这篇论文研究了在3D医学图像分割领近年引入了许多新的架构和方法,但大多数方法并没有超过2018年的原始nnU-Net基准。作者指出,许多关于新方法的优越性的声称在进行严格验证后并不成立,这揭示了当前在方法验证上存在的不严谨性。
揭示验证短板:深入探讨了当前医学图像分割研究中存在的验证不足问题,特别是在新方法与旧基准的比较中缺乏严格的科学验证和不公平的比较基准。
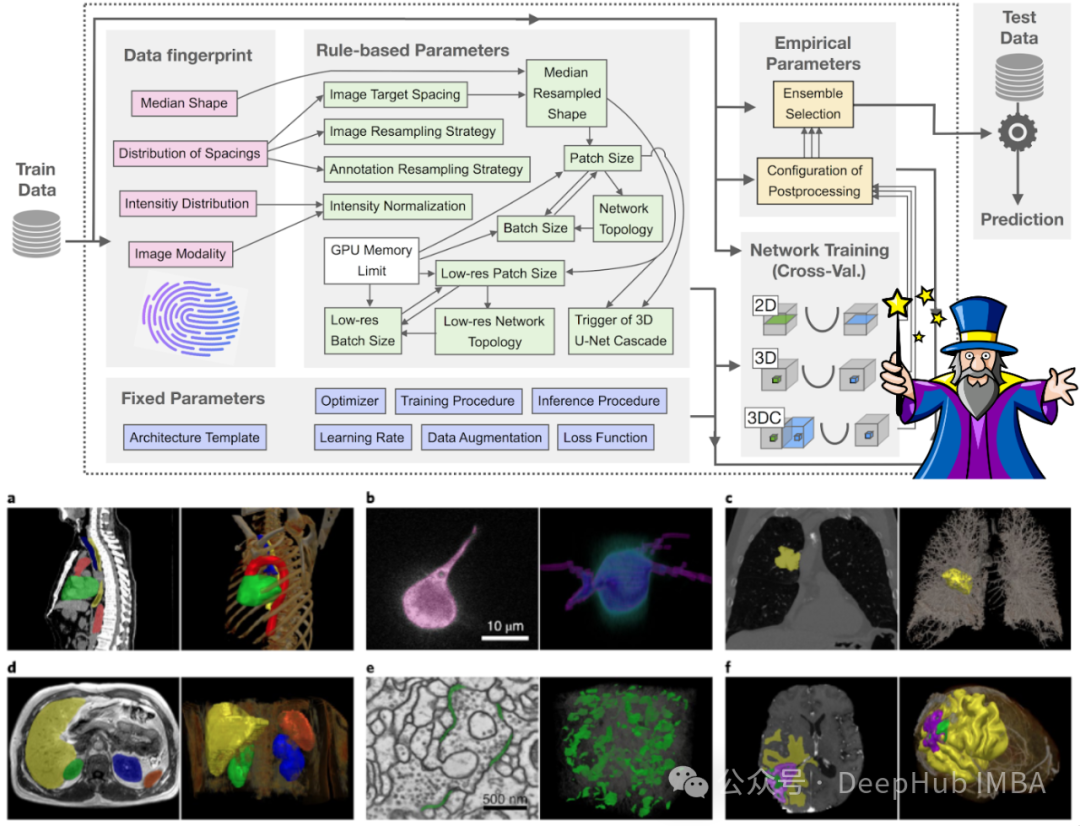
系统性的基准测试:通过广泛的实验,作者系统地评估了现有的多种分割方法(包括基于CNN、基于Transformer和Mamba的方法),强调了合适的配置和现代硬件资源的重要性,以及在严格控制条件下的性能比较。
更新标准化基线:发布了一系列基于nnU-Net框架的更新标准化基线,这些基线适配了不同的硬件配置,以便更公平、更一致地评估不同方法的性能。
强调科学验证的重要性:论文提倡在未来的研究中应更加重视科学严谨的验证流程,以确保方法的改进是实质性的而非表象上的提升。
论文最终呼吁整个领域需要文化上的转变,即在评估新方法时应将验证的质量视为与网络架构的创新同等重要,以推动真正的科学进步。
验证短板
论文中对当前医学图像分割研究中存在的验证不足问题进行了详细的描述,特别指出了新方法与旧基准之间比较时常见的几个问题。这些问题包括:
- 基线设置不当:在比较新方法与现有方法时,经常使用设置不当或优化不足的基线。这种情况下,新方法可能看起来性能较好,但这种比较是在不公平的条件下进行的,因为基线方法没有得到同等水平的优化或配置。
- 数据集的使用不适当:论文指出,在很多研究中,所使用的数据集数量不足或不具代表性,这限制了方法性能的普适性和可信度。此外,有些研究可能过度依赖某些特定数据集的特征,而这些特征不一定能代表更广泛的应用场景。
- 计算资源的忽略:新方法往往在资源消耗更大的条件下运行,例如使用更高的VRAM或更长的训练时间,而这些条件并未在与旧基准的比较中透明化。这导致比较结果可能偏向于资源消耗更大的新方法,而非真实反映算法的效率和效果。
- 性能提升的误导性归因:有时候性能提升被错误地归因于新引入的架构或技术,而实际上这些提升可能来源于如额外的训练数据、预训练模型或更复杂的数据增强技术等其他因素。
论文呼吁采用更严格的验证标准和方法。所以提出需要系统地识别和避免这些验证误区,提供了一系列的建议和措施,如确保进行公平的基线比较、使用足够多和具有挑战性的数据集、以及透明化计算资源的使用。通过这种方式,研究社区能更准确地评估新方法的真实效能和实用价值,推动医学图像分割领域的科学进展。
系统性的基准测试
论文中详细讨论了各种3D医学图像分割方法的性能,主要通过Dice Similarity Coefficient (DSC)分数来量化各方法的准确性。
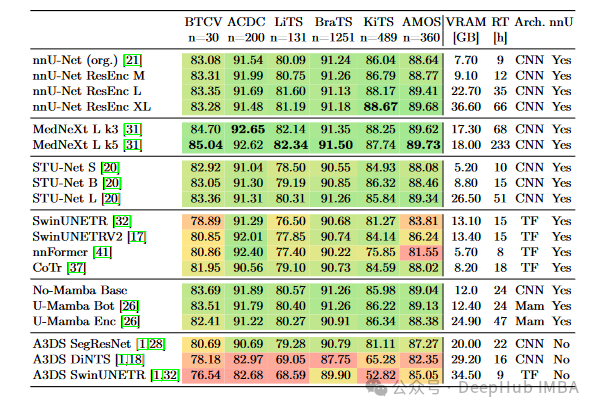
以下是一些关键的性能提升数据及其与以前研究的比较:
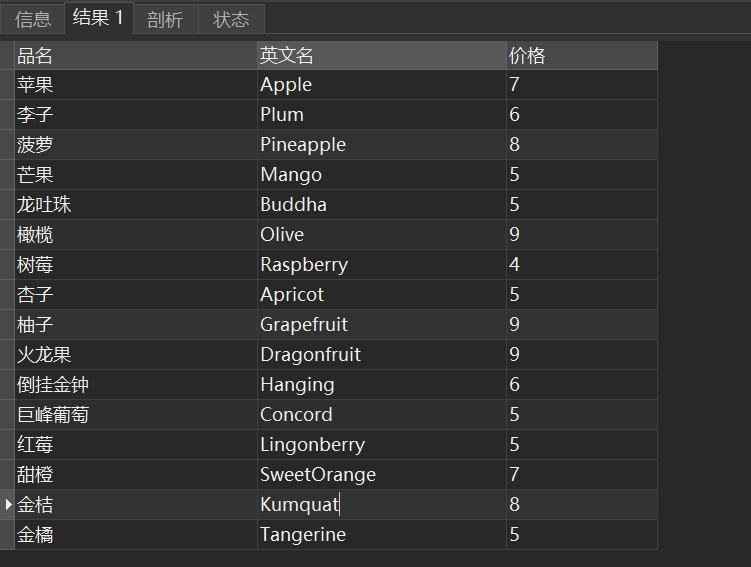
