九头蛇的进化:Tesla AutoPilot 纯视觉方案解析
前言
本文整理自原文链接,写的非常好,给了博主很多启发,投原创是因为平台机制,希望能被更多人看到。
嘿嘿,漫威粉不要打我←_←不是Hail Hydra,我要说的是Tesla AI day上他们的视觉方案,其核心模板的名字也叫HydraNet,很多设计非常有启发性,想和咱们自动驾驶从业者以及爱好者一起来学习交流下。
原视频链接:Tesla AI Day
说一句Tesla牛逼!各个模块的负责人都是行业大牛!!其中CV界华人大佬Fei-Fei Li的学生Andrej Karpathy博士就是我今天要说的这个视觉模块的主讲人。
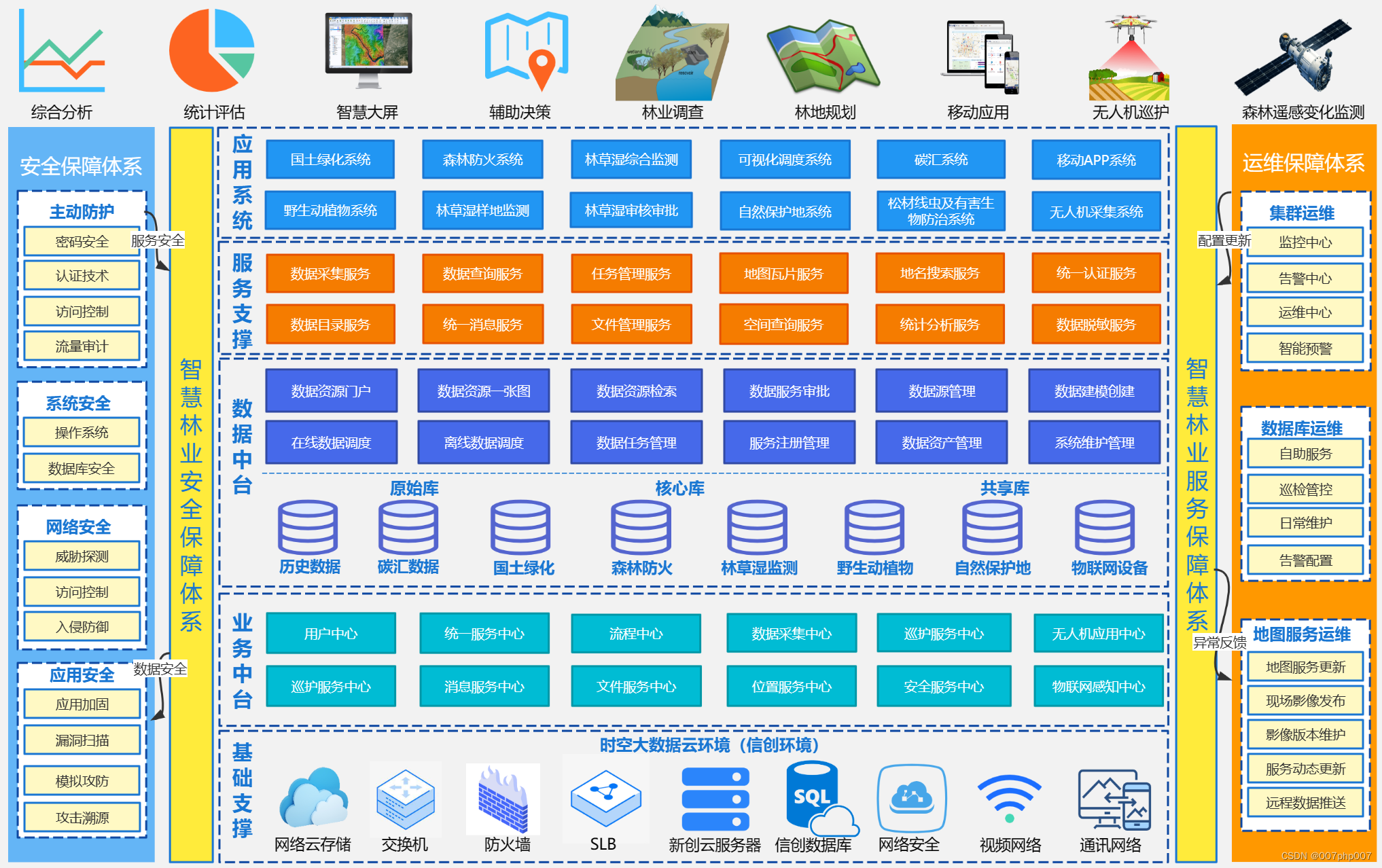
Tesla视觉系统的输入和输出
Tesla的视觉系统由8个摄像头环绕车身,视野范围达360度,每个摄像头采集分辨率为1280×960,12-Bit, 36Hz的RAW格式图像,对周围环境的监测距离最远可达250米。
摄像头捕获环境中的视觉信息经过一系列神经网络模型的处理,最终直接输出3D场景下的“Vector Space”用于后面的规划和智驾系统。

Tesla的8摄像头分为前视3目,负责近、中远3种不同距离和视角的感知;侧后方两目,侧前方两目,以及后方单目,完整覆盖360度场景。
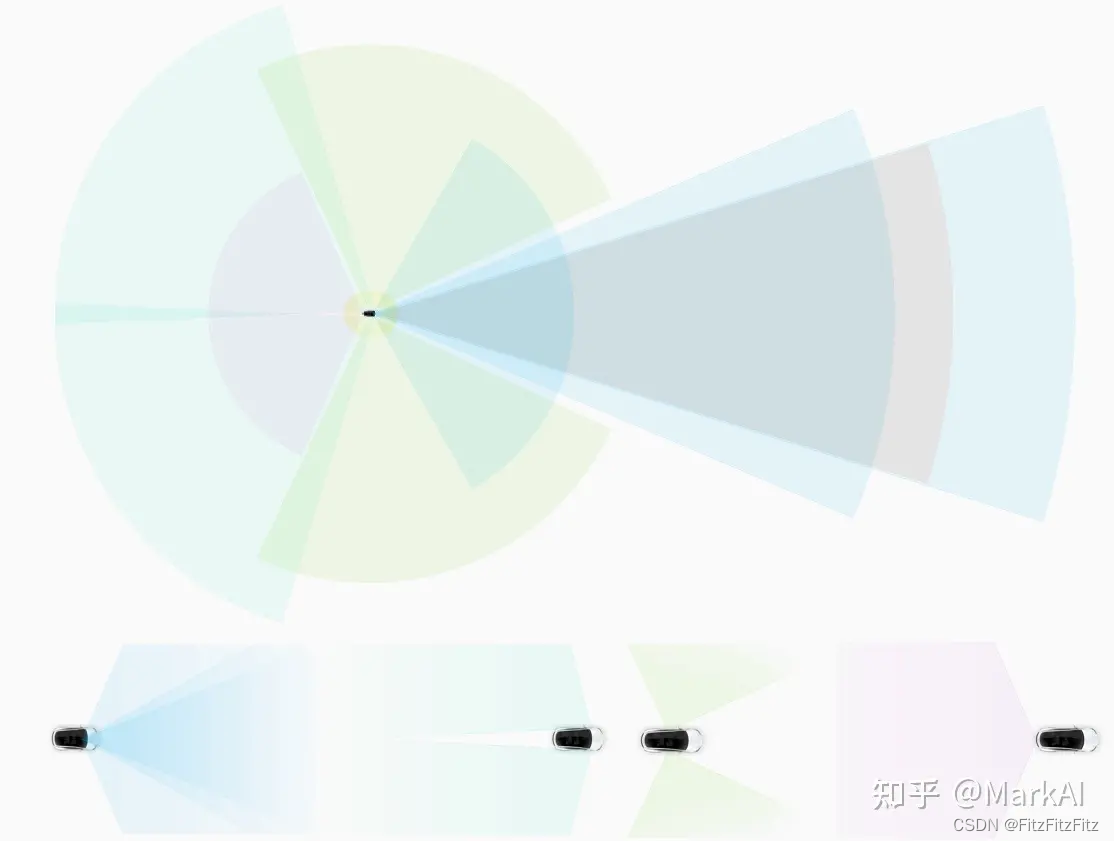
Tesla的自动驾驶感知算法经过了多个版本迭代,最初的HydraNet是比较早期的版本,经过不断的迭代一路进化,应用到了近期的FSD系统中。我们首先介绍一下最初的HydraNet。
HydraNet
HydraNet以分辨率为1280×960,12-Bit, 36Hz的RAW格式图像作为输入,采用的Backbone为RegNet,并使用BiFPN构建多尺度feature map,再在上面再添加task specific的Heads。
