前言
随着软件测试行业的快速发展,去测试化、全员测开化的趋势,技术测试已成为确保软件质量不可或缺的一环。
但对于许多没有代码基础或缺乏系统性自动化知识的测试人员来说,如何入手并实现高质量的自动化测试成为了一个挑战。
为此,我编写了这款自动化测试框架脚手架,给大家提供思路和引导。
它基于Python语言,结合强大的pytest测试框架进行二次开发并融合request、allure、log、openpyxl、pandas、mysql、oracle以及邮件通知等技术;
旨在为测试人员提供简单、高效、易用且灵活的自动化测试解决方案,轻松应对各种复杂的测试场景。
源码暂不开源,作为我的第一篇知识付费,付费后获取下载链接,可免费讲解。
下载地址:点击 > 微信公众号: 测试开发的烦恼
技术选型
- 编程语言:Python 3.8.5
- 测试框架:Pytest 8.2.0
- 测试报告:Allure 2.13.5
- 网络请求:requests 2.25.1
- 响应断言:jsonpath 0.82.2 | jsonpath-ng 1.6.1
- 数据文件读取:Openpyxl 3.1.2 | pandas 2.2.2
- 数据库操作:PyMysql 1.1.0 | cx_Oracle 8.3.0
- …
- pytest:python的一个单元测试框架 https://docs.pytest.org/en/latest/
- pytest-xdist:pytest的一个插件,可多进程同时执行测试用例 https://github.com/pytest-dev/pytest-xdist
- allure-pytest:用于生成测试报告 http://allure.qatools.ru/
- requests:用于HTTP请求 http://docs.python-requests.org/en/master/
- cx_Oracle:用于操作Oracle数据库 https://cx-oracle.readthedocs.io/en/latest/index.html
- PyMySQL:用于操作MySQL数据库 https://github.com/PyMySQL/PyMySQL
框架实现功能
- 参数化与数据驱动:本框架通过数据驱动的方式,实现了测试业务和测试数据的完全隔离。这不仅降低了测试人员的工作量,还提高了测试数据的可维护性和复用性。
- 自动生成测试代码:测试人员无需编写繁琐的测试代码,测试人员只需在Excel文件中按照模板填写测试数据,框架便能自动生成对应的测试用例函数代码。这不仅降低了测试人员的技术门槛,还提高了测试效率。
- 串联接口数据依赖:在复杂的业务场景中,接口之间往往存在数据依赖关系。本框架支持这种依赖关系,例如C接口可以依赖B接口响应内容中的部分数据,而B接口又可以依赖于A接口的返回结果。这种依赖关系的支持,使得框架能够更好地模拟真实业务场景,提高测试的覆盖率。
- 动态替换测试数据:本框架支持在请求头、请求报文以及前后置SQL语句中进行动态数据替换,使得测试数据更加真实、灵活。这一特性有助于模拟实际场景中的各种情况,提高测试的准确性和可靠性。
- 支持多种场景断言:可以同时验证响应结果、数据库、第三方接口等多个方面的数据。这种动态多断言机制能够全面覆盖各种测试场景,确保接口的稳定性和可靠性。
- 统计接口运行耗时:作为扩展功能,本框架提供了接口运行耗时的统计功能。测试人员可以根据需要开启或关闭该功能,以便更好地分析接口性能瓶颈和优化方向。
- 环境清理与断言:在测试执行前后,框架能够自动执行SQL语句进行环境清理或断言,确保测试环境的纯净性和测试结果的准确性。这有助于减少测试之间的相互影响,提高测试的可重复性。
- 日志记录与报告生成:本框架提供了详细的日志记录功能,能够记录测试过程中的关键信息和错误信息,方便测试人员进行问题追踪和定位。同时,结合allure插件,框架能够自动生成美观易读的测试报告,展示测试结果、统计数据和失败原因等信息,为团队成员提供全面的测试反馈。
- 公共变量与二次处理:本框架支持将SQL语句查询结果以及响应内容存储到公共变量池中,方便测试人员在测试过程中共享和使用数据。同时,框架还提供了丰富的二次处理功能,如字符串截取、替换、计数、仅保留数字、执行正则表达式以及JSONPath表达式等,满足测试人员对数据处理的多样化需求。
- 多线程执行测试用例:为了提高测试效率,框架支持多进程执行测试用例,可根据计算机的核心数量自动适应。
- 即时邮件通知功能:测试执行完成后,本框架支持发送邮件通知。测试人员可以自定义邮件内容,包括测试结果、失败用例详情等信息。这种邮件通知机制使得测试结果传递更加高效,方便相关人员及时了解测试情况并作出响应。
Excel 字段说明
- 用例序号:为每一个测试用例分配唯一的序号,便于标识和管理。
- 用例信息:详细记录每个测试用例的关键信息,包括名称、描述、所属模块、功能、接口名称以及生成路径等,确保测试的全面性和可追溯性。
- 执行开关:灵活控制测试用例的执行状态,通过设置执行开关(如“Y”代表执行,其他代表不执行),实现对测试范围的精确控制。
- 关联序号:利用用例序号构建复杂的接口链路测试场景,模拟真实业务环境中的接口交互过程。
- 请求头部:支持配置接口请求时的头部数据,包括参数化动态替换,确保请求符合接口规范。
- 请求地址:指定接口请求发送的目标服务器地址。
- 请求方式:支持多种请求方式,如GET、POST、DELETE、PUT等,适应不同接口的需求。
- 请求参数类型:根据接口类型和内容,灵活选择params查询字符串、data表单或json对象等参数类型
- 请求参数内容:与“请求参数类型”相匹配的请求参数内容。
- 响应断言:提供丰富的响应验证机制,包括响应代码、响应信息、响应耗时以及通过JSONPath表达式进行验证,确保接口返回的数据符合预期。
- 前置SQL处理:在接口请求发送前执行SQL语句,用于清理测试环境、准备测试数据或查询数据用于报文参数化。
