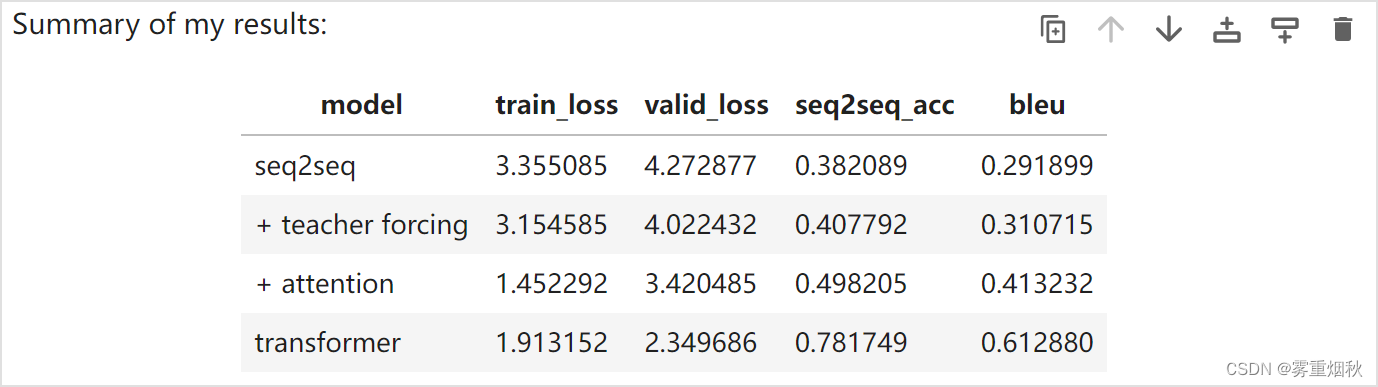
本文参考自https://github.com/fastai/course-nlp。
注意力机制和 Transformer
Nvidia AI 研究员 Chip Huyen 写了一篇很棒的文章《Top 8 trends from ICLR 2019》,其中的趋势之一是 RNN 正在失去研究人员的青睐。
这是有原因的,RNN 可能很麻烦:并行化可能很棘手,而且很难调试。 由于语言是递归的,RNN 似乎在概念上与 NLP 非常契合,但最近使用注意力的方法在 NLP 上取得了最先进的成果。
这仍然是一个非常活跃的研究领域,例如,最近的一篇论文《使用轻量级和动态卷积减少注意力》表明,卷积在某些任务上可以胜过注意力,包括英语到德语的翻译。 需要对 RNN、CNN 和 transformer/注意力的各种优势进行更多的研究,也许还需要研究如何将每种方法的优点结合起来。
from fastai.text import *
path = Config().data_path()/'giga-fren'
path.ls()
[PosixPath('/home/jhoward/.fastai/data/giga-fren/cc.en.300.bin'),
PosixPath('/home/jhoward/.fastai/data/giga-fren/data_save.pkl'),
PosixPath('/home/jhoward/.fastai/data/giga-fren/models'),
PosixPath('/home/jhoward/.fastai/data/giga-fren/giga-fren.release2.fixed.en'),
PosixPath('/home/jhoward/.fastai/data/giga-fren/giga-fren.release2.fixed.fr'),
PosixPath('/home/jhoward/.fastai/data/giga-fren/questions_easy.csv'),
PosixPath('/home/jhoward/.fastai/data/giga-fren/cc.fr.300.bin')]
加载数据
我们重复使用与翻译笔记本中相同的功能来加载我们的数据。
def seq2seq_collate(samples, pad_idx=1, pad_first=True, backwards=False):
"Function that collect samples and adds padding. Flips token order if needed"
samples = to_data(samples)
max_len_x,max_len_y = max([len(s[0]) for s in samples]),max([len(s[1]) for s in samples])
res_x = torch.zeros(len(samples), max_len_x).long() + pad_idx
res_y = torch.zeros(len(samples), max_len_y).long() + pad_idx
if backwards: pad_first = not pad_first
for i,s in enumerate(samples):
if pad_first:
res_x[i,-len(s[0]):],res_y[i,-len(s[1]):] = LongTensor(s[0]),LongTensor(s[1])
else:
res_x[i, :len(s[0])],res_y[i, :len(s[1])] = LongTensor(s[0]),LongTensor(s[1])
if backwards: res_x,res_y = res_x.flip(1),res_y.flip(1)
return res_x, res_y
class Seq2SeqDataBunch(TextDataBunch):
"Create a `TextDataBunch` suitable for training an RNN classifier."
