本章将以通俗易懂、贴合实际的方式介绍以下内容:
- 协程是什么,有什么特点,协程的优势是什么
- 如何理解事件和事件循环
- 协程的创建方式,如何控制协程的并发量
- 在协程中使用aiohttp发送HTTP请求
- aiohttp案例
- 协程中的异常处理,请求重试,使用 asyncio.Lock 保护共享资源
- 如何捕获KeyboardInterrupt异常
- 在协程中使用tqdm显示进度条。
前言
协程、线程池和多进程都是并发编程的方式,但它们在实现方式、适用场景和性能方面有一些区别。下面是它们的主要区别:
协程
- 协程是一种轻量级线程,在单个线程内并发执行多个协程(任务)。比如协程并发量设置为100,则在1个线程内创建100个协程
- 无论协程的并发量设置为多少,实际上只有一个线程在运行。而在这个线程内部,通过事件循环来调度多个协程的执行。协程之间通过非阻塞的方式切换执行,当一个协程遇到阻塞时,事件循环会暂停该协程的执行,切换到其他可执行的协程,从而实现了并发执行的效果
- 由于协程只允许一个线程执行,在一个线程内通过协程调度器调度多个协程的执行,因此切换的开销非常小
- 适用于 I/O 密集型任务,比如网络请求需要花费大量时间等待外部资源的响应
为什么协程比多线程效率高?
因为在传统的多线程环境中,操作系统需要在不同的线程之间切换,这涉及保存和恢复线程状态、上下文切换等操作,这些操作会引入一定的开销
相比之下,协程的切换则是在用户空间内完成的,不需要操作系统的干预,因此切换的开销非常小。这使得协程可以在一个线程内并发执行多个任务,而不需要频繁地切换线程。
当一个协程被阻塞(例如等待 I/O 操作)时,事件循环可以迅速切换到另一个协程,而无需承担完整线程切换的开销。这使得协程切换比线程切换更轻量级。
协程的效率提升来自于在切换时不依赖操作系统进行线程管理,避免了线程切换的开销。
线程池
- 如果线程池的并发量设置为100,那么线程池会创建并管理100个线程。
- 系统需要在不同的线程之间切换,这涉及保存和恢复线程状态、上下文切换等操作,这些操作增加一定开销
- 适用于计算密集型任务
多进程
- 适用于 I/O 密集型任务,如网络请求、文件读写等。
- 进程切换的开销较大
多进程和多线程及协程都是通过任务切换来实现并发,只不过协程的任务切换开销较小,而go是真正的在一时刻执行多个任务。
协程基础概念
- 异步和同步:同步是指代码按照顺序一步一步地执行,每一步的执行都会阻塞后续的操作,直到当前步骤完成。异步执行是指代码的执行顺序不必等待某个操作完成,而是可以继续执行后续的操作。在异步模式下,代码可以在等待某个操作的同时继续执行其他任务,无需阻塞。
- async 和 await 关键字:在定义协程时,使用 async 关键字来声明一个异步函数,该函数可以包含 await 表达式,用于等待异步操作的结果。
- asyncio.create_task 函数:使用这个函数可以将协程任务包装为一个可调度的任务,并将其添加到事件循环中。
- 协程的生命周期:协程从创建到完成,有以下几个阶段:
-
- 创建协程对象。
- 通过事件循环调度执行协程。
- 协程执行时,遇到 await 表达式会暂停执行并释放事件循环,等待异步操作完成。
- 异步操作完成后,协程恢复执行。
- 并发的协程:通过将多个协程任务同时调度到事件循环中,可以实现并发的异步操作,从而提高程序性能。
- 协程间的通信:协程之间可以通过队列、事件等方式进行通信,以实现数据的传递和协作。
事件(Event)
在异步编程中,事件通常与异步操作的完成相关。如网络请求、文件读写的完成或用户输入发生时。例如,当网络请求完成、文件读写操作完成时,这些都可以被视为事件。这些事件会恢复之前等待的协程,以便程序能够继续执行后续的操作。
事件循环(Event Loop)
事件循环(Event Loop)是异步编程中的一个核心概念。它描述了程序中的一个持续运行的循环,这个循环等待并处理事件。事件循环不断地查看这些事件,并根据这些事件调用相应的处理函数(通常是异步函数或回调函数)。举个例子:
想象一下你正在一个餐厅工作,你是服务员。餐厅里有很多顾客,他们各自点了菜(这就像是异步操作),而你的任务就是等待这些菜做好(等待异步操作完成),然后把菜送到对应的顾客桌上(调用处理函数)。
事件循环就相当于你这个服务员。你不停地查看是否有顾客的菜已经做好(检查事件),一旦有菜做好,你就立刻把菜送到对应的顾客桌上(处理事件)。这个过程是持续不断的,直到餐厅关门(程序结束)。
在Python的asyncio库中,事件循环是一个具体的对象,它负责调度和执行异步任务(协程),等待 I/O 操作完成。你可以使用asyncio.get_event_loop()来获取这个对象,并调用它的方法来运行协程或等待某个协程完成。
