目录
一、关联分析介绍
关键概念:
1. 支持度(Support)
2. 置信度(Confidence)
3. 提升度(Lift)
4. 频繁项集
5. 关联规则
应用场景:
实现方法
二、导入数据集
额外介绍一下:
三、根据单据号,分组统计每个购物篮中的商品列表
三、根据单据号,分组统计每个购物篮中的商品数量
四、将统计数据汇总为一个数据框并过滤出商品数量大于1的购物篮
四、使用Apyori库进行关联规则分析及统计指标提取
(一) 获取到购物篮中的商品列表,用于apriori函数的输入
(二)得到关联规则和与之对应的统计指标
(三) 关联规则分析结果 DataFrame 构建
一、关联分析介绍
关联分析是一种数据挖掘方法,主要用于发现数据集中变量项之间有趣的关联或相关关系,特别是那些在商业、市场篮子分析、用户行为分析等领域中隐含的模式。这种分析的核心在于识别出哪些项目倾向于一起出现,基于这些发现,企业可以做出更加精准的营销策略、商品摆放决策或是个性化推荐等。
关键概念:
1. 支持度(Support)
指一个项集(一个或多个项目的组合)在所有交易数据中出现的频率。高支持度的项集表示这些项目经常被一起购买或出现。通常,只有满足最小支持度阈值的项集才会被认为是频繁项集。
2. 置信度(Confidence)
如之前解释,衡量的是如果一个项集A出现时,另一个项集B出现的条件概率。它用来量化关联规则的强度,比如规则“A→B”的置信度表示在包含A的所有事务中,同时包含B的事务所占的比例。
3. 提升度(Lift)
评估关联规则的实际效果相对于随机情况的提升程度,计算方式为置信度除以B的单独支持度。提升度大于1表示A和B的关联强于随机预期。
4. 频繁项集
支持度高于预定义阈值的所有项集。
5. 关联规则
形式上为X→Y,表示如果X发生,那么Y很可能也会发生。通常根据支持度和置信度来筛选有效的规则。





应用场景:
零售业:著名的“啤酒与尿布”案例,通过分析发现顾客购买尿布时常常会同时购买啤酒,促使超市调整商品布局,提高销售。
电子商务:个性化推荐系统,基于用户的购物历史推荐可能感兴趣的其他商品。
医疗健康:分析患者的病史记录,发现某些病症和治疗方案之间的关联,辅助临床决策。
市场营销:识别顾客的购买偏好,制定针对性的营销策略和促销活动。
Web使用模式分析:理解用户浏览行为,优化网站设计和内容推荐。
实现方法
Apriori算法:经典的关联规则挖掘算法,通过迭代减少候选项集的数量来高效发现频繁项集。
FP-growth算法:利用频繁模式树(FP-tree)结构进行优化,减少对数据库的扫描次数,适合处理大规模数据集。关联分析是一个强大的工具,帮助企业从海量数据中提取有价值的信息,优化业务决策并提升用户体验。
二、导入数据集
import pandas
data = pandas.read_csv("超市销售数据.csv",encoding='utf8', engine='python')
额外介绍一下:
如下图,查看一下单据号是否有重复值,发现有31198条重复行
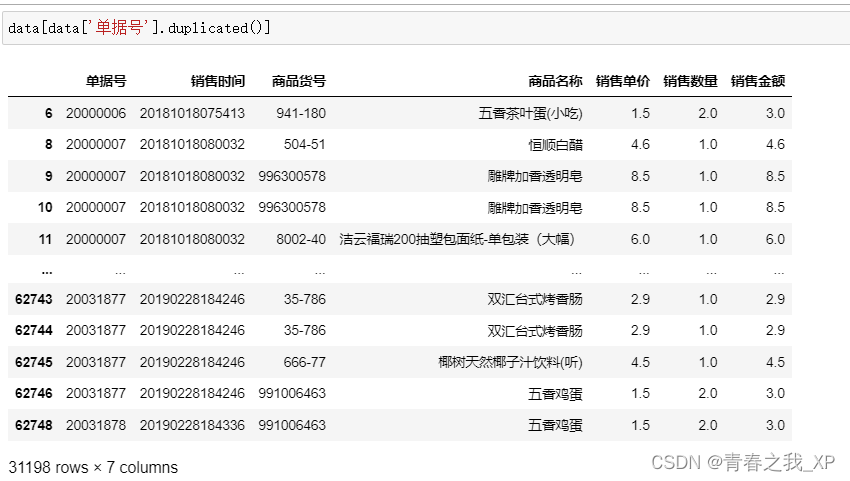
如果添加上keep=False的参数的话,就有了45722条重复行。

原因:
在Pandas中,`duplicated()` 函数用来识别数据框中的重复行。这个函数接受几个参数,其中 `keep` 参数决定了如何标记重复行。`keep` 可以取三个值:`'first'`、`'last'` 或 `False`。
- 当 `keep='first'` 时,每组重复项中第一个出现的行被视为非重复,其余的视为重复。
- 当 `keep='last'` 时,每组重复项中最后一个出现的行被视为非重复,其余的视为重复。
- 当 `keep=False` 时,所有重复项都被视为重复,不管它们在数据框中的位置。因此,`data[data['单据号'].duplicated(keep=False)]` 和 `data[data['单据号'].duplicated()]` 的区别在于如何处理重复的 `'单据号'`:
- `data[data['单据号'].duplicated(keep=False)]`:这会返回所有具有重复 `'单据号'` 的行,不论它们在数据集中的重复次数或位置。这意味着,如果有多个行的 `'单据号'` 相同,所有这些行都会被包含在这个结果中。
- `data[data['单据号'].duplicated()]`:默认情况下,`keep` 参数的值是 `'first'`。因此,这个表达式会返回除了每个 `'单据号'` 的第一个出现之外的所有重复行。也就是说,如果有重复的 `'单据号'`,只有第一次出现之后的那些重复行会被标记并返回。
总结来说,前者会包括所有重复的行,而后者只会包括除首个重复外的其他重复行。