@classmethod
def create(cls, train_ds, valid_ds, test_ds=None, path='.', bs=32, val_bs=None, pad_idx=1,
dl_tfms=None, pad_first=False, device=None, no_check=False, backwards=False, **dl_kwargs):
"Function that transform the `datasets` in a `DataBunch` for classification. Passes `**dl_kwargs` on to `DataLoader()`"
datasets = cls._init_ds(train_ds, valid_ds, test_ds)
val_bs = ifnone(val_bs, bs)
collate_fn = partial(seq2seq_collate, pad_idx=pad_idx, pad_first=pad_first, backwards=backwards)
train_sampler = SortishSampler(datasets[0].x, key=lambda t: len(datasets[0][t][0].data), bs=bs//2)
train_dl = DataLoader(datasets[0], batch_size=bs, sampler=train_sampler, drop_last=True, **dl_kwargs)
dataloaders = [train_dl]
for ds in datasets[1:]:
lengths = [len(t) for t in ds.x.items]
sampler = SortSampler(ds.x, key=lengths.__getitem__)
dataloaders.append(DataLoader(ds, batch_size=val_bs, sampler=sampler, **dl_kwargs))
return cls(*dataloaders, path=path, device=device, collate_fn=collate_fn, no_check=no_check)
class Seq2SeqTextList(TextList):
_bunch = Seq2SeqDataBunch
_label_cls = TextList
请参阅笔记本 7-seq2seq-translation,了解我们用于创建、处理和保存此数据的代码。
data = load_data(path)
data.show_batch()

Transformer 模型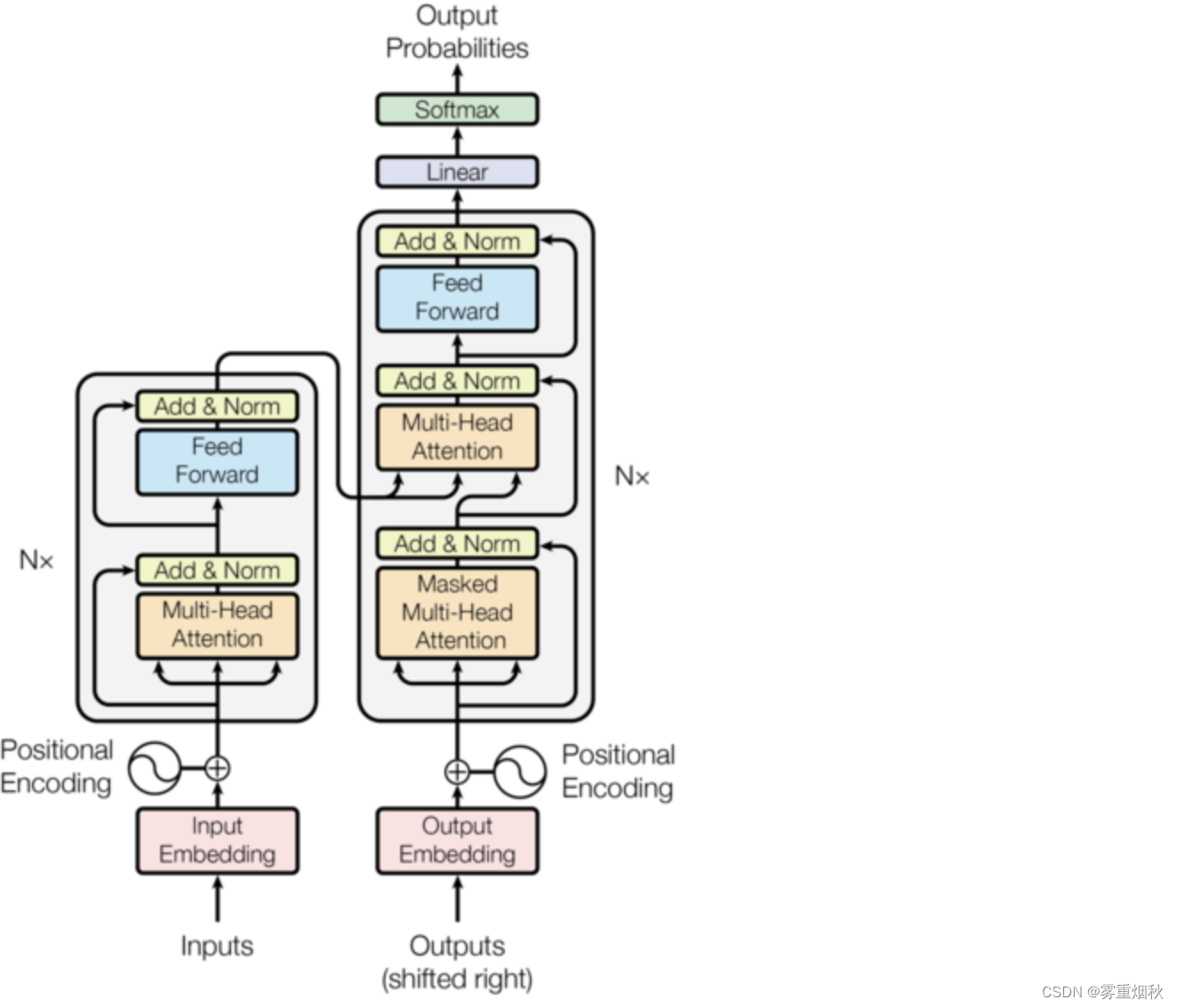
转移(Shifting)
我们向数据加载器添加一个转换,将目标向右移动并在开头添加填充。
v = data.vocab
v.stoi['xxpad']
1
def shift_tfm(b):
x,y = b
y = F.pad(y, (1, 0), value=1)
return [x,y[:,:-1]], y[:,1:]
data.add_tfm(shift_tfm)
嵌入(Embeddings)
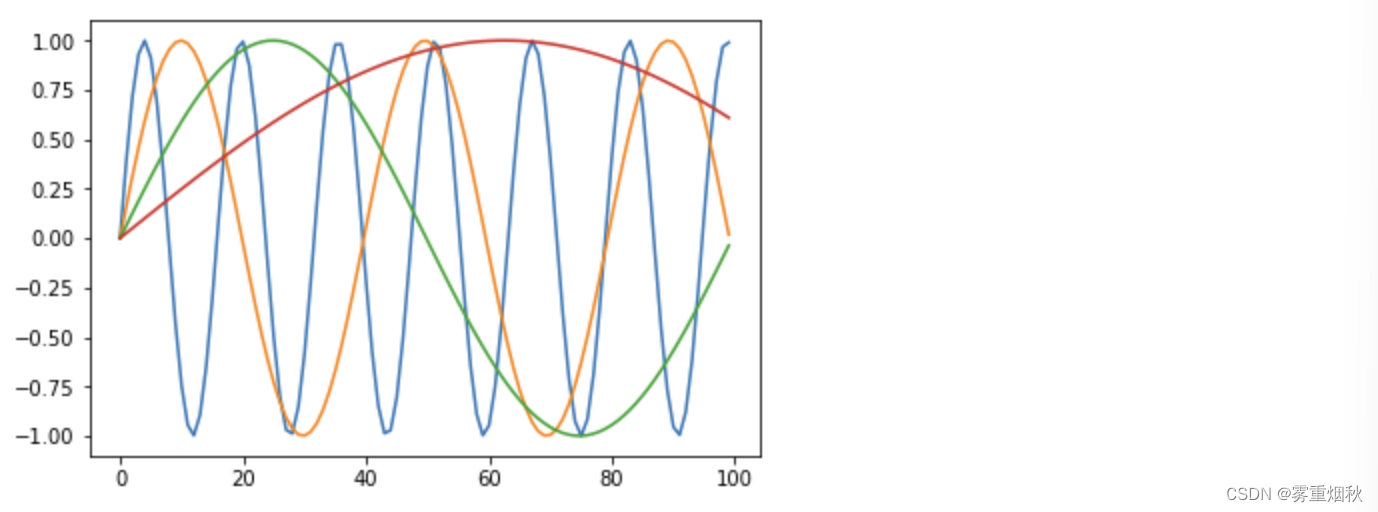
输入和输出嵌入是传统的 PyTorch 嵌入(如果需要,我们可以使用预训练向量)。Transformer 模型不是循环模型,因此它不知道单词的相对位置。为了帮助它做到这一点,他们必须对输入嵌入进行位置编码,该编码是特定频率的余弦:
d = 30
torch.arange(0., d, 2.)/d
tensor([0.0000, 0.0667, 0.1333, 0.2000, 0.2667, 0.3333, 0.4000, 0.4667, 0.5333,
0.6000, 0.6667, 0.7333, 0.8000, 0.8667, 0.9333])
class PositionalEncoding(nn.Module):
"Encode the position with a sinusoid."
