1. 认识Tokenizer
1.1 为什么要有tokenizer?
计算机是无法理解人类语言的,它只会进行0和1的二进制计算。但是呢,大语言模型就是通过二进制计算,让你感觉计算机理解了人类语言。
- 举个例子:单=1,双=2,计算机面临“单”和“双”的时候,它所理解的就是2倍关系。
- 再举一个例子:赞美=1,诋毁=0, 当计算机遇到0.5的时候,它知道这是“毁誉参半”。
- 再再举一个例子:女王={1,1},女人={1,0},国王={0,1},它能明白“女人”+“国王”=“女王”。
可以看出,计算机面临文字的时候,都是要通过数字去理解的。
所以,如何把文本转成数字,是语言模型中最基础的一步,而Tokenizer的作用就是完成文本到数字的转换,是大语言模型最基础的组件。
1.2 什么是tokenizer?
Tokenizer是一个词元生成器,它首先通过分词算法将文本切分成独立的token列表,再通过词表映射将每个token转换成语言模型可以处理的数字。
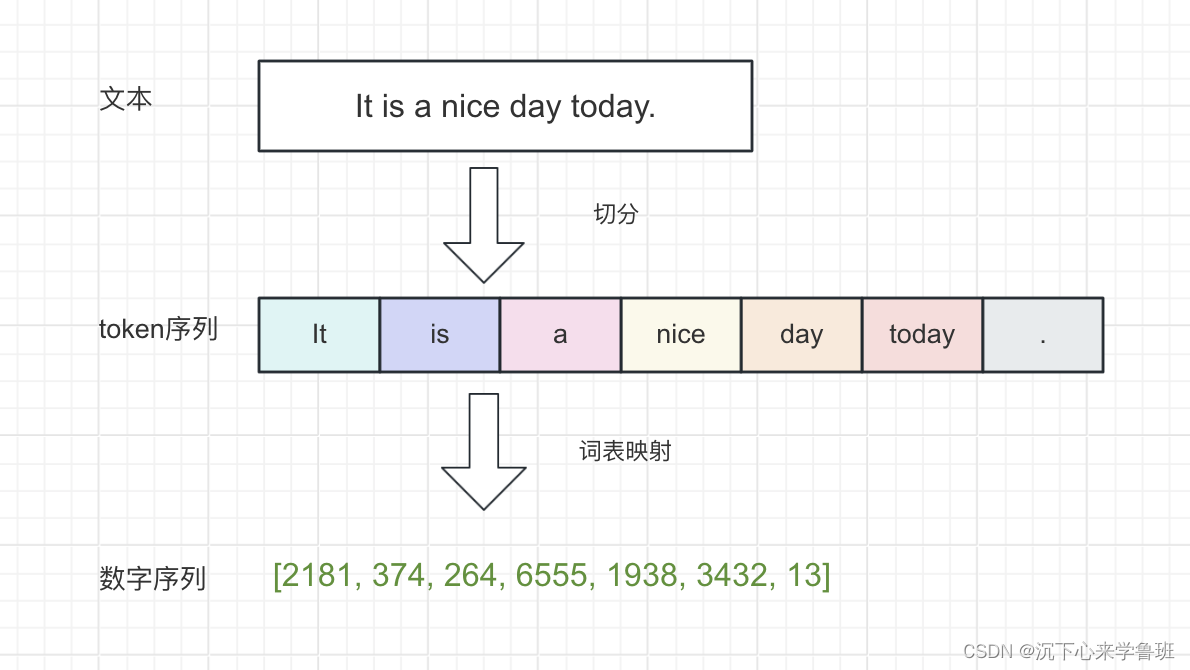
这里有一个网站,可以在线演示tokenizer的切分,见:tokenizer在线演示
大多数常见的英语单词都分配一个token:

而有的单词却分配不止一个token:
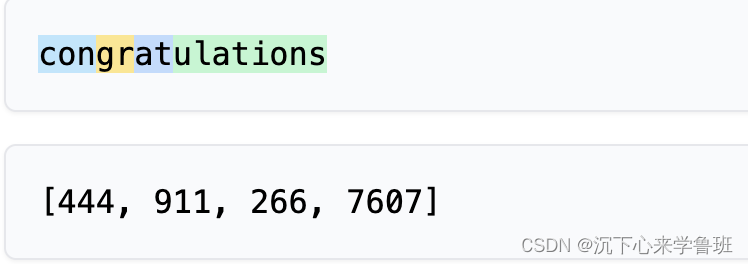
像congratulations就被切分成4个token.