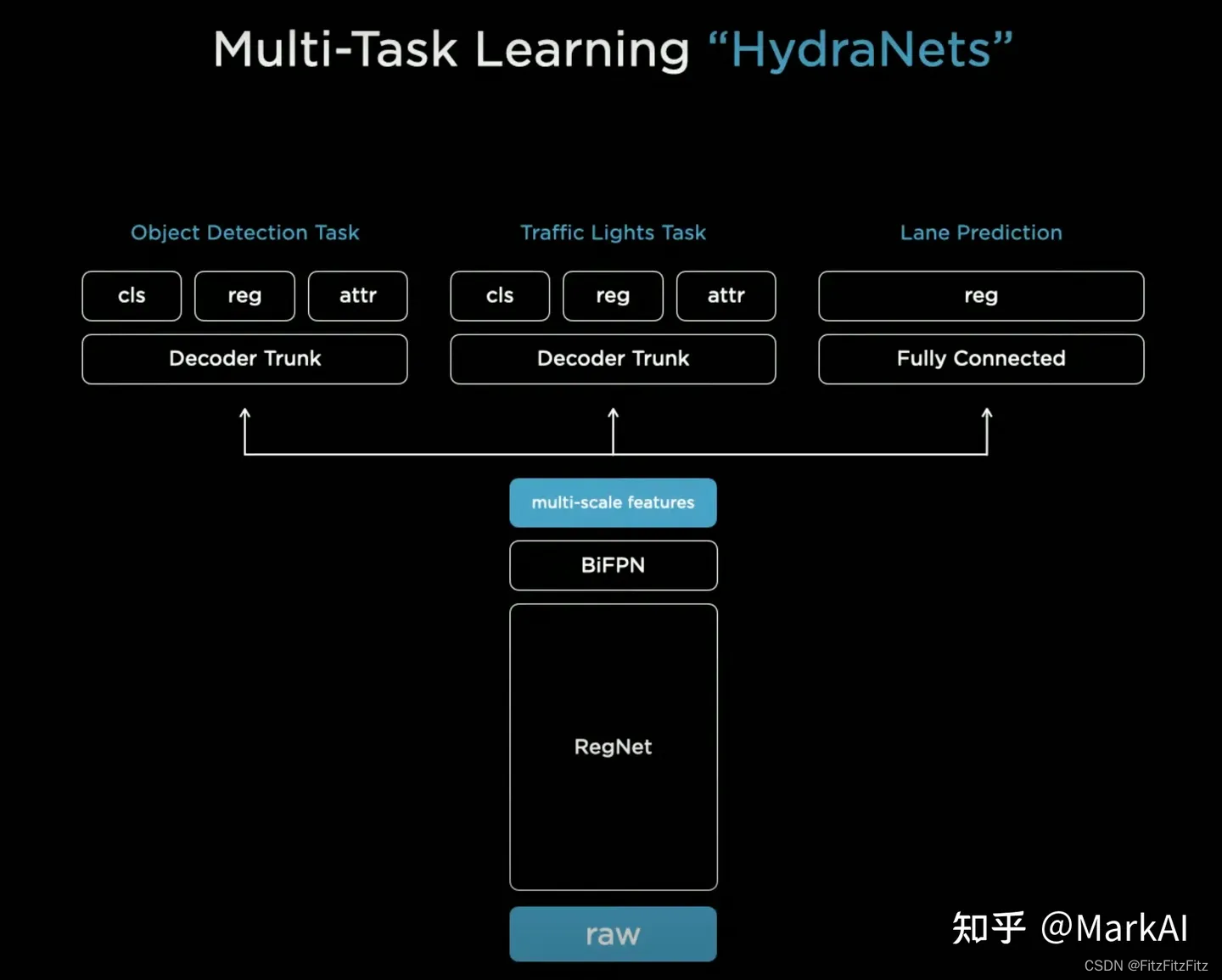
熟悉目标检测或是车道线检测的同学可以发现,初代HydraNet的各个组成部分都是常规操作,没有太多特殊的地方,共享Backbone和BiFPN能够在部署的时候很大程度的节省算力,也算是业界比较常见的。
但是,Tesla却把这样的结构玩出了花来,用这样的结构带来以下三点好处:
- 预测的时候非常高效:因为共享特征,避免了大量的重复计算;
- 可以解耦每个子任务:每个子任务可以在backbone的基础上进行fine-tuning,或是修改,而不影响其他子任务。
- 可以加速fine-tuning:训练过程中可以将feature缓存,这样fine-tuning的时候可以只使用缓存的feature来fine-tune模型的head,而不再需要重复计算。
所以HydraNet实际的训练流程是先端到端地训练整个模型,然后使用缓存的feature分别训练每个子任务,然后再端到端地训练整个模型,以此迭代。
牛就一个字啊!就这样,一个普通的模型就被Tesla把潜力挖掘到了极致,模型训练中一切不必要的计算开销都被省略了。
进化一:多相机输入
我们知道不能简单使用图像上的感知结果来进行自动驾驶,要精确的知道每个交通参与者的位置,道路的走向,需要车体坐标下(Tesla在这里命名为Vector Space)的感知结果。要得到这样的感知结果有三种可能的方案:
- 在各个摄像头上分别做感知任务,然后投影到车体坐标系下进行整合;
- 将多个摄像头的图像直接变换和拼接到车体坐标系下,再在拼接后的图像上做感知任务;
- 直接端到端处理,输入多相机图像,输出车体坐标下的感知结果;
