提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、引言
- 二、文献综述
- 1. Text-prompted Object Detection
- 2. Visual-prompted Object Detection
- 3. Interactive Object Detection
- 三、模型方法
- 1. Visual-Text Promptable Object Detection
- Image Encoder
- Visual Prompt Encoder
- Text Prompt Encoder
- Box Decoder
- 2. Region-Level Contrastive Alignment
- 额外解释InfoNCE loss(非论文内容)
- 3. Training Strategy and Objective
- Visual prompt training strategy
- Text prompt training strategy
- Training objective
- 四、实验
前言
我们呈现了 T-Rex2,一个高度实用的开放式目标检测模型。先前依赖于文本提示的开放式目标检测方法有效地概括了常见对象的抽象概念,但由于数据稀缺和描述限制,对于罕见或复杂的对象表示而言表现不佳。相反,视觉提示在通过具体的视觉示例描绘新对象方面表现出色,但在传达对象的抽象概念方面不如文本提示那样有效。鉴于文本提示和视觉提示的互补优势和劣势,我们引入了 T-Rex2,通过对比学习将两种提示融合到一个单一模型中。T-Rex2 可以接受多种格式的输入,包括文本提示、视觉提示以及两者的组合,因此可以通过在两种提示模态之间切换来处理不同的场景。全面的实验表明,T-Rex2 在各种场景中展现出了出色的zero-shot目标检测能力。我们展示了文本提示和视觉提示在协同作用中可以互相受益,这对覆盖庞大且复杂的现实场景至关重要,并为通用目标检测铺平了道路。
论文地址:https://arxiv.org/pdf/2403.14610
代码地址:https://github.com/IDEA-Research/T-Rex
一、引言
Object detection, a foundational pillar of computer vision,aims to locate and identify objects within an image. Traditionally, object detection was operated within a closed-setparadigm [1, 6, 16, 21, 23, 34, 35, 42, 49, 53, 55], whereina predefined set of categories is known a prior, and the system is trained to recognize and detect objects from this set.Yet the ever-changing and unforeseeable nature of the real world demands a shift in object detection methodologies towards an open-set paradigm.
目标检测,作为计算机视觉的基础支柱,旨在通过图像定位和识别对象。传统上,目标检测在封闭集范式内运行[1, 6, 16, 21, 23, 34, 35, 42, 49, 53, 55], ,即已知一组预定义的类别,并且系统经过训练以识别和检测来自该集合的目标。然而,现实世界不断变化和不可预见的特性要求目标检测方法向开放集范式转变。
Open-set object detection represents a significant paradigm shift, transcending the limitations of closed-set detection by empowering models to identify objects beyond a predetermined set of categories. A prevalent approach is to use text prompts for open-vocabulary object detection [5, 7, 11, 19, 24, 28, 54]. This approach typically involves distilling knowledge from language models like CLIP [32] or BERT [3] to align textual descriptions with visual representations.