- 后置SQL处理:在接口请求发送后执行SQL语句,用于清理测试环境、验证数据状态或查询数据用于后续测试。
- 公共变量处理:提供公共变量管理机制,支持对场景测试中产生的变量进行修改或另辟,包括字符串截取、字符串替换、字符串计数、正则表达式执行、JSONPath提取等功能,增强测试数据的灵活性和可维护性。
用例信息详解
在“用例信息”列中,需要填写一个符合特定格式的JSON字符串。
这个JSON字符串必须包含以下七个关键字段:“用例名称”、“用例描述”、“模块名称”、“功能名称”、“接口名称”、“存放路径”以及“所属标记”。
其中,“模块名称”、“功能名称”、“接口名称”、“用例名称”和“所属标记”这几个字段的用于丰富Allure报告的内容。
要求这些数据填写在Excel中,实际上是为了动态地配置Allure报告中的标题、描述等关键信息。
通过这种方式,我们可以确保生成的测试报告内容充实、结构清晰,便于团队成员理解和分析测试结果。
此外,“接口名称”和“存放路径”这两个字段在测试数据的构建过程中发挥着重要作用。
它们不仅用于标识特定的测试接口,还指定了自动生成测试函数文件的存放位置。
这样,测试框架就能根据这些信息准确地找到所需的测试数据,并将生成的测试函数文件保存在正确的路径下。
要求格式如下所示:
{
"用例名称": "登录-获取用户类型-001",
"用例描述": "登录模块-获取用户类型功能的测试用例描述,传递正确的参数,通过断言",
"模块名称": "登录",
"功能名称": "获取用户类型",
"接口名称": "login",
"存放路径": "LoginDirs",
"所属标记": [
"冒烟测试1",
"冒烟测试2"
]
}
关联序号详解
接口测试通常分为两种:独立接口,关联接口;
独立接口测试:指的是那些不依赖于其他数据源,只需按照接口文档要求正确提供参数即可进行测试的接口;
关联接口测试:则涉及多个接口之间的依赖关系,例如C接口需要依赖B接口响应内容中的部分数据,而B接口又依赖于A接口的返回结果;
在这种场景下:为了测试C接口,必须首先执行A接口,再执行B接口,并将A接口的返回数据传递给B接口,最后将B接口的返回数据传递给C接口;为了更有效地支持“testcase”文件的自动生成、Allure报告中对执行步骤的详细记录,以及关联接口之间变量的共享;
决定放弃使用pytest-dependency和pytest-ordering等插件。
选择自定义一种更适合当前框架的数据结构,并将其传递给特定的case函数中使用;
这样,我们可以更灵活地控制测试用例的执行顺序和依赖关系,同时确保变量在关联接口之间得到正确的共享和传递;读取指定路径的Excel文件,获取指定的sheet名称全部数据(这些数据以列表嵌套字典的形式呈现,确保每个元素都是易于解析和操作的结构化数据);
对提取出的数据进行遍历和处理,目的是识别并分离出独立案例和关联案例。
独立案例收集规则:
- 如果其“执行开关”列值为Y、“关联序号”列值为空,并且“用例序号”没有在“关联序号”列中的任何位置出现;
- 将以“用例信息”列中的“接口名称”(以json格式提供)作为key,整行数据作为value;
关联案例收集规则:- 当一个用例的“执行开关”为’Y’且“关联序号”不为空时,该用例将被视为关联案例的一部分;
- 所有在“关联序号”列中存在的“用例序号”的数据将从独立案例字典中删除,并按顺序添加到子列表中,最后将“关联序号”不为空数据行添加到列表末尾。
- 将以子列表中所有“用例信息”列中的“接口名称”(以json格式提供)拼接成以“-”分隔的字符串作为key,子列表作为value;
最终测试数据结构:
{key1: [[{}, {}, {}]], key2: [[{}, {}, {}]], key3: [[{}, {}, {}]], …}
响应断言详解
代码设计思想
利用JSONPath对响应内容完成断言校验
1.断言响应代码
2.断言响应信息
3.断言响应text中是否包含某值
4.断言响应json中是否包含某jsonpath路径
5.断言响应json中的某jsonpath路径下的值是否符合预期
6.断言响应json中的某jsonpath路径下的值是否满足比较运算
7.断言响应耗时是否小于预期耗时
8.获取响应json中的某jsonpath路径下的值
- JSONPath是一种用于在JSON(JavaScript Object Notation)数据中定位和提取特定元素的查询语言。
- 它类似于XPath对XML的作用,可以帮助我们轻松地按照特定的路径表达式从复杂的JSON结构中获取所需的数据。
- 使用JSONPath,可以指定一个或多个路径表达式,以匹配JSON数据的特定部分。
- 这些路径表达式由一系列操作符、通配符和属性键组成,用于描述所需数据的位置和结构。
- JSONPath还支持过滤器,可以根据条件筛选出满足要求的数据。
- 模拟一个接口响应内容(响应内容按照封装后的格式,详见RequestUtils.py封装文件)
mock_response = {
"response_text": "xxxxxxxxxxxxxx假设这是一个接口的响应text文本内容xxxxxxxxxxxxxx",
"response_json": {
"name": "zhangsan",
"age": 30,
"address": "上海市浦东新区",
"phone": "13800001234",
"cars": [
{"model": "Ford", "mpg": 25.0},
{"model": "BMW", "mpg": 28.0},
{"model": "Fiat", "mpg": 30.0}
]
},
"response_code": 200,
"response_info": "ok",
"response_time": 1,
"response_url": "xxx",
"response_xxx": "..."