对于方案1,实践发现图像空间的输出并不是正确的输出空间,比如图四,图像空间显示很好的车道线检测结果,投影到Vector space之后,就变得不太能用。
问题的原因在于需要精确到像素级别的预测,才能比较准确地将结果投影到Vector space,而这一要求过于严格。

同时,在多相机的目标检测中,当一个目标同时出现在两个以上摄像头的视野中时,投影到车体坐标之后会出现重影;此外,对于一些比较大的目标,一个摄像头的视野不足以囊括整个目标,每个摄像头都只能捕捉到局部,整合这些摄像头的感知结果就会变成非常困难的事情。
对于方案2,图像完美拼接本就是一件非常困难的事情,同时拼接还会受到路平面以及遮挡的影响。
于是Tesla最终选用了方案3。方案3会面临如下两方面的问题,一方面是如何将图像空间的特征转换到vector space,另一个问题是如何获得vector space下的标注数据。如何获得标注数据的问题比较庞大,可以看我整理的另一篇文章(喜欢的同学关注下我不亏哒!)
长文预警:自动驾驶の核燃料库!Tesla数据标注系统解析
这里主要探讨第一个问题。
关于将图像空间的特征转换到vector space,Tesla采用的方案是直接使用一个Multi-Head Attention的transformer来表示这个转换空间,而将每个摄像头的图像转换为key和value。
我看到这一操作后简直惊为天人,这个方案精妙,完美地运用了Transformer的特点,将每个相机对应的图像特征转换为Key和value,然后训练模型以查表的方式自行检索需要的特征用于预测。
同时难以置信的是,业界还在讨论Transformer能不能用到产品端的时候,Tesla已经悄无声息地将其插入到了最新的系统中!
因为这样的设计,不需要显式地在特征空间上做一些几何变换操作,也不受路平面等因素的干扰,很优雅地将输入信息过渡到了Vector Space!
