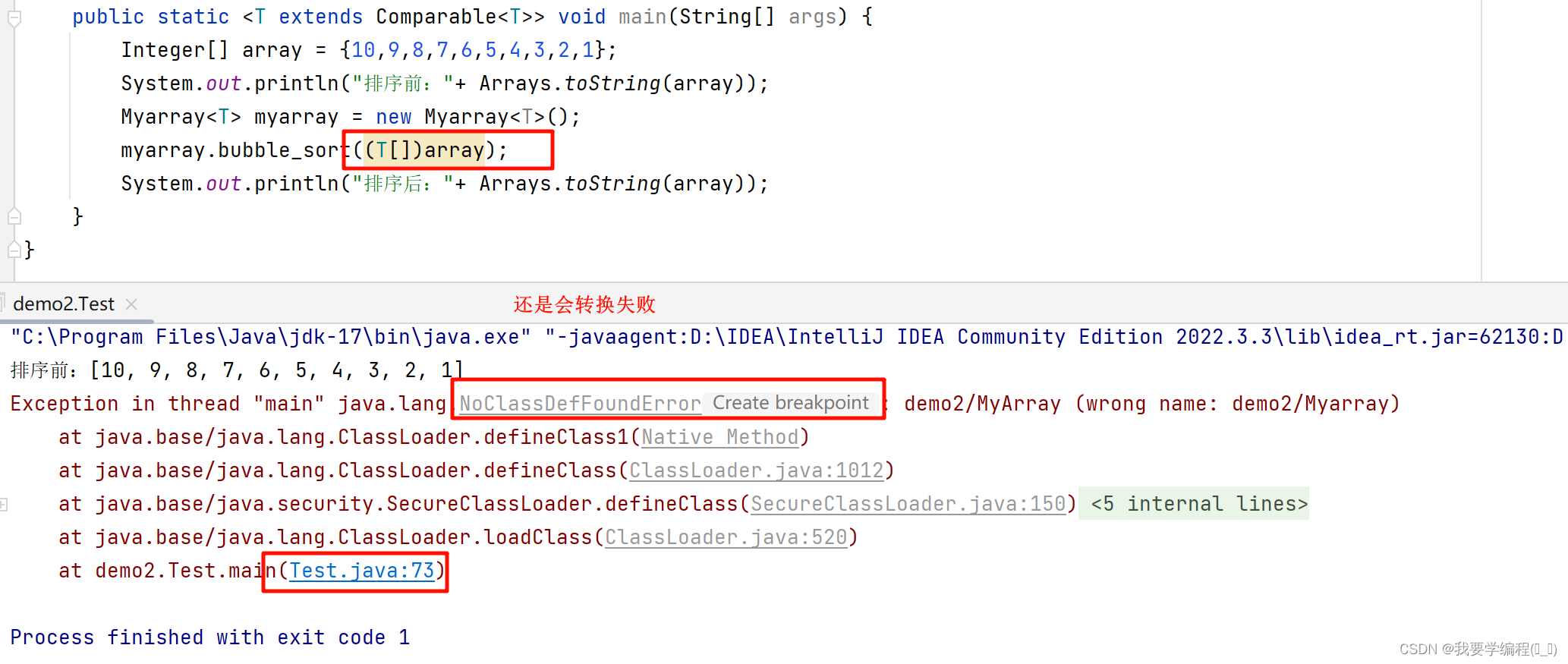
本次分享论文:BIOCODER: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge
基本信息
-
原文作者:Xiangru Tang, Bill Qian, Rick Gao, Jiakang Chen, Xinyun Chen, Mark Gerstein
-
作者单位:耶鲁大学, Google DeepMind
-
关键词:Code Generation, Benchmark, Bioinformatics, Large Language Models
-
原文链接:https://biocoder-benchmark.github.io/
-
开源代码:https://github.com/gersteinlab/biocoder
论文要点
论文简介:BIOCODER 是一项专为生物信息学领域设计的代码生成基准测试,其目的是评估大语言模型(LLM)在此领域的表现。这项基准测试涵盖了多种生物信息学编程问题,特别强调功能依赖和全局变量管理等实际应用需求。通过集成多种评估工具和广泛的数据集,BIOCODER 旨在提升 LLM 在生物信息学代码生成方面的专业性和准确性。
研究目的:BIOCODER的研究目的是创建一个专业基准测试,旨在评估和提升大语言模型在生物信息学代码生成方面的能力。这项基准测试专注于提供真实世界的编程挑战,例如管理复杂的生物数据格式和实施高级数据处理工作流。BIOCODER旨在弥补现有基准在领域特定性方面的不足,推动语言模型更好地适应生物信息学的专业需求,从而提高其在实际应用中的准确性和效率。
研究贡献:
-
创建了一个高质量的、针对代码生成的新数据集,从1720个生物信息学存储库中提取。
-