def __init__(self, d):
super().__init__()
self.register_buffer('freq', 1 / (10000 ** (torch.arange(0., d, 2.)/d)))
def forward(self, pos):
inp = torch.ger(pos, self.freq)
enc = torch.cat([inp.sin(), inp.cos()], dim=-1)
return enc
tst_encoding = PositionalEncoding(20)
res = tst_encoding(torch.arange(0,100).float())
_, ax = plt.subplots(1,1)
for i in range(1,5): ax.plot(res[:,i])
res[:6,:6]

class TransformerEmbedding(nn.Module):
"Embedding + positional encoding + dropout"
def __init__(self, vocab_sz, emb_sz, inp_p=0.):
super().__init__()
self.emb_sz = emb_sz
self.embed = embedding(vocab_sz, emb_sz)
self.pos_enc = PositionalEncoding(emb_sz)
self.drop = nn.Dropout(inp_p)
def forward(self, inp):
pos = torch.arange(0, inp.size(1), device=inp.device).float()
return self.drop(self.embed(inp) * math.sqrt(self.emb_sz) + self.pos_enc(pos))
前馈(Feed forward)
前馈单元很简单:它只是两个带有跳过连接和 LayerNorm 的线性层。
def feed_forward(d_model, d_ff, ff_p=0., double_drop=True):
layers = [nn.Linear(d_model, d_ff), nn.ReLU()]
if double_drop: layers.append(nn.Dropout(ff_p))
return SequentialEx(*layers, nn.Linear(d_ff, d_model), nn.Dropout(ff_p), MergeLayer(), nn.LayerNorm(d_model))
多头注意力机制
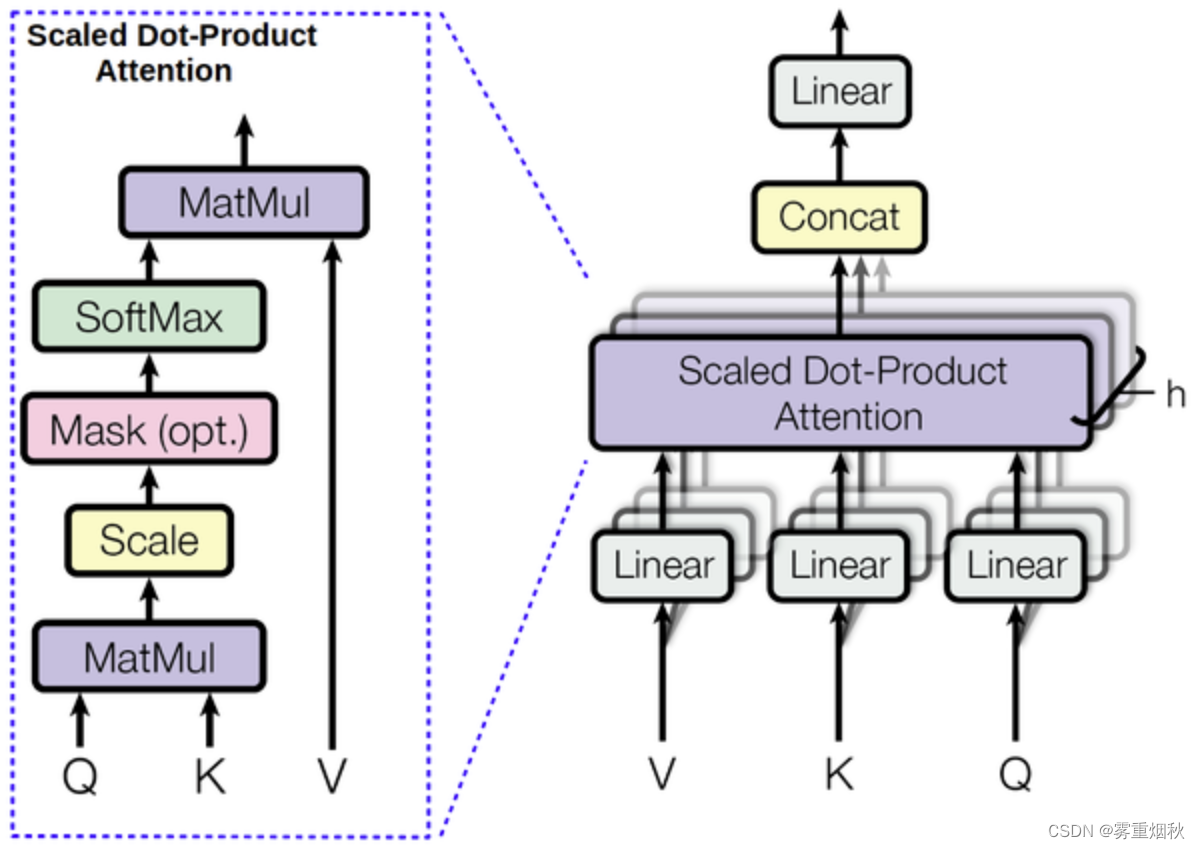
class MultiHeadAttention(nn.Module):
def __init__(self, n_heads, d_model, d_head=None, p=0., bias=True, scale=True):
super().__init__()
d_head = ifnone(d_head, d_model//n_heads)
self.n_heads,self.d_head,self.scale = n_heads,d_head,scale
self.q_wgt,self.k_wgt,self.v_wgt = [nn.Linear(
d_model, n_heads * d_head, bias=bias) for o in range(3)]