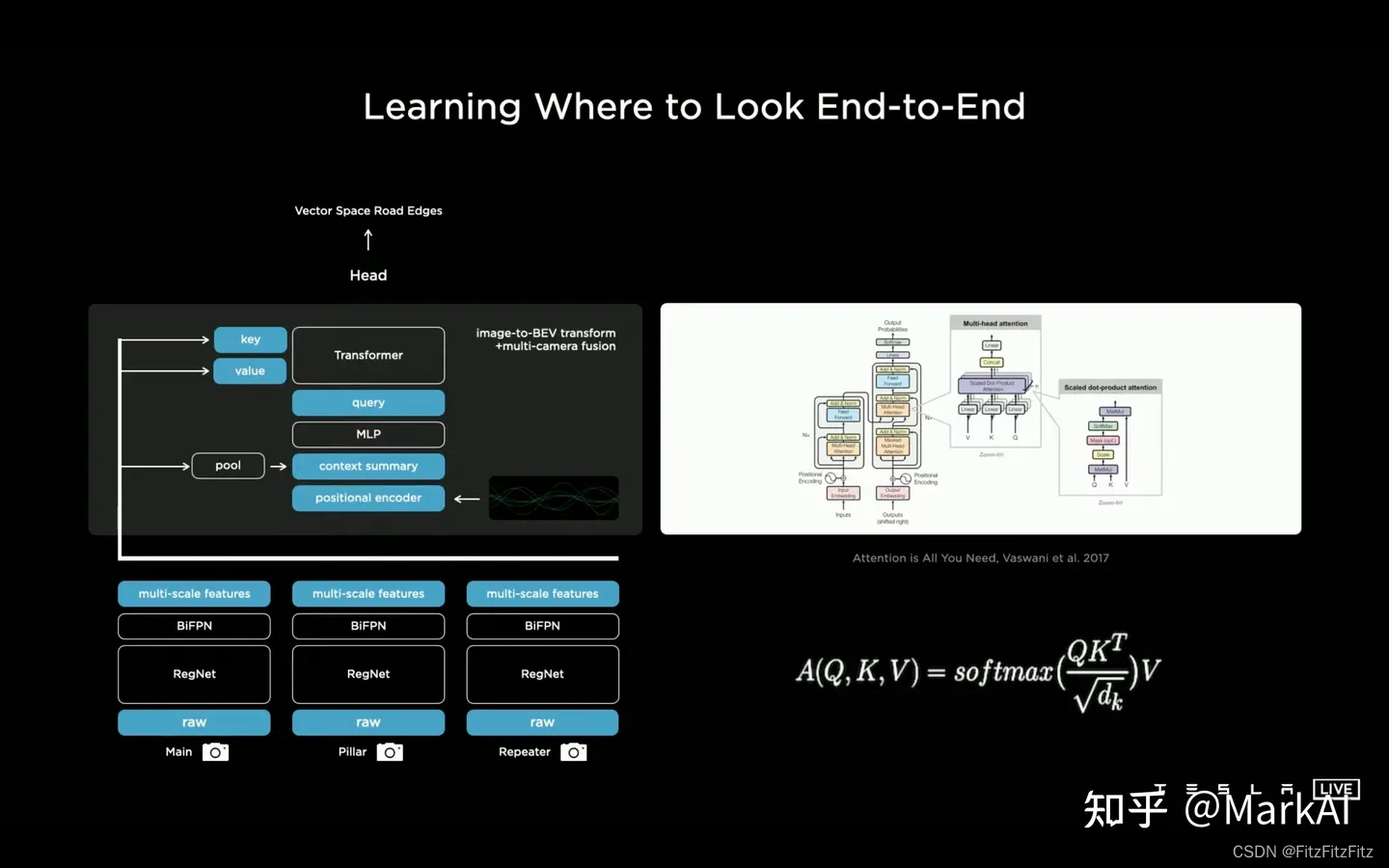
不用怀疑,加入这一优化后的结果就是车道线更加准确清晰,目标检测的结果更加稳定,同时不再有重影。

进化二:时间和空间信息
经过上一步的进化,感知模型虽然可以在多相机输入的情况下得到Vector Sapce下稳定和准确的预测结果,但是依然是单帧处理的,没有考虑时序信息。
而在自动驾驶场景,需要对交通参与者的行为有预判,同时视觉上的遮挡等情况需要结合多帧信息进行处理,因此需要将时序信息考虑进来。
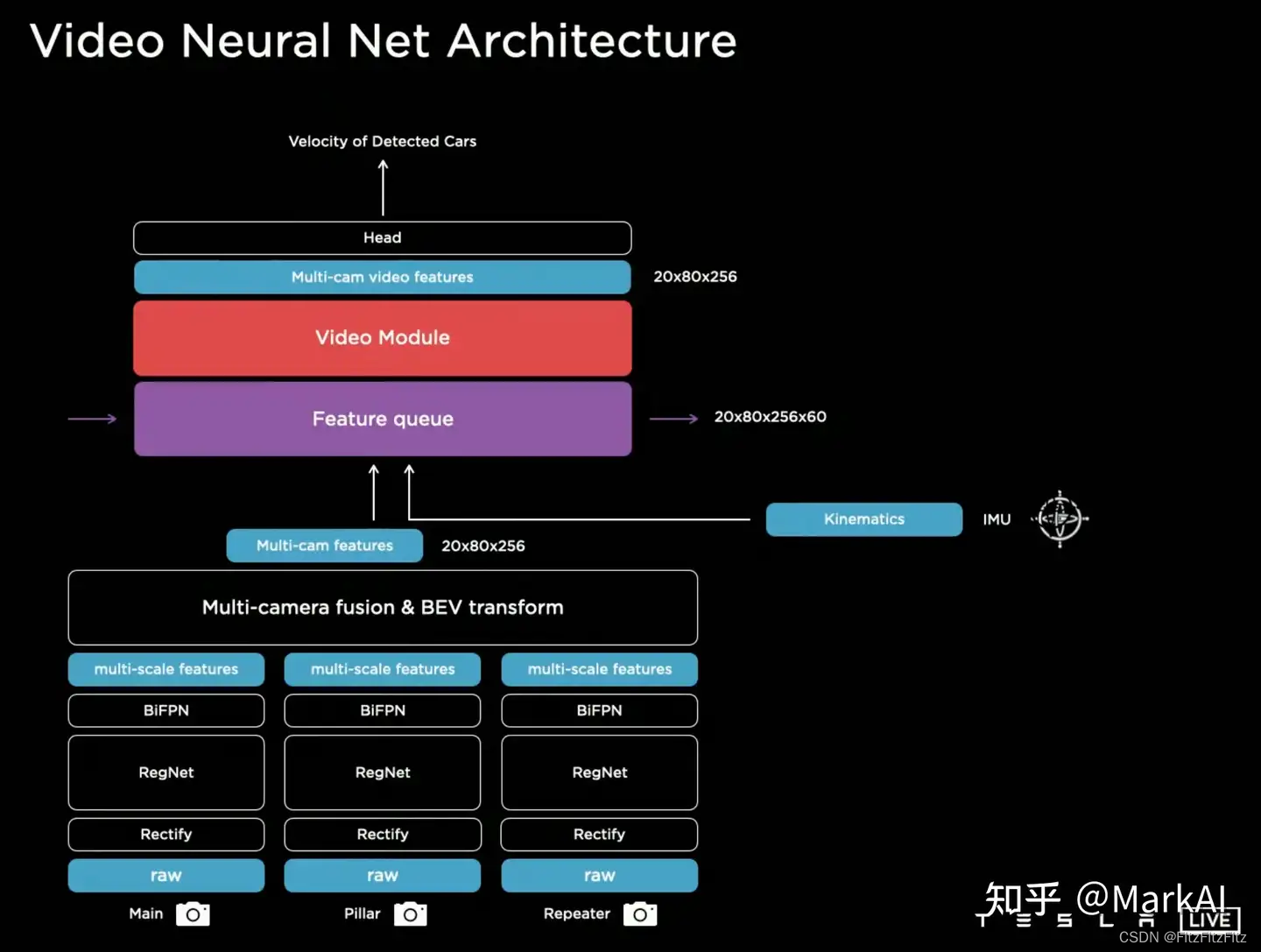
为此,Tesla在网络中又添加了特征队列模块(Feature queue module)用来缓存时序上的一些特征,以及视频模块(Video module)用来融合时序上的信息。此外,还给模型加入了IMU等模块带来的运行学信息比如车速和加速度。