}
# 创建断言工具对象
assert_tool = AssertUtils(mock_response)
# 进行断言测试
assert_tool.assert_status_code(200)
assert_tool.assert_status_message('OK')
print(assert_tool.get_jsonpath_value('$.name')) # zhangsan
assert_tool.assert_jsonpath_exists('$.cars[0]')
assert_tool.assert_jsonpath_exists('$.cars[1]')
print(assert_tool.get_jsonpath_value('$.cars[0]')) # {'model': 'Ford', 'mpg': 25.0}
assert_tool.assert_jsonpath_value('$.cars[0]["mpg"]', 25.0)
assert_tool.assert_contains_text("123")
assert_tool.assert_jsonpath_value_compare('$.cars[0]["mpg"]', 25, "等于")
assert_tool.assert_response_time(10.5)
填写格式和断言类型
针对断言功能,做了统一的调用封装,以便在Excel文件中填写符合特定格式的JSON字符串时能够便捷使用。
该封装支持七大类断言操作,分别是“响应代码”验证、“响应信息”校验、“响应耗时”分析、“文本查找”功能、“路径查找”机制、“数据比较”逻辑以及“存储变量”操作。
这些断言操作可以根据实际需求任意搭配使用,一个或多个均可;
针对断言数据的填写进行了汉化处理,旨在提供更加友好、易于理解的用户体验。
其中,“数据比较”功能尤为关键,它支持数值的大小运算以及字符串的相等运算,满足了复杂的数据校验需求。
此外,“存储变量”功能允许将响应内容中的数据保存到公共变量池中,这样在后续的关联案例中,如请求头、请求参数、SQL语句等数据依赖时,可以方便地引用这些变量,提高了测试用例的复用性和维护性。
{
"响应代码": [
{
"预期值": "200"
}
],
"响应信息": [
{
"预期值": "OK"
}
],
"响应耗时": [
{
"预期值": "5"
}
],
"文本查找": [
{
"预期值": "success"
}
],
"路径查找": [
{
"JSONPath": "$.status"
}
],
