目录
摘要
ABSTRACT
一、文献阅读
1、相关信息
2、摘要
3、文献解读
1、Introduction
2、文章主要贡献
3、模型架构
4、实验
4、结论
二、代码实现
总结
摘要
本周我阅读了一篇题目为《Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention》的文献,该文献引入了一种浅层、轻量级的Transformer模型(SAMformer),该模型采用锐度感知优化技术。SAMformer不仅能克服不良的局部最小值,而且在各种真实世界的多变量时间序列数据集中的表现也超过了领先的TSMixer模型14.33%,同时其参数数量大约少了4倍。其次通过其代码实现,对论文中的实验部分有了更深的了解。
ABSTRACT
This week, a literature review was conducted on a paper titled "Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention". In this paper, a shallow, lightweight transformer model known as SAMformer was introduced, which is optimized using sharpness-aware techniques. The SAMformer not only overcomes poor local minima but also outperforms the leading TSMixer model by 14.33% across various real-world multivariate time series datasets, while having approximately four times fewer parameters. Furthermore, a deeper understanding of the experimental section of the paper was gained through the implementation of its code.
一、文献阅读
1、相关信息
Title:Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
期刊/会议:ICML 2024
链接:https://arxiv.org/abs/2402.10198
2、摘要
基于Transformer的模型在自然语言处理和计算机视觉中表现出色,但在多变量长期预测中的表现却不如简单的线性模型。本研究揭示了尽管Transformer的模型复杂,但在基本的线性预测场景中,它们难以达到最优解决方案,主要是因为它们的注意力机制的泛化能力较低。为了解决这个问题,我们引入了一种浅层、轻量级的Transformer模型(SAMformer),该模型采用锐度感知优化技术。SAMformer不仅能克服不良的局部最小值,而且在各种真实世界的多变量时间序列数据集中的表现也超过了领先的TSMixer模型14.33%,同时其参数数量大约少了4倍。
Transformer-based models excel in natural language processing and computer vision but underperform compared to simple linear models in multivariate long-term forecasting. This study reveals that despite their complexity, transformers struggle to reach optimal solutions in a basic linear forecasting scenario, primarily due to their attention mechanism's low generalization ability. To address this, we introduce a shallow, lightweight transformer model (SAMformer) optimized with sharpness-aware techniques. SAMformer not only overcomes poor local minima but also outperforms the leading TSMixer model by 14.33% across various real-world multivariate time series datasets, all while being significantly more parameter-efficient.
3、文献解读
1、Introduction
Transformer在处理序列数据方面表现出特别的效率,这自然促使其应用于时间序列分析。不少研究试图提出针对时间序列的特定的Transformer架构,以利用其捕捉时间交互的能力。然而,当前在多变量时间序列预测方面的最先进模型是基于简单的MLP(多层感知机)模型,它显著优于基于Transformer的方法。最近将Transformer应用于时间序列数据的研究主要集中在两个方面:一是实现高效的注意力机制,以降低其计算成本;二是分解时间序列以更好地捕捉其中的模式。本文的研究提出了一种浅层的Transformer模型,名为SAMformer,该模型采用了研究社区提出的最佳实践,包括可逆实例归一化和通道注意力。我们展示了通过使用锐度感知最小化(SAM)优化这样一个简单的Transformer,可以收敛到具有更好泛化能力的局部最小值。我们的实证结果表明,我们的方法在常见的多变量长期预测数据集上具有优越性。SAMformer在平均性能上提高了14.33%,同时参数数量大约减少了四倍。
2、文章主要贡献
1、Transformer推广不佳,收敛到尖锐的局部极小值,即使在一个简单的玩具线性预测问题,作者确定主要是注意力的原因。
2、文章提出了一个浅层Transformer模型,称为SAMformer,它结合了研究界提出的最佳实践,包括可逆实例归一化和通道注意力。文章表明,优化这样一个简单的Transformer与sharpnessware最小化(SAM)允许收敛到局部最小值,更好的推广。
3、SAMformer将当前最先进的多变量模型TSMixer平均提高了14.33%,同时参数减少了104倍。
3、模型架构
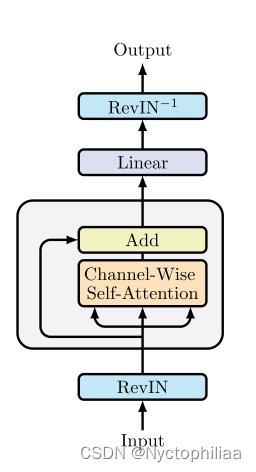
首先将可逆实例归一化(RevIN)应用于X(该技术被证明在处理时间序列中训练数据和测试数据之间的转换方面是有效的)。其次使用SAM优化模型,使其收敛到平坦的局部最小值。

4、实验
1、数据集
数据集:the 4 Electricity Transformer Temperature datasets ETTh1, ETTh2, ETTm1 and ETTm2 , Electricity, Exchange , Traffic , and Weather datasets.
