文章目录
- 前言:
- 1. 进程线程间的互斥相关背景概念
- 1.1. 操作共享变量会有问题的售票系统代码:
- 2. 互斥量的接口
- 2.1. 解决方案
- 2.1.1. 使用全局的锁:
- 2.1.2. 使用局部的锁:
- 2.1.3. 封装为RAII风格的加锁和解锁:
- 2.1.4. C++ 11 中也有类似的锁:
- 3. 互斥的底层实现
- 总结:
前言:
在现代的操作系统中,多线程编程是一种常见的并发执行方式,它能够提高程序的执行效率和资源利用率。然而,当多个线程需要访问同一资源时,如果没有适当的同步机制,就可能出现数据竞争、条件竞争等并发问题,导致程序运行结果不可预测。本文将深入探讨进程和线程间互斥的背景概念,介绍互斥量(mutex)的使用和实现原理,并提供具体的编程示例,以帮助读者理解和掌握多线程编程中的互斥机制。
1. 进程线程间的互斥相关背景概念
- 临界资源:多线程执行流共享的资源就叫临界资源。
- 临界区:每个写成内部,访问临界资源的代码,就叫做临界区
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对对临界资源起保护作用。
- 原子性(后面讨论如何实现):不会被任何调度机制打断的操作,该操作只要两态,要么完成,要么未完成。
互斥量mutex
- 大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程空间内,这种情况,变量属于单个线程,其他线程无法获取这种变量。
- 但有的时候,很多变量都需要在线程间共享,这样的变量被称为共享变量,可以通过数据的共享,完成线程之间的交互。
- 多个线程并发的操作共享变量,会带来以西为问题。
1.1. 操作共享变量会有问题的售票系统代码:
// Thread.hpp
#ifndef __THREAD_HPP__
#define __THREAD_HPP__
#include <iostream>
#include <string>
#include <unistd.h>
#include <functional>
#include <pthread.h>
namespace ThreadModule
{
template<typename T>
using func_t = std::function<void(T)>;
// typedef std::function<void(const T&)> func_t;
template<typename T>
class Thread
{
public:
void Excute()
{
_func(_data);
}
public:
Thread(func_t<T> func, T data, const std::string &name="none-name")
: _func(func), _data(data), _threadname(name), _stop(true)
{}
static void *threadroutine(void *args) // 类成员函数,形参是有this指针的!!
{
Thread<T> *self = static_cast<Thread<T> *>(args);
self->Excute();
return nullptr;
}
bool Start()
{
int n = pthread_create(&_tid, nullptr, threadroutine, this);
if(!n)
{
_stop = false;
return true;
}
else
{
return false;
}
}
void Detach()
{
if(!_stop)
{
pthread_detach(_tid);
}
}
void Join()
{
if(!_stop)
{
pthread_join(_tid, nullptr);
}
}
std::string name()
{
return _threadname;
}
void Stop()
{
_stop = true;
}
~Thread() {}
private:
pthread_t _tid;
std::string _threadname;
T _data; // 为了让所有的线程访问同一个全局变量
func_t<T> _func;
bool _stop;
};
} // namespace ThreadModule
#endif
// Thread.cc
#include <iostream>
#include <vector>
#include "Thread.hpp"
using namespace ThreadModule;
int g_tickets = 10000; //一万张票,共享资源,没有被保护的,
//对全局的tickets的判断不是原子的!
