介绍
一句话,
G
e
n
s
i
m
Gensim
Gensim中的word2vec类就是用来训练词向量的,这个类实现了词向量训练的两种基本模型
s
k
i
p
−
g
r
a
m
skip-gram
skip−gram和
C
B
O
W
CBOW
CBOW,可以通过后面的参数设置来选择,。但是,在Gensim这个模块中训练词向量的方法还有很多:
**gensim.models.doc2vec.Doc2Vec,gensim.models.fasttext.FastText,gensim.models.wrappers.**VarEmbed等等都能得到词向量。
Word2vec类
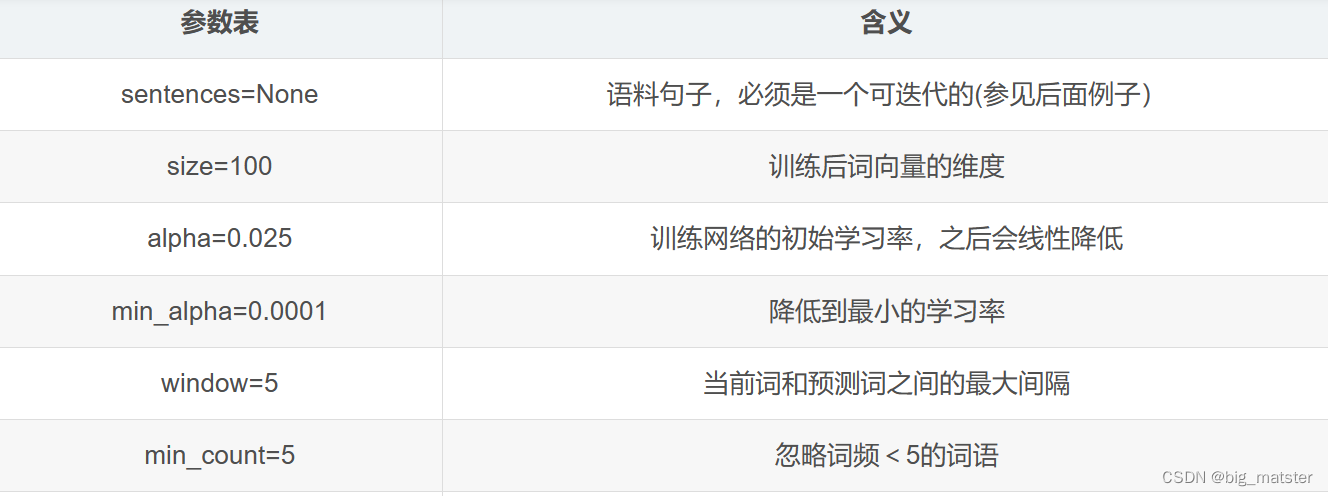
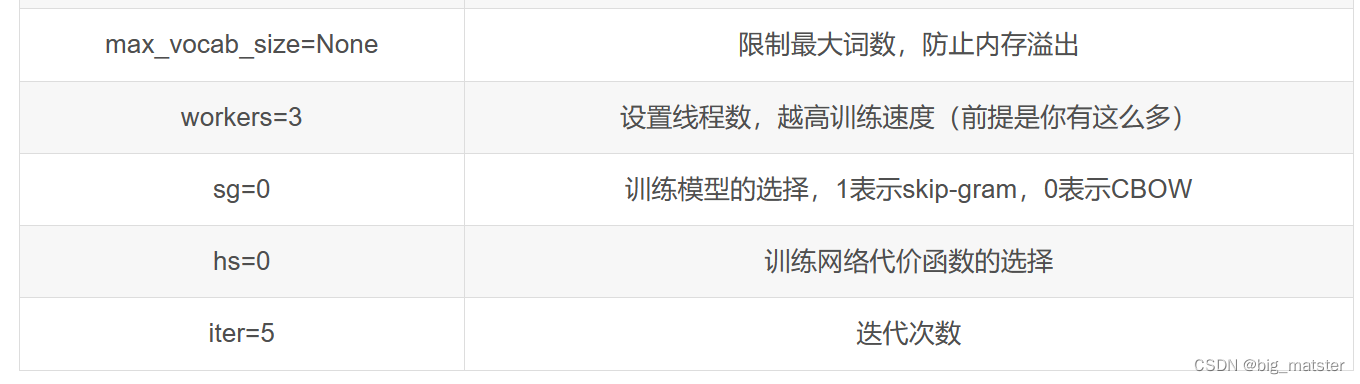
Word2vec初始化参数
在下面介绍参数时,可能不会列举完,完整的参数见word2vec.py源码。
注:参数表这一列,等号右边的值表示默认值
训练保存模型
# 示例1
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
print(common_texts)
train_model = Word2Vec(common_texts, size=100, window=5, min_count=1, workers=4)
train_model.save('./MyModel')
train_model.wv.save_word2vec_format('./mymodel.txt', binary=False)
训练模型
只要给
w
o
r
d
2
v
e
c
word2vec
word2vec类赋上参数,就可以直接训练了,其中common_texts是一段内置的语料如下:


保存模型
在示例1中,第8行和第10行都是用来保存训练模型的(简称 s a v e save save和 f o r m a t s a v e format_save formatsave),而两者之间的相同点就是:都可以复用,即载入之后可以得到对应单词的词向量;不同点是**:save保存的模型,载入之后可以继续在此基础上接着训练**(后文会介绍),而format_save保存的模型不能,但有个好处就是如果s设置binary=False则保存后的结果可以直接打开查看(一共有12个词向量,每个词向量100维)
12 100
system -0.0027418726 -0.0029260677 0.0002653271 ......
user 0.000851792 -0.004782654 0.0017041893 ......
trees 6.689873e-05 0.0027949389 -0.002869004 ......
graph -0.0038760677 -0.0021227715 0.0029032128 ......