开放集目标检测代表着一个重要的范式转变,通过增强模型能力识别预定类别范围外的目标的能力,超越了封闭集检测的限制。一种主流方法是对open-vocabulary使用文本提示的目标检测[5, 7, 11, 19, 24, 28, 54]。这种方法通常涉及从诸如CLIP或BERT之类的语言模型中提炼知识,以使文本描述与视觉表征相一致。
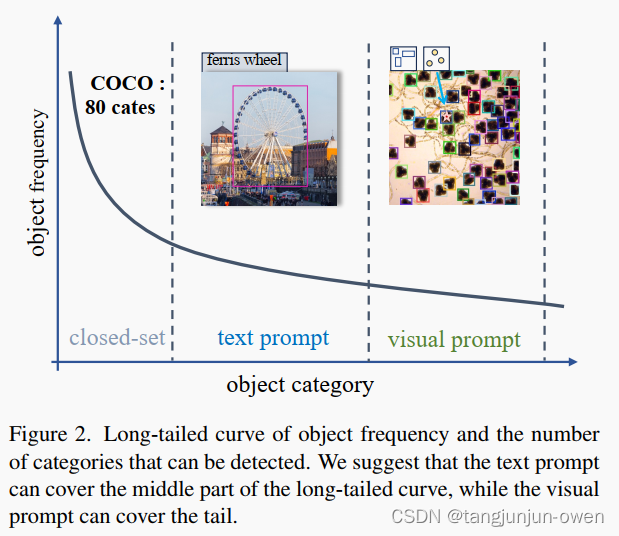
While using text prompts has been predominantly favored in open-set detection for their capacity to abstractly describe objects, it still faces the following limitations. 1) Long-tailed data shortage. The training of text prompts necessitates modality alignment between visual representations, however, the scarcity of data for long-tailed objects may impair the learning efficiency. As depicted in Fig. 2, the distribution of objects inherently follows a long-tail pattern, i.e., as the variety of detectable objects increases, the available data for these objects becomes increasingly scarce. This data scarcity may undermine the capacity of models to identify rare or novel objects. 2) Descriptive limitations. Text prompts also fall short of accurately depicting objects that are hard to describe in language. For instance, as shown in Fig. 2, while a text prompt may effectively describe ferris wheel, it may struggle to accurately represent the microorganisms in the microscope image without biological knowledge.
虽然文本提示在开放集检测中被广泛青睐,因为它们具有抽象描述对象的能力,但仍面临以下限制。1) 长尾数据短缺。文本提示的训练需要视觉表征之间的模态校准,然而,长尾目标数据的稀缺可能影响学习效率。正如图2所示,对象的分布固有地遵循长尾模式,即随着可检测对象的种类增加,这些对象的可用数据变得越来越稀缺。这种数据稀缺可能削弱模型识别罕见或新颖目标的能力。2) 描述性限制。文本提示也难以准确描述语言难以描述的目标。例如,如图2所示,虽然文本提示可以有效地描述摩天轮,但在没有生物知识的情况下,可能很难准确表示显微镜图像中的微生物。
Conversely, visual prompts [10, 12, 17, 18, 44, 56] provide a more intuitive and direct method to represent objects by providing visual examples. For example, users can use points or boxes to mark the object for detection, even if they do not know what the object is. Additionally, visual prompts are not constrained by the need for cross-modal alignment, since they rely on visual similarity rather than linguistic correlation, enabling their application to novel objects that are not encountered during training.
相反,视觉提示[10, 12, 17, 18, 44, 56] 提供了一种更直观、更直接的方法来表示目标,通过提供视觉示例来实现。例如,用户可以使用点或框来标记要检测的目标,即使他们不知道目标是什么。此外,视觉提示不受跨模态对齐的限制,因为它们依赖于视觉相似性而不是语言相关性,从而使其能够应用于训练过程中未遇到的新颖目标。
Nonetheless, visual prompts also exhibit limitations, as they are less effective at capturing the general concept of objects compared to text prompts. For instance, the term dog as a text prompt broadly covers all dog varieties. In contrast, visual prompts, given the vast diversity in dog breeds, sizes, and colors, would necessitate a comprehensive image collection to visually convey the abstract notion of dog.
然而,视觉提示也存在局限性,因为它们在捕捉目标的一般概念方面不如文本提示有效。例如,作为文本提示,术语“狗”广泛涵盖所有狗品种。相比之下,由于狗品种、大小和颜色多样性巨大,视觉提示需要收集大量图像以视觉传达“狗”的抽象概念。
Recognizing the complementary strengths and weaknesses of both text and visual prompts, we introduce TRex2, a generic open-set object detection model that integrates both modalities. T-Rex2 is built upon the DETR [1] architecture which is an end-to-end object detection model. It incorporates two parallel encoders to encode both text and visual prompts. For text prompts, we utilize the text encoder of CLIP [32] to encode input text into text embedding. For visual prompts, we introduce a novel visual prompt encoder equipped with the deformable attention [55] that can transform the input visual prompts (points or boxes) on a single image or across multiple images into visual prompt embeddings. To facilitate the collaboration of these two prompt modalities, we propose a contrastive learning [9, 32] module that can explicitly align text prompts and visual prompts. During the alignment, visual prompts can benefit from the generality and abstraction capabilities inherent in text prompts. Conversely, text prompts can enhance their descriptive capabilities by looking at various visual prompts. This iterative interaction allows both visual and text prompts to evolve continuously, thereby improving their ability for generic understanding within one model.