self.out = nn.Linear(n_heads * d_head, d_model, bias=bias)
self.drop_att,self.drop_res = nn.Dropout(p),nn.Dropout(p)
self.ln = nn.LayerNorm(d_model)
def forward(self, q, kv, mask=None):
return self.ln(q + self.drop_res(self.out(self._apply_attention(q, kv, mask=mask))))
def create_attn_mat(self, x, layer, bs):
return layer(x).view(bs, x.size(1), self.n_heads, self.d_head
).permute(0, 2, 1, 3)
def _apply_attention(self, q, kv, mask=None):
bs,seq_len = q.size(0),q.size(1)
wq,wk,wv = map(lambda o: self.create_attn_mat(*o,bs),
zip((q,kv,kv),(self.q_wgt,self.k_wgt,self.v_wgt)))
attn_score = wq @ wk.transpose(2,3)
if self.scale: attn_score /= math.sqrt(self.d_head)
if mask is not None:
attn_score = attn_score.float().masked_fill(mask, -float('inf')).type_as(attn_score)
attn_prob = self.drop_att(F.softmax(attn_score, dim=-1))
attn_vec = attn_prob @ wv
return attn_vec.permute(0, 2, 1, 3).contiguous().view(bs, seq_len, -1)
掩蔽(Masking)
注意层使用掩码来避免关注某些时间步骤。首先,我们并不希望网络真正关注填充,因此我们将对其进行掩码。其次,由于此模型不是循环的,因此我们需要(在输出中)掩码所有我们不应该看到的标记(否则就是作弊)。
def get_output_mask(inp, pad_idx=1):
return torch.triu(inp.new_ones(inp.size(1),inp.size(1)), diagonal=1)[None,None].byte()
# return ((inp == pad_idx)[:,None,:,None].long() + torch.triu(inp.new_ones(inp.size(1),inp.size(1)), diagonal=1)[None,None] != 0)
未来令牌的掩码示例:
torch.triu(torch.ones(10,10), diagonal=1).byte()
tensor([[0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.uint8)
编码器和解码器块
现在我们准备在模型图中添加的块中重新组合这些层:
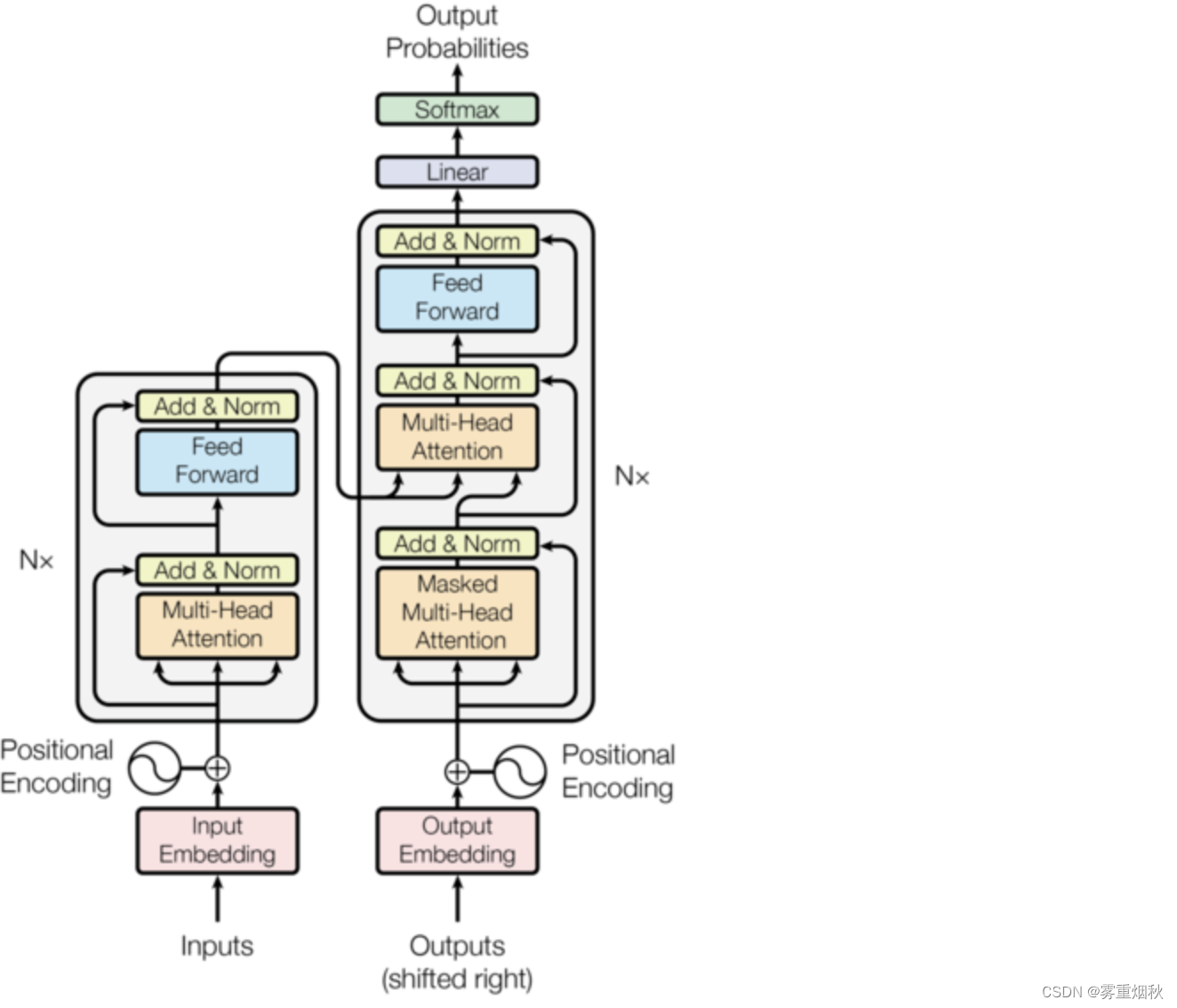
class EncoderBlock(nn.Module):
"Encoder block of a Transformer model."