数据量:4个电力变压器温度数据集ETTm1、ETTm2、ETTh1和ETTh2 包含了2016年7月至2018年7月电力变压器采集的时间序列。Electricity 包含了321个客户从2012年到2014年的用电量时间序列。Exchange 包含了1990年至2016年8个国家之间每日汇率的时间序列。Traffic包含2015年1月至2016年12月862个传感器捕获的道路占用率时间序列。Weather包含了2020年21个天气指标记录的气象信息的时间序列。
2、参数设置
对于SAMformer和Transformer,模型的维数设置为16,在我们所有的实验中保持不变,使用Adam优化器,批量大小为32,对于使用SAM训练的SAMformer和TSMixer,使用的邻域大小ρ*值如表3所示。ETT数据集的训练/验证/测试分割为12/4/4个月,其他数据集为70%/20%/10%。我们使用回看窗口L = 512,并使用步幅为1的滑动窗口来创建序列。训练损失是多元时间序列上的MSE。训练在300个epoch中进行,我们使用提前停止,patience为5个epoch。对于每个数据集、基线和预测水平H∈{96,192,336,720},每个实验用不同的种子运行5次,我们显示5次试验的测试MSE和MAE的平均值和标准差。
3、实验结果

在SAMformer的训练中引入SAM,使其损耗比Transformer更平滑。我们在上图a中通过比较
在ETTh1和Exchange上训练后Transformer和SAMformer的值来说明这一点。我们的观察表明,Transformer表现出相当高的清晰度,而SAMformer有一个理想的行为,损失景观清晰度是一个数量级小。
SAMformer演示了针对随机初始化的反业务。图5b - 1给出了SAMformer和Transformer在ETTh1
和Exchange上5种不同种子的试验MSE分布,预测水平为H = 96。SAMformer在不同的种子选择中始终保持性能稳定性,而Transformer表现出显著的差异,因此高度依赖于权重初始化。
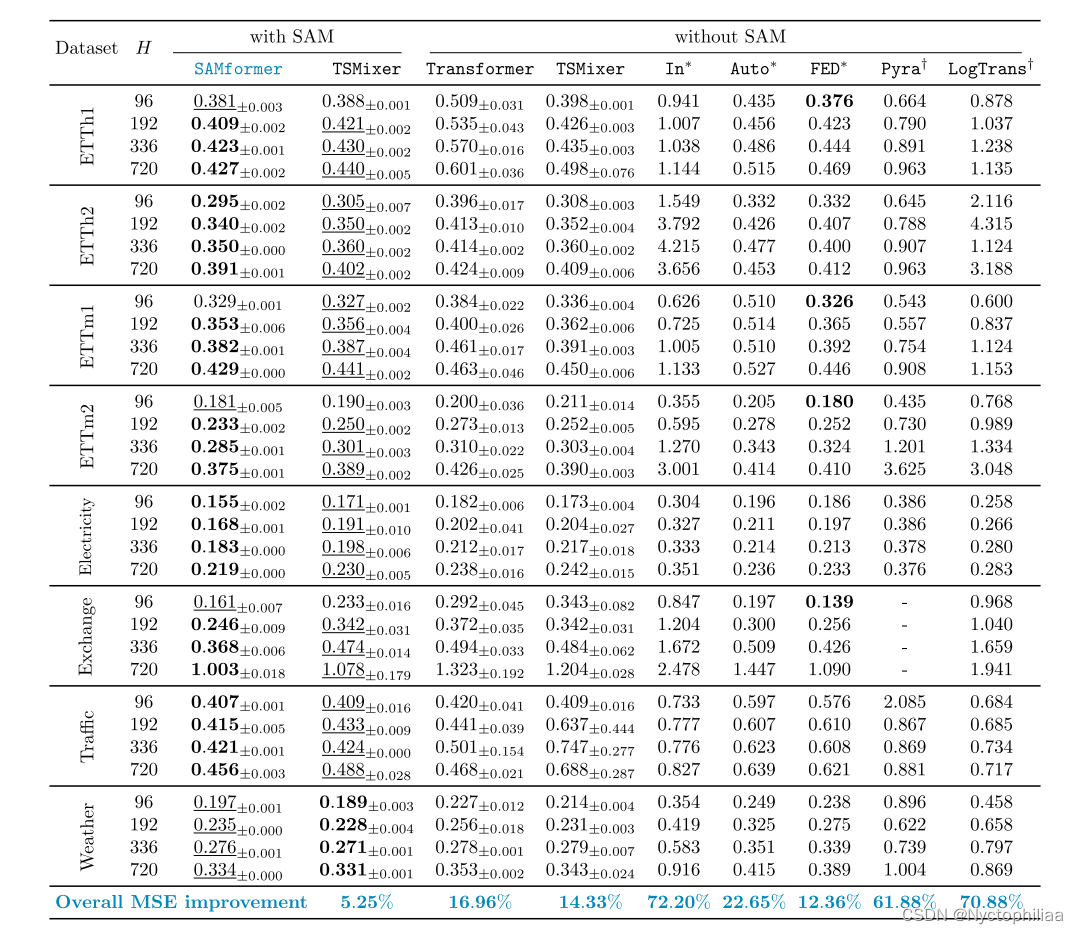
SAMformer在8个数据集中的7个上明显优于其竞争对手。特别是,它比其最
佳竞争对手TSMixer+SAM提高了5.25%,比独立TSMixer提高了14.33%,比基于变压器的最佳模型FEDformer提高了12.36%。此外,它比Transformer提高了16.96%。对于每个数据集和视界,SAMformer被排名第一或第二。值得注意的是,SAM的集成提高了TSMixer的泛化能力,平均提高了9.58%。
4、结论
作者提出的SAMformer,通过锐度感知最小化优化,与现有的预测基线相比,可以获得显着的性能提升,并受益于跨数据集和预测范围的高通用性和鲁棒性。在时间序列预测中,channel-wise attention比以前常用的temporal attention在计算和性能方面都更有效。我们相信这一令人惊讶的发现可能会在我们的简单架构之上激发许多进一步的工作,以进一步改进它。
二、代码实现
1、attention实现
这段代码定义了一个使用PyTorch库的函数,实现了缩放点积注意力机制,用于模型中的注意力计算。它接受查询(query)、键(key)和值(value)张量,并可选地接受注意力掩码和丢失概率参数。函数首先计算查询和键的点积,并根据查询的维度大小进行缩放。如果指定了因果关系或提供了注意力掩码,它会修改注意力权重以避免未来信息的泄露或应用额外的掩码。最后,它使用Softmax函数规范化注意力权重,并通过点积操作与值张量结合,输出最终的注意力加权结果。
import torch
import numpy as np
def scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False, scale=None):
"""
A copy-paste from https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html
"""
L, S = query.size(-2), key.size(-2)
scale_factor = 1 / np.sqrt(query.size(-1)) if scale is None else scale
attn_bias = torch.zeros(L, S, dtype=query.dtype, device=query.device)
if is_causal:
assert attn_mask is None
temp_mask = torch.ones(L, S, dtype=torch.bool, device=query.device).tril(diagonal=0)
attn_bias.masked_fill_(temp_mask.logical_not(), float("-inf"))
attn_bias.to(query.dtype)
if attn_mask is not None:
if attn_mask.dtype == torch.bool:
attn_bias.masked_fill_(attn_mask.logical_not(), float("-inf"))
else:
attn_bias += attn_mask