- nnU-Net 及其变体的性能:- 原始 nnU-Net 在不同数据集上的DSC分数:BTCV (83.08%), ACDC (91.54%), LiTS (80.09%), BraTS (91.24%), KiTS (86.04%), AMOS (88.64%).- nnU-Net ResEnc M/L/XL 在不同数据集上的DSC分数逐步提升,如在KiTS数据集上,nnU-Net ResEnc XL 达到了 88.67% 的 DSC 分数。
- MedNeXt 的表现:- MedNeXt L k3 在不同数据集上的最高DSC分数:BTCV (84.70%), ACDC (92.65%), LiTS (82.14%), BraTS (91.35%), KiTS (88.25%), AMOS (89.62%).- 这表明 MedNeXt 在大多数数据集上的性能优于原始 nnU-Net 和其他变体。
- Transformer 和 Mamba 基方法的比较:- Transformer方法如SwinUNETR和nnFormer在多个数据集上的表现通常低于CNN基方法,如SwinUNETR在ACDC数据集上的DSC为91.29%,而nnU-Net为91.54%。
- 效率和VRAM使用:- 不同模型的VRAM使用和训练时间也被报告,如nnU-Net ResEnc XL使用36.60GB VRAM且训练时间达66小时,显示出在处理大型数据集时,模型缩放和硬件资源的充分利用对性能有显著影响。
这些性能数据的提出是基于与以前方法的直接比较。比如,通过将nnU-Net的各种配置与新的Transformer和Mamba方法进行比较,显示了尽管后者在理论上可能具有优势,但在实际医学图像分割任务中,经典的CNN方法(特别是经过精心配置和适配现代硬件的方法)仍然显示出更高的效率和准确率。此外,通过更新和标准化的基线测试,本文能够提供一种更为严谨和可比较的方法性能评估,这对于未来的研究方向具有指导意义。
新标准化基线模型
论文中提到的nnU-Net及其不同变体(如ResEnc M/L/XL)是基于U-Net架构的优化版本,具体设计考虑了不同的硬件能力和数据集特性。这些变体在nnU-Net的框架内进行了特定的调整以适应更广泛的应用场景。
- nnU-Net (原始):- 架构:基于经典的U-Net架构,使用标准的卷积层、池化层和上采样层。- 自适应配置:nnU-Net的一个重要特点是其自动化的配置过程,能够根据具体的数据集自动调整网络的参数和训练策略。
- nnU-Net ResEnc M/L/XL:- M(Medium):设计用于中等规模的VRAM和处理能力。- L(Large):针对较大的VRAM和更高的计算需求进行优化。- XL(Extra Large):为最大的VRAM和计算能力配置,适合处理非常大的数据集和复杂的模型训练任务。- 架构:这些变体在原始nnU-Net的基础上引入了残差连接(Residual connections)。残差连接帮助改善了网络在深层中的信息流,有助于解决梯度消失的问题,特别是在更深的网络结构中。- 尺寸变体:- 自适应批次和补丁尺寸:不同的变体通过调整批次大小和补丁尺寸来适应不同的VRAM预算。