协程基础
asyncio是Python标准库中的模块,用于编写并发的异步代码,允许在单线程中同时执行多个任务。
简单的协程案例1
下面主要介绍如何定义和运行一个异步函数
- 使用async来定义一个异步函数
- loop = asyncio.get_event_loop() 获取当前的事件循环
- asyncio.run() 运行顶级入口点的异步代码,并处理事件循环的创建、运行和关闭
import asyncio
async def say_hello():
print("hello")
await asyncio.sleep(1)
print("world")
if __name__ == "__main__":
loop = asyncio.get_event_loop() #获取当前的事件循环
loop.run_until_complete(say_hello()) #启动事件循环并运行给定的协程,直到该协程完成。
loop.close() #关闭事件循环从Python 3.7起,推荐使用asyncio.run(say_hello())来替代获取事件循环、运行协程和关闭事件循环的步骤。在 Python 3.10 及以后的版本中,asyncio.get_event_loop() 和相关函数已被弃用。
import asyncio
async def say_hello():
print("hello")
await asyncio.sleep(1)
print("world")
if __name__ == "__main__":
asyncio.run(say_hello()) 在windows下,某些时候使用asyncio.run()会报错:https://www.yuque.com/dafcs-dqalz/uz9oso
简单的协程案例2
上面的say_hello 协程案例并没有直接展示协程在并发方面的优势。为了演示并发,我们可以创建多个协程并使用asyncio.gather() 运行它们,比如模拟多个异步任务同时进行的场景。
await asyncio.gather(*tasks) 用于并发地运行多个协程(coroutine)并等待它们全部完成。详细解释:
- 并发运行协程:这个函数接受一个或多个协程作为参数,并返回一个协程,这个返回的协程在调用时将会并发地运行所有传入的协程。
- 等待所有协程完成:await asyncio.gather(*tasks) 将会挂起当前的协程,直到所有 tasks 中的协程都完成。这里的 *tasks 是解包(unpack)tasks 列表中的每个协程,并将它们作为独立的参数传递给 gather 函数。
- 处理异常:如果 tasks 中的任何协程引发了异常,asyncio.gather 将会收集这些异常并在等待它的协程中引发一个 asyncio.gather.CancelledError 异常。这使得你可以在一个地方捕获和处理多个协程可能引发的所有异常。
- 结果收集:如果所有协程都成功完成,asyncio.gather 将会返回一个包含所有协程返回值的元组(tuple)。例如,如果每个 say_hello 协程都返回了一个值,那么 await asyncio.gather(*tasks) 将会返回一个包含这些值的元组。
import asyncio, time
async def say_hello():
print("hello")
await asyncio.sleep(2)
print("world")
async def main():
# 创建并运行三个协程,放入列表中
tasks = [
say_hello(),
say_hello(),
say_hello()
]
await asyncio.gather(*tasks)
if __name__ == "__main__":
start_time = time.time() # 记录开始时间
asyncio.run(main())
end_time = time.time() # 记录结束时间
print(f"程序运行时间: {end_time - start_time:.2f} 秒") #输出 程序运行时间: 2.00 秒由于 say_hello 协程没有返回值,所以 await asyncio.gather(*tasks) 的结果将是一个包含三个 None 的元组

协程的创建方式
下面介绍了两种协程创建方式之间的差异:直接调用协程 vs asyncio.create_task()