attn_weight = query @ key.transpose(-2, -1) * scale_factor
attn_weight += attn_bias
attn_weight = torch.softmax(attn_weight, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value
2、dataset处理
这段代码定义了一个Python类 LabeledDataset,它是一个继承自 torch.utils.data.Dataset 的自定义数据集类,用于处理带有标签的数据。该类的主要作用是将 NumPy 数组格式的数据和标签转换为 PyTorch 张量格式,并提供了一些基本的数据处理方法,使其可以用于 PyTorch 的数据加载和预处理流程中。
import torch
from torch.utils.data import Dataset
class LabeledDataset(Dataset):
def __init__(self, x, y):
"""
Converts numpy data to a torch dataset
Args:
x (np.array): data matrix
y (np.array): class labels
"""
self.x = torch.FloatTensor(x)
self.y = torch.FloatTensor(y)
def transform(self, x):
return torch.FloatTensor(x)
def __len__(self):
return self.y.shape[0]
def __getitem__(self, idx):
examples = self.x[idx]
labels = self.y[idx]
return examples, labels3、Revin
这段代码定义了一个名为 RevIN(Reversible Instance Normalization)的 Python 类,它继承自 PyTorch 的 nn.Module。这个类实现了可逆的实例归一化,主要用于神经网络中,可以在正向传播时进行标准化,并在需要时进行反向去标准化。
import torch
import torch.nn as nn
class RevIN(nn.Module):
"""
Reversible Instance Normalization (RevIN) https://openreview.net/pdf?id=cGDAkQo1C0p
https://github.com/ts-kim/RevIN
"""
def __init__(self, num_features: int, eps=1e-5, affine=True):
"""
:param num_features: the number of features or channels
:param eps: a value added for numerical stability
:param affine: if True, RevIN has learnable affine parameters
"""
super(RevIN, self).__init__()
self.num_features = num_features
self.eps = eps
self.affine = affine
if self.affine:
self._init_params()
def forward(self, x, mode:str):
if mode == 'norm':
self._get_statistics(x)
x = self._normalize(x)
elif mode == 'denorm':
x = self._denormalize(x)
else: raise NotImplementedError
return x
def _init_params(self):
# initialize RevIN params: (C,)
self.affine_weight = nn.Parameter(torch.ones(self.num_features))
self.affine_bias = nn.Parameter(torch.zeros(self.num_features))
def _get_statistics(self, x):
dim2reduce = tuple(range(1, x.ndim-1))
self.mean = torch.mean(x, dim=dim2reduce, keepdim=True).detach()
self.stdev = torch.sqrt(torch.var(x, dim=dim2reduce, keepdim=True, unbiased=False) + self.eps).detach()
def _normalize(self, x):
x = x - self.mean
x = x / self.stdev
if self.affine:
x = x * self.affine_weight
x = x + self.affine_bias
return x
def _denormalize(self, x):
if self.affine:
x = x - self.affine_bias
x = x / (self.affine_weight + self.eps*self.eps)
x = x * self.stdev
x = x + self.mean
return x4、sam
这段代码定义了一个名为 SAM 的 Python 类,它是一个用于优化神经网络训练的自定义优化器,继承自 PyTorch 的 Optimizer。SAM 代表 Sharpness-Aware Minimization,这是一种用于改进模型泛化能力的优化技术,通过最小化损失函数的锐度来实现。
import torch
from torch.optim import Optimizer
class SAM(Optimizer):
"""
SAM: Sharpness-Aware Minimization for Efficiently Improving Generalization https://arxiv.org/abs/2010.01412
https://github.com/davda54/sam
"""
def __init__(self, params, base_optimizer, rho=0.05, adaptive=False, **kwargs):
assert rho >= 0.0, f"Invalid rho, should be non-negative: {rho}"
defaults = dict(rho=rho, adaptive=adaptive, **kwargs)
super(SAM, self).__init__(params, defaults)
self.base_optimizer = base_optimizer(self.param_groups, **kwargs)
self.param_groups = self.base_optimizer.param_groups
@torch.no_grad()
def first_step(self, zero_grad=False):
grad_norm = self._grad_norm()
for group in self.param_groups:
scale = group["rho"] / (grad_norm + 1e-12)
for p in group["params"]:
if p.grad is None:
continue
e_w = (
(torch.pow(p, 2) if group["adaptive"] else 1.0)
* p.grad
* scale.to(p)
)
p.add_(e_w) # climb to the local maximum "w + e(w)"
self.state[p]["e_w"] = e_w
if zero_grad:
self.zero_grad()
@torch.no_grad()
def second_step(self, zero_grad=False):
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
p.sub_(self.state[p]["e_w"]) # get back to "w" from "w + e(w)"
self.base_optimizer.step() # do the actual "sharpness-aware" update
if zero_grad:
self.zero_grad()
@torch.no_grad()
def step(self, closure=None):
assert (
closure is not None
), "Sharpness Aware Minimization requires closure, but it was not provided"
closure = torch.enable_grad()(
closure
) # the closure should do a full forward-backward pass
self.first_step(zero_grad=True)
closure()
self.second_step()
def _grad_norm(self):
shared_device = self.param_groups[0]["params"][
0
].device # put everything on the same device, in case of model parallelism
norm = torch.norm(
torch.stack(
[
((torch.abs(p) if group["adaptive"] else 1.0) * p.grad)
.norm(p=2)
.to(shared_device)
for group in self.param_groups
for p in group["params"]
if p.grad is not None
]
),
p=2,
)
return norm
5、samformer
这段代码定义了两个主要的 Python 类,SAMFormerArchitecture 和 SAMFormer,它们基于 PyTorch 框架用于构建和训练一个深度学习模型,具体是用于时间序列预测任务。这些类利用了一些先进的技术如可逆实例归一化(RevIN)、注意力机制和锐度感知最小化(SAM)来改善模型的预测性能和泛化能力。