const int num = 4; // 创建4个进程
class threadData
{
public:
threadData(int& tickets, const std::string& name) :_tickets(tickets), _name(name), _total(0)
{}
~threadData()
{}
public:
int &_tickets; // 所有的线程,最后都会引用同一个全局的g_tickets
std::string _name;
int _total;
};
void route(threadData* td)
{
while(true)
{
if (td->_tickets > 0)
{
// 模拟一次抢票的逻辑
usleep(1000);
printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);
td->_tickets--;
td->_total++;
}
else
{
break;
}
}
}
int main()
{
//std::cout << "main: &tickets:" << &g_tickets << std::endl;
std::vector<Thread<threadData*>> threads;
std::vector<threadData*> datas;
// 1. 创建一批线程
for (int i = 0; i < num; i++)
{
std::string name = "thread-" + std::to_string(i + 1);
threadData* td = new threadData(g_tickets, name);
threads.emplace_back(route, td, name);
datas.emplace_back(td);
}
// 2. 启动 一批线程
for (auto &thread : threads)
{
thread.Start();
}
// 3. 等待一批线程
for (auto &thread : threads)
{
thread.Join();
std::cout << "wait thread done, thread is: " << thread.name() << std::endl;
}
sleep(1);
// 4. 输出统计数据
for (auto& data : datas)
{
std::cout << data->_name << " : " << data->_total << std::endl;
}
return 0;
}
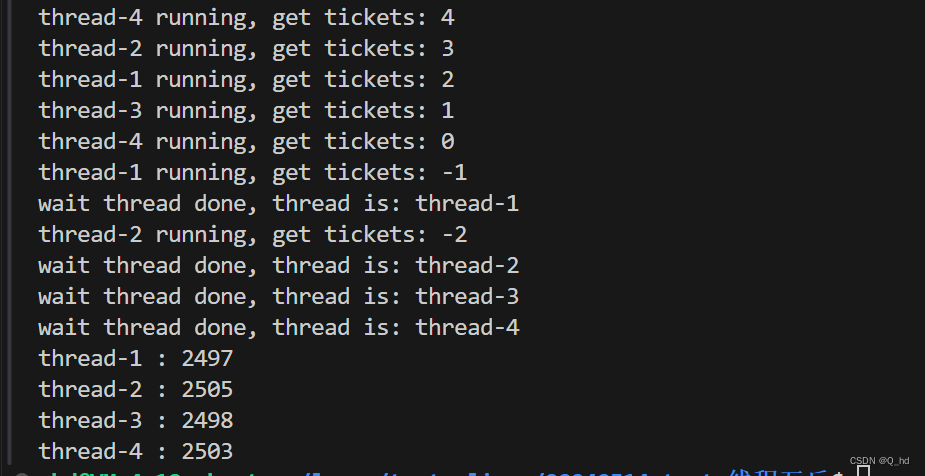
为什么抢到了负数:
if (td->_tickets > 0)
判断是逻辑运算,必须在CPU内部运行。
td->_tickets--;
tickets 等价于 tickets = tickets-1;
- 从内存读取到CPU
- CPU内部进行-- 操作
- 写回内存
它不是原子的,编译后不止一条汇编语句
解决问题:
要解决以上问题,需要做到三点:
- 代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
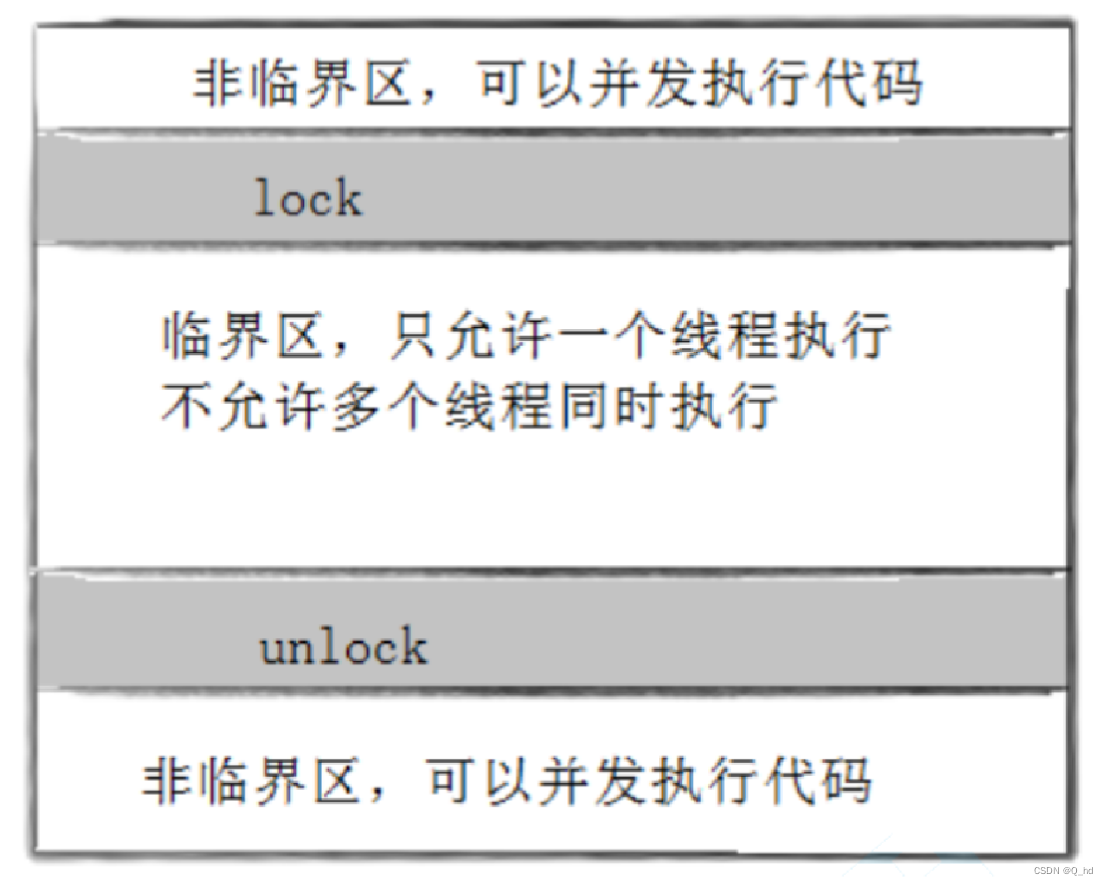
要做到这三点,本质上就是需要一把锁。Linux上提供的这把锁叫互斥量。
初始化互斥量
初始化互斥量有两种方法:
解决问题:
2. 互斥量的接口
初始化互斥量
初始化互斥量有两种方法:
- 方法1,静态分配:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
- 方法2,动态分配:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict
attr);
参数:
mutex:要初始化的互斥量
attr:NULL
销毁互斥量
销毁互斥量需要注意:
- 使用PTHREAD_MUTEX_INITIALIZER 初始化的互斥量不需要销毁
- 不要销毁一个已经枷锁的互斥量
- 已经销毁的互斥量,要却表后面不会有线程再尝试加锁
