERE version >= 2
- Elasticsearch 使用
- 存在字段查询:
- Elasticsearch 使用
exists查询,ClickHouse 使用IS NOT NULL条件。ES{ "query":{ "exists":{ "field":"application" } }}Clickhouse"SELECT * FROM syslog WHERE application is not NULL"
- Elasticsearch 使用
–
- 正则表达式查询:
- Elasticsearch 使用
regexp查询,ClickHouse 使用match函数。ES{ "query":{ "regexp":{ "hostname":{ "value":"up.*", "flags":"ALL", "max_determinized_states":10000, "rewrite":"constant_score" } } }}Clickhouse"SELECT * FROM syslog WHERE match(hostname, 'up.*')"
- Elasticsearch 使用
- 聚合计数:
- Elasticsearch 使用
value_count聚合,ClickHouse 使用count函数。ES{ "aggs":{ "version_count":{ "value_count":{ "field":"version" } } }}Clickhouse"SELECT count(version) FROM syslog"
- Elasticsearch 使用
- 聚合不重复值:
- Elasticsearch 使用
cardinality聚合,ClickHouse 使用count(distinct)函数。ES{ "aggs":{ "my-agg-name":{ "cardinality":{ "field":"priority" } } }}Clickhouse"SELECT count(distinct(priority)) FROM syslog"
- Elasticsearch 使用
–
总结与结论
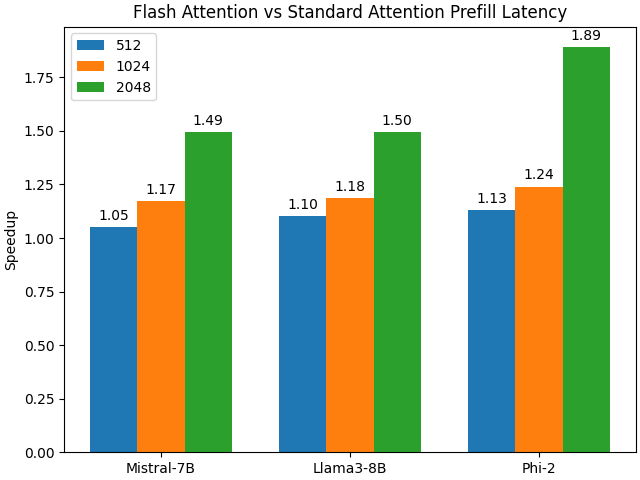
![[Pasted image 20240522014451.png|600x288]]
- 查询性能对比:
- ClickHouse 在大部分查询的性能上明显优于 Elasticsearch,尤其在聚合和复杂查询场景中表现尤为突出。
- Elasticsearch 优势:
- 在处理实时搜索和全文检索方面表现优秀,适用于需要复杂搜索和实时分析的应用场景。
- ClickHouse 优势:
- 在大规模数据分析和聚合查询方面表现优异,适用于需要高性能数据查询和分析的场景。
ps: 测试并没有任何优化,对于Clickhouse也没有打开布隆过滤器
–
5.2 总结
两者在数据模型、查询与索引机制、写入与更新流程等方面的差异和优势:
| 特性类别 | 技术点 | ClickHouse | Elasticsearch |
|---|---|---|---|
| 数据模型 | 数据存储方式 | 列式存储,优化了大规模数据分析和报告的性能。 | 文档存储,使用倒排索引,优化了全文搜索的性能。 |
| 主要优势 | 高速查询性能,尤其在聚合和分析大量数据时效率高。 | 实时索引和搜索,支持复杂数据结构和全文搜索,适用于实时数据分析。 | |
| 查询与索引 | 索引机制 | 支持创建数据部分索引,用于优化查询,但不涉及全部数据。 | 核心以倒排索引为基础,每个词条都被索引,优化文本搜索。 |
| 查询优化 | 向量化执行引擎和数据压缩技术,优化读取操作。 | 利用缓存和各种优化算法提高查询效率,支持复杂的查询语法。 | |
| 写入与更新 | 写入流程 | 优化批量数据插入,对于小批量写入可能效率较低。 | 支持高效的实时数据写入和索引,适合高并发场景。 |
| 更新流程 | 数据更新较为复杂,推荐批量更新或重写数据分区。 | 文档更新通过删除旧文档并索引新文档实现,适应频繁更新的需求。 |
6 应用案例与场景匹配
- 针对分析型业务的ClickHouse解决方案
- 针对实时搜索与日志分析的Elasticsearch应用
- 如何根据业务需求选择技术平台
–
| 解决方案 | 特点和优势 | 适用场景和业务需求 | 技术选型和实现 |
|---|---|---|---|
| ClickHouse | 分析型业务 | 针对分析型业务的ClickHouse解决方案 | 实现与架构 |