"数据比较": [
{
"JSONPath": "$.status",
"预期值": "success",
"运算符": "等于"
}
],
"存储变量": [
{
"JSONPath": "$.userinfo.usertype",
"变量名称": "UserType66"
}
]
}
前后置SQL处理详解
代码设计思想
- 利用正则表达式技术,精准匹配并提取出每一条SQL语句中所有以${xxx}形式包裹的占位符。
- 随后,将这些占位符与公共变量池中的数据进行同名绑定,实现占位符的自动替换功能,确保SQL语句的正确执行。
- 为了提高数据库操作的性能,采用了数据库连接池技术。
- 连接池能够高效地管理和复用数据库连接,避免了频繁地创建和关闭连接所带来的性能损耗,从而显著提升了系统的整体响应速度。
- 在执行SQL语句时,将数据库操作分为两大类:查询和其他操作。
- 对于查询操作,将查询结果按照指定的变量名称一一对应地保存到公共变量池中,以便后续操作能够方便地引用这些结果数据。
- 如果未上送变量名称,则默认以数据库字段名作为变量名保存到公共变量池。
- 对于其他操作(增、删、改),默认记录受影响的行数,并将其作为操作结果的一部分进行返回。
- 此外,需要注意的是,如果指定的变量名称或数据库字段存在重复,我们会优先使用最新的数据,即覆盖已有数据,以确保数据的准确性和一致性。
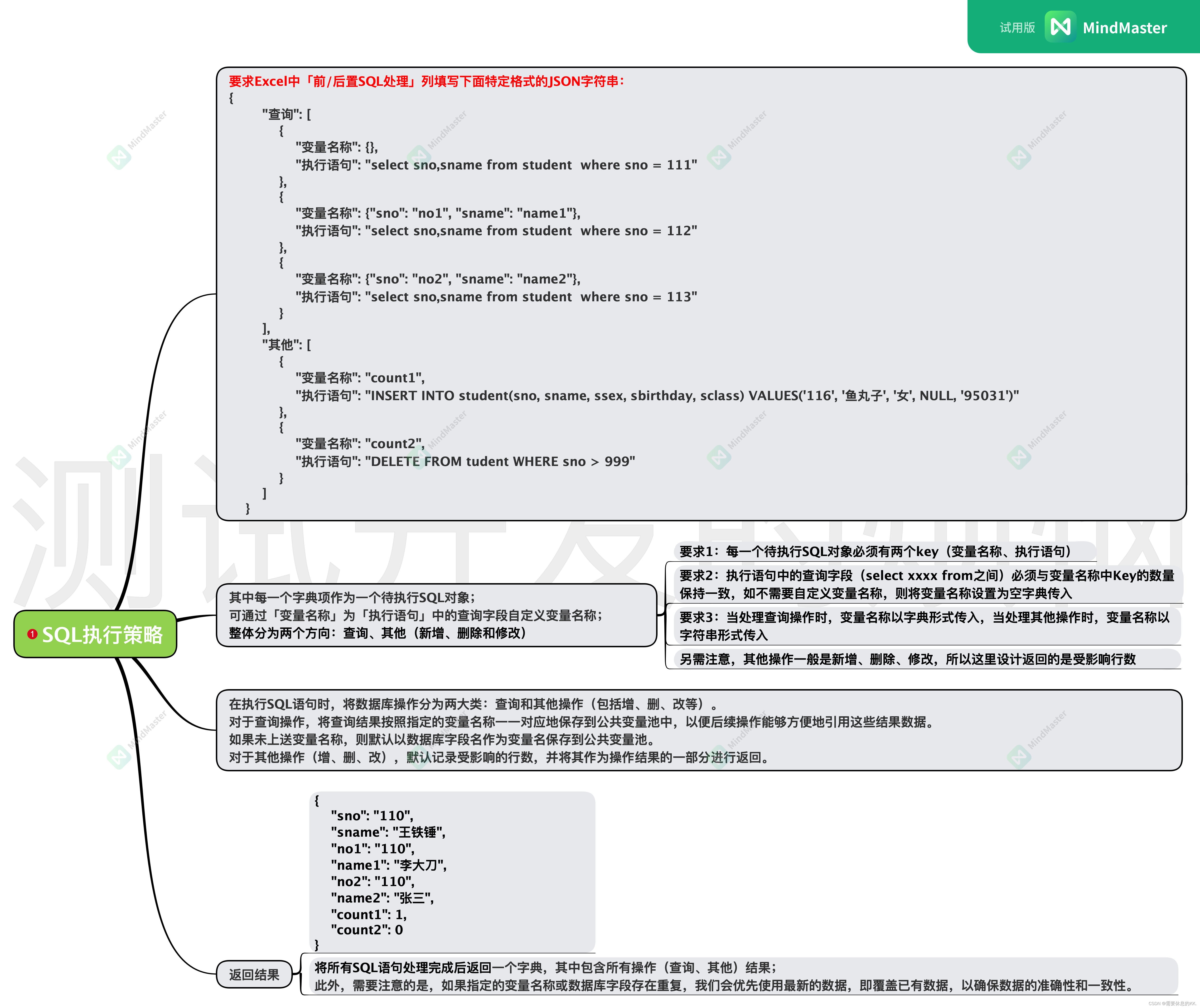
填写格式和操作类型
要求在Excel文件中填写符合特定格式的JSON字符串
{
"查询": [
{
"变量名称": {},
"执行语句": "select sno,sname from student where sno = 111"
},
{
"变量名称": {
"sno": "student_no1",
"sname": "student_name1"
},
"执行语句": "select sno,sname from student where sno = 112"
},
{
"变量名称": {
"sno": "student_no2",
"sname": "student_name2"
},
"执行语句": "select sno,sname from student where sno = 113"
}
],
"其他": [
{
"变量名称": "count1",
"执行语句": "INSERT INTO student(sno, sname, ssex, sbirthday, sclass) VALUES('116', '鱼丸子', '女', NULL, '95031')"