鉴于文本和视觉提示各自的优势和劣势,我们引入了TRex2,一个整合了两种模态的通用开集目标检测模型。T-Rex2建立在DETRE[1]架构之上,这是一个端到端目标检测模型。它包括两个并行编码器,用于编码文本和视觉提示。对于文本提示,我们利用CLIP的文本编码器将输入文本编码为文本嵌入。对于视觉提示,我们引入了一个新颖的视觉提示编码器,配备了可变形注意机制,可以将单个图像或多个图像上的输入视觉提示(点或框)转换为视觉提示嵌入。为促进这两种提示模态的协作,我们提出了一个对比学习模块,可以明确地对齐文本提示和视觉提示。在对齐过程中,视觉提示可以受益于文本提示固有的一般性和抽象能力。相反,文本提示可以通过查看各种视觉提示来增强其描述能力。这种迭代交互允许视觉和文本提示持续演变,从而提高它们在一个模型内进行通用理解的能力。
T-Rex2 supports four unique workflows that can be applied to various scenarios: 1) interactive visual prompt workflow, allowing users to specify the object to be detected by given visual example through box or point on the current image; 2) generic visual prompt workflow, permitting users to define a specific object across multiple images through visual prompts, thereby creating a universal visual embedding applicable to other images; 3) text prompt workflow, enabling users to employ descriptive text for openv ocabulary object detection; 4) mix prompt workflow, which combines both text and visual prompts for joint inference.
T-Rex2支持四种可应用于各种场景的独特工作流程:1) 交互式视觉提示工作流程,允许用户通过在当前图像上通过框或点指定要检测的目标;2) 通用视觉提示工作流程,允许用户通过视觉提示在多个图像上定义具体检测目标,从而创建适用于其他图像的通用视觉embedding;3) 文本提示工作流程,使用户能够使用描述性文本进行开放词汇目标检测;4) 混合提示工作流程,结合了文本和视觉提示进行联合推断。
T-Rex2 demonstrates strong object detection capabilities and achieves remarkable results on COCO [20], LVIS [8], ODinW [15] and Roboflow100 [2], all under zero-shot setting. Through our analysis, we observe that text and visual prompts serve complementary roles, each excelling in scenarios where the other may not be as effective. Specifically, text prompts are particularly good at recognizing common objects, while visual prompts excel in rare objects or scenarios that may not be easily described through language. This complementary relationship enables the model to perform effectively across a wide range of scenarios. To summarize,our contributions are threefold:
• We propose an open-set object detection model T-Rex2 that unifies text and visual prompts within one framework, which demonstrates strong zero-shot capabilities across various scenarios.
• We propose a contrastive learning module to explicitly align text and visual prompts, which leads to mutual enhancement of these two modalities.
• Extensive experiments demonstrate the benefits of unifying text and visual prompts within one model. We also reveal that each type of prompt can cover different scenarios, which collectively show promise in advancing toward general object detection.
