还记得2022年末ChatGPT的横空出世,带来了整个NLP乃至AI领域的震动,随后如LLaMA、ChatGLM、Qwen等类ChatGPT大模型(LLM)开始如雨后春笋般涌现,这些先进的模型不仅展示了在零样本学习中的出色表现,还在多种NLP任务中展示了其强大的能力,例如文本摘要、机器翻译、信息提取和情感分析等,使得多种NLP任务得以在单一模型中得到解决。
那种勃勃生机,万物竞发的境界,犹在眼前。
一年多时间过去,尽管LLMs在NLP任务中的应用已经取得了诸多成果,但关于它们的系统性研究和未来潜力的探索仍处于初级阶段。本文旨在通过详细分析LLMs在NLP中的应用现状,探讨它们当前的进展、面临的挑战以及未来的发展方向。通过引入新的分类体系,包括参数冻结范式和参数微调范式,本研究提供了一个统一的视角来理解LLMs在NLP任务中的应用,并探讨了新的研究前沿和挑战,旨在激发未来的突破性进展。
论文标题:
Large Language Models Meet NLP - A Survey
论文链接:
https://arxiv.org/pdf/2405.12819.pdf
大模型的分类和应用
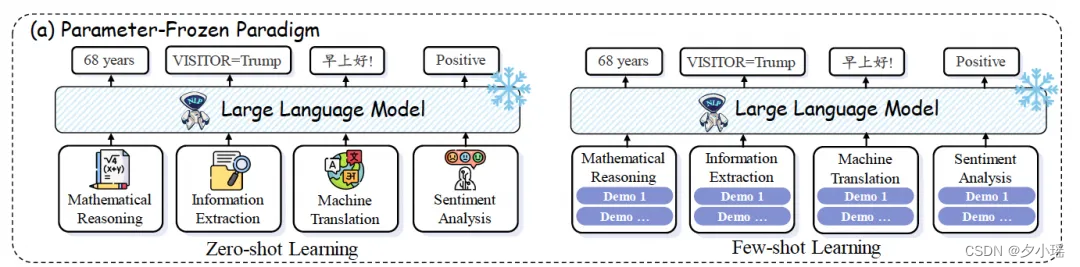
参数冻结范式
参数冻结范式是指在不对模型的参数进行任何微调的情况下,直接使用LLMs来处理NLP任务(下图a部分)。这种应用方式主要包括零样本学习(Zero-shot Learning)和少样本学习(Few-shot Learning)两种形式。
零样本学习利用模型的指令遵循能力,通过给定的指令提示来解决NLP任务。这种方式不需要额外的示例或训练数据,模型能够直接根据指令执行任务。
少样本学习则是通过在上下文中提供少量的示例来引导模型学习。这种方法需要一些相关的示例来展示任务的执行方式,从而帮助模型更好地理解和完成任务。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
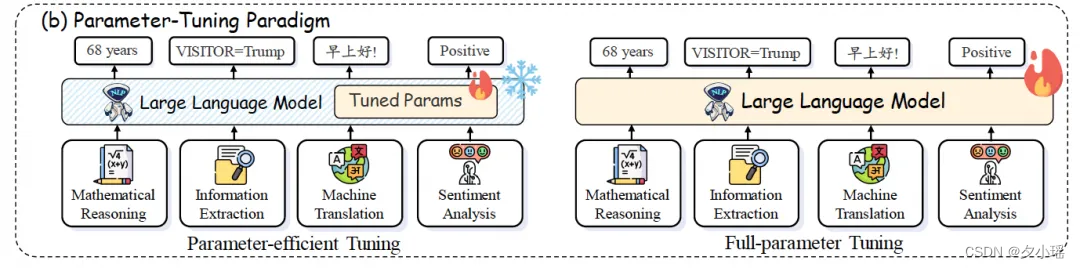
参数微调范式
参数微调范式涉及到对LLMs的参数进行微调,以适应特定的NLP任务(下图b部分)。这类范式可以进一步分为全参数微调(Full-parameter Tuning)和参数高效微调(Parameter-efficient Tuning)两种形式。
全参数微调指的是对模型的所有参数进行微调,以便模型能够更好地适应特定的任务或数据集。这种方法通常需要大量的计算资源和时间,但可以显著提高模型在特定任务上的表现。
参数高效微调则是一种更为高效的微调方式,它只微调模型的一部分参数或引入可调整的额外参数,如Bottleneck Adapter或Low-Rank Adaptation等,从而在不显著增加计算负担的情况下提升模型的表现。
NLP任务
本文从“是否调整参数”的角度,将NLP学习方式分为了两个大类,四个小类,并分别对各个类别下NLP的两大任务类型,自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generation, NLG),进行了以下汇总:

自然语言理解
自然语言理解涉及对文本内容的深入分析和解释。
-
情感分析:情感分析旨在识别文本中的情感倾向,如正面意见或批评。LLMs在情感分析任务中表现出色,尤其是通过指令微调和上下文学习来实现零样本学习和少样本学习。
-
信息抽取:信息提取任务旨在从纯文本中提取结构化信息,包括关系提取、命名实体识别和事件提取。
-
对话理解:对话理解包括口语理解和对话状态跟踪。
-
表格理解:表格理解涉及理解和分析表格中呈现的结构化数据,重点关注解释和提取有意义信息。
自然语言生成
自然语言生成涉及将数据或信息转换成自然语言文本的过程。
-
摘要:摘要的目标是从文本文档中提取最核心的信息,生成简洁且连贯的概要,同时保留原始内容的主要主题。LLMs在参数冻结范式下生成摘要方面表现出色,挑战了传统微调方法的必要性。
-
代码生成:代码生成涉及根据自然语言规范自动创建可执行代码,为编程提供了更直观的界面。LLMs在代码生成方面取得了显著进展,展示了在零、少样本情况下生成代码的能力。
-
机器翻译:机器翻译是自动将一种语言的信息翻译成另一种语言的经典任务,旨在实现准确性并保留原始材料的语义本质。
-
数学推理:数学推理任务涉及使用NLP技术来理解数学文本中的信息,执行逻辑推理,并生成答案。
未来工作和新前沿

多语言LLM的挑战与机遇
多语言LLM在处理多种语言的NLP任务中展示了巨大的潜力。例如,最近的研究表明,通过使用多语言情感词典,LLM能够在零样本情况下进行情感分析,即使在资源较少的语言中也能表现出色[1]。然而,这种模型在处理低资源语言时仍面临挑战,如何提高这些语言的性能是未来研究的一个重要方向。此外,和跨语言对齐也是多语言LLM需要解决的关键问题,有效的跨语言对齐可以极大地提高模型在跨语言NLP任务中的表现。
多模态LLM的探索与实践
随着AI领域对多模态学习的兴趣日益增加,多模态LLM成为了研究的热点。这些模型不仅处理文本数据,还能处理图像、视频等多种类型的数据。尽管当前的多模态LLM在简单的多模态推理任务中表现良好,如图像识别,但在更复杂的多模态推理任务中仍然存在挑战[2]。此外,如何设计有效的多模态交互机制,以弥合不同模态之间的差异,是实现有效多模态NLP的关键[3]。
LLM在NLP中的工具使用与优化
LLM在实际应用中往往需要与各种工具和代理一起使用,以解决更复杂的NLP任务。例如,通过与任务相关的工具链配合,LLM可以更有效地处理任务导向的对话任务。然而,如何选择合适的工具,并有效地规划工具的使用,是提高LLM在实际应用中表现的关键[4]。此外,当前的研究主要集中在单一工具的使用上,如何协调多个工具的使用,以达到最佳的性能,是未来研究的一个重要方向[5]。
LLMs在NLP中的X-of-Thought
当LLMs解决复杂的NLP问题时,它们通常需要复杂的思考过程[6]。因此,一些工作采用了X-of-Thought(XoT)进行高级逻辑推理[7]。主要挑战包括如何开发一种普遍适用的步骤分解方法,以将LLMs推广到各种NLP任务;以及如何更好地整合不同XoT的知识以解决NLP问题。
LLMs在NLP中的幻觉问题
在解决NLP任务时,LLMs不可避免地会产生与世界知识、用户请求或自生成上下文偏离的幻觉输出。因此,如何找到合适的统一评估基准和指标,对追踪并改善幻觉起到了重要作用。另一方面,合理利用幻觉也可以在某种程度上促进创造力,比如产生更好的创新知识[8]。
LLMs在NLP中的安全性问题
将LLM应用于下游NLP任务也引发了不可避免的安全问题,包括版权问题、仇恨毒性、社会偏见和心理安全问题。目前仍然缺乏针对各种NLP任务的LLM的安全相关基准,此外在多语言环境中识别和减轻这些风险是一个重要挑战[9][10]。
总结
LLM在NLP领域的应用已经取得了显著的进展。通过对模型参数的冻结和微调,LLM能够在多种NLP任务中表现出色,如文本摘要、机器翻译和情感分析等。未来,随着多语言和多模态LLM的进一步研究,以及工具使用和优化策略的改进,我们有理由相信LLM将在NLP领域发挥更大的作用,推动该领域的发展。同时,随着研究的深入,我们也期待LLM能够在处理更复杂的NLP任务中展现出更强的能力,为人工智能技术的应用开辟新的道路。


参考资料
[1]Fajri Koto, Tilman Beck, Zeerak Talat, Iryna Gurevych, and Timothy Baldwin. 2024. Zero-shot sentiment analysis in low-resource languages using a multilingual sentiment lexicon. arXiv preprint arXiv:2402.02113.
[2] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. 2023b. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381.
[3]Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, and Jie Tang. 2023e. Cogvlm: Visual expert for pretrained language models. ArXiv.
[4]Mengkang Hu, Yao Mu, Xinmiao Yu, Mingyu Ding, Shiguang Wu, Wenqi Shao, Qiguang Chen, Bin Wang, Yu Qiao, and Ping Luo. 2023a. Tree-planner: Efficient close-loop task planning with large language models. arXiv preprint arXiv:2310.08582.
[5]Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2023c. A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432.
[6]Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199– 22213.
[7]Bin Lei, Chunhua Liao, Caiwen Ding, et al. 2023. Boosting logical reasoning in large language models through a new framework: The graph of thought. arXiv preprint arXiv:2308.08614.
[8]Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. arXiv preprint arXiv:2305.14251.
[9]Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858.
[10]Hao Sun, Zhexin Zhang, Jiawen Deng, Jiale Cheng, and Minlie Huang. 2023a. Safety assessment of chinese large language models. arXiv preprint arXiv:2304.10436.