梯度下降的基本概念
梯度下降(Gradient Descent)是一种用于优化机器学习模型参数的算法,其目的是最小化损失函数,从而提高模型的预测精度。梯度下降的核心思想是通过迭代地调整参数,沿着损失函数下降的方向前进,最终找到最优解。
生活中的背景例子:寻找山谷的最低点
想象你站在一个山谷中,眼睛被蒙住,只能用脚感受地面的坡度来找到山谷的最低点(即损失函数的最小值)。你每一步都想朝着坡度下降最快的方向走,直到你感觉不到坡度,也就是你到了最低点。这就好比在优化一个模型时,通过不断调整参数,使得模型的预测误差(损失函数)越来越小,最终找到最佳参数组合。
梯度下降的具体方法及其优化
1. 批量梯度下降(Batch Gradient Descent)
生活中的例子:
你决定每次移动之前,都要先测量整个山谷的坡度,然后再决定移动的方向和步幅。虽然每一步的方向和步幅都很准确,但每次都要花很多时间来测量整个山谷的坡度。
公式:
θ
:
=
θ
−
η
⋅
∇
θ
J
(
θ
)
\theta := \theta - \eta \cdot \nabla_{\theta} J(\theta)
θ:=θ−η⋅∇θJ(θ)
其中:
- θ \theta θ是模型参数
- η \eta η是学习率
- ∇ θ J ( θ ) \nabla_{\theta} J(\theta) ∇θJ(θ)是损失函数 J ( θ ) J(\theta) J(θ)关于 θ \theta θ的梯度
API:
TensorFlow:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
PyTorch:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
批量梯度下降过程图像python代码
import numpy as np
import matplotlib.pyplot as plt
# 损失函数: y = x^2
def loss(x):
return x ** 2
# 损失函数的梯度: dy/dx = 2x
def gradient(x):
return 2 * x
# 批量梯度下降
def batch_gradient_descent(start, learning_rate, iterations):
x = start
path = [x]
for i in range(iterations):
grad = gradient(x)
x = x - learning_rate * grad
path.append(x)
return path
# 参数
start = 10
learning_rate = 0.1
iterations = 20
# 运行梯度下降
path = batch_gradient_descent(start, learning_rate, iterations)
# 绘制图像
x = np.linspace(-10, 10, 100)
y = loss(x)
plt.plot(x, y, label='Loss Function')
plt.scatter(path, [loss(p) for p in path], color='red', label='Batch Gradient Descent Path')
plt.xlabel('x')
plt.ylabel('Loss')
plt.legend()
plt.title('Batch Gradient Descent')
plt.show()

- 从图像可知,批量梯度下降每次使用整个训练集计算梯度并更新参数,适用于小规模数据集,收敛稳定,但计算开销大。
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
生活中的例子:
你决定每一步都只根据当前所在位置的坡度来移动。虽然这样可以快速决定下一步怎么走,但由于只考虑当前点,可能会导致路径不稳定,有时候会走过头。
公式:
θ
:
=
θ
−
η
⋅
∇
θ
J
(
θ
;
x
(
i
)
,
y
(
i
)
)
\theta := \theta - \eta \cdot \nabla_{\theta} J(\theta; x^{(i)}, y^{(i)})
θ:=θ−η⋅∇θJ(θ;x(i),y(i))
其中
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)}, y^{(i)})
(x(i),y(i))是当前样本的数据
API:
TensorFlow 和 PyTorch 中的API与批量梯度下降相同,具体行为取决于数据的加载方式。例如在训练时可以一批数据包含一个样本。
随机梯度下降过程图像python代码
import numpy as np
import matplotlib.pyplot as plt
# 损失函数: y = x^2
def loss(x):
return x ** 2
# 损失函数的梯度: dy/dx = 2x
def gradient(x):
return 2 * x
# 随机梯度下降
def stochastic_gradient_descent(start, learning_rate, iterations):
x = start
path = [x]
for i in range(iterations):
grad = gradient(x)
x = x - learning_rate * grad * np.random.uniform(0.5, 1.5) # 模拟随机样本的影响
path.append(x)
return path
# 参数
start = 10
learning_rate = 0.1
iterations = 20
# 运行梯度下降
path = stochastic_gradient_descent(start, learning_rate, iterations)
# 绘制图像
x = np.linspace(-10, 10, 100)
y = loss(x)
plt.plot(x, y, label='Loss Function')
plt.scatter(path, [loss(p) for p in path], color='red', label='SGD Path')
plt.xlabel('x')
plt.ylabel('Loss')
plt.legend()
plt.title('Stochastic Gradient Descent')
plt.show()
- 随机梯度下降每次使用一个样本计算梯度并更新参数,计算效率高,适用于大规模数据集,但收敛不稳定,容易出现抖动。
3. 小批量梯度下降(Mini-Batch Gradient Descent)
生活中的例子:
你决定每次移动之前,只测量周围一小部分区域的坡度,然后根据这小部分区域的平均坡度来决定方向和步幅。这样既不需要花太多时间测量整个山谷,也不会因为只看一个点而导致路径不稳定。
公式:
θ
:
=
θ
−
η
⋅
∇
θ
J
(
θ
;
B
)
\theta := \theta - \eta \cdot \nabla_{\theta} J(\theta; \mathcal{B})
θ:=θ−η⋅∇θJ(θ;B)
其中
B
\mathcal{B}
B是当前小批量的数据
API:
TensorFlow 和 PyTorch 中的API与批量梯度下降相同,但在数据加载时使用小批量。
小批量梯度下降过程图像python代码
import numpy as np
import matplotlib.pyplot as plt
# 损失函数: y = x^2
def loss(x):
return x ** 2
# 损失函数的梯度: dy/dx = 2x
def gradient(x):