三、根据单据号,分组统计每个购物篮中的商品列表
#根据单据号,分组统计每个购物篮中的商品列表
itemSetList = data.groupby(by='单据号').apply(lambda x: list(x.商品名称))
三、根据单据号,分组统计每个购物篮中的商品数量
#根据单据号,分组统计每个购物篮中的商品数量
itemSetCount = itemSet = data.groupby(
by='单据号').apply(
lambda x: len(x.商品名称))
四、将统计数据汇总为一个数据框并过滤出商品数量大于1的购物篮
#将统计数据汇总为一个数据框
itemSet = pandas.DataFrame({
'商品列表': itemSetList,
'商品数量': itemSetCount
})
#过滤出商品数量大于1的购物篮
itemSet = itemSet[itemSet.商品数量>1]
四、使用Apyori库进行关联规则分析及统计指标提取
(一) 获取到购物篮中的商品列表,用于apriori函数的输入
#获取到购物篮中的商品列表,用于apriori函数的输入
transactions = itemSet['商品列表'].values
#提取名为 '商品列表' 的列,并获取该列的所有值。
transactions
(二)得到关联规则和与之对应的统计指标
from apyori import apriori
#调用apriori算法进行计算,
#得到关联规则和与之对应的统计指标
results = list(
apriori(
transactions,
min_support=0.001, #最小支持度
min_confidence=0.001, #最小置信度
min_lift=1.001#最小提升度
)
)
#支持度(support)
supports = []
#置信度(confidence)
confidences = []
#提升度(lift)
lifts = []
#基于项items_base
bases = []
#推导项items_add
adds = []#results[0].ordered_statistics
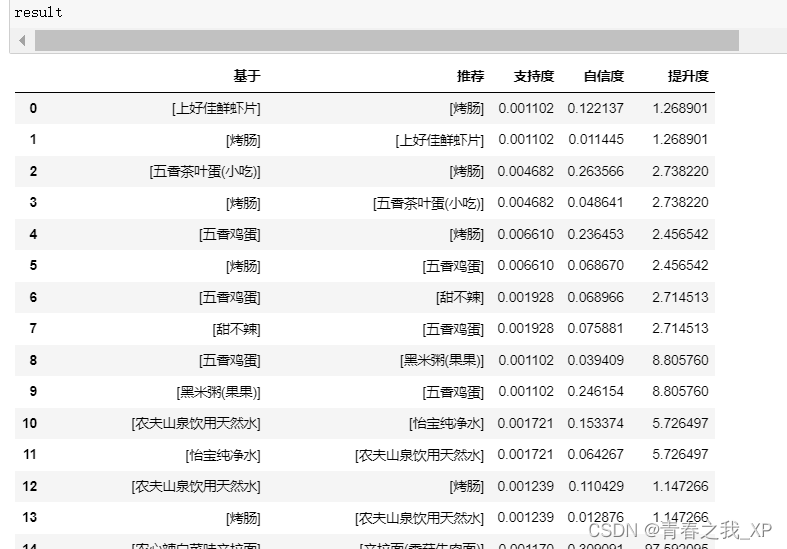
(三) 关联规则分析结果 DataFrame 构建
首先,迭代Apriori算法的结果results,将每个结果中的关键信息(支持度、置信度、提升度、基于项、推荐项)分别存储在对应的列表中。
接着,使用Pandas库创建一个名为result的数据框,包含5个列:
基于(bases):存储每个频繁项集中的基于项,即频繁项集中的第一个项。
推荐(adds):存储每个频繁项集中的推荐项,即频繁项集中的第二个项。
支持度(supports):存储每个频繁项集的支持度。
置信度(confidences):存储每个频繁项集的置信度。
提升度(lifts):存储每个频繁项集的提升度。
#把apriori函数计算的结果,
#保存成为一个数据框,方便数据分析
for r in results:
size = len(r.ordered_statistics)
for j in range(size):
supports.append(r.support)
confidences.append(
r.ordered_statistics[j].confidence
)
lifts.append(r.ordered_statistics[j].lift)
bases.append(
list(r.ordered_statistics[j].items_base)
)
adds.append(
list(r.ordered_statistics[j].items_add)
)
#保存成为一个数据框
result = pandas.DataFrame({
'基于': bases,
'推荐': adds,
'支持度': supports,
'置信度': confidences,
'提升度': lifts
})
result
若要显示全部结果,如下操作:
pandas.options.display.max_rows = None在Python的Pandas库中,pandas.options.display.max_rows 是一个用于控制DataFrame显示最大行数的选项。默认情况下,当DataFrame的行数超过一定数量时(通常是30行),Pandas会只显示一个省略号(...),表示有更多行数据未显示。
# 当你设置 pandas.options.display.max_rows = None 时,你是在告诉Pandas不要限制DataFrame的显示行数,即显示所有的行。这样,无论DataFrame有多少行,都会完全显示出来,而不会出现省略号。
70个结果全部显示完全