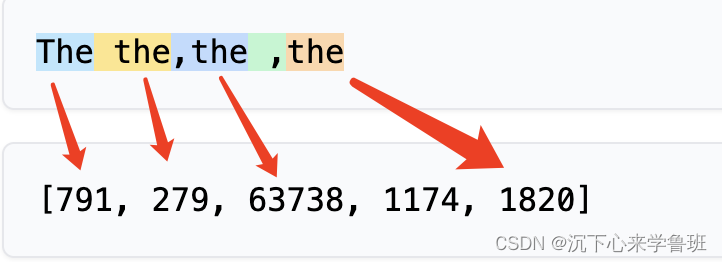
不仅如此,而字母大小写,空格和标点符号对分词结果也有影响,如下面示例:
以上这些分词效果,均与token的切分方式有关。
2. token切分方式
根据切分粒度的不同可以把tokenizer分为:
- 基于词的切分
- 基于字的切分
- 基于subword的切分
2.1 基于词的切分
将文本按照词语进行分割,通过空格或者标点符号来把文本分成一个个单词,这样分词之后的 token 数量就不会太多,比如 It is a nice day -> It, is, a, nice, day。缺点是:
- 词表规模可能会过大;
- 一定会存在UNK,造成信息丢失;
- 不能学习到词根、词缀之间的关系,例如:dog与dogs,happy与unhappy;
UNK是"unknown"(未知)的缩写,表示模型无法识别的单词或标记,对于一些新词、生僻词、专有名词或拼写错误的词可能未被词典收录。
词表规模过大原因:自然语言中存在大量的词汇,而词汇与词汇之间的排列组合又能造出大量的复合词,这会导致词表规模很大,并且持续增长。
2.2 基于字的切分
将文本按照字符进行切分,把文本拆分成一个个字符单独表示,比如 highest -> h, i, g, h, e, s, t。
- 优点:
- 词表Vocab 不会太大,Vocab 的大小为字符集的大小,英文只有26个字母;
- 也不会遇到UNK问题;
- 缺点:
- 字符本身并没有传达太多的语义,丧失了词的语义信息;
- 分词之后的 token序列过长,例如
highest一个单词就可以得到 7 个 token,如果是很长的文本分出来的token数量将难以想象,这会造成语言模型的解码效率很低;
2.3 基于subword的切分
从上可以看出,基于词和基于字的切分方式是两个极端,其优缺点也是互补的。而subword就是一种相对平衡的折中方案,基本切分原则是:
- 高频词依旧切分成完整的整词,例如
It=>[ It ] - 低频词被切分成有意义的子词,例如
dogs=>[dog, s]
它的特点是:
- 词表规模适中,解码效率较高
- 不存在UNK,信息不丢失
- 能学习到词缀之间的关系
因此基于subword的切分是目前的主流切分方式。
3. subword分词流程
分词的基本需求:给定一个句子,基于分词模型切分成一连串token。效果如下:
input: Hello, how are u tday?
output: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
整个tokenize的过程可以用下面这个图来理解,分为预分词、基于模型分词、编码三步。

3.1 预分词
预分词阶段会把句子切分成词单元,可以基于空格或者标点进行切分。
以gpt2为例,预切分结果如下,每个单词变成了[word, (start_index, end_index)]
input: Hello, how are you?
pre-tokenize:
[GPT2]: [('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)), ('?', (19, 20))]
在GPT2中,空格会保留成特殊的字符“Ġ”。
不同的模型在切分时对于空格和标点的处理方式不同,作为对比:
- BERT的tokenizer也是基于空格和标点进行切分,但不会保留空格。
[BERT]: [('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
- LLama 的T5则只基于空格进行切分,标点不会切分。并且空格会保留成特殊字符"▁",并且句子开头也会添加特殊字符"▁"。
[t5]: [('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]
3.2 基于模型分词
上面预分词的结果基本就是一个单词一个token,但这样的切分粒度是很粗的,正如上面切分方式中介绍的问题,容易造成词表规模过大。
而基于模型分词本质上就是对预分词后的每个单词再尝试进行切分,也就是上面提到的subword方式,目前主流大语言模型使用的是BPE算法。
BPE分词的过程可以简单理解为从短到长逐步查找词元的过程,概括为以下三步。
- 对于输入序列中的每个单词拆分成一个个字符,以
Ġtday为例,拆分结果如下。
('Ġ', 't', 'd', 'a', 'y')
在BPE算法中,每个字母都是最基本的词元,这样能避免UNK问题。
- 从输入的字符序列逐步查找是否有更长的词元可以代替,如果找到,就将较短的几个词元替换成这个更长的词元,还是以
Ġtday为例替换过程如下所示。
# 第一次替换:'Ġ'和't'->'Ġt'
('Ġt', 'd', 'a', 'y')
# 第二次替换:'a'和'y'->'ay'
('Ġt', 'd', 'ay')
# 第三次替换:'d'和'ay'->'day'
('Ġt', 'day')
# 结束
- 这样
Ġtday这个预分的词元就被拆分成了Ġt和day两个最终的词元,这两个词元会替换掉先前的Ġtday。
为什么
Ġt和day不能进一步合并替换呢?