},
{
"变量名称": "count2",
"执行语句": "DELETE FROM tudent WHERE sno > 999"
}
]
}
公共变量处理详解
代码设计思想
在关联案例测试中,被测接口往往依赖于一系列特定的变量值来执行其功能。
然而,实际获取的原始数据可能无法直接使用,这就需要对数据二次处理,以便其能够更精准地应用于测试场景。
二次处理的过程可能涉及多种操作,比如从数据库或外部数据源获取的字符串数据,可能需要进行截取、替换或正则匹配等步骤,以提取出测试所必需的关键信息。
以身份证号码为例,我们可能需要通过截取的方式,从身份证号码中提取出生年月日信息,以满足birthday字段的yyyyMMdd格式要求。
通过一系列的数据转换和格式化操作,将原始数据转化为符合测试要求的格式或状态。
这样,就能够更加高效、准确地执行测试,从而确保被测接口的功能正常且符合预期。
这种处理的核心原理在于数据处理和转换的灵活性,它使得我们能够适应各种不同的测试场景和需求。
填写格式和操作类型
[
{
"变量名称": "被处理的变量名称",
"处理类型": "字符串截取",
"处理规则": "start_index:end_index:step_index",
"变量保存": "变量是否需要另存,如果为空则覆盖原变量"
},
{
"变量名称": "被处理的变量名称",
"处理类型": "字符串替换",
"处理规则": "old_text:new_text",
"变量保存": "变量是否需要另存,如果为空则覆盖原变量"
},
{
"变量名称": "被处理的变量名称",
"处理类型": "字符串计数",
"处理规则": "",
"变量保存": "变量是否需要另存,如果为空则覆盖原变量"
},
{
"变量名称": "被处理的变量名称",
"处理类型": "正则表达式",
"处理规则": "正则表达式语句",
"变量保存": "变量是否需要另存,如果为空则覆盖原变量"
},
{
"变量名称": "被处理的变量名称",
"处理类型": "仅保留数字",
"处理规则": "",
"变量保存": "变量是否需要另存,如果为空则覆盖原变量"
},
{
"变量名称": "被处理的变量名称",
"处理类型": "JSONPath提取",
"处理规则": "JSONPath语句",
"变量保存": "变量是否需要另存,如果为空则覆盖原变量"
}
]
数据动态替换策略
本框架在处理请求头、请求报文以及前后置SQL语句时,支持动态数据替换功能。在数据替换的过程中,每项数据都会经历两次扫描操作。
