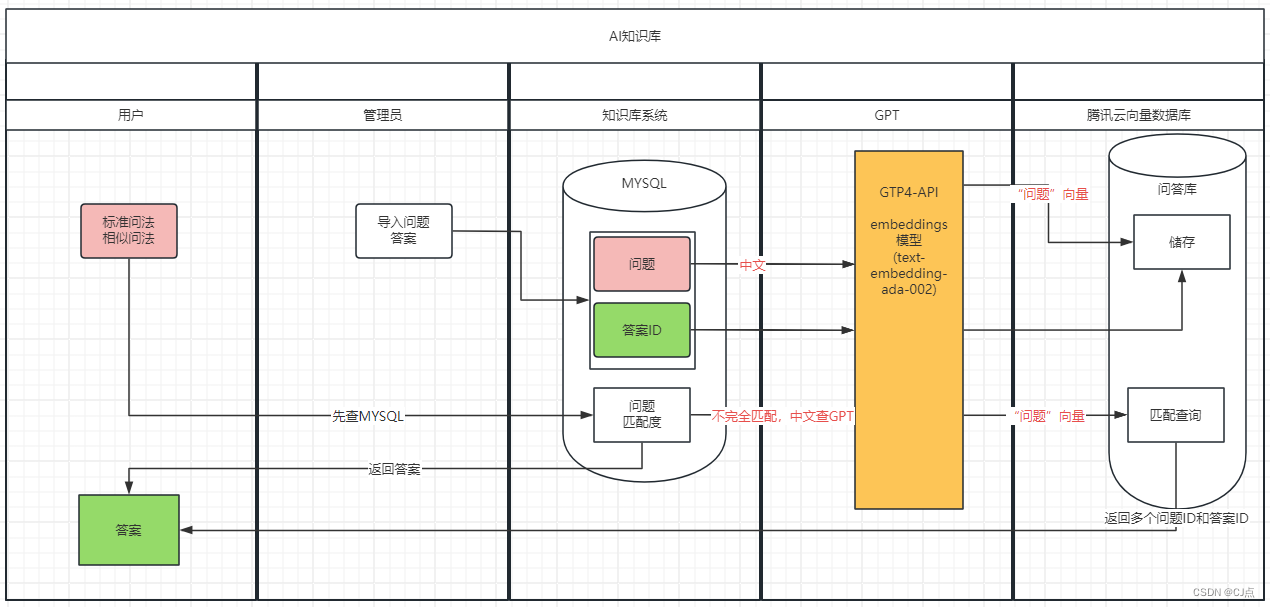
主要通过深度优先搜索来完成树的重心,其中关于树的重心的定义可以结合文字多加理解。
文章目录
前言☀
一、树的重心☀
二、算法思路☀
1.图用邻接表存储
2.图的遍历
3.算法思路
二、代码如下☀
1.代码如下:
2.读入数据
3,代码运行结果
总结
前言☀
主要通过深度优先搜索来完成树的重心,其中关于树的重心的定义可以结合文字多加理解。
提示:以下是本篇文章正文内容,下面案例可供参考
一、树的重心☀
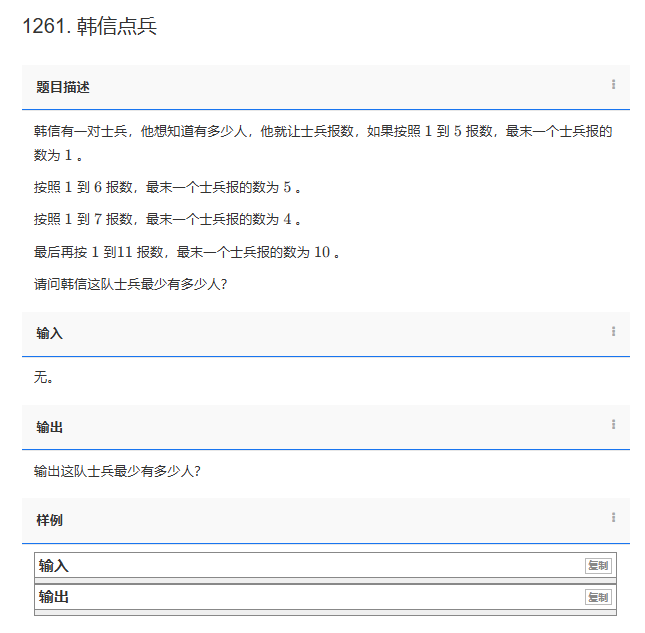
给定一颗树,树中包含 n 个结点(编号 1∼n)和 n−1 条无向边。
请你找到树的重心,并输出将重心删除后,剩余各个连通块中点数的最大值。
重心定义:重心是指树中的一个结点,如果将这个点删除后,剩余各个连通块中结点数的最大值最小,那么这个节点被称为树的重心。
输入格式
第一行包含整数 n,表示树的结点数。
接下来 n−1行,每行包含两个整数 a 和 b,表示点 a 和点 b 之间存在一条边。
输出格式
输出一个整数 m,表示将重心删除后,剩余各个连通块中点数的最大值。
数据范围
1≤n≤100000
二、算法思路☀
1.图用邻接表存储
我们通过一个链表数组来存储,我们把数组中每一个链表的起点对应图中的一个结点,然后与该结点相连的结点,挂在数组中对应起始结点的后面即可,图示如下:

图1.1图邻接表存储
我们引入一维整型数组e,存储链表里面的各个结点的值;一维整型数组ne里面存储结点的下一个结点在数组e里面的索引值;整型变量index表示新创建结点在e数组中的下标。
一位整型数组head用来存储图中的每个节点,head[i]表示以i结点为起点的单链表的头结点,链表中的每一个结点都是与i相连的结点,如图1.1所示。故head数组里面的值初始化为-1,表示此时链表都为空。
我们新创建的结点值为b即e[index] = b;然后将新创建的结点头插法插入,即将原本头结点后的所有结点链接到新结点后面即ne[index] = head[a];然后再将头结点指向新创建的结点head[a] = index。注意让index++,保证index一直指向新创建的结点。
//添加边
//头插法
public static void add(int a,int b){
e[index] = b;
ne[index] = head[a];
head[a] = index++;
}关于单链表的基本操作还有不明白的可以去看我的单链表-java-CSDN博客 这篇博客,里面有对单链表操作的各种详细介绍。

2.图的遍历
无向图是特殊的有向图,树也是特殊的图,故我们只需要考虑有向图即可。

图2.1深度优先遍历示例图
深度优先遍历其实就是一条路走到尽头,每当我们走过一个结点会设置一个标记表示已经走过了。当我们走到尽头无法再走时就回退到上一个结点,然后从该结点看看有无其它没走过的路径,无路可走时再回退到上一个结点,所有结点都被走过后就完成了深度优先遍历。依次走过的结点顺序如图2.1的黄色数字描述的顺序一致。

图2.2广度优先遍历示例图
广度优先遍历也叫层序遍历,我们一层一层逐层遍历。可以通过队列模拟,将根结点入队;当队列不为空,弹出结点,然后再将与该结点相连的结点一次入队,重复上述操作,直到队列为空,就遍历的所有的结点。
遍历的顺序如图2.2模拟所示,黄色数字表示层数。
3.算法思路

图3.1样例模拟

图3.2删除结点1连通块情况

图3.3删除结点2连通块情况

图3.4删除结点4各个连通块情况
树的重心:删除一个结点后,剩下的连通块中结点个数最多但是在删除各个结点的连通块中的结点数最小的,那么这个结点就是树的重心。通过上述图3.1-3.4的示例,即我们删除1结点连通块中结点最多是4,删除结点2连通块中结点最多是6,删除结点4连通块中结点最多是5,等等,我们可以知道结点1就是树的重心。