return 2 * x
# 小批量梯度下降
def mini_batch_gradient_descent(start, learning_rate, iterations, batch_size=5):
x = start
path = [x]
for i in range(iterations):
grad = gradient(x)
x = x - learning_rate * grad * np.random.uniform(0.8, 1.2) # 模拟小批量样本的影响
path.append(x)
return path
# 参数
start = 10
learning_rate = 0.1
iterations = 20
# 运行梯度下降
path = mini_batch_gradient_descent(start, learning_rate, iterations)
# 绘制图像
x = np.linspace(-10, 10, 100)
y = loss(x)
plt.plot(x, y, label='Loss Function')
plt.scatter(path, [loss(p) for p in path], color='red', label='Mini-Batch Gradient Descent Path')
plt.xlabel('x')
plt.ylabel('Loss')
plt.legend()
plt.title('Mini-Batch Gradient Descent')
plt.show()
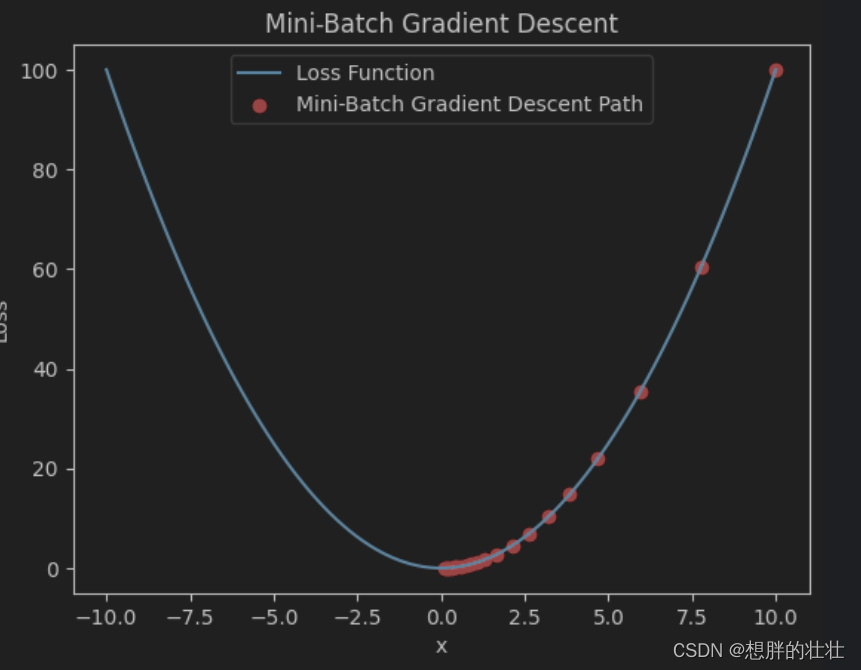
- 小批量梯度下降每次使用一个小批量样本计算梯度并更新参数,平衡了计算效率和稳定性。
4. 动量法(Momentum)
生活中的例子:
你在移动时,不仅考虑当前的坡度,还考虑之前几步的移动方向,就像带着惯性一样。如果前几步一直往一个方向走,那么你会倾向于继续往这个方向走,减少来回震荡。
公式:
v
:
=
β
v
+
(
1
−
β
)
∇
θ
J
(
θ
)
v := \beta v + (1 - \beta) \nabla_{\theta} J(\theta)
v:=βv+(1−β)∇θJ(θ)
θ
:
=
θ
−
η
v
\theta := \theta - \eta v
θ:=θ−ηv
其中:
- v v v是动量项
- β \beta β是动量系数(通常接近1,如0.9)
API:
TensorFlow:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9)
PyTorch:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
动量法图像python代码
import numpy as np
import matplotlib.pyplot as plt
# 损失函数: y = x^2
def loss(x):
return x ** 2
# 损失函数的梯度: dy/dx = 2x
def gradient(x):
return 2 * x
# 动量法
def momentum_gradient_descent(start, learning_rate, iterations, beta=0.9):
x = start
v = 0
path = [x]
for i in range(iterations):
grad = gradient(x)
v = beta * v + (1 - beta) * grad
x = x - learning_rate * v
path.append(x)
return path
# 参数
start = 10
learning_rate = 0.1
iterations = 20