第一次扫描所有形如${xxxx}的占位符:
对于这些占位符,框架会尝试在公共变量池中查找与其同名的变量,并将这些变量的值替换到相应的占位符位置。第二次扫描所有形如${xxxx}的占位符:
此时,框架会执行与占位符同名的内置函数,并将函数执行的结果替换到占位符上。
同时,框架还会将占位符中的内容作为键(key),将函数执行的结果作为值(value),保存到公共变量池中,以便后续可能的使用。如果经过这两次扫描和替换操作后,公共变量池和内置函数都无法完成某个占位符的替换,框架将会抛出一个异常错误,以提示用户存在无法处理的占位符或相关的配置问题。
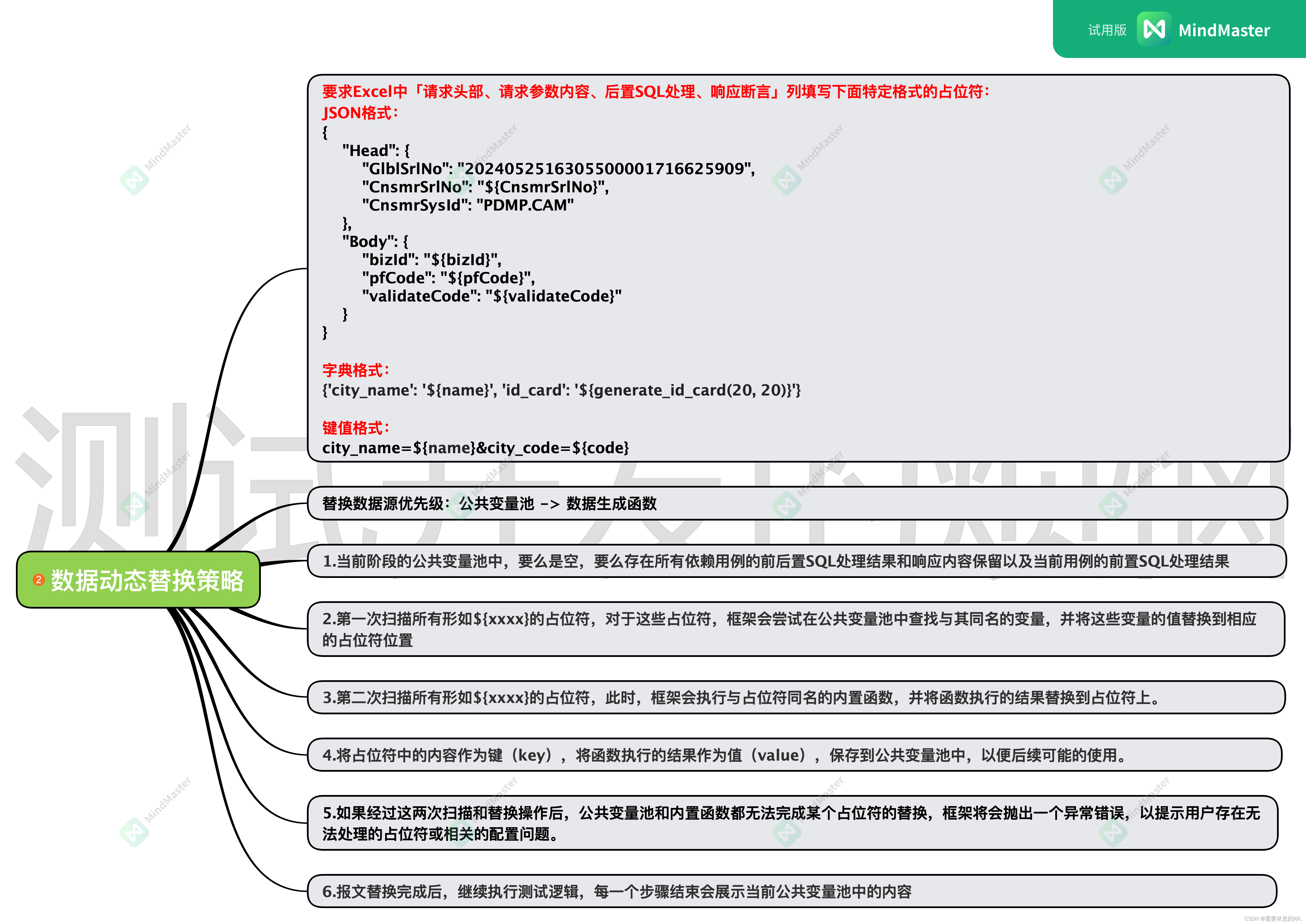
自动生成testcase文件
在编写好Excel文件之后,可以直接执行 TestcaseAutomaticGenerate.py 会根据你设计的测试用例数据,进行构建独立testcase还是关联testcase。
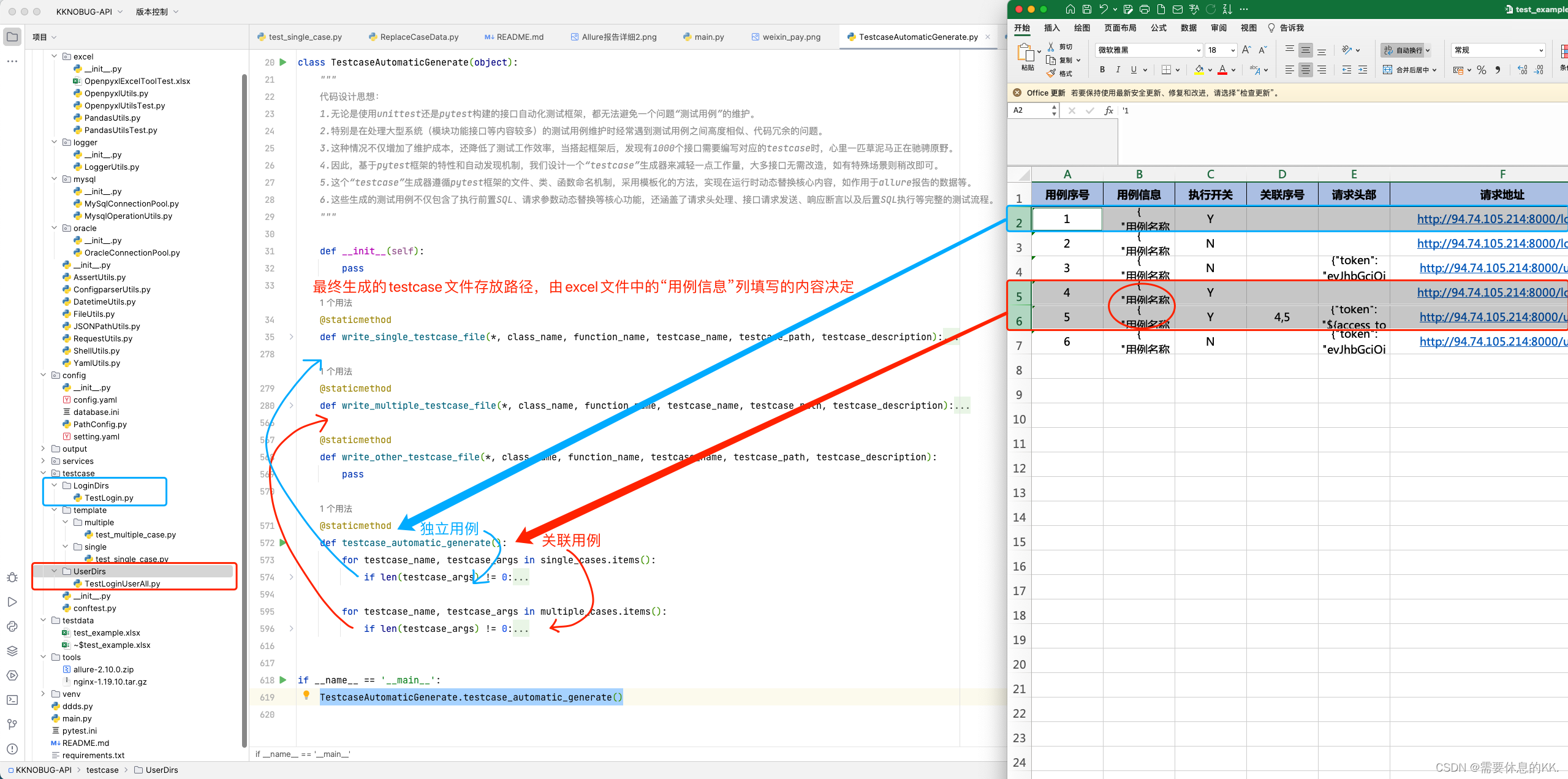
安装教程
- 搭建 python 环境:Python安装 Pycharm安装
- 搭建 allure 环境:Allure安装 Java JDK安装
安装依赖库
如上环境如都搭建好,则安装本框架的所有第三方库依赖,执行如下命令
pip3 install -r requirements.txt
使用方法
- 在Excel文件中按照模板填写各类数据,框架会自动根据编写的测试用例数据生成pytest对应的testcase代码。
- 根据需求在config/setting.yaml文件中配置:logger、project、excel、email相关数据。
- 当Excel文件编写好之后,直接运行main.py主程序,执行所有自动化接口
- 在output/reports/html中会生成最新的测试报告
独立用例编写

关联用例编写

邮件通知
实现了测试用例执行通过率反馈、失败信息回溯、日志文件附件
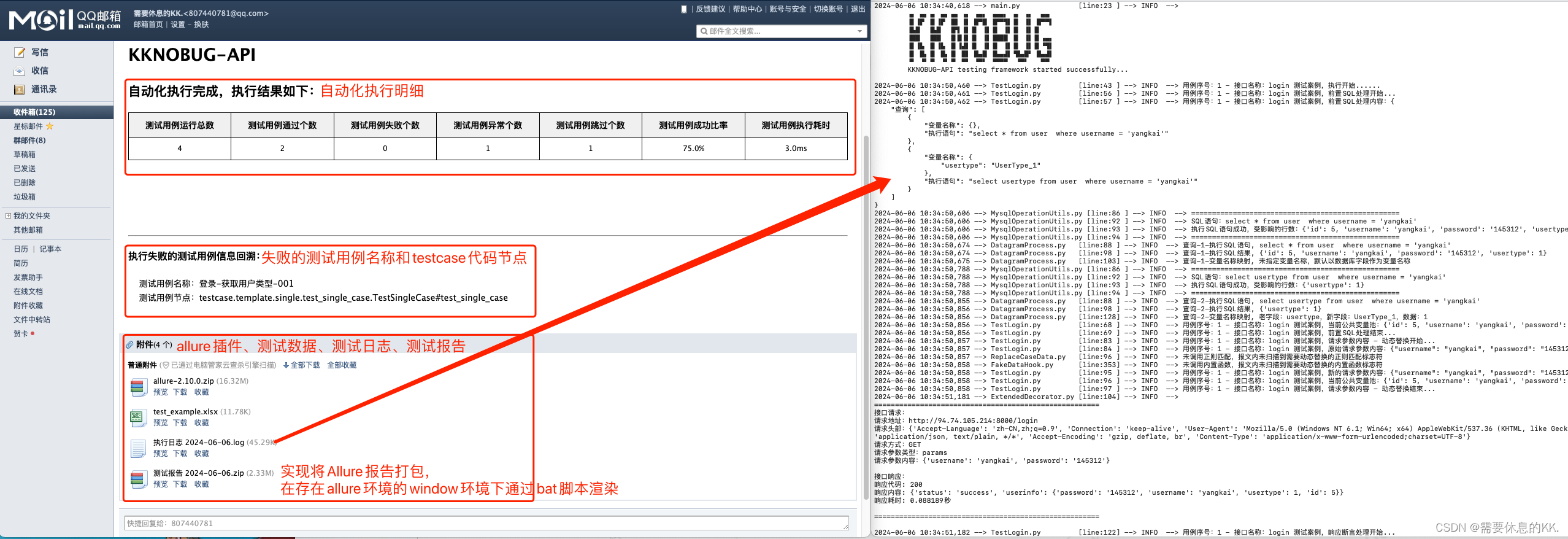
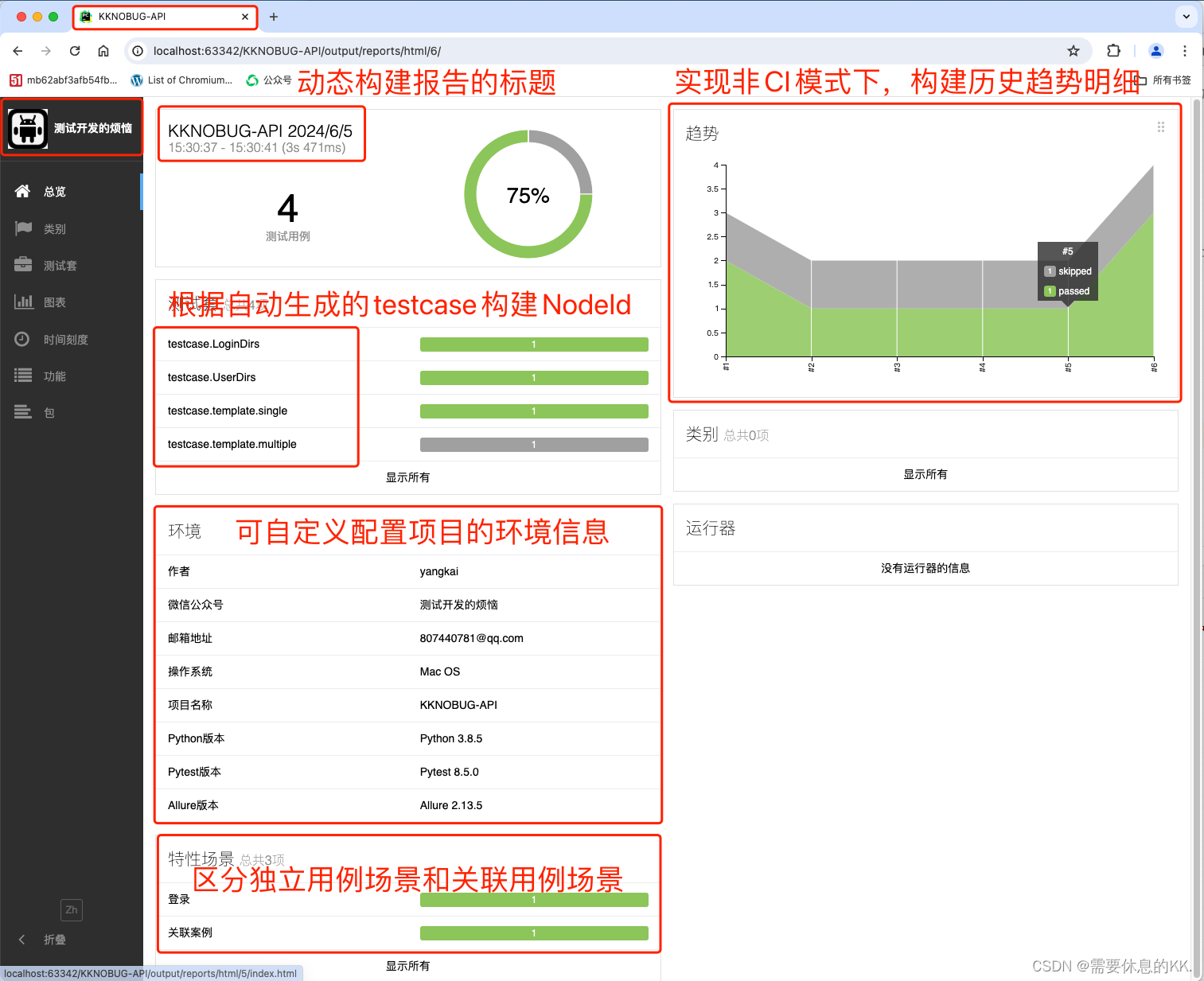
测试报告
实现了非CI模式下,pytest中使用allure生成的报告,附有历史趋势信息
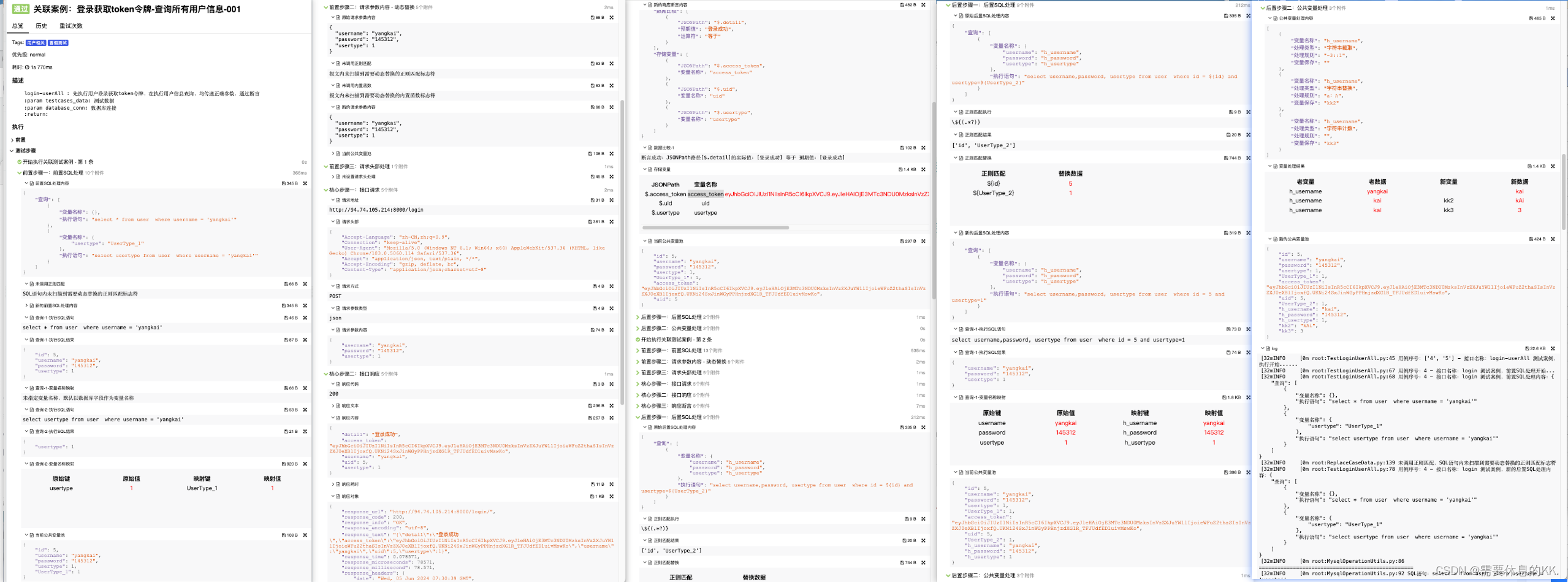
详细的记录了所有测试用例的执行过程和数据变化,让错误有迹可循

目录结构
├── common
│ ├── excel
