在说明静态绑定和动态绑定之前,我们首先要了解在字节码指令的层面,JVM是如何调用方法的:
例如我有以下的代码,很简单就是在main方法中调用了另一个静态方法:
public class MethodTest {
public static void main(String[] args) {
study();
}
private static void study() {
System.out.println("... study");
}
}编译成的字节码文件如下:
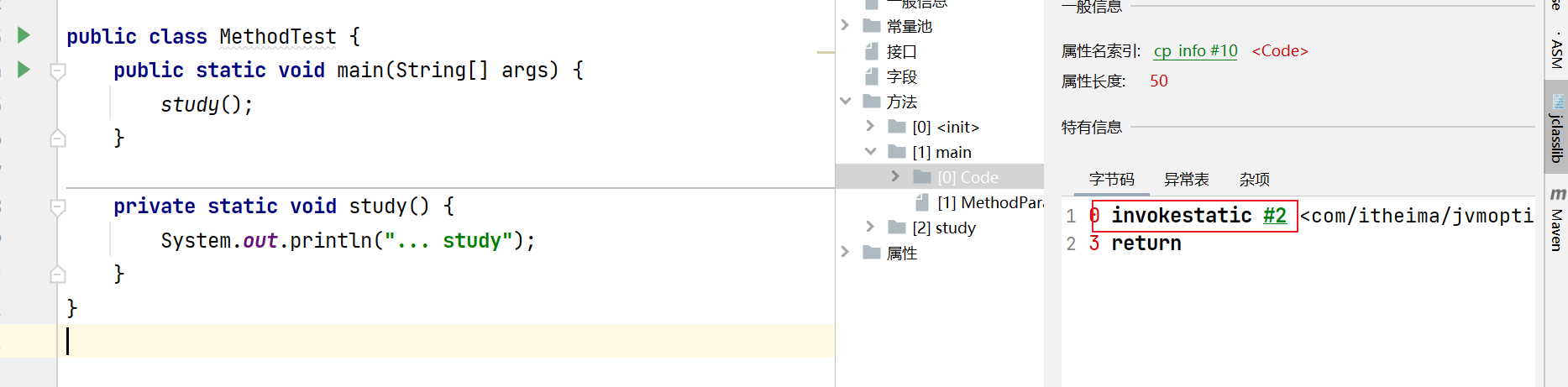
关键在于invokestatic 这个字节码指令,它的作用就是调用一个静态方法,与此类似的还有:
- invokevirtual:用于调用实例方法。
- invokespecial:用于调用私有方法,构造方法,通过super关键字调用父类的构造方法。
- invokeinterface:调用接口方法。
- invokedynamic:用于调用动态方法。
1、静态绑定
静态绑定也称为早期绑定(Early Binding)。在编译时就决定了要调用的方法,通常会发生在调用静态方法,私有方法,final方法时。
这三种方法都有一个共同点,那就是在编译期间就能被确定。
在上面的案例中,我们可以看到,编译成的字节码文件中,调用方法的关键字后跟上了一个#符号引用,它指向常量池中的方法定义:

静态绑定的情况下,符号引用是在第一次方法被调用时,替换成为直接引用。JVM会从常量池中找到编号为2的项,根据这些信息定位到实际的类和方法,将符号引用替换为直接引用。
JVM在加载类时并不会立即解析所有符号引用。相反,符号引用的解析通常发生在第一次实际使用这些引用的时候。这种机制称为延迟解析。
例如案例中study方法的解析过程:
- 首先会找到常量池中#2的元素。
- 然后会把MethodTest类加载到内存中。
- 通过符号引用中的方法名和描述符,定位到study方法。
- 将符号引用#2替换成直接指向study方法的引用。
2、动态绑定
动态绑定也称为后期绑定(Late Binding)或运行时绑定(Runtime Binding)。在运行时决定调用哪个方法。
最常见的场景是为了支持多态:当一个父类的引用变量引用子类的对象时,调用重写的方法时会在运行时决定调用子类的实现,通常发生在invokevirtual、invokeinterface字节码指令中。
而虚方法表又是实现多态的一种方式,什么是虚方法表?