- 训练参数和优化:- 学习率:学习率的配置也是自动化的,根据网络的训练反馈进行调整。- 数据增强:nnU-Net使用广泛的数据增强技术来提高模型的泛化能力,包括旋转、缩放、弹性形变等。
这些基线的设计显示了nnU-Net在自动化、标准化和适应不同硬件能力方面的优势,使其在多个数据集上都能达到或超越其他先进方法的性能。此外,论文还提供了关于这些基线的实施细节和训练策略,这有助于研究社区更容易地复现和利用这些模型进行进一步的研究和应用。
这个论文最有意思的地方就是这部分没有说明白,没有详细说明nnU-Net ResEnc M/L/XL各变体的具体参数细节,把结果引向了Github,具体的参数配置需要我们自己看源代码。

所以在最后我们来介绍如何使用nnUNet
nnUNet代码示例
上面论文也说到了,nnUNetv2包含了标准化的基线模型,也就是说我们可以运行命令行的方式以进行训练、评估和推理,所以我们首先安装
pip install nnunetv2
作为一个集成框架,我们需要使用nnUNet的自定义推理管道,我们呢再安装官方的包
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
然后就可以配置数据集了,这里需要三个变量
- nnUNet_raw:放置数据的地方。它应该是遵循nnUNet数据集命名约定的数据。我们将在下一节中对此进行更详细的解释。
- nnUNet_preprocessed:这是一个将保存预处理数据的文件夹。运行预处理命令(我们将在下面介绍)时,nnUNet将使用这个文件夹来保存预处理的数据。
- nnUNet_results:这是nnUNet将保存训练工件的文件夹,包括模型权重、配置JSON文件和调试输出。
可以通过多种方式设置这些环境变量。但是最简单的选择是在要运行nnUNet命令的终端中直接设置它们。例如,对于Linux机器上的环境变量nnUNet_raw,你可以这样做:
export nnUNet_raw="/path/to/your/deephub_nnUNet_raw" # Linux
set nnUNet_raw=C:\path\to\your\deephub_nnUNet_raw # Windows
因为是标准化的处理,所以框架要求数据集具有非常特定的格式,如果你在使用Medical Segmentation Decathlon (MSD) 的数据,那么可以直接运行 nnUNetv2_convert_MSD_dataset 来进行转换
#显示帮助信息
nnUNetv2_convert_MSD_dataset -h
如果正在使用MSD以外的任何数据集,则需要以nnUNet格式组织和命名数据集。
nnUNet格式要求如下
Dataset[IDENTIFIER]_[Name]
IDENTIFIER
是一个数字标识,并且应该有3位数字,这个数字代表着我们数据集的ID,也就是说一个数据集一个ID
Name
是数据集的名称。例如用于分割主动脉的数据集,我的文件夹名称可以是
Dataset300_Aorta
。
在这个主文件夹中,需要创建一个名为imagesTr的训练图像文件夹和一个名为labelsTr的包含训练标签(分割)的文件夹。另外还可以添加一个包含测试图像的测试文件夹,它应该被称为imagesTs。不需要为测试映像添加标签。