│ │ ├── OpenpyxlUtils.py Excel工具类1
│ │ └── PandasUtils.py Excel工具类2
│ ├── logger
│ │ └── LoggerUtils.py 日志收集工具类
│ ├── mysql
│ │ ├── MysqlConnectionPool.py Mysql数据库连接池
│ │ └── MysqlOperationUtils.py Mysql数据库增删改查工具类
│ ├── oracle
│ │ ├── OracleConnectionPool.py Oracle数据库连接池
│ │ └── OracleOperationUtils.py Oracle数据库增删改查工具类
│ ├── AssertUtils.py 响应内容断言工具类
│ ├── ConfigparserUtils.py 配置文件读写工具类
│ ├── DatetimeUtils.py 时间日期工具类
│ ├── FileUtils.py 文件或目录工具类
│ ├── JSONPathUtils.py JSON数据增删改查工具类
│ ├── RequestUtils.py HTTP网络请求工具类
│ ├── ShellUtils.py shell命令执行工具类
│ ├── YamlUtils.py yaml文件增删改查工具类
├── config
│ ├── setting.yaml 框架整体配置
│ ├── database.ini 数据库连接配置
│ ├── PathConfig.py 框架内文件路径配置
├── output
│ ├── documents 框架实现文档、策略文档
│ ├── logs 执行日志
│ ├── reports 测试报告
├── services
│ ├── core
│ │ ├── AllureCustormization.py Allure报告定制化
│ │ ├── DatagramProcess.py 测试数据预处理
│ │ ├── EmailNotification.py 邮件通知
│ │ ├── TestcaseAutomaticGenerate.py 自动生成测试函数代码
│ ├── CheckInstanceType.py 报文类型检查
│ ├── ExtendedDecorator.py 扩展装饰器
│ ├── FakeDataHook.py 造数函数封装
│ ├── RelevanceCaseData.py 测试数据组装
│ ├── ReplaceCaseData.py 测试数据动态替换