经上述模块处理之后的特征融合了时序上的多相机特征,在Heads中进行解码得到最终输出。
下面首先介绍特征队列模块。
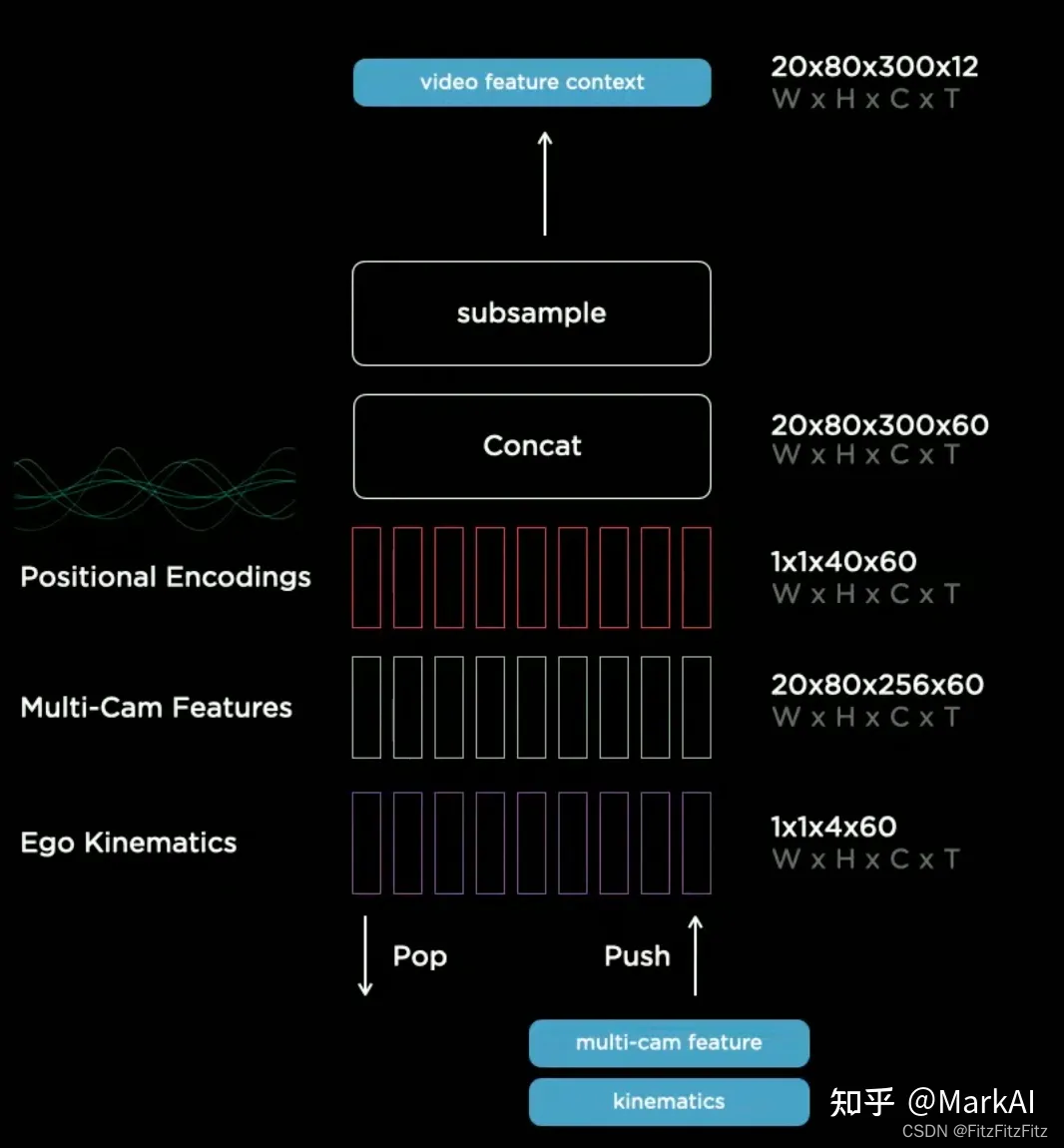
特征队列模块将时序上多个相机的特征,运动学的特征,以及特征的position encoding concat到一起,这一组合后的特征将在Video Module中使用。
顾名思义,特征队列模块按照队列的数据结构组织特征序列,根据队列的入队规则可分为时间特征队列(Time based queue)以及空间特征队列(Spatial based queue)。
时序特征队列:每过27ms将一个特征加入队列。时序特征队列可以稳定感知结果的输出,比如运动过程中发生的目标遮挡,模型可以找到目标被遮挡前的特征来预测感知结果。
空间特征队列:每前进1m将一个特征加入队列。用于等红绿灯一类需要长时间静止等待的状态,在该状态下一段时间之前的在时序特征队列中的特征会出队而丢失。