图片的命名格式如下:
{CASE_IDENTIFIER}_{XXXX}.{FILE_ENDING}
CASE_IDENTIFIER数据集的唯一名称,它应该是唯一标识符号。例如训练图像(CT扫描)被命名为aorta_000_000 .nrrd。
对于分割结果也就是labelsTr的文件格式如下:
{CASE_IDENTIFER}.{FILE_ENDING}
主动脉数据集中的一个例子是AORTA_000.nrrd。
最后就是dataset.json的json文件。这个文件包含关于数据集的元信息。
{
"channel_names": {
"0": "CT"
},
"labels": {
"background": 0,
"AORTA": 1
},
"numTraining": 51,
"file_ending": ".nrrd",
"overwrite_image_reader_writer": "SimpleITKIO"
}
在这个文件中,指定了channel_names,这个例子中就是CT。还指定了标签,还有numTraining,这是训练图像(扫描)的数量,还有file_ending是扩展名。
最后一个overwrite_image_reader_writer是可选的。因为要读取nrrd文件,所以我将其设置为SimpleITKIO。也可以不设置,那么nnUNet将根据文件扩展名匹配加载工具。
最后完成的数据集文件夹如下:

开始训练
训练nnUNet模型是一个多步骤的过程,从预处理数据集开始,这一步是通过nnUNetv2_plan_and_preprocess命令完成的。该命令将预处理放在nnUNet_raw文件夹路径中的数据,并将预处理后的数据保存到nnUNet_preprocessed文件夹路径中。
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity -np 1
这里的DATASET_ID将是数据集标识符,也就是300。
-np是运行预处理的进程或工作进程的数量。这个CPU的核数相关,但是太大可能会占用很多内存,这也是需要考虑的问题
然后就是训练了
nnUNetv2_train 300 3d_fullres all -tr nnUNetTrainer_250epochs
300为数据集ID。
3d_fullres是我们选择的nnUNet配置。还有其他3个:2d, 3d_lowres, 3d_cascade_fullres。因为是3D图像所以我们选这个。
All指的是我们想要使用整个训练文件夹来进行训练,而不是进行交叉验证。
-tr nnUNetTrainer_250epochs 是一个特定的训练器配置,我们运行250个epoch的训练。这个配置是写死再python代码中的
#nnunetv2/training/nnUNetTrainer/variants/training_length/nnUNetTrainer_Xepochs.py
classnnUNetTrainer_250epochs(nnUNetTrainer):