在上面我们直接调用了say_hello()协程函数,并将返回的协程对象放入了tasks列表中
# 创建并运行三个协程,放入列表中
tasks = [
say_hello(),
say_hello(),
say_hello()
]
await asyncio.gather(*tasks) 还有一种是使用asyncio.create_task()显式地创建协程任务。这个函数会立即调度协程的执行(虽然它不会立即完成,因为协程是异步的),并返回一个Task对象,这个对象可以被用来取消任务、检查任务状态等。
# 创建并运行三个协程,放入列表中
tasks = []
for _ in range(3):
task = asyncio.create_task(say_hello()) # 显式地创建协程任务
tasks.append(task)
await asyncio.gather(*tasks) # 等待所有任务完成asyncio.create_task() 与 直接调用协程的具体差异:
- 执行时机与任务管理
-
- asyncio.create_task(): 使用asyncio.create_task()会立即将协程调度为任务,并返回一个Task对象。这意味着协程可能在await asyncio.gather(*tasks)之前就已经开始执行了,具体取决于事件循环的调度。此外,通过Task对象,你可以更方便地管理任务,例如取消任务、检查任务状态等。
- 直接调用协程: 直接调用协程(如say_hello())只是创建了一个协程对象,并将其放入列表中。这个协程对象在await asyncio.gather(*tasks)之前并没有开始执行。同时,由于没有Task对象,你无法直接管理该协程的生命周期。
- 资源管理和控制
-
- asyncio.create_task(): 使用asyncio.create_task()创建的任务对象提供了更多的资源管理和控制功能。你可以使用Task对象的cancel()方法取消任务,或者使用done()、cancelled()等方法检查任务的状态。
- 直接调用协程: 直接调用协程创建的协程对象没有提供这些高级功能。你只能等待它们完成或失败,而无法直接控制它们的执行或取消它们。
- 可读性和习惯
-
- asyncio.create_task(): 在许多异步编程的上下文中,使用asyncio.create_task()来创建任务是更常见和推荐的做法。它明确表达了创建任务并等待其完成的意图,使得代码更加清晰和易于理解。
- 直接调用协程: 虽然直接调用协程在功能上也能达到同样的效果,但在某些情况下可能会让代码看起来有些模糊。特别是当你有多个协程需要管理时,使用asyncio.create_task()可以使代码更加整洁和结构化。
- 兼容性
-
- asyncio.create_task(): 这个函数是在Python 3.7中引入的,如果你使用的是更早的版本,那么你需要使用asyncio.ensure_future()来达到类似的效果。
- 直接调用协程: 直接调用协程的方式在Python的异步编程中是通用的,不受版本限制。
综上所述,使用asyncio.create_task()来创建和管理协程任务通常是一个更好的选择,因为它提供了更多的灵活性、可读性和资源管理功能。然而,在某些简单的场景下,直接调用协程也是可行的。
控制协程的并发数
下面主要介绍使用asyncio.Semaphore()限制协程并发数量。
如下,当要执行100个携程时,程序默认会尝试同时运行它们,所耗时间也为2秒。然而,如果我们不希望程序同时运行过多协程以节省资源或避免性能问题,我们可以通过控制协程的并发数量来优化程序的执行。这样做可以确保在任何时候只有一定数量的协程在运行,从而更有效地管理资源并提高程序的稳定性和响应性。
import asyncio, time
async def say_hello():
print("hello")
await asyncio.sleep(2)
print("world")
async def main():
tasks = []
for _ in range(100):
task = asyncio.create_task(say_hello())
tasks.append(task)
await asyncio.gather(*tasks)
if __name__ == "__main__":
start_time = time.time() # 记录开始时间
asyncio.run(main())
end_time = time.time() # 记录结束时间