int pthread_mutex_destroy(pthread_mutex_t* mutex);
互斥量加锁和解锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值:成功返回0,失败返回错误号
申请锁成功:函数就会返回,允许你继续向后运行
申请锁失败:函数就会阻塞,不允许你继续向后运行
函数调用失败:出错返回
调用pthread_lock 时,可能会遇到以下情况:
- 互斥量处于未锁状态,该函数会将互斥量锁定,同时返回成功。
- 发起函数调用时,其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_ lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁。
2.1. 解决方案
出现并发访问的问题,本质是因为多个执行流的访问全局数据的代码导致!
保护全局共享资源,本质是通过保护:临界区完成的!
临界区:这段代码在执行时访问共享资源(如共享内存、全局变量等),而且可能会被多个并发执行的线程或进程访问。
非临界区:不访问共享资源的代码段,或者即使访问了也不会引发竞争条件的代码段。
我们加锁,本质就是把并行执行变为串行执行,加锁的粒度越细越好!
2.1.1. 使用全局的锁:
// tesetThread.cc
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;
void route(threadData* td)
{
while(true)
{
// 访问临界资源的代码,叫做临界区!我们加锁,本质就是把并行执行变为串行执行,加锁的粒度越细越好!
pthread_mutex_lock(&gmutex); // 加锁:竞争是自由竞争的,竞争锁的能力太强的线程,会导致其它线程抢不到锁,造成了其它写线程的饥饿问题!
if (td->_tickets > 0) // 1
{
// 模拟一次抢票的逻辑
usleep(1000);
printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets); // 2
td->_tickets--; // 3
pthread_mutex_unlock(&gmutex); // 解锁
td->_total++; // 每个线程一人一个不属于临界区
}
else
{
pthread_mutex_unlock(&gmutex); // 解锁
break;
}
}
}
加锁:竞争是自由竞争的,竞争锁的能力太强的线程,会导致其它线程抢不到锁,造成了其它写线程的饥饿问题!
2.1.2. 使用局部的锁:
// tesetThread.cc
#include <iostream>
#include <vector>
#include "Thread.hpp"
using namespace ThreadModule;
// 共享资源没有被保护,临界资源
int g_tickets = 10000; //一万张票,共享资源,没有被保护的,对全局的tickets的判断不是原子的!
const int num = 4; // 创建4个进程
class threadData
{
public:
threadData(int& tickets, const std::string& name, pthread_mutex_t &mutex)
:_tickets(tickets), _name(name), _total(0), _mutex(mutex)
{}
~threadData()
{}
public:
int &_tickets; // 所有的线程,最后都会引用同一个全局的 g_tickets
std::string _name;
int _total;
pthread_mutex_t &_mutex;
};
// pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;
void route(threadData* td)
{
while(true)
{
// 访问临界资源的代码,叫做临界区!我们加锁,本质就是把并行执行变为串行执行,加锁的粒度越细越好!