def__init__(self, plans: dict, configuration: str, fold: int, dataset_json: dict, unpack_dataset: bool=True,
device: torch.device=torch.device('cuda')):
super().__init__(plans, configuration, fold, dataset_json, unpack_dataset, device)
self.num_epochs=250
推理和评估
nnUNetv2_train训练完成后就可以进行推理了。使用nnUNetv2_predict命令,可以轻松地将训练好的模型应用到新的数据集并生成预测。
nnUNetv2_predict -i nnUNet_dirs/nnUNet_raw/Dataset300_Aorta/imagesTs -o nnUNet_dirs/nnUNet_raw/nnUNet_tests/ -d 300 -c 3d_fullres -tr nnUNetTrainer_250epochs -f all
如果需要评估,则使用nnUNetv2_evaluate_folder
nnUNetv2_evaluate_folder /nnUNet_tests/gt/ /nnUNet_tests/predictions/ -djfile Dataset300_Aorta/nnUNetTrainer_250epochs__nnUNetPlans__3d_fullres/dataset.json -pfile Dataset300_Aorta/nnUNetTrainer_250epochs__nnUNetPlans__3d_fullres/plans.json
这个命令的第一个参数是ground truth文件夹。
第二个参数是预测文件夹。
-djfile是数据集的dataset.json文件。
-pfile是计划的plans.json文件,该文件在预处理步骤中创建。
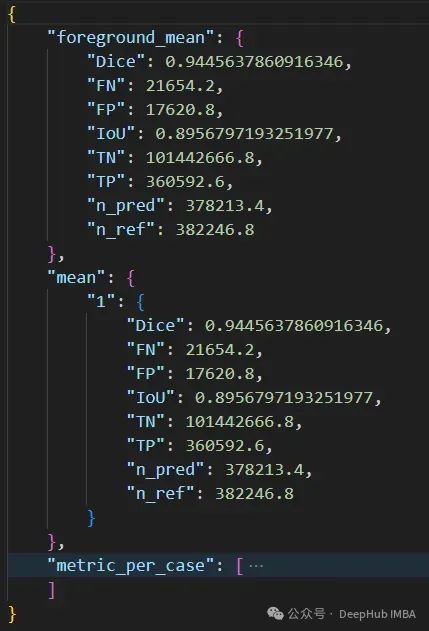
当你运行评估命令时,会得到这样的结果:
下面是在主动脉数据集上训练nnUNet的输出样本:
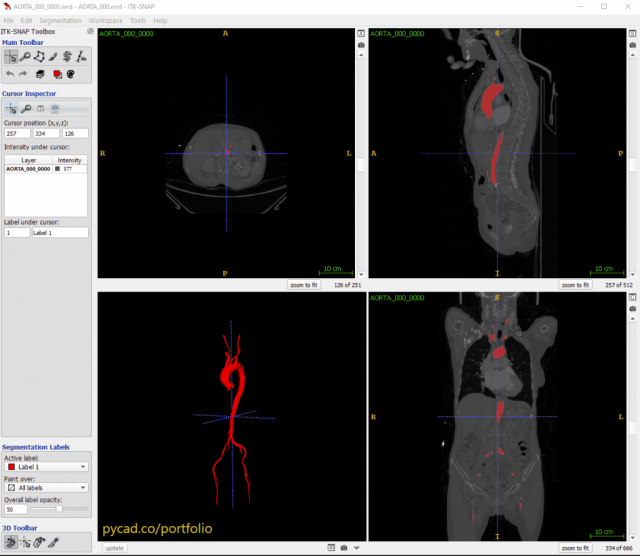
总结
最后不要忘了我们介绍的这篇论文:《nnU-Net Revisited: A Call for Rigorous Validation in 3D Medical Image Segmentation》重新审视了3D医学图像分割领域,特别是关注在新方法与旧基准的比较中存在的验证不足问题。作者通过批判性地评估现有研究中的常见短板,揭示了许多新颖方法性能超越传统方法的声称在严格验证后难以站得住脚。论文不仅挑战了当前研究的一些普遍实践,也为未来的研究方向提供了明确的指导,旨在推动3D医学图像分割领域向更加严谨和有效的方向发展。
论文地址:
https://avoid.overfit.cn/post/fc43928c41574818a0d61958f572e9cb