T-Rex2展示了强大的目标检测能力,并在COCO、LVIS、ODinW和Roboflow100等数据集上取得了显著的成果,都是在零样本设置下。通过我们的分析,我们观察到文本和视觉提示发挥着互补的作用,每种在另一种可能不太有效的场景中表现出色。具体而言,文本提示在识别常见对象方面特别出色,而视觉提示在罕见对象或通过语言难以描述的场景中表现优异。这种互补关系使模型能够有效地在各种场景下发挥作用。总结我们的贡献有三个方面:
• 我们提出了一个开放集目标检测模型T-Rex2,将文本和视觉提示统一到一个框架中,展现了在各种场景下强大的零样本能力。
• 我们提出了对比学习模块,明确地对齐文本和视觉提示,从而促进这两种模态的相互增强。
• 大量实验证明了在一个模型中统一文本和视觉提示的好处。我们还揭示了每种提示类型可以涵盖不同的场景,这共同展示了向通用目标检测的进展前景。
二、文献综述
1. Text-prompted Object Detection
Remarkable progress has been achieved in text-prompted object detection [7, 11, 19, 24, 28, 48, 50, 52], which demonstrate impressive zero-shot and few-shot recognition capabilities. These models are typically built upon a pre-trained text encoder like CLIP [32] and BERT [3]. GLIP [19] proposes to formulate object detection as grounding problems, which unifies different data formats to align different modalities and expand detection vocabulary. Following GLIP, Grounding DINO [24] improves the vision-language alignment by fusing different modalities in the early phase. DetCLIP [46] and RegionCLIP [52] leverages image-text pairs with pseudo boxes to expand region knowledge for more generalized object detection.
在文本提示的目标检测领域[7, 11, 19, 24, 28, 48, 50, 52]取得了显著进展,展示出令人印象深刻的零样本和少样本识别能力。这些模型典型的基于预训练的文本编码器,如CLIP和BERT。GLIP提出将目标检测形式化为grounding问题,统一了不同的数据格式以对齐不同的模态并扩展到检测词汇。在GLIP之后,Grounding DINO在早期阶段融合不同模态来改善视觉语言对齐。DetCLIP和RegionCLIP利用图像-文本对和伪框来扩展区域知识,以实现更广义的目标检测。
2. Visual-prompted Object Detection
Beyond text-prompted models, developing models incorporating visual prompts is a trending research area due to its flexibility and context-awareness. Main stream visual prompted models [28, 44, 48] adopt raw images as visual prompts and leverage image-text-aligned representation to transfer knowledge from text to visual prompts. However, it is restricted to image-level prompts and highly relies on aligned image-text foundation models. Another emergent approach for visual prompts is to use visual instructions like box, point, and referred region of another image. DINOv [17] proposes to use visual prompts as incontext examples for open-set detection and segmentation tasks. When detecting a novel category, it takes in several visual examples of this category to understand this category in an in-context manner. In this paper, we focus on visual prompts in the form of visual instructions.
除了文本提示模型,结合视觉提示的模型因是一个具有灵活性和上下文感知性称为研究热点。主流的视觉提示模型 [28, 44, 48] 采用原始图像作为视觉提示,并利用图像-文本对齐表示知识转换,从文本传递到视觉提示。然而,这种方法受限于图像级别提示,并且高度依赖于对齐的图像-文本基础模型。另一种新兴的视觉提示方法是使用类似框、点和另一幅图像中的区域等视觉指令。DINOv提出将视觉提示作为上下文示例用于开放集检测和分割任务。在检测新类别时,它会使用该类别的几个视觉示例以上下文方式理解该类别。本文关注以视觉指令形式的视觉提示。
3. Interactive Object Detection
Interactive models have shown significant promise in aligning human intentions in the field of computer vision. It has been wildly applied for interactive segmentation [12, 18, 56], where the user provides a visual prompt (box, point, and mask, etc.) and the model outputs a mask corresponding to the prompt. This process typically follows a one to-one interaction model, i.e., one prompt for one output mask. However, object detection requires a one-to-many approach, where a single visual prompt can lead to multiple detected boxes. Several works [14, 45] have incorporated interactive object detection for the purpose of automating annotations. T-Rex [10] leverages interactive visual prompts for the task of object counting through object detection, however, its capabilities in generic object detection have not been extensively explored.
交互式模型在计算机视觉领域展示出显著的潜力,用于对齐人类意图。它已被广泛应用于交互式分割 [12, 18, 56],用户提供视觉提示(框、点、mask等),模型输出与提示相对应的mask。这个过程通常遵循一对一交互模型,即一个提示对应一个输出mask。然而,目标检测需要一对多的方法,其中一个单一的视觉提示可以导致多个检测框。几项研究[14,45]已将交互式目标检测纳入自动化注释的目的。T-Rex利用交互式视觉提示借助目标检测进行目标计数任务,但其在通用目标检测方面的能力尚未得到广泛探讨。
三、模型方法
T-Rex2 integrates four components, as illustrated in Fig.3: i) Image Encoder, ii) Visual Prompt Encoder, iii) Text Prompt Encoder, and iv) Box Decoder. T-Rex2 adheres to the design principles of DETR [1] which is an end-to-end object detection model. These four components collectively facilitate four distinct workflows that encompass a broad range of application scenarios.