print(f"程序运行时间: {end_time - start_time:.2f} 秒") #输出 程序运行时间: 2.02 秒要控制协程的并发数量,可以使用asyncio.Semaphore。Semaphore是一个基于计数器的同步原语,用于限制对共享资源的并发访问数量。在异步编程中,你可以用它来限制同时运行的协程数量。
限制同时运行的携程数量最大为20,程序所耗时间由原来的2s变为2 x 5 = 10s
- sem = asyncio.Semaphore(20) 这意味着在任何时候最多有 20 个协程可以并行执行 say_hello 函数。
- async with sem: 这行代码是一个上下文管理器,用于确保在 async with 块内的代码执行期间,有一个 Semaphore 的许可(或“令牌”)被占用。如果 Semaphore 当前没有可用的许可,那么尝试进入这个 async with 块的协程将会被挂起,直到有许可可用。
import asyncio, time
async def say_hello(sem):
async with sem:
print("hello")
await asyncio.sleep(2)
print("world")
async def main():
sem = asyncio.Semaphore(20)
tasks = []
for _ in range(100):
task = asyncio.create_task(say_hello(sem))
tasks.append(task)
await asyncio.gather(*tasks)
if __name__ == "__main__":
start_time = time.time() # 记录开始时间
asyncio.run(main())
end_time = time.time() # 记录结束时间
print(f"程序运行时间: {end_time - start_time:.2f} 秒") #输出 程序运行时间: 10.06 秒aiohttp发送HTTP请求
当你使用 asyncio 编写协程代码并希望发送HTTP请求时,你应该使用异步的HTTP库,如 aiohttp。而requests 库是一个同步的HTTP库,它不支持在协程中直接使用,因为它会阻塞事件循环,导致协程并发执行的优势无法体现。
aiohttp是基于asyncio的第三方库,专注于异步HTTP请求和Web应用的开发。它们的结合使得编写高性能的异步网络通信变得更加方便和灵活。
主要特点:
- 异步处理:aiohttp利用Python的asyncio库实现异步处理,这意味着它可以同时处理多个请求,提高系统的并发能力和性能。
- 轻量级:aiohttp是一个轻量级的框架,代码简洁易懂,学习成本低。
- 高性能:由于采用异步处理方式,aiohttp能够处理大量并发请求,适用于需要处理大量请求的高并发场景。
- 可扩展性:aiohttp提供了丰富的扩展接口和插件机制,可以方便地扩展功能。
- 支持WebSocket:aiohttp支持WebSocket协议,可以实现实时通信和推送功能。
aiohttp和request的区别
1. 实现方式
- aiohttp:
-
- 基于Python的asyncio库,实现异步IO操作。
- 允许在等待IO操作完成时不阻塞程序,而是继续执行其他任务。
- 支持HTTP/1.1和HTTP/2协议,能够高效地处理大量并发请求。
- requests:
-
- 同步HTTP库,按照传统的阻塞方式发送请求。
- 在发送一个请求时,程序会等待该请求完成后再继续执行下一个请求。
2. 性能特点
- aiohttp:
-
- 异步编程模型使得aiohttp在处理高并发和IO密集型任务时具有显著优势。
- 由于能够同时处理多个请求,因此具有更高的吞吐量和更快的响应速度。
- 例如,在发送大量请求时,aiohttp的异步特性可以显著减少总体请求时间。
- requests:
-
- 同步请求模型在处理大量请求时会导致性能瓶颈。
- 发送请求的数量增加时,总体请求时间将显著增加。
3. 适用场景
- aiohttp:
-
- 适用于需要处理大量并发请求的场景,如Web服务器、实时通信应用等。
- 在对性能有严格要求的环境中,aiohttp是更好的选择。
- requests:
-
- 适用于对性能要求不高的简单HTTP请求场景。
- 在不需要处理大量并发请求的情况下,requests的简单易用性使其成为一个不错的选择。
4. 其他功能
- aiohttp:
-
- 提供了异步Web服务器和客户端的功能,可以方便地构建异步Web应用。
- 支持WebSocket协议,方便实现实时通信。