#Can't use Sequential directly cause more than one input...
def __init__(self, n_heads, d_model, d_head, d_inner, p=0., bias=True, scale=True, double_drop=True):
super().__init__()
self.mha = MultiHeadAttention(n_heads, d_model, d_head, p=p, bias=bias, scale=scale)
self.ff = feed_forward(d_model, d_inner, ff_p=p, double_drop=double_drop)
def forward(self, x, mask=None): return self.ff(self.mha(x, x, mask=mask))
class DecoderBlock(nn.Module):
"Decoder block of a Transformer model."
#Can't use Sequential directly cause more than one input...
def __init__(self, n_heads, d_model, d_head, d_inner, p=0., bias=True, scale=True, double_drop=True):
super().__init__()
self.mha1 = MultiHeadAttention(n_heads, d_model, d_head, p=p, bias=bias, scale=scale)
self.mha2 = MultiHeadAttention(n_heads, d_model, d_head, p=p, bias=bias, scale=scale)
self.ff = feed_forward(d_model, d_inner, ff_p=p, double_drop=double_drop)
def forward(self, x, enc, mask_out=None): return self.ff(self.mha2(self.mha1(x, x, mask_out), enc))
整个模型
class Transformer(Module):
def __init__(self, inp_vsz, out_vsz, n_layers=6, n_heads=8, d_model=256, d_head=32,
d_inner=1024, p=0.1, bias=True, scale=True, double_drop=True, pad_idx=1):
self.enc_emb = TransformerEmbedding(inp_vsz, d_model, p)
self.dec_emb = TransformerEmbedding(out_vsz, d_model, 0.)
args = (n_heads, d_model, d_head, d_inner, p, bias, scale, double_drop)
self.encoder = nn.ModuleList([EncoderBlock(*args) for _ in range(n_layers)])
self.decoder = nn.ModuleList([DecoderBlock(*args) for _ in range(n_layers)])
self.out = nn.Linear(d_model, out_vsz)
self.out.weight = self.dec_emb.embed.weight
self.pad_idx = pad_idx
def forward(self, inp, out):
mask_out = get_output_mask(out, self.pad_idx)
enc,out = self.enc_emb(inp),self.dec_emb(out)
enc = compose(self.encoder)(enc)
out = compose(self.decoder)(out, enc, mask_out)
return self.out(out)
Bleu 度量(参见专用笔记本)
class NGram():
def __init__(self, ngram, max_n=5000): self.ngram,self.max_n = ngram,max_n
def __eq__(self, other):
if len(self.ngram) != len(other.ngram): return False
return np.all(np.array(self.ngram) == np.array(other.ngram))
def __hash__(self): return int(sum([o * self.max_n**i for i,o in enumerate(self.ngram)]))
def get_grams(x, n, max_n=5000):
return x if n==1 else [NGram(x[i:i+n], max_n=max_n) for i in range(len(x)-n+1)]
def get_correct_ngrams(pred, targ, n, max_n=5000):