因此需要用空间特征队列来记住一段距离之前路面的箭头或是路边的标牌等交通标志信息。
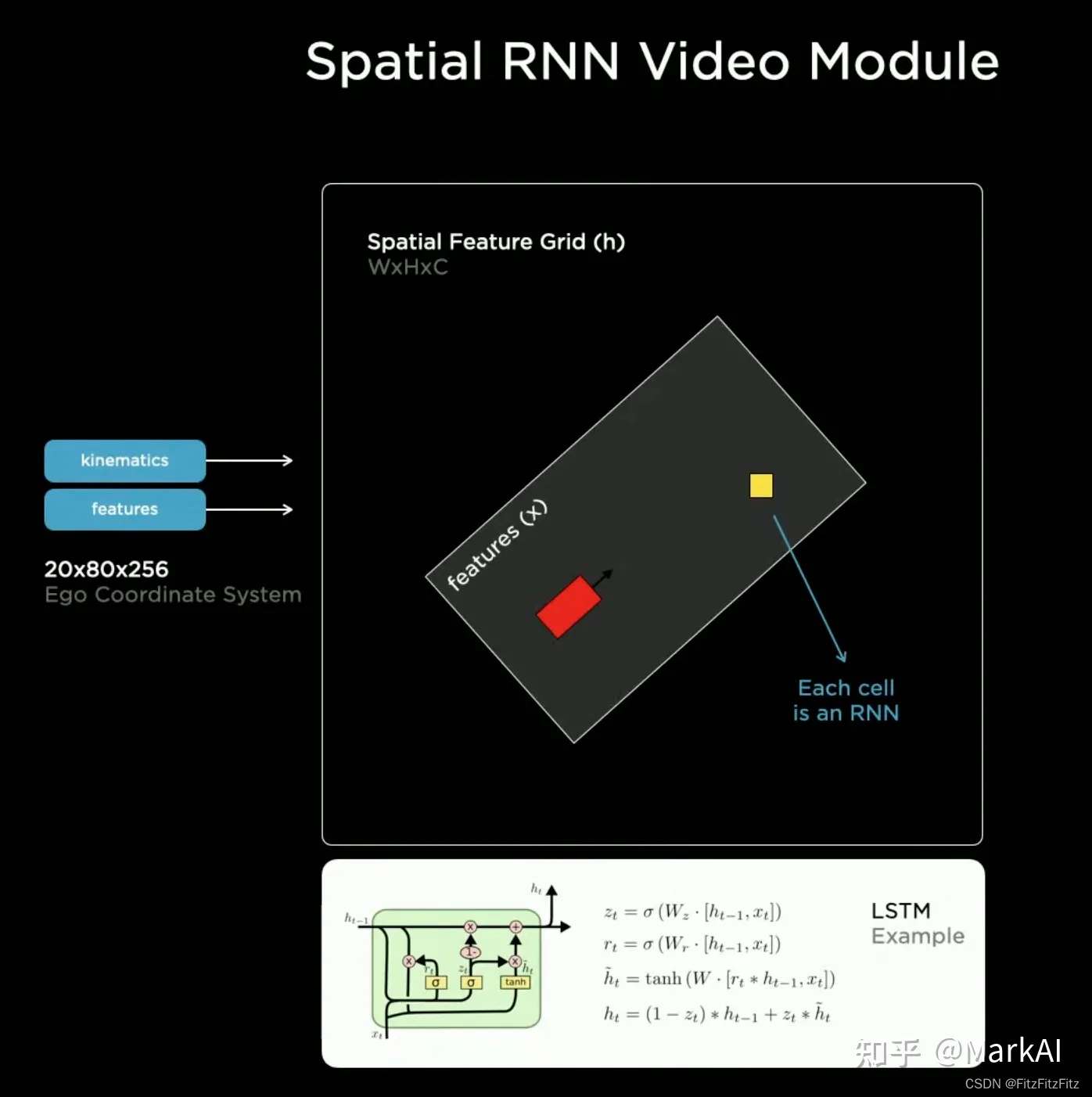
前面提到的特征队列只是用来组织时序信息,接下来介绍的视频模块要用来整合这些时序信息。Tesla团队选择了使用RNN结构来作为视频模块,并命名为空间RNN模块(Spatial RNN Module)。
因为车辆在二维平面上前进,所以可以将隐状态组织成一个2D的网格。当车辆前进的时候,只更新网格上车辆附近可见的部分,同时使用车辆的运动学状态以及隐特征(hidden features) 更新车辆位置。
在这里,Tesla相当于是使用一个2D的feature map来作为局部的地图,在车辆前进过程中,不断根据运动学状态以及感知结果更新这个地图,避免因为视角和遮挡带来的不可见问题。同时在此基础上,可以添加一个Head用来预测车道线,交通标志等,以构建高精地图。