- requests:
-
- 提供了丰富的功能特性,如Keep-Alive、连接池、国际化域名和URL支持等。
- 具有简单易用的API,可以快速上手。
简单的aiohttp案例
首先安装aiohttp
pip install aiohttp
对列表中的url批量请求,如果响应码为200则使用print输出。
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as response:
print(url, response.status)
async def main():
async with aiohttp.ClientSession() as session:
# 创建一个任务列表
tasks = []
urls = [
'http://127.0.0.1',
'http://192.168.59.132',
'http://www.baidu.com',
'http://127.0.0.1',
'http://192.168.59.132',
'http://www.baidu.com',
'http://127.0.0.1',
'http://192.168.59.132',
'http://www.baidu.com'
]
# 为每个URL创建一个fetch任务
for url in urls:
task = asyncio.create_task(fetch(session, url))
tasks.append(task)
# 等待所有任务完成
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main()) 可以看到cmd中的输出并不会像线程池一样乱序,print时无需使用with lock。因为协程的执行顺序是由事件循环控制的

aiohttp.ClientSession()
async with aiohttp.ClientSession() as session 用于创建一个 HTTP 会话(session)对象,并自动管理其生命周期。主要特点如下
- 复用 TCP 连接:通过创建一个会话对象,你可以在多个 HTTP 请求之间复用底层的 TCP 连接。这避免了为每个请求都建立新的 TCP 连接的开销,提高了性能和效率。
- 连接池:aiohttp.ClientSession 默认使用连接池来管理 TCP 连接。这意味着在需要时可以并行发送多个请求,而不需要等待前一个请求完成后再发送下一个。
- 跨请求共享配置:通过会话对象,你可以跨多个请求共享配置,如 cookies、请求头、SSL 验证等。
- 简化资源管理:使用 async with 语句可以确保会话在不再需要时被正确关闭,释放底层资源,如 TCP 连接。这有助于避免资源泄露和潜在的内存泄漏问题。
关于复用 TCP 连接解释:
- TCP连接的建立:
-
- 当你首次通过aiohttp.ClientSession()发起一个HTTP请求时,aiohttp会尝试与服务器建立一个TCP连接。这个连接过程包括TCP三次握手,是一个相对耗时的操作。
- HTTP请求与TCP连接:
-
- 一旦TCP连接建立成功,你就可以在这个连接上发送多个HTTP请求。这些请求会共享同一个TCP连接,而不是每个请求都创建一个新的连接。
- 对于HTTP/1.1,通过Keep-Alive头部信息,客户端和服务器都可以表示它们愿意在单个TCP连接上发送多个请求/响应,而不是在每次请求后都关闭连接。
- 复用TCP连接的过程:
-
- 当你使用aiohttp.ClientSession()并发起多个HTTP请求时,这些请求会尽可能地复用已经建立的TCP连接。
- 如果当前有可用的TCP连接(即连接池中有空闲的连接),aiohttp就会使用这个连接来发送新的HTTP请求。
- 如果没有可用的连接(例如,所有的连接都在使用中或连接池中没有连接),aiohttp可能会尝试建立一个新的TCP连接,或者等待一个连接变得可用。
- 为什么复用TCP连接有用:
-
- 性能提升:避免了为每个HTTP请求都进行TCP三次握手的开销,从而减少了网络延迟。
- 资源效率:减少了频繁建立和关闭TCP连接所需的系统资源(如内存和CPU时间)。
- 更好的错误处理:在会话中,你可以更容易地处理诸如重定向、cookies、HTTP头、SSL验证等跨多个请求的问题。
aiohttp.ClientSession() 放置的位置
上面async with aiohttp.ClientSession() as session放在了main函数中,我们也可以fetch函数中,都能正常工作。但是它们之间的区别是什么?