图3.5示例图
我们用深度优先搜索dfs来确定根节点u的结点的个数;当前结点遍历过设置为flag[u] = true;然后用整型变量sum来统计结点的个数,初始化为1(根节点本身),然后访问与u相连的边,如果没有被访问过,就接着对该边进行dfs深度优先搜索,然后更新为删除这一节点后所剩的连通图的结点数目的最大值;将sum加上子树的结点个数就是以u为根节点的结点的个数。
比较删除u后的u子树中最大的连通块(6,3-9中的更大者),和整个树减u子树剩下的连通块(1-2-8-5-7)
res = Math.max(n - sum,res)。
sum:表示以这一点为根结点的树中所有结点个数
res:表示删除这一点后的连通块中结点数目的最大值(不断更新)
ans:表示所有(依次删除每个结点的情况)最大连通结点数目的最小值,即各个res的最小值(不断更新)
所有备注可结合上方图示一起看
//深度优先搜索
//以u为根节点的结点的个数
public static int dfs(int u){
//当前点被搜过了
flag[u] = true;
//存储以u为结点
int sum = 1;
//存储当前删掉某个结点后最大连通子图的个数
int res = 0;
//访问u的子节点
for(int i = head[u];i != -1;i = ne[i]){
int j = e[i];
if(!flag[j]){
int s = dfs(j);
res = Math.max(s,res);
//以u为根结点的树结点数量=1+它各个子树的结点数量
sum += s;
}
}
// 比较删除u后的u子树中最大的连通块(6,3-9中的更大者),和整个树减u子树剩下的连通块(1-2-8-5-7)
res = Math.max(n - sum,res);
//所有最大的连通块结点数目找到最小值
ans = Math.min(ans,res);
return sum;
}
二、代码如下☀
1.代码如下:
import java.io.*;
import java.util.Arrays;
import java.util.Scanner;
public class 树的重心 {
static PrintWriter pw = new PrintWriter(new OutputStreamWriter(System.out));
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static int N = 100010,M = N * 2;
//记录头结点
static int[] head = new int[N];
//存储结点的值
static int[] e = new int[M];
//存储当前结点的下一个结点的索引值
static int[] ne = new int[M];
//最新创建的结点的索引即数组e中空最新的空结点的索引
static int index;
//用来存储结点是否被遍历过了
static boolean[] flag = new boolean[N];
static int n;
static int ans = N;
public static void main(String[] args) {
Scanner sc = new Scanner(br);
n = sc.nextInt();
Arrays.fill(head,-1);
for (int i = 0;i < n - 1;i++){
int a = sc.nextInt();
int b = sc.nextInt();
add(a,b);
add(b,a);
}
dfs(1);
pw.print(ans);
pw.flush();
}
//深度优先搜索
//以u为根节点的结点的个数
public static int dfs(int u){
//当前点被搜过了
flag[u] = true;
//存储以u为结点
int sum = 1;
//存储当前删掉某个结点后最大连通子图的个数
int res = 0;
//访问u的子节点
for(int i = head[u];i != -1;i = ne[i]){
int j = e[i];
if(!flag[j]){
int s = dfs(j);
res = Math.max(s,res);
//以u为根结点的树结点数量=1+它各个子树的结点数量
sum += s;
}
}
res = Math.max(n - sum,res);
//所有最大的连通块结点数目找到最小值
ans = Math.min(ans,res);
return sum;
}
//添加边
public static void add(int a,int b){
e[index] = b;
ne[index] = head[a];
head[a] = index++;
}
}
2.读入数据
9
1 2
1 7
1 4
2 8
2 5
4 3
3 9
4 63,代码运行结果
4总结
这次多看一下图示,理解各变量的意义,代码是简介,其中的意思要多加理解。

![[ue5]建模场景学习笔记(5)——必修内容可交互的地形,交互沙(2)](https://img-blog.csdnimg.cn/direct/fb477df0bdae48f48100a38f630431b9.png)