pred_grams,targ_grams = get_grams(pred, n, max_n=max_n),get_grams(targ, n, max_n=max_n)
pred_cnt,targ_cnt = Counter(pred_grams),Counter(targ_grams)
return sum([min(c, targ_cnt[g]) for g,c in pred_cnt.items()]),len(pred_grams)
class CorpusBLEU(Callback):
def __init__(self, vocab_sz):
self.vocab_sz = vocab_sz
self.name = 'bleu'
def on_epoch_begin(self, **kwargs):
self.pred_len,self.targ_len,self.corrects,self.counts = 0,0,[0]*4,[0]*4
def on_batch_end(self, last_output, last_target, **kwargs):
last_output = last_output.argmax(dim=-1)
for pred,targ in zip(last_output.cpu().numpy(),last_target.cpu().numpy()):
self.pred_len += len(pred)
self.targ_len += len(targ)
for i in range(4):
c,t = get_correct_ngrams(pred, targ, i+1, max_n=self.vocab_sz)
self.corrects[i] += c
self.counts[i] += t
def on_epoch_end(self, last_metrics, **kwargs):
precs = [c/t for c,t in zip(self.corrects,self.counts)]
len_penalty = exp(1 - self.targ_len/self.pred_len) if self.pred_len < self.targ_len else 1
bleu = len_penalty * ((precs[0]*precs[1]*precs[2]*precs[3]) ** 0.25)
return add_metrics(last_metrics, bleu)
训练
n_x_vocab,n_y_vocab = len(data.train_ds.x.vocab.itos), len(data.train_ds.y.vocab.itos)
model = Transformer(n_x_vocab, n_y_vocab, d_model=256)
learn = Learner(data, model, metrics=[accuracy, CorpusBLEU(n_y_vocab)], loss_func = CrossEntropyFlat())
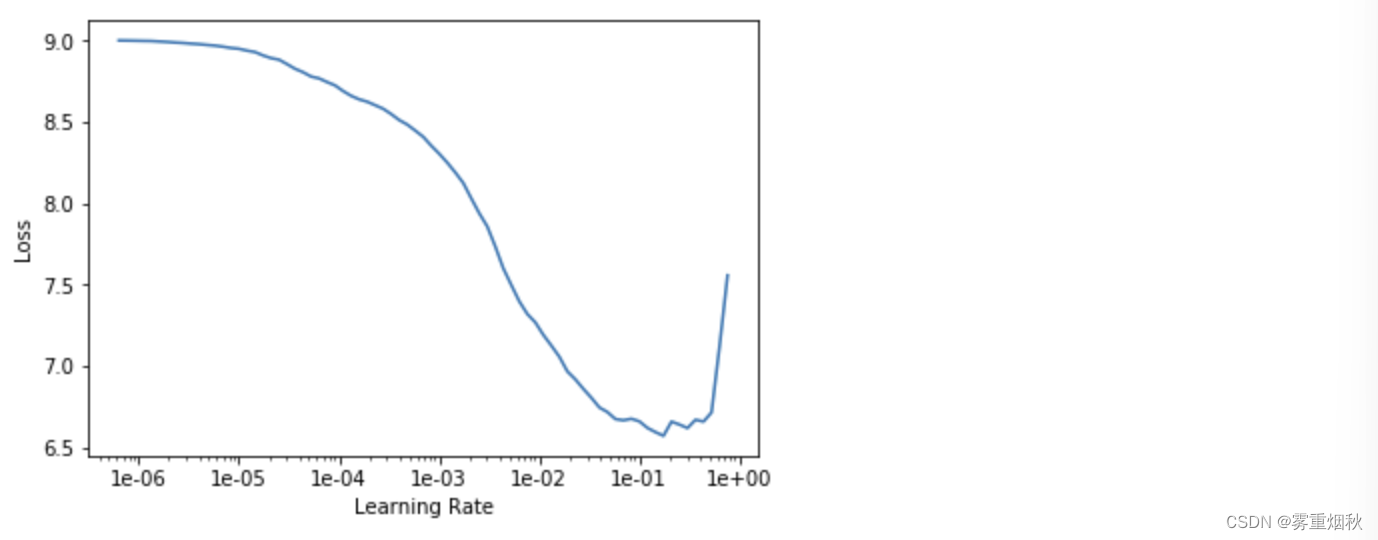
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(8, 5e-4, div_factor=5)
def get_predictions(learn, ds_type=DatasetType.Valid):
learn.model.eval()
inputs, targets, outputs = [],[],[]
with torch.no_grad():
for xb,yb in progress_bar(learn.dl(ds_type)):
out = learn.model(*xb)
for x,y,z in zip(xb[0],xb[1],out):
inputs.append(learn.data.train_ds.x.reconstruct(x))
targets.append(learn.data.train_ds.y.reconstruct(y))
outputs.append(learn.data.train_ds.y.reconstruct(z.argmax(1)))
return inputs, targets, outputs
inputs, targets, outputs = get_predictions(learn)
inputs[10],targets[10],outputs[10]
(Text xxbos xxmaj pendant que xxunk les activités requises pour maintenir mon xxunk physique , est - ce que je xxunk de la protection d’un régime d’assurance ou de pension ?,
Text xxbos xxmaj while i go about maintaining this high degree of fitness , am i protected under an insurance or pension plan ?,
Text xxbos xxmaj while i do to the my physical physical of physical , do i aware by the pension plan service plan ?)