......
......
载入模型和使用
我们只使用4个维度来表示词向量。
#示例 2 查看词表相关信息
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
model = Word2Vec.load('./MyModel')
# 对于训练好的模型,我们可以通过下面这前三行代码来查看词表中的词,频度,以及索引位置,
# 最关键的是可以通过第四行代码判断模型中是否存在这个词
for key in model.wv.vocab:
print(key)
print(model.wv.vocab[key])
print('human' in model.wv.vocab)
print(len(model.wv.vocab)) #获取词表中的总词数
#结果:
trees
Vocab(count:3, index:2, sample_int:463795800)
graph
Vocab(count:3, index:3, sample_int:463795800)
minors
Vocab(count:2, index:11, sample_int:579459575)
True
12
获取对应词向量维度
# 示例3 获取对应的词向量及维度
model = Word2Vec.load('./MyModel')
print(model.wv.vector_size)
print(model['human'])
print(model['good'])
# 结果
4
[-0.06076013 -0.03567408 -0.07054472 -0.10322621]
KeyError: "word 'good' not in vocabulary"
Process finished with exit code 1
# 在取词向量之前一定要先判断
计算两个词相似度,
# 示例4 常用方法
#---------------4.1 计算两个词的相似度(余弦距离)--------
model = Word2Vec.load('./MyModel')
print(model.wv.similarity('human', 'user'))
print(model.wv.similarity('human', 'survey'))
# 结果越大越相似(此处由于维度太小,所以结果好像不怎么准确)
-0.6465453
0.55347687
#---------------4.2 计算两个词的距离--------
model = Word2Vec.load('./MyModel')
print(model.wv.distance('human', 'user'))
print(model.wv.distance('human', 'survey'))
# 结果越大越不相似
1.6465452909469604
0.44652312994003296
#---------------4.3 取与给定词最相近的topn个词--------
model = Word2Vec.load('./MyModel')
print(model.wv.most_similar(['human'],topn=3))
#结果
[('computer', 0.7984297871589661), ('response', 0.6434261798858643), ('survey', 0.5534768104553223)]
#---------------4.4 找出与其他词差异最大的词
model = Word2Vec.load('./MyModel')
print(model.wv.doesnt_match(['human','user','survey']))
#结果
user
其他还有很多如:
words_closer_than(),similar_by_word(),similar_by_vector(),similarity_matrix()
参见源码keyedvectors.py
载入模型并继续训练
载入模型并继续训练意思是,之前训练好了一个词向量模型,可能训练时间不足,或者又有了新的数据,那么此时就可以在原来的基础上接着训练而不用从头再来。
#示例 5
model = Word2Vec(sentences=pos,size=50,min_count=5)
model.save('./vec.model_pos')
print('语料数:', model.corpus_count)
print('词表长度:', len(model.wv.vocab))
# 结果
语料数: 5000
词表长度: 6699
#-------------增量训练
model = Word2Vec.load('./vec.model_pos ')
model.build_vocab(sentences=neg, update=True)
model.train(sentences=neg, total_examples=model.corpus_count, epochs=model.iter)
model.save('./vec.model')
print('语料数:', model.corpus_count)
print('词表长度:', len(model.wv.vocab))
# 结果
语料数: 5001
词表长度: 8296
可以看到,第一次训练时用了5000个语料,训练完成后词表中一共有6699个词;在追加训练时,用了5001个语料,此时词表中一共就有了8296个词
载入模型和使用
我们用之前训练好的模型来演示
# 示例 6
model = Word2Vec.load('./vec.model')
print('词表长度:', len(model.wv.vocab))
print('爱 对应的词向量为:',model['爱'])
print('喜欢 对应的词向量为:',model['喜欢'])
print('爱 和 喜欢的距离(余弦距离)',model.wv.similarity('爱','喜欢'))
print('爱 和 喜欢的距离(欧式距离)',model.wv.distance('爱','喜欢'))
print('与 爱 最相近的3个词:',model.wv.similar_by_word('爱',topn=3))
print('与 喜欢 最相近的3个词:',model.wv.similar_by_word('喜欢',topn=3))
print('爱,喜欢,恨 中最与众不同的是:',model.wv.doesnt_match(['爱','喜欢','恨']))
#结果
词表长度: 8296
爱 对应的词向量为: [-1.0453074 -2.5688617 1.2240907 ...
喜欢 对应的词向量为: [-0.5997423 -1.8003637 1.2935492 ...
爱 和 喜欢的距离(余弦距离) 0.89702404
爱 和 喜欢的距离(欧式距离) 0.10297596454620361
与 爱 最相近的3个词: [('喜欢', 0.89702), ('伤害', 0.88481), ('情感', 0.883626)]
与 喜欢 最相近的3个词: [('青梅竹马', 0.91182), ('轻浮', 0.91145), ('爱', 0.89702)]
爱,喜欢,恨 中最与众不同的是: 恨