在前面的文章中提到过,类在加载阶段JVM会将读取到的字节码信息保存到内存的方法区中,生成一个InstanceKlass对象,InstanceKlass对象 中就包含了虚方法表。
例如我现在有A一直到G这么多类,每个类的父类都是上一个类。如果G类需要调用A类中的方法,难道会从G一直找到A?答案是否定的。
每个类中都有一个虚方法表,记录了类中的每个方法以及方法的地址:

如果子类继承了父类,会先复制一份父类的虚方法表,然后加上自己特有的方法,如果重写了父类中的某个方法,就会在自己类的虚方法表中将父类中被重写方法的地址指向本类。(这就是为什么子类重写了父类的方法,以子类的该方法为准。)

动态绑定时,字节码指令执行的流程是,首先根据每个对象头中的元数据指针,去找到方法区中的InstanceKlass对象,然后根据虚方法表获得对应方法的地址,最后调用方法。
下面我们通过一个案例说明一下动态绑定的执行流程:
class Animal {
public void makeSound() {
System.out.println("Animal sound");
}
}
class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("Dog barks");
}
}
public class Test {
public static void main(String[] args) {
Animal a = new Dog();
a.makeSound(); // 动态绑定
}
}当a.makeSound();执行时,会执行以下的操作:
- 编译阶段:a是animal类型的引用,但是指向了Dog实例,使用invokevirtual 字节码指令去调用makeSound方法,但是此时不会去决定调用哪个实例的makeSound方法。并且此时是符号引用。
- 加载和连接阶段:JVM会加载Animal和Dog类,并进行连接,此时常量池中的符号引用被替换成了直接引用 ,但是还没有动态绑定。
- 运行时阶段:当运行到a.makeSound()时,会真正的执行invokevirtual 字节码指令,JVM会发现a的实际类型是Dog实例。会去Dog类的虚方法表查找makeSound方法。因为Dog重写了父类的makeSound方法,makeSound方法实际指向了Dog类。
- 执行方法:JVM使用方法表中的直接引用调用Dog类的makeSound方法。
Animal和Dog的虚方法表:
Animal VTable:
+-----------------+
| makeSound() -> | --> 指向 Animal::makeSound
+-----------------+Dog VTable:
+-----------------+
| makeSound() -> | --> 指向 Dog::makeSound
+-----------------+
虽然在连接阶段中的解析这一步会把符号引用替换成直接引用,但是还没有进行动态分派。需要在运行时根据对象实际的类型查询虚方法表。
3、异常捕获处理
在之前的文章中,有提到过每个方法都有其异常表,例如有一个方法:
public class ExceptionTest {
public static void main(String[] args) {
try {
int i = 0;
}catch (Exception e){
int i = 2;
}
}
}它的字节码指令:
0 iconst_0
1 istore_1
2 goto 8 (+6)
5 astore_1
6 iconst_2
7 istore_2
8 return
对应的异常表:

这个异常表中的起始PC和结束PC,表示捕获异常生效的字节码起始和结束位置。
跳转PC指的是出现异常并被捕获后,跳转到字节码指令的位置。
如果有多个catch分支捕获不同的异常呢?
public class ExceptionTest {
public static void main(String[] args) {
try {
int i = 0;
}catch (ClassCastException e){
int i = 2;
}catch (NullPointerException ex){
int i= 3;
}
}
}在异常表的层面会从上往下遍历,如果出现的异常与第一个不匹配,就会去查找第二个,第三个...