inputs[700],targets[700],outputs[700]
(Text xxbos xxmaj quelles sont les conséquences sur la recherche , la mise en pratique et les politiques en ce qui a trait à l'ac ?,
Text xxbos xxmaj what are the xxunk for xxup kt research , practice / policy ?,
Text xxbos xxmaj what are the implications implications research kt , , policy and policies in)
inputs[701],targets[701],outputs[701]
(Text xxbos xxmaj quelle est la position des xxmaj états - xxmaj unis , du xxmaj canada et de la xxup xxunk à ce propos ?,
Text xxbos xxmaj where do the xxup us , xxmaj canada and xxup xxunk stand ?,
Text xxbos xxmaj what is xxmaj xxup us xxmaj xxmaj united and the xxunk fit in)
inputs[2500],targets[2500],outputs[2500]
(Text xxbos xxmaj quels sont les atouts particuliers du xxmaj canada en recherche sur l'obésité sur la scène internationale ?,
Text xxbos xxmaj what are the unique xxmaj canadian strengths in obesity research that set xxmaj canada apart on an international front ?,
Text xxbos xxmaj what are xxmaj specific strengths canada strengths in obesity - ? are up canada ? from international international stage ?)
inputs[4002],targets[4002],outputs[4002]
(Text xxbos xxmaj quelles sont les répercussions politiques à long terme de cette révolution scientifique mondiale ?,
Text xxbos xxmaj what are some of the long - term policy implications of this global knowledge revolution ?,
Text xxbos xxmaj what are the long the long - term policies implications of this global scientific ? ?)
标签平滑(Label smoothing)
他们在论文中指出,使用标签平滑有助于获得更好的 BLEU/准确度,即使它会使损失变得更糟。
model = Transformer(len(data.train_ds.x.vocab.itos), len(data.train_ds.y.vocab.itos), d_model=256)
learn = Learner(data, model, metrics=[accuracy, CorpusBLEU(len(data.train_ds.y.vocab.itos))],
loss_func=FlattenedLoss(LabelSmoothingCrossEntropy, axis=-1))
learn.fit_one_cycle(8, 5e-4, div_factor=5)
learn.fit_one_cycle(8, 5e-4, div_factor=5)
print("Quels sont les atouts particuliers du Canada en recherche sur l'obésité sur la scène internationale ?")
print("What are Specific strengths canada strengths in obesity - ? are up canada ? from international international stage ?")
print("Quelles sont les répercussions politiques à long terme de cette révolution scientifique mondiale ?")
print("What are the long the long - term policies implications of this global scientific ? ?")
Quels sont les atouts particuliers du Canada en recherche sur l'obésité sur la scène internationale ?
What are Specific strengths canada strengths in obesity - ? are up canada ? from international international stage ?
Quelles sont les répercussions politiques à long terme de cette révolution scientifique mondiale ?
What are the long the long - term policies implications of this global scientific ? ?
inputs[10],targets[10],outputs[10]
(Text xxbos xxmaj quelle distance y a - t - il entre le point le plus rapproché de la surface à xxunk et la position d’utilisation habituelle du tube radiogène ?,
Text xxbos xxmaj what is the distance between the nearest point of the area to be shielded and the usual operational position of the x - ray tube ?,
Text xxbos xxmaj what is the xxmaj between the xxmaj and of the xxmaj ? the ? and the most ? ? of the xxmaj - ray tube ?)
inputs[700],targets[700],outputs[700]
(Text xxbos xxmaj quels types de présentations xxmaj santé xxmaj canada xxunk - t - il dans le format ectd à compter du 1er septembre ?,
Text xxbos xxmaj what kind of submission types will xxmaj health xxmaj canada accept on xxmaj september 1 , 2004 in ectd format ?,
Text xxbos xxmaj what is of information is of be canadian xxmaj canada take ? the canadian ? , and ? the format ?)
inputs[701],targets[701],outputs[701]
(Text xxbos xxmaj quelles sont les trois caractéristiques qui vous incitent le plus à investir dans votre région ( xxup nommez - xxup les ) ?,
Text xxbos xxmaj what are the three most attractive features about investing in your region ( xxup name xxup it ) ?,
Text xxbos xxmaj what is the main main important concerns of the in the country ? xxup xxunk , xxunk ) ?)
inputs[4001],targets[4001],outputs[4001]
(Text xxbos xxmaj quelles actions avez - vous prises et quel en a été le résultat ?,
Text xxbos xxmaj what were your actions and the outcomes ?,
Text xxbos xxmaj what is the targets ? how main of)
测试泄露(Test leakage)
如果我们改变位置 n 处目标中的标记,它不应该影响之前的预测。
learn.model.eval();
xb,yb = data.one_batch(cpu=False)
inp1,out1 = xb[0][:1],xb[1][:1]
inp2,out2 = inp1.clone(),out1.clone()
out2[0,15] = 10
y1 = learn.model(inp1, out1)
y2 = learn.model(inp2, out2)
(y1[0,:15] - y2[0,:15]).abs().mean()
tensor(0., device='cuda:0', grad_fn=<MeanBackward1>)