放在main函数中:
- 如果你打算在整个程序的生命周期中只使用一个会话,或者你想要控制会话的创建和关闭,那么将其放在main函数中是一个好选择。
- 在这种情况下,你可以在main函数中创建一个会话,并将它作为参数传递给fetch函数(或者其他需要发送HTTP请求的函数)。
- 这种方法的优点是你可以更清晰地控制会话的生命周期,并避免在多个地方重复创建和关闭会话。
放在fetch函数中:
- 如果你打算在每次发送请求时都创建一个新的会话,或者你的程序结构使得在fetch函数中创建会话更加方便,那么你可以将async with语句放在fetch函数中。
- 在这种情况下,每次调用fetch函数时都会创建一个新的会话,并在请求完成后自动关闭它。
- 这种方法的好处是简单直接,但如果你发送大量请求,频繁地创建和关闭会话可能会影响性能。
建议:
- 通常情况下,推荐在main函数中创建一个会话,并将其作为参数传递给其他需要发送HTTP请求的函数。这样可以复用TCP连接,提高性能。
- 如果你确实需要在每次请求时都创建一个新的会话(例如,出于安全性或隔离性的考虑),那么可以将async with语句放在fetch函数中。
- 无论你选择哪种方法,都要确保会话在使用完毕后被正确关闭,以避免资源泄漏。如果你将会话作为参数传递,请确保在调用者中正确处理异常,以确保即使发生错误也会关闭会话。
import asyncio
import aiohttp
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
print(url, response.status)
async def main():
# 创建一个任务列表
tasks = []
urls = [
'http://127.0.0.1',
'http://192.168.59.132',
'http://www.baidu.com',
'http://127.0.0.1',
'http://192.168.59.132',
'http://www.baidu.com',
'http://127.0.0.1',
'http://192.168.59.132',
'http://www.baidu.com'
]
# 为每个URL创建一个fetch任务
for url in urls:
task = asyncio.create_task(fetch(url))
tasks.append(task)
# 等待所有任务完成
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main()) session.get()发送HTTP请求
“async with session.get(url) as response”在Python的异步编程中用于发起一个HTTP GET请求,并管理HTTP响应对象的生命周期。
该请求会返回一个HTTP响应对象,这个对象包含了HTTP响应的所有信息,如状态码、响应头、响应体等。
session.get()中常见的请求参数
- 添加请求头header
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
session.get(url=url, headers=header)- 设置请求超时时间
#表示整个请求(包括连接和读取)的超时时间为15秒。
session.get(url, timeout=aiohttp.ClientTimeout(total=15))- 是否允许自动重定向
#默认情况下,allow_redirects 参数的值为 True,即自动重定向。
session.get(allow_redirects=False)- 设置代理,proxy是一个字符串而不是字典
##所有http或https的url都会走8080代理端口
session.get(url=url, proxy='http://127.0.0.1:8080')- 禁用ssl验证
connector = aiohttp.TCPConnector(ssl=False)
async with aiohttp.ClientSession(connector=connector) as session: HTTP响应对象属性
async with session.get(url) as response 语句中的 response 对象是一个HTTP响应的对象,它提供了多种方法和属性来访问响应的不同部分。
#获取一个异步上下文管理器,response 就是异步上下文管理器返回的响应对象
async with session.get(url) as response:
#获取响应码,会自动处理重定向。即获取的是重定向后的状态码
code = response.status
#以字符串的形式返回响应体的内容。或者使用await response.read()来获取原始的字节响应体。
await response.text()
#返回一个包含响应内容的 bytes 对象。你可以使用它来获取响应的原始字节内容。
content = response.read()
#响应头
headers = response.headers异常处理
和普通的异常处理一样,如下捕获http请求的错误
async def fetch(session, url):
try:
async with session.get(url) as response:
print(url, response.status)
except Exception as e:
print(str(e))请求重试
如下手动实现重试逻辑,当max_retries = 2时,当请求错误时会自动重试两次
import asyncio
import aiohttp
max_retries = 2 # 设置最大重试次数