T-Rex2集成了四个组件,如图3所示:i) 图像编码器,ii) 视觉提示编码器,iii) 文本提示编码器和iv) 边界框解码器。T-Rex2遵循DETR[1]的设计原则,这是一种端到端的目标检测模型。这四个组件共同促进了四种不同的工作流程,涵盖了广泛的应用场景。

1. Visual-Text Promptable Object Detection
Image Encoder
Mirroring the Deformable DETR [55]framework, the image encoder in T-Rex2 consists of a vision backbone (e.g. Swin Transformer [25]) that extracts multi-scale feature maps from input image. This is followed by several transformer encoder layers [4] equipped with deformable self-attention [55], which are utilized to refine these extracted feature maps. The feature maps output from the image encoder is denoted as fi ∈ RCi×Hi×Wi, i ∈{1, 2, …, L}, where L is the number of feature map layers.
图像编码器。在 T-Rex2 中,图像编码器类似了 Deformable DETR 框架,由一个视觉主干(例如 Swin Transformer)提取输入图像的多尺度特征图。接着是几个带有可变形自注意力机制的 Transformer 编码层,用于优化这些提取的特征图。图像编码器输出的特征图被表示为 fi ∈ R Ci×Hi×Wi,其中 i ∈ {1, 2, …, L},L是特征图层数。
Visual Prompt Encoder
Visual prompt has been widely used in interactive segmentation [12, 18, 56], yet to be fully explored within the domain of object detection. Our method incorporates visual prompts in both box and point formats. The design principle involves transforming user-specified visual prompts from their coordinate space to the image feature space. Given K user-specified 4D normalized boxes bj = (xj, yj, wj, hj), j ∈ {1, 2, …, K}, or 2D normalized points pj = (xj, yj), j ∈ {1, 2, …, K} on a reference image, we initially encode these coordinate inputs into position embeddings through a fixed sine-cosine embedding layer. Subsequently, two distinct linear layers are employed to project these embeddings into a uniform dimension:
视觉提示编码器。视觉提示在交互式分割中被广泛使用,但在目标检测领域尚未得到充分探索。我们的方法在框和点格式中均融入了视觉提示。设计原则涉及将用户指定的视觉提示从它们的坐标空间转换到图像特征空间。给定参考图像上的 K 个用户指定的4D归一化框 bj = (xj, yj, wj, hj),j ∈ {1, 2, …, K},或者2D归一化点 pj = (xj, yj),j ∈ {1, 2, …, K},我们首先通过一个固定的正弦-余弦嵌入层将这些坐标输入编码为位置嵌入。随后,采用两个不同的线性层将这些嵌入投影到一个统一的维度。

where PE stands for position embedding and Linear(·; θ) indicate a linear project operation with parameter θ. Different from the previous method [18] that regards point as a box with minimal width and height, we model box and point as distinct prompt types. We then initiate a learnable content embedding that is broadcasted K times, denoted as C ∈ RK×D. Additionally, a universal class token C′ ∈ R1×D is utilized to aggregate features from other visual prompts, accommodating the scenario where users might supply multiple visual prompts within a single image. These content embeddings are concatenated with position embeddings along the channel dimension, and a linear layer is applied for projection, thereby constructing the input query embedding Q:
其中,PE 代表位置嵌入,Linear(·; θ) 表示具有参数 θ 的线性投影操作。与先前的方法不同,该方法将点视为具有最小宽度和高度的框,我们将框和点建模为不同的提示类型。然后,我们初始化一个可学习的内容embedding,将其广播 K 次,表示为 C ∈ R K×D。此外,还利用一个通用的class token C’ ∈ R 1×D 来聚合来自其他视觉提示的特征,以适应用户可能在单个图像中提供多个视觉提示的情况。这些内容embeddings与位置embedding沿通道维度cancat,然后应用一个线性层进行投影,从而构建输入查询嵌入 Q:
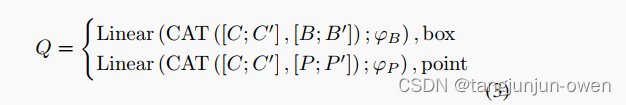