原因:tday其实是today这个单词的网络用语,这个网络简称在词汇表中并不存在,所以无法合并,最终tday这个单词就在分词阶段拆分成了t和day两个token。
那么,具体哪些字符或子词能合并成更长的词元呢?
这里依据的是分词模型中子词合并记录merges.txt,这个文件是模型训练过程中生成的,其中一段示例如下。
[
["]", ",\\u010a"],
["\\u0120H", "e"],
["_", "st"],
["f", "ul"],
["o", "le"],
[")", "{\\u010a"],
["\\u0120sh", "ould"],
["op", "y"],
["el", "p"],
["i", "er"],
["_", "name"],
["ers", "on"],
["I", "ON"],
["ot", "e"],
["\\u0120t", "est"],
["\\u0120b", "et"],
["rr", "or"],
["ul", "ar"],
["\\u00e3", "\\u0122"],
["\\u0120", "\\u00d0"],
["b", "s"],
["t", "ing"],
["\\u0120m", "ake"],
["T", "r"],
["\\u0120a", "fter"],
["ar", "get"],
["R", "O"],
["olum", "n"],
["r", "c"],
["_", "re"],
["def", "ine"],
["\\u0120r", "ight"],
["r", "ight"],
["d", "ay"],
["\\u0120l", "ong"],
["[", "]"],
["(", "p"],
["t", "d"],
["con", "d"],
["\\u0120P", "ro"],
["\\u0120re", "m"],
["ption", "s"],
["v", "id"],
[".", "g"],
["\\u0120", "ext"],
["\\u0120", "__"],
["\'", ")\\u010a"],
["p", "ace"],
["m", "p"],
["\\u0120m", "in"],
["st", "ance"],
["a", "ir"],
["a", "ction"],
["w", "h"],
["t", "ype"],
["ut", "il"],
["a", "it"],
["<", "?"],
["I", "C"],
["t", "ext"],
["\\u0120p", "h"],
["\\u0120f", "l"],
[".", "M"],
["cc", "ess"],
["b", "r"],
["f", "ore"],
["ers", "ion"],
[")", ",\\u010a"],
[".", "re"],
["ate", "g"],
["\\u0120l", "oc"],
["in", "s"],
["-", "s"],
["tr", "ib"],
这个合并记录表与我们人类能理解的单词、词根、词缀有一定差别,既有我们常见单词的合并记录: ["def","ine"], ["r", "ight"], ["d", "ay"],也有我们看不明白的: ["\\u0120f", "l"],、 ["cc", "ess"],这些合并记录不是人工编辑的,而是模型训练阶段根据实际语料来生成的。
这种方式是有效的,它既能保留常见的独立词汇(例如:how), 又能保证未知或罕见的词汇能被拆分为较小的词根或词缀(例如:tday->t和day),即使没有词根或词缀,最后还能以单个字符(例如:?, u) 作为词元保证不会出现UNK。
这样,通过词汇表就可以将预分词后的单词序列切分成最终的词元。
input: Hello, how are u tday?