async def fetch(session, url, retries=0):
try:
async with session.get(url, proxy='http://127.0.0.1:8080', timeout=aiohttp.ClientTimeout(total=3)) as response:
print(url, response.status)
except Exception as e:
if retries < max_retries:
# 递归调用自身,增加重试次数
await asyncio.sleep(0.5) # 可以添加等待时间,避免过于频繁的请求
return await fetch(session, url, retries + 1)
else:
pass
async def main():
async with aiohttp.ClientSession() as session:
# 创建一个任务列表
tasks = []
urls = [
'http://192.168.59.132',
'http://192.168.59.134'
]
# 为每个URL创建一个fetch任务
for url in urls:
task = asyncio.create_task(fetch(session, url))
tasks.append(task)
# 等待所有任务完成
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main()) 协程进阶
使用 asyncio.Lock 保护共享资源
在批量请求时,往往需要将结果保存,如保存到列表中,此时我们需要使用同步机制来确保资源在任一时刻只有一个协程可以访问和修改列表。当一个协程获得了锁并准备修改列表时,其他尝试获取同一锁的协程将被阻塞,直到锁被释放为止。
在asyncio中,通常通过asyncio.Lock实现。
import asyncio
import aiohttp
max_retries = 2 # 设置最大重试次数
alive_code = [200, 301, 302, 303, 304, 401, 403]
results = []
# 创建一个锁来保护对results的写入
lock = asyncio.Lock()
async def dirfuzzMain(session, sem, path, retries=0):
async with sem:
try:
async with session.get(path, proxy='http://127.0.0.1:8080', timeout=aiohttp.ClientTimeout(total=3)) as response:
code = response.status
if code in alive_code:
print(path, code)
# 使用锁来保护对results的写入
async with lock:
results.append((path, code))
except Exception as e:
if retries < max_retries:
# 递归调用自身,增加重试次数
await asyncio.sleep(0.5) # 可以添加等待时间,避免过于频繁的请求
return await dirfuzzMain(session, sem, path, retries + 1)
else:
pass
async def main():
url = "http://192.168.59.132"
dicc = [line.strip().rstrip('/') for line in open("dicc.txt", "r", encoding="utf-8")]
sem = asyncio.Semaphore(60)
connector = aiohttp.TCPConnector(ssl=False)
async with aiohttp.ClientSession(connector=connector) as session:
# 创建一个任务列表
tasks = []
# 为每个URL创建一个fetch任务
for path in dicc:
path = url + "/" + path
task = asyncio.create_task(dirfuzzMain(session, sem, path))
tasks.append(task)
# 等待所有任务完成
await asyncio.gather(*tasks)
print(results)
if __name__ == "__main__":
loop = asyncio.get_event_loop() #获取当前的事件循环
loop.run_until_complete(main()) #启动事件循环并运行给定的协程,直到该协程完成。tqdm显示进度条
tqdm 通常用于在 Python 中显示一个进度条,特别是在循环或迭代过程中。它可以帮助用户直观地了解代码的执行进度。
在协程中使用 tqdm
- 在异步环境中使用 asyncio 运行时,使用 tqdm.asyncio.tqdm 可以确保进度条的更新与异步任务同步,从而提供更准确的进度显示。
- 在协程中更新 tqdm 进度条是安全的,因为每个更新都是独立的,并且不依赖于其他协程的状态。
- 不需要使用锁(如 async with lock:)来保护对 tqdm 进度条的访问,因为它不是共享资源,并且更新操作是原子的。
使用 with 语句
- 当使用 tqdm 时,推荐使用 with 语句来创建和管理进度条对象。这样可以确保在 with 块结束时,进度条会被正确地关闭,并且与之相关的资源会被释放(尽管 tqdm 可能不持有太多需要显式释放的资源)。