Finally代码块的处理,Finally代表无论是否出现异常,最终一定会执行的代码,那么在字节码的层面是如何进行处理的?
public class ExceptionTest {
public static void main(String[] args) {
try {
int i = 0;
}catch (ClassCastException e){
int i = 2;
}finally {
int i = 10;
}
}
}首先看一下编译后的异常表:

会发现除了catch中的ClassCastException,还多了两个any捕获类型,表示捕获所有类型的异常。
Nr.1的any,其实对应的就是try块中的代码,Nr.2的any,对应的是catch块中的代码。
实际上是把finally中的逻辑插入到了try和catch代码块中。
4、JIT即时编译
JIT(Just-In-Time)即时编译器是一种在程序运行时将Java字节码动态编译为机器码的技术,以提高程序的执行效率。
第一篇中提到过,Java语言支持跨平台特性的实现在于,Java程序在开发完成后会被编译成字节码,然后JVM会将字节码转换为具体平台的机器码进行执行。
如果有一些代码的执行频率较高,这样的代码会被称之为热点代码,会被JIT即时编译器编译成机器码的同时进行优化,保存在内存中。
在JVM中,一般有两种即时编译器:
- C1:适用于需要快速启动时间的应用,如桌面应用。它在做简单优化的同时,能快速完成编译。
- C2:适用于长时间运行的服务器端应用。它进行更多、更复杂的优化,以获得最佳性能。
通常情况下C1和C2不会单独工作,而是会协同进行,这就引出了分层编译机制:
4.1、分层编译
分层编译是JVM中一个重要的优化策略,它结合了C1和C2编译器的优点,既能实现快速启动,又能在长时间运行时提供高效的优化:
- Tier 0 - 解释执行:JVM启动时,所有方法最初都是通过解释器执行的。这允许应用程序快速启动,因为解释执行不需要任何编译时间。
- Tier 1 - 简单编译(C1 without profiling):当一个方法被调用多次,达到一定的阈值时,JVM会使用C1编译器对其进行简单的编译。这种编译会生成未经复杂优化的机器码,但执行速度比解释执行要快。
- Tier 2 - 带性能分析的编译(C1 with profiling):在这个层次上,C1编译器不仅进行编译,还会在生成的机器码中插入性能分析代码(profiling code)。这些性能分析代码会收集运行时数据,例如方法调用频率、分支预测信息和类型分布等。这些数据将用于后续更高级别的优化。
- Tier 3 - 更高级的编译(C1 with more profiling):这一层次进一步加强性能分析,同时进行更多的中等优化。
- Tier 4 - 高级编译(C2):当方法经过充分的性能分析并被标记为热点方法时,JVM会使用C2编译器对其进行高级编译。C2编译器会利用收集到的性能数据进行深入的优化,包括内联、循环优化和逃逸分析等。
由此可见在分层编译时,JVM会优先使用C1编译器为C2编译器收集信息,协同C2编译器进行编译。C1和C2一般都是用独立的线程进行处理,线程中存有队列存放需要编译的任务。
那么C1和C2是如何协同工作的?
- 启动阶段:JVM启动时,所有方法通过解释器执行(Tier 0)。这保证了应用程序能够快速启动。
- 热点探测:JVM通过计数器机制监控方法的执行频率。当某个方法调用次数达到Tier 1的阈值时,C1编译器介入,对该方法进行简单编译。
- 性能分析和优化:在Tier 2和Tier 3层次上,C1编译器插入性能分析代码,收集运行时的性能数据。JVM根据这些数据判断哪些方法应该进一步优化,并在合适的时候使用C2编译器对热点方法进行高级编译。
- 持续优化:C2编译器对方法进行高级优化,生成高效的机器码。C2编译的机器码会替换之前C1编译的机器码或解释执行的代码。如果运行时情况发生变化,例如方法的调用频率下降或性能特征改变,JVM可以重新调整编译策略,可能会回退到C1编译,甚至返回解释执行。(称之为取消优化)
4.2、方法内联
方法内联是指在编译时,将被调用的方法的代码直接插入到调用点,而不是在运行时进行方法调用。这样做可以避免参数传递,接受返回值,创建栈帧等。
例如我有以下的代码:
public int add(int a, int b) {
return a + b;
}
public int calculate() {
int x = 10;
int y = 20;
return add(x, y);
}
在没有进行内联时,调用add方法,会产生一个新的栈帧,并且需要传递参数,得到返回的结果。
而通过内联,会得到如下的效果:
public int calculate() {
int x = 10;
int y = 20;
return x + y; // add(x, y) 的内联结果
}通常内联后还会进行一次常量折叠(因为案例中x和y的值是在编译时就能确定,不会动态发生变更):