| 特点 | - 列式存储 - 高压缩比 - 实时数据写入和查询 - 分布式处理 | - 数据仓库 - BI 报表 - 大数据分析 - OLAP(在线分析处理) | - 通过列式存储和分区表设计提高查询效率 - 使用物化视图和分区表加速聚合查询 - 部署 ClickHouse 集群,实现高可用性和负载均衡 |
| 优势 | - 快速查询 - 高效压缩 - 支持复杂查询和大规模数据处理 | - 需要高性能分析处理的业务,如电商平台的销售数据分析,用户行为分析等 | - 配置分布式集群和副本,提高数据可靠性和可用性 - 使用 MergeTree 表引擎优化数据写入和查询性能 |
| Elasticsearch | 实时搜索与日志分析 | 针对实时搜索与日志分析的Elasticsearch应用 | 实现与架构 |
| 特点 | - 全文搜索 - 实时索引 - 强大的查询语言 - 支持复杂查询和聚合 | - 实时日志分析 - 全文搜索引擎 - 实时监控和报警 - 事件追踪 | - 利用 Kibana 可视化工具,提供实时数据展示 - 部署 Elastic Stack (Elasticsearch, Logstash, Kibana) 实现日志采集、存储和展示 - 通过集群配置,确保高可用性和扩展性 |
| 优势 | - 近实时搜索 - 强大的全文检索和分析功能 - 高度可扩展 - 支持多种数据源 | - 需要实时数据索引和搜索的业务,如网站搜索引擎,实时日志监控系统等 | - 使用分片和副本机制,确保高可用性和数据冗余 - 通过自定义路由策略,实现特定业务场景的数据分布优化 |
–
如何根据业务需求选择技术平台
| 业务需求 | 推荐平台 | 理由和优势 | 示例应用 |
|---|---|---|---|
| 大规模数据分析和报表 | ClickHouse | - 高效的列式存储 - 实时数据处理 - 高性能查询 | - 数据仓库 - BI 报表系统 |
| 实时日志监控和报警 | Elasticsearch | - 近实时索引和搜索 - 强大的日志分析功能 - 支持复杂查询和聚合 | - 实时日志监控 - 安全事件管理系统 |
| 全文搜索引擎 | Elasticsearch | - 强大的全文检索功能 - 高度可扩展 - 实时索引和搜索 | - 网站搜索引擎 - 文档管理系统 |
| 用户行为分析 | ClickHouse | - 快速数据查询和分析 - 高效的列式存储 - 支持复杂查询和聚合 | - 电商平台的用户行为分析 |
| 实时数据流处理 | Elasticsearch | - 支持实时数据索引 - 强大的聚合和分析功能 - 可视化工具(Kibana)支持 | - 实时事件追踪系统 - 数据流处理平台 |
| 历史数据查询和分析 | ClickHouse | - 优异的历史数据查询性能 - 支持复杂的 OLAP 查询 - 高压缩比 | - 长期存储的业务数据分析 |
| 实时应用监控 | Elasticsearch | - 近实时监控和报警 - 强大的日志分析和搜索功能 - 支持复杂的查询 | - 应用性能管理(APM)系统 |
7 性能挑战与优化策略
- 面对大规模数据集的性能调优案例
- 高级功能:聚合与数据压缩技术详解
- 扩展性与生态系统的长期支持
–
7.1 面对大规模数据集的性能调优案例
–
**优化数据分区**- **场景**:需要对过去五年的交易数据进行快速查询和分析,以识别交易模式和异常行为。
- **策略**:将交易数据按时间分区,每月一个分区。通过合理的分区设计,可以显著提高查询性能,特别是在进行时间范围查询时。
- **结果**:查询性能提高了约60%,数据处理时间大幅减少。
- **场景**:需要定期生成多种复杂报表,如每日交易汇总、月度收入分析等。
- **策略**:使用物化视图预计算常用查询结果,减少每次报表生成的计算开销。
- **结果**:报表生成时间从数小时缩短到几分钟,系统负载明显降低。
- **场景**:需要分析大量支付交易数据,包括点击流和用户行为数据。
- **策略**:充分利用 ClickHouse 的列式存储,选择合适的压缩算法,如 LZ4 或 ZSTD,以平衡存储和查询性能。
- **结果**:存储空间减少了约50%,查询性能提升了30%。
–
**索引模板和别名**- **场景**:需要对实时交易数据进行全文搜索和分析,以快速响应客户查询和检测欺诈行为。
- **策略**:使用索引模板定义一致的索引设置和映射,使用别名来简化索引管理和切换。
- **结果**:索引管理效率提高,搜索性能优化,系统运行更加稳定。
- **场景**:需要处理大量支付交易日志数据,每天产生数十亿条日志记录。
- **策略**:根据数据量和查询负载调整分片和副本数量,确保每个节点的负载均衡。同时,合理规划热数据和冷数据的存储策略。