通过可视化该RNN的feature,可以更加明确该RNN具体做了什么:不同channel分别关注了道路边界线,车道中心线,车道线,路面等等。
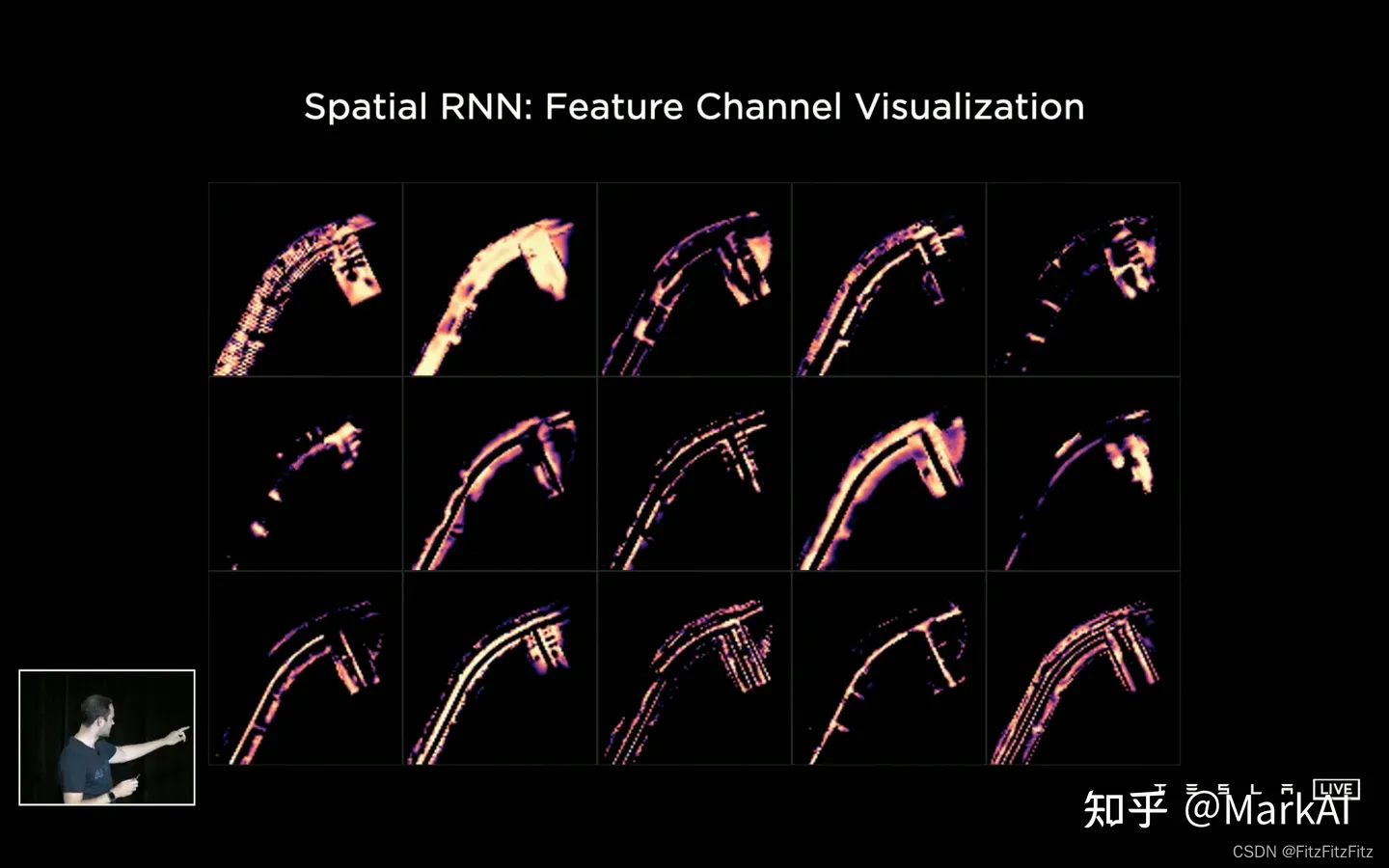
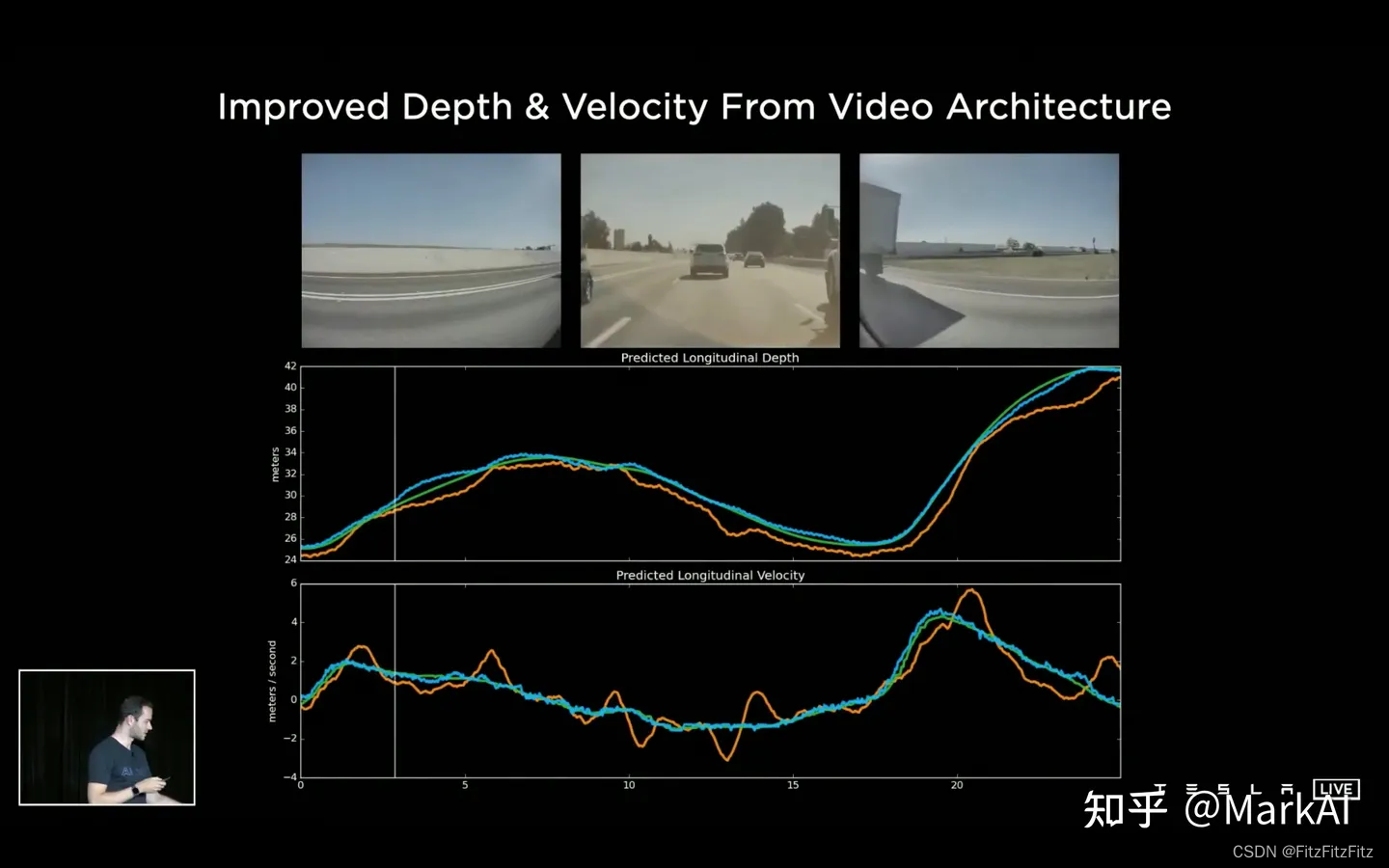
添加了视频模块之后,能够提升感知系统对于时序遮挡的鲁棒性,对于距离和目标移动速度估计的准确性。
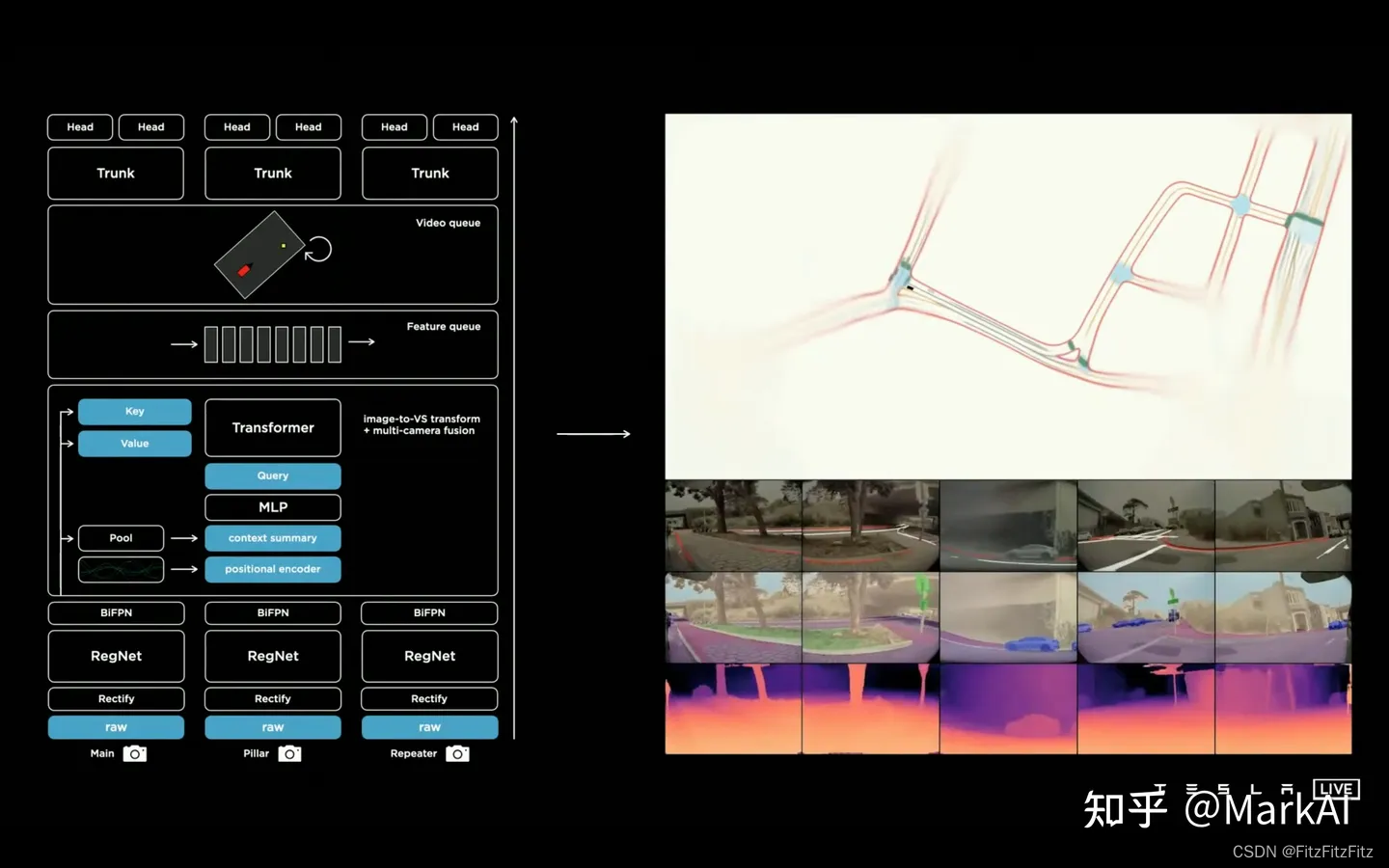
最终的模型
在初版HydraNet的基础上,使用Transformer整合了多个相机的特征,使用Feature Queue维护一个时序特征队列和空间特征队列,并且使用Video Module对特征队列的信息进行整合,最终接上HydraNet各个视觉任务的Head输出各个感知任务。
整个感知系统使用一个模型进行整合,融合了多个相机时序上和空间上的信息,最终直接输出所有需要的感知结果,一气呵成,非常干净和优雅,可以当做教科书一般。
赞叹该系统的精妙之外,也可以看到Tesla团队强大的工程能力,背后强大的算力和数据标注系统是支持这一切的前提,当然,那啥,本质上还是有钱啦……
此外,该系统也并不是最终版的自动驾驶感知系统,还会一直不断迭代升级,国内的同行们要加油了!!
最后,我想说的是……虽然不敢打包票Tesla到底有没有被Hydra资助or控制←_←但他们作为一家科技公司可以那么详细的无私分享自己的技术细节,确实让人敬佩!Respect and Thank you!


![[office] excel怎么设置图表格式- excel中chart tools的使用方法 #笔记#经验分享#其他](https://img-blog.csdnimg.cn/img_convert/0a0ed6e2c67e20c20fb07206c234cae5.jpeg)