# 运行梯度下降
path = momentum_gradient_descent(start, learning_rate, iterations)
# 绘制图像
x = np.linspace(-10, 10, 100)
y = loss(x)
plt.plot(x, y, label='Loss Function')
plt.scatter(path, [loss(p) for p in path], color='red', label='Momentum Path')
plt.xlabel('x')
plt.ylabel('Loss')
plt.legend()
plt.title('Momentum Gradient Descent')
plt.show()
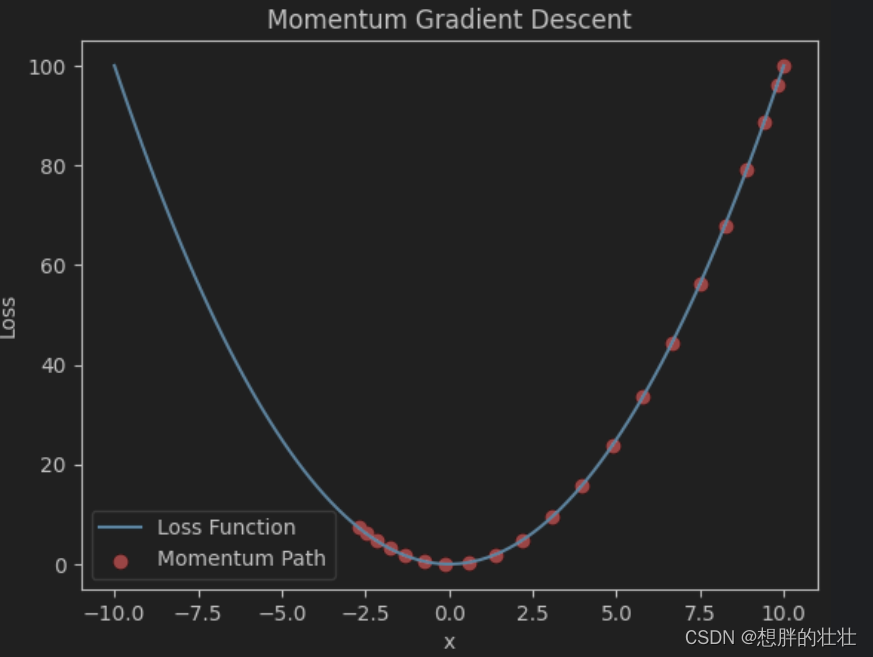
- 动量法通过引入动量项加速收敛并减少震荡,适用于深度神经网络训练。
5. RMSProp
生活中的例子:
你在移动时,会根据最近一段时间内每一步的坡度情况,动态调整步幅。比如,当坡度变化剧烈时,你会迈小步,当坡度变化平缓时,你会迈大步。
公式:
s
:
=
β
s
+
(
1
−
β
)
(
∇
θ
J
(
θ
)
)
2
s := \beta s + (1 - \beta) (\nabla_{\theta} J(\theta))^2
s:=βs+(1−β)(∇θJ(θ))2
θ
:
=
θ
−
η
s
+
ϵ
∇
θ
J
(
θ
)
\theta := \theta - \frac{\eta}{\sqrt{s + \epsilon}} \nabla_{\theta} J(\theta)
θ:=θ−s+ϵη∇θJ(θ)
其中:
- s s s是梯度平方的加权平均值
- ϵ \epsilon ϵ是一个小常数,防止除零错误
API:
TensorFlow:
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)
PyTorch:
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.001)
RMSProp图像python代码
import numpy as np
import matplotlib.pyplot as plt
# 损失函数: y = x^2
def loss(x):
return x ** 2
# 损失函数的梯度: dy/dx = 2x
def gradient(x):
return 2 * x
# RMSProp
def rmsprop_gradient_descent(start, learning_rate, iterations, beta=0.9, epsilon=1e-8):
x = start
s = 0
path = [x]
for i in range(iterations):
grad = gradient(x)
s = beta * s + (1 - beta) * grad**2
x = x - learning_rate * grad / (np.sqrt(s) + epsilon)
path.append(x)
return path
# 参数
start = 10
learning_rate = 0.1
iterations = 20
# 运行梯度下降
path = rmsprop_gradient_descent(start, learning_rate, iterations)
# 绘制图像
x = np.linspace(-10, 10, 100)
y = loss(x)
plt.plot(x, y, label='Loss Function')
plt.scatter(path, [loss(p) for p in path], color='red', label='RMSProp Path')