- **结果**:系统负载均衡,查询性能提升了约40%,同时降低了硬件资源的浪费。
- **场景**:需要对用户支付行为数据进行复杂的聚合分析,以生成实时统计和监控报表。
- **策略**:使用 Elasticsearch 的聚合功能预计算常用的统计数据,减少实时计算的负担。
- **结果**:聚合查询的响应时间从数秒缩短到毫秒级别,用户体验显著提升。
–
7.2 高级功能:聚合与数据压缩技术详解
ClickHouse 的聚合与数据压缩
- 聚合:ClickHouse 支持多种聚合函数,如
SUM、AVG、MIN、MAX、COUNT等,以及复杂的窗口函数和用户自定义聚合函数(UDAF)。通过物化视图和分区表,可以预先计算和存储聚合结果,进一步提升查询性能。 - 数据压缩:ClickHouse 提供多种压缩算法(如 LZ4、ZSTD、Delta、DoubleDelta 等),用户可以根据数据特点选择合适的压缩方法,以在存储空间和查询性能之间取得平衡。列式存储加上高效压缩,使得 ClickHouse 能够在处理大规模数据时依然保持高效。
Elasticsearch 的聚合与数据压缩
- 聚合:Elasticsearch 提供强大的聚合功能,包括指标聚合(如
avg、sum、max、min)、桶聚合(如terms、range、histogram)和管道聚合。通过组合这些聚合,可以进行复杂的数据分析和可视化。 - 数据压缩:Elasticsearch 使用 Lucene 提供的压缩技术,如
LZ4和BEST_COMPRESSION,对索引数据进行压缩。此外,通过优化映射和字段存储方式,可以进一步减少存储空间和提高查询性能。
–
7.3 扩展性与生态系统的长期支持
ClickHouse 的扩展性
- 扩展性:ClickHouse 通过分布式表和分片机制实现横向扩展。用户可以将数据分布到多个节点上,实现高并发的写入和查询。
- 生态系统:ClickHouse 社区活跃,提供多种连接器和工具,如 JDBC、ODBC 驱动,以及与流处理框架(如 Kafka、RabbitMQ)的集成,支持与 BI 工具(如 Tableau、Power BI)的兼容。
Elasticsearch 的扩展性
- 扩展性:Elasticsearch 通过分片和副本机制实现高可用性和横向扩展。用户可以根据需要增加或减少节点,动态调整集群规模。
- 生态系统:Elasticsearch 生态系统包括 Elastic Stack(Elasticsearch、Logstash、Kibana、Beats),提供从数据采集、存储、分析到可视化的完整解决方案。此外,Elasticsearch 与多种数据源和框架(如 Hadoop、Spark)无缝集成,支持多种编程语言的客户端。
8 结论与战略建议
- 总结两种技术的关键优势与局限
–
8.1 总结两种技术的关键优势与局限
–
ClickHouse
- 关键优势:
- 高效的列式存储,适合大规模数据的快速查询和分析。
- 高压缩比,节省存储空间。
- 实时数据写入和查询,支持复杂的 OLAP 操作。
- 分布式处理,具备高可用性和可扩展性。
- 局限:
- 不适合实时搜索和全文检索场景。
- 对于小数据量的简单查询,可能性能优势不明显。
- 学习曲线较陡,配置和管理复杂度较高。
–
Elasticsearch
- 关键优势:
- 强大的全文搜索和实时索引能力,适合实时搜索和日志分析。
- 支持复杂查询和聚合操作,提供丰富的查询语言。
- 高度可扩展,能够处理大规模数据索引和搜索。
- 与 Kibana 配合,提供强大的数据可视化和实时监控功能。
- 局限:
- 数据存储成本较高,尤其在需要高冗余和高可用性配置时。
- 写入性能相对较弱,特别是在高并发写入场景下。
- 对于长时间的历史数据查询和分析,性能可能不如 ClickHouse。
–
8.2 建议
- 选择 ClickHouse 的场景:
- 适用于大规模数据的分析型业务,如数据仓库、BI 报表和用户行为分析等场景。
- 需要高性能数据查询和复杂 OLAP 分析的企业。
- 关注存储效率和压缩比,希望降低存储成本。
- 选择 Elasticsearch 的场景:
- 适用于需要实时搜索和日志分析的业务,如网站搜索引擎、实时日志监控和安全事件管理等场景。
- 需要快速响应和全文检索能力的企业。
- 希望通过 Kibana 实现数据可视化和实时监控,提升运维效率。
![[word] word文字间隙怎么调整? #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/8d66a8fe48ad434438a5277427acd1f7.gif)