where notion CAT stands for concatenation at channel dimension. B′ and P ′ represent global position embeddings, which are derived from global normalized coordinates [0.5, 0.5, 1, 1] and [0.5, 0.5]. The global query serves the purpose of aggregating features from other queries. Subsequently, we employ a multi-scale deformable cross attention [55] layer to extract visual prompt features from the multi-scale feature maps, conditioned on the visual prompts. For the j-th prompt, the query feature Q′ j after cross attention is computed as:
其中,CAT 表示在通道维度上进行连接。B’ 和 P’ 代表全局位置embeddings,这些embeddings是从全局归一化坐标 [0.5, 0.5, 1, 1] 和 [0.5, 0.5] 中导出的。全局查询的目的是聚合来自其他查询的特征。随后,我们使用多尺度可变形交叉注意力层从多尺度特征图中提取视觉提示特征,条件是视觉提示。对于第 j 个提示,交叉注意力后的查询特征 Q’ j 计算如下:
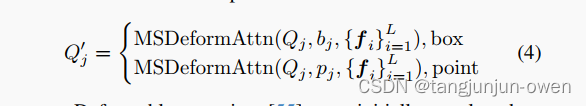
Deformable attention [55] was initially employed to address the slow convergence problem encountered in DETR [1]. In our approach, we condition deformable attention on the coordinates of visual prompts, i.e., each query will selectively attend to a limited set of multi-scale image features encompassing the regions surrounding the visual prompts. This ensures the capture of visual prompt embeddings representing the objects of interest. Following the extraction process, we use a self-attention layer to regulate the relationships among different queries and a feed-forward layer for projection. The output of the global content query will be used as the final visual prompt embedding V:
可变形注意力最初被用来解决 DETR 中遇到的收敛速度慢的问题。在我们的方法中,我们将可变形注意力置于视觉提示的坐标上,即每个查询将有选择地关注一组有限的多尺度图像特征,包括围绕视觉提示的区域。这确保了捕获代表感兴趣对象的视觉提示嵌入。在提取过程之后,我们使用自注意力层来调节不同查询之间的关系,并使用FFN层进行投影。全局内容查询的输出将被用作最终的视觉提示embedding V:

Text Prompt Encoder
We employ the text encoder of CLIP [32] to encode category names or short phrases and use the [CLS] token output as the text prompt embedding, denoted as T .
我们使用 CLIP 的文本编码器来编码类别名称或短语,并使用 [CLS] token的输出作为文本提示embedding,表示为 T。
Box Decoder
We employ a DETR-like decoder for box prediction. Following DINO [49], each query is formulated as a 4D anchor coordinate and undergoes iterative refinement across decoder layers. We employ the query selection layer proposed in Grounding DINO [24] to initialize the anchor coordinates (x, y, w, h). Specifically, We compute the similarity between the encoder feature and the prompt embeddings and select indices with similarity of top 900 to initialize the position embeddings. Subsequently, the detection queries utilize deformable cross-attention [55] to focus on the encoded multi-scale image features and are used to predict anchor offsets (∆x, ∆y, ∆w, ∆h) at each decoder layer. The final predicted boxes are obtained by summing the anchors and offsets:
我们采用 DETR 风格的解码器进行框预测。跟随DINO,每个查询被构建为一个4D锚点坐标,并在多个解码器层进行迭代refine。我们使用 Grounding DINO 中提出的查询选择层来初始化锚点坐标 (x, y, w, h)。具体来说,我们计算encoder 特征与prompt embeddings之间的相似性,并选择相似度前900的索引来初始化位置embeddings。随后,检测query利用可变形交叉注意力来提炼encoder的多尺度图像特征,并用于在每个解码器层预测anchor偏移量 (∆x, ∆y, ∆w, ∆h)。最终预测的框通过box和偏移相加获得:

Where Qdec are predicted queries from the box decoder.Instead of using a learnable linear layer to predict classlabels, following previous open-set object detection methods [19, 24], we utilize the prompt embeddings as the weights for the classification layer:
其中,Qdec 是来自框解码器的预测查询。与使用可学习的线性层来预测类别标签不同,我们遵循先前的开放集目标检测方法,利用提示embeddings作为分类层的权重:

Where C denotes the total number of visual prompt classes, and N represents the number of detection queries.