public int calculate() {
return 30; // 常量折叠后的代码
}通过上面的简单案例,我们对于什么是方法内联有了一定的认识,下面总结一下方法内联的过程:
- JIT编译器会根据一定的标准来识别哪些方法适合进行内联。这些标准包括方法的大小、调用频率、编译层次(如C1或C2编译器)和方法的特性(如是否为虚方法)。
- 一旦确定某个方法可以内联,JIT编译器会将该方法的字节码直接插入到调用点,替代原来的方法调用指令。(在代码层面,就如同上面案例将return add(x, y) 替换成return x + y)
- 在插入内联方法的代码后,JIT编译器会进行进一步的优化,例如常量折叠、消除无用代码和循环展开等,以最大限度地提高执行效率。
而需要实现方法内联,也要满足一定的条件,首先是方法的大小:IT编译器通常会设置一个方法大小的阈值,超过这个阈值的方法将不会被内联。其次是调用频率 ,经常被调用的方法更有可能被内联。以及访问修饰符 ,一般被private,final,static修饰的方法更容易被内联,因为它们的调用行为是确定的,不会被子类重写或动态绑定。(这一条不由得让我想到了曾经看到的八股文中final关键字的作用,其中就有一条被final修饰的常量会被虚拟机内联提高效率)
4.3、逃逸性分析
逃逸性分析(Escape Analysis)是JVM(Java虚拟机)JIT(Just-In-Time)编译器用来优化内存分配和垃圾回收的重要技术。通过分析对象的动态作用域,JVM可以确定哪些对象不会“逃逸”出其创建的方法或线程,从而进行进一步优化,如栈上分配和同步消除。
根据是否发生逃逸,及逃逸的范围,一般会将对象划分为以下的种类:
不逃逸:对象完全在创建它的方法内部使用,未被返回或传递给外部。
对于不逃逸的对象,JVM可以在栈上分配内存,而不是堆上。栈上分配的对象随着方法结束自动销毁,无需垃圾回收。
public class EscapeAnalysisDemo {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Test test = new Test();
System.out.println(test);
}
}
}
方法逃逸:对象作为返回值或参数传递给外部方法,但不逃逸出创建它的线程。
public class EscapeAnalysisDemo {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Test test = new Test();
method1(test);
}
}
}
线程逃逸:对象被其他线程访问,通常通过共享变量或线程间通信传递。
public class EscapeAnalysisDemo {
public static void main(String[] args) {
Test test = new Test();
new Thread(()->{
System.out.println(test);
},"t1");
}
}我们再通过另一个案例详细看下逃逸性分析的过程以及JVM做出的优化
public class Example {
public static class Point {
int x, y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
public void calculate() {
Point p = new Point(10, 20);
System.out.println(p.x + p.y);
}
public static void main(String[] args) {
Example example = new Example();
example.calculate();
}
}
JVM的JIT编译器会分析Point对象的逃逸性:
Point对象是在calculate()方法中被创建,p.x和p.y也都是发生在calculate()方法中的,Point对象没有传递给其他方法,也不会返回给其他方法。
4.3.1、栈上分配:
由于Point对象不逃逸,JVM可以选择在栈上分配Point的内存,而不是在堆上。这样,当 calculate()方法结束时,Point对象的内存会自动释放,无需垃圾回收。
4.3.2、同步消除
假设我们在calculate()方法中使用了同步代码块:
public void calculate() {
synchronized(new Point(10, 20)){
System.out.println(p.x + p.y);
}
}同步块可以被消除,因为没有其他线程会访问Point对象。
4.3.3、标量替换
JVM可以将Point对象分解为两个局部变量X和Y,避免对象的创建
public void calculate() {
int x = 10;
int y = 20;
int sum = x + y;
System.out.println(sum);
}