import torch
import random
import numpy as np
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from .utils.attention import scaled_dot_product_attention
from .utils.dataset import LabeledDataset
from .utils.revin import RevIN
from .utils.sam import SAM
class SAMFormerArchitecture(nn.Module):
def __init__(self, num_channels, seq_len, hid_dim, pred_horizon, use_revin=True):
super().__init__()
self.revin = RevIN(num_features=num_channels)
self.compute_keys = nn.Linear(seq_len, hid_dim)
self.compute_queries = nn.Linear(seq_len, hid_dim)
self.compute_values = nn.Linear(seq_len, seq_len)
self.linear_forecaster = nn.Linear(seq_len, pred_horizon)
self.use_revin = use_revin
def forward(self, x):
# RevIN Normalization
if self.use_revin:
x_norm = self.revin(x.transpose(1, 2), mode='norm').transpose(1, 2) # (n, D, L)
else:
x_norm = x
# Channel-Wise Attention
queries = self.compute_queries(x_norm) # (n, D, hid_dim)
keys = self.compute_keys(x_norm) # (n, D, hid_dim)
values = self.compute_values(x_norm) # (n, D, L)
if hasattr(nn.functional, 'scaled_dot_product_attention'):
att_score = nn.functional.scaled_dot_product_attention(queries, keys, values) # (n, D, L)
else:
att_score = scaled_dot_product_attention(queries, keys, values) # (n, D, L)
out = x_norm + att_score # (n, D, L)
# Linear Forecasting
out = self.linear_forecaster(out) # (n, D, H)
# RevIN Denormalization
if self.use_revin:
out = self.revin(out.transpose(1, 2), mode='denorm').transpose(1, 2) # (n, D, H)
return out.reshape([out.shape[0], out.shape[1]*out.shape[2]])
class SAMFormer:
"""
SAMFormer pytorch trainer implemented in the sklearn fashion
"""
def __init__(self, device='cuda:0', num_epochs=100, batch_size=256, base_optimizer=torch.optim.Adam,
learning_rate=1e-3, weight_decay=1e-5, rho=0.5, use_revin=True, random_state=None):
self.network = None
self.criterion = nn.MSELoss()
self.device = device
self.num_epochs = num_epochs
self.batch_size = batch_size
self.base_optimizer = base_optimizer
self.learning_rate = learning_rate
self.weight_decay = weight_decay
self.rho = rho
self.use_revin = use_revin
self.random_state = random_state
def fit(self, x, y):
if self.random_state is not None:
torch.manual_seed(self.random_state)
random.seed(self.random_state)
np.random.seed(self.random_state)
torch.cuda.manual_seed_all(self.random_state)
