前言:想象一下,当自动驾驶汽车行驶在繁忙的街道上,DETR能够实时识别出道路上的行人、车辆、交通标志等目标,并准确预测出它们的位置和轨迹。这对于提高自动驾驶的安全性、减少交通事故具有重要意义。同样,在安防监控、医疗影像分析等领域,DETR也展现出了巨大的应用潜力,如今,一项名为DETR(Detection Transformer)的创新技术,犹如一股清流,为这一领域带来了革命性的变革。DETR,这个听起来有些神秘而高深的名词,实际上是一种基于Transformer架构的端到端目标检测模型。它摒弃了传统方法中繁琐的锚框和候选区域生成步骤,直接通过Transformer的强大能力,将图像中的目标信息与上下文信息相融合,实现了对目标的精准定位和分类。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
在进行目标检测时,需要大量手动设计的组件,比如非极大值抑制(NMS)和基于人工经验生成的先验框(Anchor)等。DETR在其文章中,将目标检测视为一个直接的集合预测任务,从而减少了对人工组件设计的依赖,并使目标检测流程更为简洁。当提供一组固定的、可学习的目标查询DETR来推断目标与全局图像之间的上下文关系时,由于DETR没有先验框的限制,这将使其在预测较大物体时表现得更为出色。
如下图展示的是DETR的核心框架。由于直接使用了transformer的结构,这导致模型的计算需求增加。因此,DETR首先利用CNN卷积神经网络来提取特征,这种方法生成的特征图通常会降低32倍的采样。接下来,我们将提取出的特征图传输到Transformer的encoder结构中,以实现自注意力的交互,从而揭示特征图中每一个像素与其他像素的相互关系。decoder首先为用户预设了N个查询。这些查询首先通过自注意力机制去除模型中的多余框,然后与来自Encoder的特征交互,生成数量为N的查询。这些查询通过线性层生成模型预测的类别和相应的边界框输出,最终完成预测:
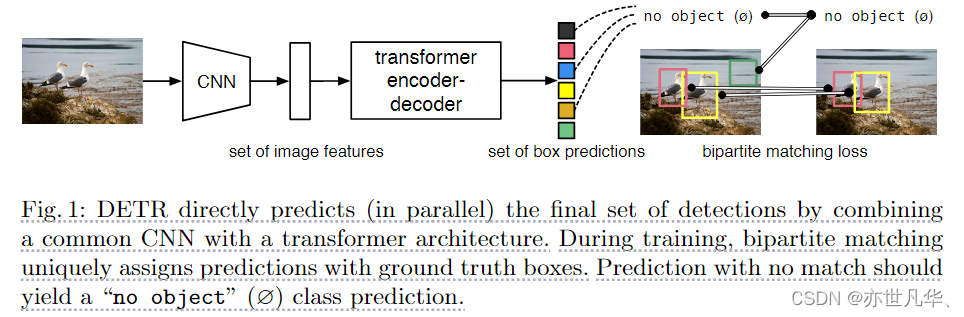
实验中N个数据比一幅图包含全部对象更多,计算损失函数时DETR先用匈牙利算法找到合适匹配方式。然后去算bbox及分类损失值。鉴于L1L1损失函数对不同尺寸的边界框产生的误差存在差异,我们决定使用GIoUGIoU损失函数来补偿这些误差。如下图,为DETR更为详尽的图示:

主干网络方面:
针对于一张通道数大小为3的图片,首先经过CNN的骨干网络,得到一个通道数为2048(这个数据由我们手动设定),长宽分别为原始图像大小132321的特征图f∈RC×H×Wf∈RC×H×。
Transformer编码器:
首先,通过1×11×1的卷积方法,我们将特征图ff的通道维数从CC减少到了更低的dd维度,并据此生成了一个新的特征图z0∈Rd×H×Wz0∈Rd×H×W,编码器希望有序列做输入,所以我们把z0z0̈个空间维度压缩成1维,生成d×HWd×HW特征图。
每一个编码器层都配备了一个统一的架构,该架构由一个多头自注意力模块和一个前馈网络(FFN)共同构成。由于Transformer架构具有置换不变性(对输入序列进行排序更改而不会对输出结果进行更改),我们用维度大小相同的位置编码来弥补这个缺点,位置编码被添加到每个注意力层的输入中。Transformer解码器:
DETR与标准Transformer架构中的decoder有所不同,因为它并未使用掩码技术,这意味着N个预测的边界框可以被同时输出。
鉴于解码器依然保持置换不变性,我们选择了可学习的位置编码作为其输入嵌入方式,并将其命名为object query。这种object query经由若干层结构最后被转换到输出边界框上并经由FFN结构产生N个坐标点以及分类后之物体。
下图所示是模型Transformer的主要结构,来自CNN主干网络的图像特征被送到transformer编码器中,在每个多头自注意力机制中与空间位置编码相加作为多头自注意力机制的键和查询,(生成q,k,v需要矩阵相乘,并不是一个直接的结果)。作为在解码器和编码器进行注意力机制计算之前,首先object query需要进行一个自注意力机制,该步骤是为了去除模型中的冗余框:

演示效果
使用一个GPU进行模型训练、验证和可视化,命令如下:
# 模型训练
python -m torch.distributed.launch --nproc_per_node=1 --use_env main.py --coco_path data/coco
# 模型验证
python main.py --batch_size 2 --no_aux_loss --eval --resume ckpt/detr-r50-e632da11.pth --coco_path data/coco
# 模型可视化
python imshow.py部署项目方式如下:
# 首先安装相应版本的PyTorch 1.5+和torchvision 0.6+ ,如果有GPU则安装GPU版本的,没有安装相应cpu版本的,注意linux和window之间的区别
conda install -c pytorch pytorch torchvision
# 安装pycococtools(在COCO数据集上进行预测)和scipy(为了训练)
conda install cython scipy
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'从http://cocodataset.org下载COCO2017的train和val图像,相应地annotation,具体如下截图所示:

将数据集按照下面的形式进行摆放:
data/coco/
annotations/ # annotation json files
train2017/ # train images
val2017/ # val images从detr-r50-e632da11.pth下载相应的权重,并命名为ckpt/detr-r50-e632da11.pth,放在ckpt文件夹下,如下图所示:

使用DETR进行目标检测,效果如下:

使用DETR交叉注意力机制可视化如下:

DETR自注意力机制可视化,query表示当前物体的标号,下方对应的是相应的名称,下方显示的点可以人工手动调整:

核心代码
下面这段代码实现了一个目标检测模型 DETR(DEtection TRansformer),它使用了 Transformer 架构进行目标检测,在 __init__ 函数中,模型接受了一个 backbone 模型、一个 transformer 模型、目标类别数 num_classes、最大检测框个数 num_queries 和一个参数 aux_loss。其中,backbone 模型用于提取特征,transformer 模型用于处理特征和进行目标检测。模型的输出包括分类 logits 和检测框坐标,以及可选的辅助损失。
在 forward 函数中,模型接受了一个 NestedTensor,其中 samples.tensor 是一个批次的图像,samples.mask 是一个二进制掩码,表示每个图像中的有效像素。首先,模型使用 backbone 模型提取特征和位置编码。然后,模型使用 transformer 模型对特征和位置编码进行处理,得到分类 logits 和检测框坐标。最后,模型将分类 logits 和检测框坐标输出为字典,其中 pred_logits 表示分类 logits,pred_boxes 表示检测框坐标。
在 _set_aux_loss 函数中,模型处理辅助损失。这里使用了一个 workaround,将输出的字典转换为一个列表,每个元素包含分类 logits 和检测框坐标。这样做是为了让 torchscript 能够正常工作,因为它不支持非同构值的字典。
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, height, width). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
# backbone 网络进行了两个操作,分别是获取特征图和位置编码
features, pos = self.backbone(samples)
src, mask = features[-1].decompose()
assert mask is not None
# input_proj: src: [2,2048,28,38]->[2,256,28,38] 改变特征图的通道维数
# mask: [2,28,38] mask的通道维数为1 pos: [2,256,28,38] query表示查询,也就是图片里面可能有多少物体的个数
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
# 都只使用最后一层decoder输出的结果
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]下面这段代码实现了一个 Transformer 模型,用于对输入特征进行编码和解码,首先,模型将输入特征和位置编码展平,并进行转置,得到形状为 [HW, N, C] 的张量。然后,模型将查询编码重复 N 次,并将掩码展平,以便在解码器中使用。接下来,模型使用编码器对输入特征进行编码,并使用解码器对编码后的特征进行解码。最后,模型将解码器的输出进行转置,得到形状为 [batch_size, num_queries, d_model] 的张量,并将编码器的输出进行转置和重构,得到与输入特征相同的形状,如下:
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC [2,256,28,38]
bs, c, h, w = src.shape
# src: [2,256,28,38]->[2,256,28*38]->[1064,2,256]
# pos_embed: [2,256,28,38]->[2,256,28*38]->[1064,2,256]
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
# query_embed:[100,256]->[100,1,256]->[100,2,256]
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
# mask: [2,28,38]->[2,1064]
mask = mask.flatten(1)
# 其实也是一个位置编码,表示目标的信息,一开始被初始化为0 [100,2,256]
tgt = torch.zeros_like(query_embed)
# memory的shape和src的一样是[1064,2,256]
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
# hs 不止输出最后一层的结构,而是输出解码器所有层结构的输出情况
# hs: [6,100,2,256]->[6,2,100,256] [depth,batch_size,num_query,channel]
# 一般只使用最后一层特征所以未hs[-1]
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)写在最后
DETR以其独特的视角和创新的架构,彻底改变了目标检测的传统流程。它摒弃了复杂的预处理步骤,如锚框生成和非极大值抑制,转而采用了一种简洁而高效的设计。通过Transformer的自注意力机制,DETR能够捕捉图像中各个部分之间的长距离依赖关系,从而更准确地预测目标的位置和类别。
DETR的成功并非偶然。它基于Transformer的强大能力,将图像特征提取、目标定位和分类任务全部整合在一个模型中,实现了真正的端到端训练。这种设计不仅简化了检测过程,还提高了模型的整体优化效果。更重要的是,DETR的“集合预测”机制允许模型以并行的方式预测所有目标,无需繁琐的排序或筛选操作,进一步提升了检测效率。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。