│ ├── ResponseModel.py 响应模型
├── testcase 测试函数代码
│ ├── template
│ │ ├── single
│ │ │ └── test_single_case.py 独立用例测试函数代码示例
│ │ ├── multiple
│ │ │ └── test_multiple_case.py 关联用例测试函数代码示例
├── testdata
│ ├── test_example.xlsx 测试用例数据文件示例
├── tools
│ ├── allure-2.10.0.zip allure插件
│ └── ...
├── README.md 帮助文档
├── pytest.ini pytest框架配置文件
├── main.py 运行入口
├── requirements.txt 依赖库文档

依赖库
allure-pytest==2.13.5
allure-python-commons==2.13.5
attrs==23.2.0
certifi==2024.2.2
chardet==4.0.0
charset-normalizer==3.3.2
cx_Oracle==8.3.0
DBUtils==3.1.0
et-xmlfile==1.1.0
exceptiongroup==1.2.1
execnet==2.1.1
Faker==24.11.0
idna==2.5
iniconfig==2.0.0
jsonpath==0.82.2
jsonpath-ng==1.6.1
numpy==1.26.4
openpyxl==3.1.2
packaging==24.0
pandas==2.2.2
pluggy==1.5.0
ply==3.11
PyMySQL==1.1.0
pytest==8.2.0
pytest-ordering==0.6
pytest-repeat==0.9.3
pytest-rerunfailures==14.0
pytest-xdist==3.6.1
python-dateutil==2.9.0.post0
pytz==2024.1
PyYAML==6.0.1
requests==2.25.1
six==1.16.0
tomli==2.0.1
tzdata==2024.1
urllib3==1.26.5
xlrd==2.0.1





![[职场] 美术指导的重要作用 #学习方法#笔记](https://img-blog.csdnimg.cn/img_convert/243377a76b281aa0241564ba719659fb.jpeg)