self.network = SAMFormerArchitecture(num_channels=x.shape[1], seq_len=x.shape[2], hid_dim=16,
pred_horizon=y.shape[1] // x.shape[1], use_revin=self.use_revin)
self.criterion = self.criterion.to(self.device)
self.network = self.network.to(self.device)
self.network.train()
optimizer = SAM(self.network.parameters(), base_optimizer=self.base_optimizer, rho=self.rho,
lr=self.learning_rate, weight_decay=self.weight_decay)
train_dataset = LabeledDataset(x, y)
data_loader_train = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True)
progress_bar = tqdm(range(self.num_epochs))
for epoch in progress_bar:
loss_list = []
for (x_batch, y_batch) in data_loader_train:
x_batch = x_batch.to(self.device)
y_batch = y_batch.to(self.device)
# =============== forward ===============
out_batch = self.network(x_batch)
loss = self.criterion(out_batch, y_batch)
# =============== backward ===============
if optimizer.__class__.__name__ == 'SAM':
loss.backward()
optimizer.first_step(zero_grad=True)
out_batch = self.network(x_batch)
loss = self.criterion(out_batch, y_batch)
loss.backward()
optimizer.second_step(zero_grad=True)
else:
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss.item())
# =============== save model / update log ===============
train_loss = np.mean(loss_list)
self.network.train()
progress_bar.set_description("Epoch {:d}: Train Loss {:.4f}".format(epoch, train_loss), refresh=True)
return
def forecast(self, x, batch_size=256):
self.network.eval()
dataset = torch.utils.data.TensorDataset(torch.tensor(x, dtype=torch.float))
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
outs = []
for _, batch in enumerate(dataloader):
x = batch[0].to(self.device)
with torch.no_grad():
out = self.network(x)
outs.append(out.cpu())
outs = torch.cat(outs)
return outs.cpu().numpy()
def predict(self, x, batch_size=256):
return self.forecast(x, batch_size=batch_size)总结
本文讨论了在时间序列预测中运用转换器模型的挑战与创新。传统的基于Transformer的模型虽然在自然语言处理和计算机视觉领域表现出色,但在多变量长期预测任务上,它们的性能却不及简单的线性模型。研究中指出,这些模型在基本的线性预测场景中难以实现最佳解决方案,主要问题在于其注意力机制的泛化能力较差。为应对这一问题,研究提出了一种新型的浅层、轻量级Transformer模型,即SAMformer。该模型采用锐度感知优化(SAM),有效克服了不良的局部最小值,显著提高了模型在多变量时间序列数据集上的性能,性能提升幅度达14.33%,且模型的参数数量大约减少了四倍。此外,SAMformer展示了优越的泛化能力和鲁棒性,其在多个数据集上的表现均优于当前先进的多变量模型TSMixer。研究结果表明,采用channel-wise注意力机制的SAMformer在计算和性能方面都比传统的temporal attention更为有效,为时间序列预测领域提供了新的视角和方法。