- 使用 with 语句还可以提高代码的可读性和健壮性,因为它自动处理了进度条的初始化和清理。
import asyncio
import aiohttp
from tqdm.asyncio import tqdm # 导入 tqdm 的异步版本
max_retries = 1 # 设置最大重试次数
alive_code = [200, 301, 302, 303, 304, 401, 403]
results = []
lock = asyncio.Lock()
async def dirfuzzMain(session, sem, path, progress_bar, retries=0):
async with sem:
try:
async with session.get(path, proxy='http://127.0.0.1:8080', timeout=aiohttp.ClientTimeout(total=3)) as response:
code = response.status
if code in alive_code:
tqdm.write(path + " " + str(code))
progress_bar.update()
async with lock:
results.append((path, code))
else:
progress_bar.update()
except Exception as e:
if retries < max_retries:
# 递归调用自身,增加重试次数
await asyncio.sleep(0.5) # 可以添加等待时间,避免过于频繁的请求
return await dirfuzzMain(session, sem, path, progress_bar, retries + 1)
else:
progress_bar.update()
async def main():
url = "http://192.168.59.132"
dicc = [line.strip().rstrip('/') for line in open("dicc.txt", "r", encoding="utf-8")]
sem = asyncio.Semaphore(3)
connector = aiohttp.TCPConnector(ssl=False)
with tqdm(total=len(dicc), desc="Requesting", bar_format='{desc}: {percentage:.0f}% ({n_fmt}/{total_fmt}) {elapsed}') as progress_bar:
async with aiohttp.ClientSession(connector=connector) as session:
# 创建一个任务列表
tasks = []
# 为每个URL创建一个fetch任务
for path in dicc:
path = url + "/" + path
task = asyncio.create_task(dirfuzzMain(session, sem, path, progress_bar))
tasks.append(task)
await asyncio.gather(*tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop() #获取当前的事件循环
loop.run_until_complete(main()) #启动事件循环并运行给定的协程,直到该协程完成。
捕获KeyboardInterrupt异常
syncio 协程运行在事件循环中,而事件循环本身可以捕获到 KeyboardInterrupt 并优雅地停止,因为它控制着协程的执行。当在协程中发生 KeyboardInterrupt 时,事件循环会开始取消所有挂起的任务,并等待它们完成或取消。
然而,线程池中的线程则不会直接捕获 Ctrl+C 信号,因为它们通常不直接与信号处理系统交互。Ctrl+C 会被主线程捕获,并触发一个 KeyboardInterrupt 异常。但是,这个异常只会在主线程中抛出,并不会自动传播到线程池中的其他线程。因此,线程池中的线程通常不会直接响应 Ctrl+C。
从 Python 3.7 开始,asyncio.run() 会自动处理 KeyboardInterrupt,并且会尝试优雅地取消并停止所有正在运行的任务。
- 协程自动捕获KeyboardInterrupt并退出,但是退出的不干净,会抛出一些异常

- 屏蔽这些异常,干净的退出
try:
asyncio.run(main())
except KeyboardInterrupt:
print("Exiting due to Ctrl+C...")
如何在捕获ctrl+c的时候,暂停程序并提示用户是否继续还是退出?在协程中涉及到更复杂的处理逻辑。
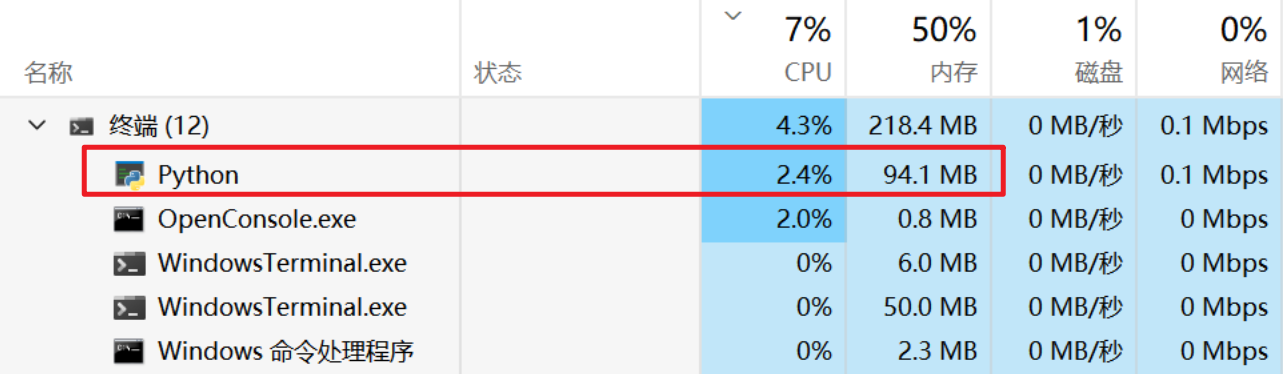
协程和线程池的资源消耗问题
请求1000多个url

一些报错的解决
RuntimeError: Event loop is closed
虽在https://www.yuque.com/dafcs-dqalz/uz9oso/kd4dgha3mk62trse#cqjcb中推荐使用asyncio.run()来运行协程,但是在windows下某些时候它会报错

解决办法是还是将 asyncio.run(main())替换为如下旧的运行方式
loop = asyncio.get_event_loop()
loop.run_until_complete(main()) 
参考:https://www.cnblogs.com/james-wangx/p/16111485.html