提供了一个可扩展的解析工具,能够从大型项目中提取所有相关信息。
-
提供了一个代码生成LLM的库,为训练和推理提供了无缝的接口。
-
开发了一个可扩展的模糊测试工具,能够处理大型数据集,提供了可靠的基准结果。
引言
本文详细阐述了生物信息学领域中复杂的数据处理需求和专业知识的深度,并强调了现有大语言模型(LLM)在代码生成方面的成就及其局限性。尽管LLM在多个领域表现出色,对于需要深入领域知识的生物信息学编程任务,它们往往未能提供满意的解决方案。
为此,BIOCODER基准测试被开发出来,通过具体的领域特定编程挑战来评估和提升这些模型的性能,从而更好地解决生物信息学中的实际问题。这项研究的引入标志着向更精确和实用的生物信息学代码生成迈出了关键一步。

研究背景
研究背景部分探讨了大语言模型(LLM)在代码生成领域的应用现状以及它们所面临的挑战。虽然这些模型在一般编程任务中表现优秀,但在生物信息学这一专业领域,它们常常难以准确处理复杂数据格式和专业数据操作。
此外,现有的代码生成基准测试主要关注通用编程技能,而缺少对生物信息学等特定领域的深入评估。因此,BIOCODER的引入旨在提供一个专业的基准测试,以全面评估和优化LLM在生物信息学应用中的性能。这一背景明确了BIOCODER项目的研究重点与目标:提升模型在生物信息学特定任务中的应用能力和精确度。
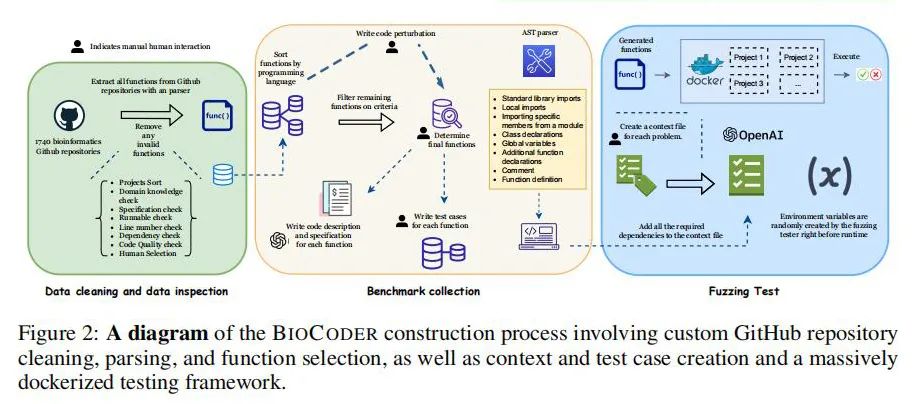
BIOCODER 基准测试
BIOCODER基准测试专门为生物信息学代码生成而设计,包括了多种复杂任务,从基因序列分析到蛋白质结构预测。该基准测试包含1026个Python函数和1243个Java方法,均从公开的GitHub仓库中精选,以确保覆盖生物信息学计算的全谱。