Model: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
3.3 编码
编码本质上就是给每个token分配一个唯一的数字ID,这个数字ID是分词模型训练好后就维护在词汇表中的。
每个分词模型内部都有一个vocab词汇表,以chatgpt为例,目前使用的词表为c100k_base, 它是一个index ——> token的map映射(index表示token对应的数字ID)里面有大概10万个词元,示例如下:
{
"0": "!",
"1": "\"",
"2": "#",
"3": "$",
"4": "%",
"5": "&",
"6": "'",
"7": "(",
"8": ")",
"9": "*",
"10": "+",
……
"1268": " how",
"1269": "rite",
"1270": "'\n",
"1271": "To",
"1272": "40",
"1273": "ww",
"1274": " people",
"1275": "index",
……
"100250": ".allowed",
"100251": "(newUser",
"100252": " merciless",
"100253": ".WaitFor",
"100254": " daycare",
"100255": " Conveyor"
}
切分好token后,就可以根据上面示例的词汇表,将token序列转换为数字序列,如下所示:
input: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
output: [9906, 11, 1268, 527, 577, 259, 1316, 5380]
关于这个词表vocab以及合并记录merges.txt的由来,与BPE算法的实现和训练过程有关,后续再介绍。
4. 中文分词
4.1 长度疑问
我们在估算token的消耗时,经常听到有同事说汉字要占两个token,是这样吗?我们来验证下:

为何有的汉字一个token,有的汉字两个token? 这和tiktoken对中文分词的实现方式有关。
4.2 实现剖析
举例:‘山东淄博吃烧烤’
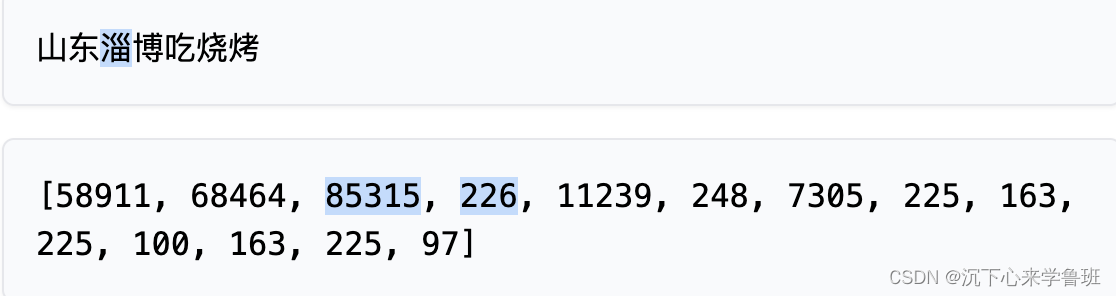
对应词汇表中的词元:
["山", "东", "b'\\xe6\\xb7'", "b'\\x84'", "b'\\xe5\\x8d'", "b'\\x9a'", "b'\\xe5\\x90'", "b'\\x83'", "b'\\xe7'", "b'\\x83'", "b'\\xa7'", "b'\\xe7'", "b'\\x83'", "b'\\xa4'"]
除了“山“、”东”这两个相对比较简单的汉字词表里面直接就有,其他的都是一些非常奇怪的Unicode编码表示。
仔细观察可以发现:tokens[85315, 226] 对应的"b’\xe6\xb7’", “b’\x84’” 拼接起来,然后按照utf-8解码回去 b’\xe6\xb7\x84’.decode(‘utf-8’) 得到的就是“淄”。
原来,OpenAI为了支持多种语言的Tokenizer,采用了文本的一种通用表示:UTF-8的编码方式,这是一种针对Unicode的可变长度字符编码方式,它将一个Unicode字符编码为1到4个字节的序列。
山和东因为比较常见,所以被编码为了独立的词元- 而
淄、博等字词频较低,所以按照Unicode编码预处理成了独立的3个字节,然后子词的迭代 合并最终分成了两个词元。
\x 表示16进制编码,可以发现
淄博分别被编码为6个16进制数字,分别占3个字节。随后,GPT-4将每2个16进制数字,也就是1字节的数据作为最小颗粒度的token,然后进行BPE的迭代、合并词表。
5. tiktoken
tiktoken是OpenAI开源一种分词工具,
采用BPE算法实现,被GPT系列大模型广泛使用。
基于某个模型来初始化tiktoken(不同模型的tiktoken词表不同):
import tiktoken
enc = tiktoken.encoding_for_model("gpt-3.5-turbo-16k")
字节对编码
encoding_res = enc.encode("Hello, how are u tday?")
print(encoding_res)
> [9906, 11, 1268, 527, 577, 259, 1316, 30]
字节对解码
raw_text = enc.decode(encoding_res)
print(raw_text)
> Hello, how are u tday?
如果想要控制token数量,则可以通过len函数来判断
length = len(enc.encode("Hello, how are u tday?"))
print(length)
> 8
参考资料
- gpt在线分词演示
- 探索GPT Tokenizer的工作原理