Both visual prompt object detection and openvocabulary object detection tasks share the same image encoder and box decoder.
其中,C 表示视觉提示类别的总数,N 代表检测查询的数量。
视觉提示目标检测和开放词汇目标检测任务共享相同的图像编码器和框解码器。
2. Region-Level Contrastive Alignment
To integrate both visual prompt and text prompt within one model, we employ region-level contrastive learning to align these two modalities. Specifically, given an input image and K visual prompt embeddings V = (v1, …, vK) extracted from the visual prompt encoder, along with the text prompt embeddings T = (t1, …, tK) for each prompt region, we calculate the InfoNCE loss [30] between the two types of embeddings:
为了将视觉提示和文本提示整合到一个模型中,我们采用区域级对比学习来对齐这两种模态。具体来说,给定一个输入图像和从视觉提示编码器提取的 K 个视觉提示embeddings V = (v1, …, vK),以及每个提示区域的文本提示embeddings T = (t1, …, tK),我们计算这两种embeddings之间的 InfoNCE 损失。
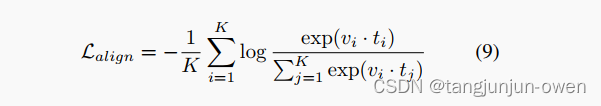
The contrastive alignment can be regarded as a mutual distillation process, whereby each modality contributes to and benefits from the exchange of knowledge. Specifically, text prompts can be seen as a conceptual anchor, around which diverse visual prompts can converge so that the visual prompt can gain general knowledge. Conversely, the visual prompts act as a continuous source of refinement for text prompts. Through exposure to a wide array of visual instances, the text prompt is dynamically updated and enhanced, gaining depth and nuance.
对比校准可以被看作是一种相互蒸馏过程,每种模态都会为知识的交换做出贡献并受益。具体来说,文本提示可以被视为一个概念anchor,围绕它的各种视觉提示可以汇聚,以便视觉提示可以获得通用知识。相反,视觉提示则作为文本提示的持续精炼refine资源源。通过接触各种视觉实例,文本提示会动态更新和增强,获得深度和细微差别。
注:文本比较泛,视觉目标细。如狗,文本可表示不同颜色、类别等狗,而视觉只知道看见训练的狗(如白色狗等)。
额外解释InfoNCE loss(非论文内容)
对比学习损失函数有多种,其中比较常用的一种是InfoNCE loss,InfoNCE loss其实跟交叉熵损失有着千丝万缕的关系,下面我们借用恺明大佬在他的论文MoCo里定义的InfoNCE loss公式来说明。 论文MoCo提出,我们可以把对比学习看成是一个字典查询的任务,即训练一个编码器从而去做字典查询的任务。假设已经有一个编码好的query (一个特征),以及一系列编码好的样本,那么可以看作是字典里的key。假设字典里只有一个key即(称为 positive)是跟是匹配的,那么和就互为正样本对,其余的key为q的负样本。一旦定义好了正负样本对,就需要一个对比学习的损失函数来指导模型来进行学习。这个损失函数需要满足这些要求,即当query 和唯一的正样本相似,并且和其他所有负样本key都不相似的时候,这个loss的值应该比较低。反之,如果和不相似,或者和其他负样本的key相似了,那么loss就应该大,从而惩罚模型,促使模型进行参数更新。
3. Training Strategy and Objective
Visual prompt training strategy
For visual prompt training, we adopt the strategy of “current image prompt, current image detect”. Specifically, for each category in a training set image, we randomly choose between one to all available GT boxes to use as visual prompts. We convert these GT boxes into their center point with a 50% chance for point prompt training. While using visual prompts from different images for cross-image detection training might seem more effective, creating such image pairs poses challenges in an open-set scenario due to inconsistent label spaces across datasets. Despite its simplicity, our straightforward training strategy still leads to strong generalization capability.