此外,BIOCODER还整合了Rosalind项目的253个问题,从而进一步丰富了测试的深度和广度。通过使用模糊测试框架评估大语言模型,BIOCODER旨在精确地测量模型在实际应用中的性能,并推动其在生物信息学领域的应用和发展。
研究结果
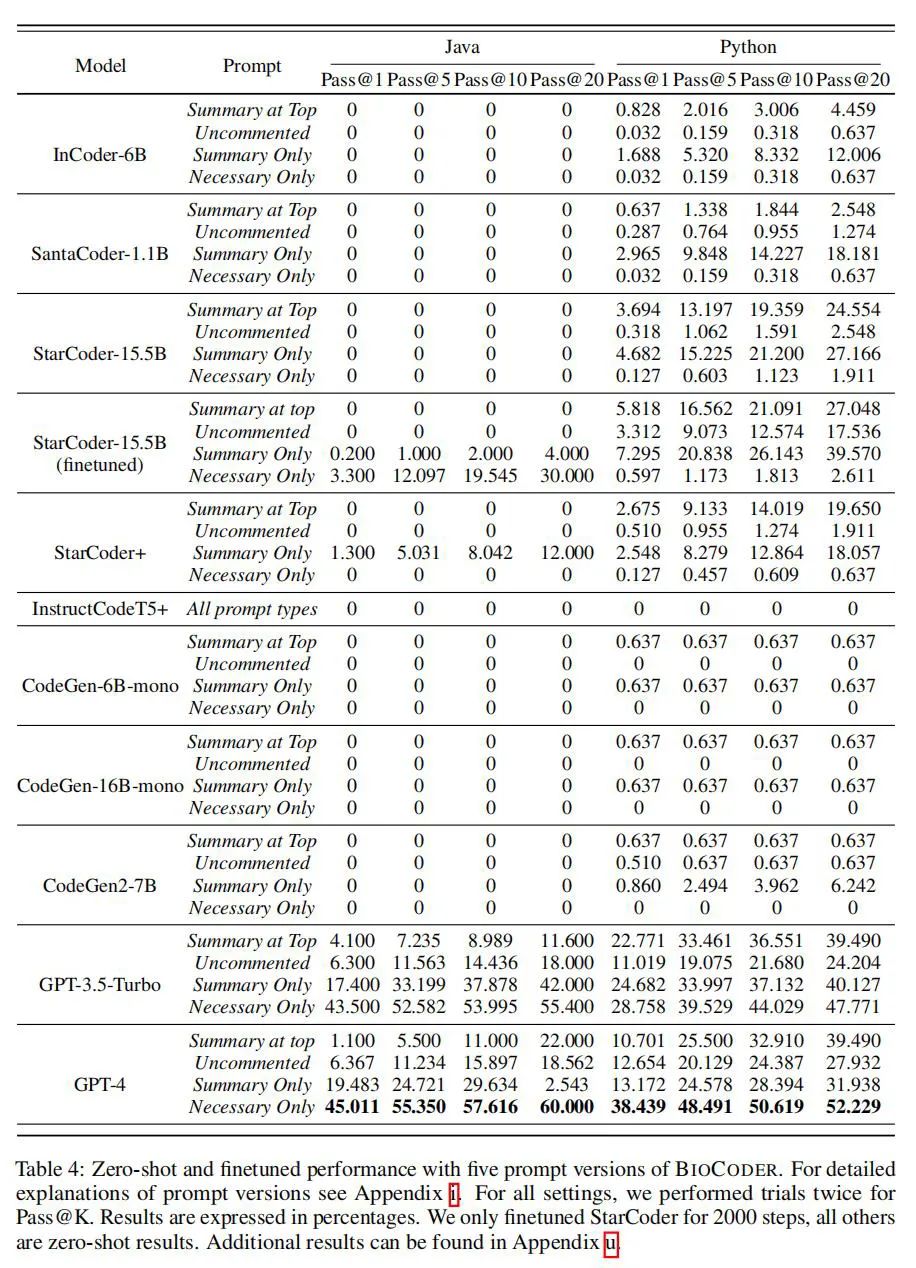
BIOCODER基准测试的研究成果显示,其专门设计的评估体系显著提升了大语言模型在生物信息学代码生成方面的性能。特别是经过微调的StarCoder模型,在处理生物信息学特定问题时实现了超过15%的性能提升。相较于其他领域的通用模型,GPT-3.5和GPT-4在BIOCODER测试中的表现尤为突出,准确率高达50%,这突显了在模型训练中融入领域特定知识的重要性。这些成果不仅证实了BIOCODER的有效性,还为未来生物信息学代码生成模型的开发提供了宝贵的指导。
分析讨论
在分析讨论部分,BIOCODER基准测试的结果展示了大语言模型在生物信息学代码生成任务中的潜力及面临的挑战。研究显示,成功的模型需处理复杂编程环境和广泛的代码依赖。特别是域知识丰富的模型,如GPT-3.5和GPT-4,其性能显著超过其他模型。此外,分析强调了训练数据的量和质对任务成功的重要性;针对特定领域需求微调模型能显著提升性能,这一点在BIOCODER的评估中得到了验证。
论文结论
论文结论部分强调了BIOCODER基准测试在生物信息学代码生成领域的重要性和创新性。研究显示,结合领域专业知识的大语言模型能够显著提高在特定任务上的性能,这证明了为模型引入生物信息学特定内容的重要性。
此外,BIOCODER也揭示了现有模型在处理复杂、依赖密集的生物信息学编程任务时的局限,为未来的研究方向提供了明确的指引。结论中提出,未来的工作将探索更广泛的生物信息学应用,进一步推动大语言模型在该领域的研究和开发。
原作者:论文解读智能体
校对:小椰风