// pthread_mutex_lock(&gmutex); // 加锁
pthread_mutex_lock(&td->_mutex);
if (td->_tickets > 0)
{
// 模拟一次抢票的逻辑
usleep(100);
printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);
td->_tickets--;
// pthread_mutex_unlock(&gmutex); // 解锁
pthread_mutex_unlock(&td->_mutex);
td->_total++; // 每个线程一人一个不属于临界区
}
else
{
// pthread_mutex_unlock(&gmutex); // 解锁
pthread_mutex_unlock(&td->_mutex);
break;
}
}
}
int main()
{
//std::cout << "main: &tickets:" << &g_tickets << std::endl;
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
std::vector<Thread<threadData*>> threads;
std::vector<threadData*> datas;
// 1. 创建一批线程
for (int i = 0; i < num; ++i)
{
std::string name = "thread-" + std::to_string(i + 1);
threadData* td = new threadData(g_tickets, name, mutex);
threads.emplace_back(route, td, name);
datas.emplace_back(td);
}
// 2. 启动 一批线程
for (auto &thread : threads)
{
thread.Start();
}
// 3. 等待一批线程
for (auto &thread : threads)
{
thread.Join();
std::cout << "wait thread done, thread is: " << thread.name() << std::endl;
}
sleep(1);
// 4. 输出统计数据
for (auto& data : datas)
{
std::cout << data->_name << " : " << data->_total << std::endl;
}
return 0;
}
上述我们这种现象叫做互斥,可以保证不出错。
互斥这套规则,必须被所有访问临界区的线程遵守!
2.1.3. 封装为RAII风格的加锁和解锁:
// LockGuard.hpp
#ifndef __LOCK_GUARD_HPP__
#define __LOCK_GUARD_HPP__
#include <iostream>
#include <pthread.h>
class LockGuard
{
public:
LockGuard(pthread_mutex_t* mutex):_mutex(mutex)
{
pthread_mutex_lock(_mutex); // 构造加锁
}
~LockGuard()
{
pthread_mutex_unlock(_mutex);
}
private:
pthread_mutex_t* _mutex;
};
#endif
// tesetThread.cc
void route(threadData* td)
{
while(true)
{
LockGuard guard(&td->_mutex); // 临时对象,RAII风格的加锁和解锁
if (td->_tickets > 0)
{
usleep(500);
printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);
td->_tickets--;
td->_total++;
}
else
{
break;
}
}
}
2.1.4. C++ 11 中也有类似的锁:
#include <mutex>
int main()
{
std::mutex mutex;
// ...
}
void route(threadData* td)
{
while(true)
{
td->_mutex.lock();
if (td->_tickets > 0)
{
usleep(500);
printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);
td->_tickets--;
td->_mutex.unlock();
td->_total++;
}
else
{
td->_mutex.unlock();
break;
}
}
}
void route(threadData* td)
{
while(true)
{
std::lock_guard<std::mutex> lock(td->_mutex);
if (td->_tickets > 0)
{
usleep(500);
printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);
td->_tickets--;
td->_total++;
}
else
{
break;
}
}
}
3. 互斥的底层实现
- 经过上面的例子,大家已经意识到单纯的
i++或者++i都不是原子的,有可能会有数据一致性问题 - 为了实现互斥锁操作,大多数体系结构都提供了
swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的 总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。 现在我们把lock和unlock的伪代码改一下

线程切换的的时机是随机的!
交换的本质:不是拷贝到寄存器,而且所有线程在争锁的时候,只有一个 1 !
交换的时候,只有一条汇编——原子的!
CPU寄存器硬件只有一套,但是CPU寄存器内部的数据,数据线程的硬件上下文!
数据在内存里,所有线程都能访问,属于共享的,但是如果转移到CPU内部寄存器,就属于一个线程私有数据了!
- 一个问题?
临界区内部,正在访问临界区的线程,可不可以被OS切换调度呢?
一个线程正在访问临界区,没有释放锁之前,对于其他线程:
- 被锁释放
- 曾经我没有申请到锁
所以临界区只要一旦加锁,对于其它线程而言就是原子的,整个抢票过程是线程安全的!
总结:
本文首先介绍了进程和线程间互斥的相关背景概念,包括临界资源、临界区和互斥的概念,以及原子性的重要性。接着,通过一个售票系统的示例代码,展示了在没有同步机制的情况下,多个线程并发访问共享资源时可能出现的问题。文章进一步讨论了互斥量的接口和底层实现,包括互斥量的初始化、加锁、解锁和销毁等操作,并介绍了如何使用全局锁和局部锁来解决并发问题。此外,还介绍了RAII风格的加锁和解锁方法,以及C++ 11中提供的互斥量支持。
通过本文的学习,读者应该能够理解互斥量在多线程编程中的重要性,掌握互斥量的使用方法,并能够运用这些知识来解决实际编程中遇到的并发问题。文章最后指出,临界区的访问必须被加锁保护,以确保线程安全,并且强调了互斥规则必须被所有访问临界区的线程遵守。通过合理地使用互斥量,可以有效地避免数据竞争和条件竞争,确保多线程程序的正确性和稳定性。