在本地安装Pycharm之后,新建工程,在main.py中键入如下代码,即可实现Python调用excel:
import pandas as pd
sheet = pd.read_excel('test.xlsx')
data = sheet.loc[0].values
print("读取指定行的数据:\n{0}".format(data))第一次编译会有很多的报错,具体的错误不详细描述。解决的基本步骤如下:
1、安装pandas
在cmd下,运行pip install pandas
一般情况下不会出错。
2、回到Pycharm,再编译,还会报错,不能识别Pandas。
3、在Pycharm下对“设置”进行更改。
参考如下文档:关于python在cmd下pip安装的包在pycharm不可用问题的解决方法
http://t.csdnimg.cn/u0sx2
4、在cmd下安装python打包工具
pip install pyinstaller

5、在cmd下安装openpyxl
pip install openpyxl

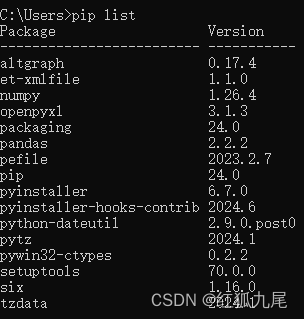
6、在cmd下,查看一下安装的包:
7、再回到Pycharm的设置页面,可以看到如下:
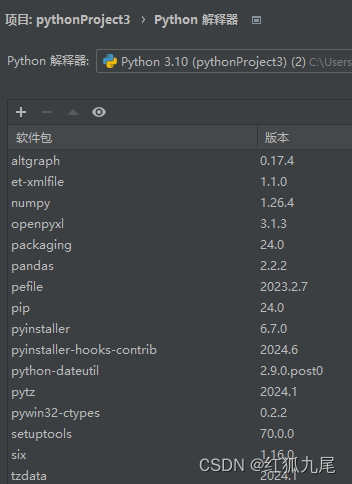
再编译即可成功。
8、创建test.xls文件
如果还出错,就是需要建立test.xlsx文件(与main.py放在同一个目录下),并在第一行填写一些数据。

执行后,可以出现如下显示:

9、附加的一些有用代码示例,包含读excel文件、写excel文件、筛选数据功能
import pandas as pd
sheet = pd.read_excel('test.xlsx')
print(sheet.loc[1])
print(sheet)
rows = {
'水果': ['苹果', '香蕉', '火龙果','山竹'],
'单价(/KG)': [25.5, 30.2, 15.8, 32],
'重量KG': [100, 85, 46, 15]
}
df = pd.DataFrame(rows)
# 将数据框架写入 Excel 文件
df.to_excel('test-out.xlsx', index=False)
#筛选数据:重量>20的数据
filtered_data = df[df['重量KG'] > 20]
print(filtered_data)