plt.xlabel('x')
plt.ylabel('Loss')
plt.legend()
plt.title('RMSProp Gradient Descent')
plt.show()
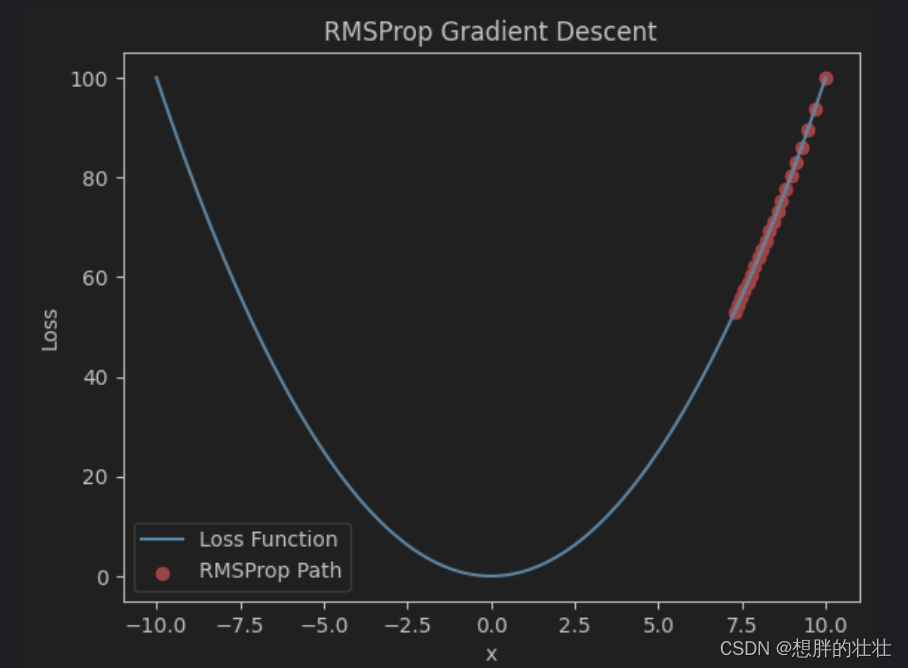
- RMSProp动态调整学习率,通过对梯度平方的加权平均值进行调整,适用于处理非平稳目标。
6. Adam(Adaptive Moment Estimation)
生活中的例子:
你在移动时,结合动量法和RMSProp的优点,不仅考虑之前的移动方向(动量),还根据最近一段时间内的坡度变化情况(调整步幅),从而使移动更加平稳和高效。
公式:
m
:
=
β
1
m
+
(
1
−
β
1
)
∇
θ
J
(
θ
)
m := \beta_1 m + (1 - \beta_1) \nabla_{\theta} J(\theta)
m:=β1m+(1−β1)∇θJ(θ)
v
:
=
β
2
v
+
(
1
−
β
2
)
(
∇
θ
J
(
θ
)
)
2
v := \beta_2 v + (1 - \beta_2) (\nabla_{\theta} J(\theta))^2
v:=β2v+(1−β2)(∇θJ(θ))2
m
^
:
=
m
1
−
β
1
t
\hat{m} := \frac{m}{1 - \beta_1^t}
m^:=1−β1tm
v
^
:
=
v
1
−
β
2
t
\hat{v} := \frac{v}{1 - \beta_2^t}
v^:=1−β2tv
θ
:
=
θ
−
η
m
^
v
^
+
ϵ
\theta := \theta - \eta \frac{\hat{m}}{\sqrt{\hat{v}} + \epsilon}
θ:=θ−ηv^+ϵm^
其中:
- m m m和 v v v分别是梯度的一阶和二阶动量
- β 1 \beta_1 β1和 β 2 \beta_2 β2是动量系数(通常分别取0.9和0.999)
- m ^ \hat{m} m^和 v ^ \hat{v} v^是偏差校正后的动量项
- t t t是时间步
API:
TensorFlow:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
PyTorch:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
Adam图像python代码
import numpy as np
import matplotlib.pyplot as plt
# 损失函数: y = x^2
def loss(x):
return x ** 2
# 损失函数的梯度: dy/dx = 2x
def gradient(x):
return 2 * x
# Adam
def adam_gradient_descent(start, learning_rate, iterations, beta1=0.9, beta2=0.999, epsilon=1e-8):
x = start
m = 0
v = 0
path = [x]
for t in range(1, iterations + 1):
grad = gradient(x)
m = beta1 * m + (1 - beta1) * grad
v = beta2 * v + (1 - beta2) * grad**2
m_hat = m / (1 - beta1**t)
v_hat = v / (1 - beta2**t)
x = x - learning_rate * m_hat / (np.sqrt(v_hat) + epsilon)
path.append(x)
return path
# 参数
start = 10
learning_rate = 0.1
iterations = 20