对于视觉提示训练,我们采用“当前图像提示,当前图像检测”的策略。具体而言,在训练图像集中的每个类别中,我们随机选择一个到所有可用的 GT 框作为视觉提示。我们有50%的概率将这些 GT 框转换为它们的中心点,用于点提示训练。虽然对于跨图像检测训练使用不同图像的视觉提示似乎更有效,但在开放集场景中创建这样的图像对面临挑战,因数据集之间标签空间的不一致。尽管我们的简单训练策略很简单,但仍具有强大的泛化能力。
Text prompt training strategy
T-Rex2 uses both detection data and grounding data for text prompt training. For detection data, we use the category names in the current image as the positive text prompt and randomly sample negative text prompts in the remaining categories. For grounding data, we extract positive phrases corresponding to the bounding boxes and exclude other words in the caption for text input. Following the methodology of DetCLIP [46, 47], we maintain a global dictionary to sample negative text prompts for grounding data, which are concatenated with the positive text prompts. This global dictionary is constructed by selecting the category names and phrase names that occur more than 100 times in the text prompt training data.
T-Rex2 使用检测数据和定位数据进行文本提示训练。对于检测数据,我们使用当前图像中的类别名称作为正文本提示,并在其余类别中随机抽样负文本提示。对于定位数据,我们提取与边界框对应的正短语,并排除文本输入中的其他单词。遵循 DetCLIP 的方法,我们维护一个全局字典,用于为定位数据采样负文本提示,这些负文本提示与正文本提示连接起来。这个全局字典是通过选取在文本提示训练数据中出现超过100次的类别名称和短语名称构建的。
Training objective
We employ the L1 loss and GIOU [36] loss for box regression. For classification loss, following Grounding DINO [24], we apply a contrastive loss that measures the difference between the predicted objects and the prompt embeddings. Specifically, we calculate the similarity between each detection query and the visual prompt or text prompt embeddings through a dot product to predict logits, followed by the computation of a sigmoid focal loss [21] for each logit. The box regression and classification loss are initially employed for bipartite matching [1] between predictions and ground truths. Subsequently, we calculate the final losses between ground truths and matched predictions, incorporating the same loss components. We use auxiliary loss after each decoder layer and after the encoder outputs. Following DINO [49], we also use denoising training to accelerate convergence. The final loss takes the following form:
我们采用 L1 损失和 GIOU 损失进行框回归。对于分类损失,遵循 Grounding DINO 的方法,我们应用对比损失来衡量预测目标与提示embedding之间的差异。具体来说,我们通过点积计算每个检测查询与视觉提示或文本提示嵌入之间的相似性以预测 logit 值,然后计算每个 logit 的 sigmoid 焦点损失。框回归和分类损失最初用于预测与地面实况之间的二分匹配。随后,我们计算地面实况与匹配预测之间的最终损失,并整合相同的损失组件。我们在每个解码器层之后和编码器输出之后使用辅助损失。遵循 DINO 的方法,我们还使用去噪训练加速收敛。最终损失如下所示:
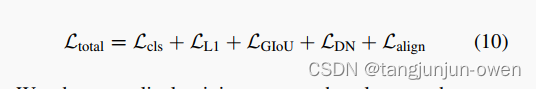
We adopt a cyclical training strategy that alternates between text prompts and visual prompts in successive iterations.
我们采用交替的循环训练策略,在连续迭代中交替使用文本提示和视觉提示。
四、实验