# 运行梯度下降
path = adam_gradient_descent(start, learning_rate, iterations)
# 绘制图像
x = np.linspace(-10, 10, 100)
y = loss(x)
plt.plot(x, y, label='Loss Function')
plt.scatter(path, [loss(p) for p in path], color='red', label='Adam Path')
plt.xlabel('x')
plt.ylabel('Loss')
plt.legend()
plt.title('Adam Gradient Descent')
plt.show()
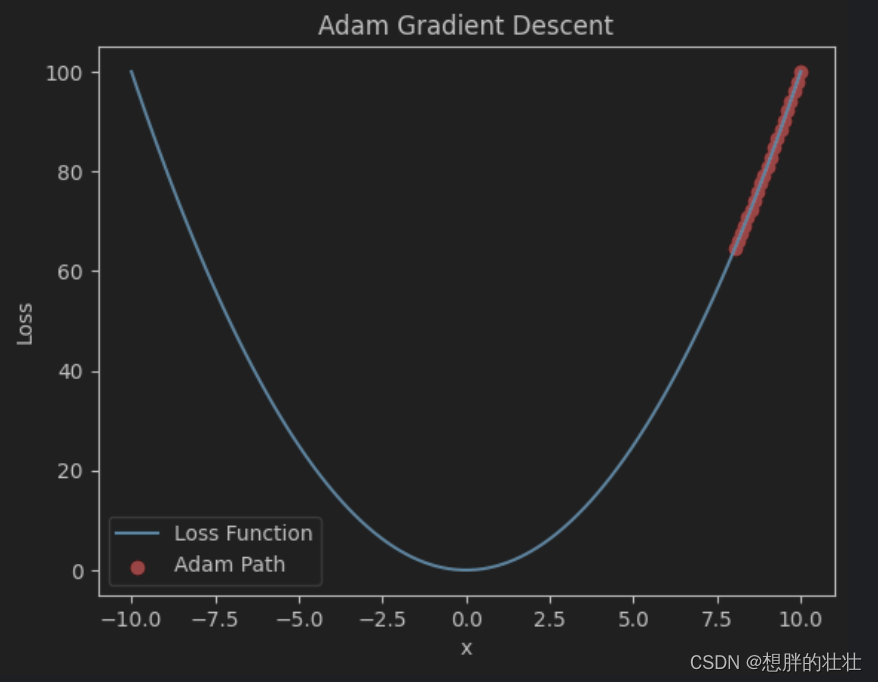
- Adam结合动量法和RMSProp的优点,自适应调整学习率,适用于各种优化问题。
综合应用示例
假设我们在使用TensorFlow和PyTorch训练一个简单的神经网络,以下是如何应用这些优化方法的示例代码。
TensorFlow 示例:
import tensorflow as tf
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型并选择优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 准备数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=32)
PyTorch 示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleNN()
# 选择优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 准备数据
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 训练模型
for epoch in range(10):
for batch in train_loader:
x_train, y_train = batch
x_train = x_train.view(x_train.size(0), -1) # Flatten the images
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
综合对比
| 优化方法 | 优点 | 缺点 | 可能出现的问题 | 适用场景 |
|---|---|---|---|---|
| 批量梯度下降(Batch GD) | 收敛稳定,适用于小规模数据集 | 每次迭代计算开销大,速度慢 | 难以处理大规模数据,容易陷入局部最优 | 小规模数据集,适合精确收敛 |
| 随机梯度下降(SGD) | 计算效率高,适用于大规模数据集 | 路径不稳定,波动较大 | 收敛路径抖动大,不稳定 | 大规模数据集,在线学习,快速迭代 |
| 小批量梯度下降(Mini-Batch GD) | 平衡了计算效率和收敛稳定性 | 需要选择合适的小批量大小,计算量仍然较大 | 小批量大小选择不当可能影响收敛效果 | 大规模数据集,适合批量计算 |
| 动量法(Momentum) | 加速收敛,减少震荡 | 需要调整动量系数,增加了参数选择的复杂性 | 动量系数选择不当可能导致过冲 | 深度神经网络训练,加速收敛 |
| RMSProp | 动态调整学习率,适应非平稳目标 | 需要调整参数β和ε,参数选择复杂 | 参数选择不当可能影响收敛效果 | 非平稳目标,复杂优化问题 |
| Adam | 结合动量法和RMSProp优点,自适应调整学习率,收敛快 | 需要调整多个参数,计算复杂性高 | 参数选择不当可能影响收敛效果 | 各种优化问题,特别是深度学习模型训练 |