为系统引入缓存之前,第一件事情是确认系统是否真的需要缓 存。从开发角度来说,引入缓存会提 高系统复杂度,因为你要考虑缓存的失效、更新、一致性等问题;从运维角度来说,缓存会掩盖一些缺 陷,让问题在更久的时间以后,出现在距离发生现场更远的位置上; 从安全角度来说,缓存可能会泄漏某些保密数据,也是容易受到攻击 的薄弱点。冒着上述种种风险,仍能说服你引入缓存的理由,总结起 来无外乎以下两种。
- 为缓解CPU压力而引入缓存:譬如把方法运行结果存储起来、 把原本要实时计算的内容提前算好、对一些公用的数据进行复用,这 可以节省CPU算力,顺带提升响应性能。
- 为缓解I/O压力而引入缓存:譬如把原本对网络、磁盘等较慢 介质的读写访问变为对内存等较快介质的访问,将原本对单点部件 (如数据库)的读写访问变为对可扩缩部件(如缓存中间件)的访 问,顺带提升响应性能。
请注意,缓存虽然是典型以空间换时间来提升性能的手段,但它 的出发点是缓解CPU和I/O资源在峰值流量下的压力,“顺带”而非 “专门”地提升响应性能。这里的言外之意是如果可以通过增强CPU、 I/O本身的性能(譬如扩展服务器的数量)来满足需要的话,那升级硬 件往往是更好的解决方案,即使需要一些额外的投入成本,也通常要 优于引入缓存后可能带来的风险。
缓存属性
有不少软件系统最初的缓存功能是以HashMap或者 ConcurrentHashMap为起点演进的。当开发人员发现系统中某些资源的 构建成本比较高,而这些资源又有被重复使用的可能时,会很自然地 产生“循环再利用”的想法,将它们放到Map容器中,待下次需要时取 出重用,避免重新构建,这种原始朴素的复用就是最基本的缓存。不 过,一旦我们专门把“缓存”看作一项技术基础设施,一旦它有了通 用、高效、可统计、可管理等方面的需求,其中要考虑的因素就变得 复杂起来。通常,我们设计或者选择缓存至少会考虑以下四个维度的 属性。
- 吞吐量:缓存的吞吐量使用OPS值(每秒操作数,Operation per Second,ops/s)来衡量,反映了对缓存进行并发读、写操作的效率, 即缓存本身的工作效率高低。
- 命中率:缓存的命中率即成功从缓存中返回结果次数与总请求 次数的比值,反映了引入缓存的价值高低,命中率越低,引入缓存的 收益越小,价值越低。
- 扩展功能:即缓存除了基本读写功能外,还提供哪些额外的管 理功能,譬如最大容量、失效时间、失效事件、命中率统计,等等。
- 分布式缓存:缓存可分为“进程内缓存”和“分布式缓存”两 大类,前者只为节点本身提供服务,无网络访问操作,速度快但缓存 的数据不能在各服务节点中共享,后者则相反。
吞吐量
缓存的吞吐量只在并发场景中才有统计的意义,因为若不考虑并 发,即使是最原始的、以HashMap实现的缓存,访问效率也已经是常量 时间复杂度(即O(1)),其中涉及碰撞、扩容等场景的处理属于数据 结构基础,这里不再展开。但HashMap并不是线程安全的容器,如果要 让它在多线程并发下正确地工作,就要用 Collections.synchronizedMap进行包装,这相当于给Map接口的所有 访问方法都自动加全局锁;或者改用ConcurrentHashMap来实现,这相 当于给Map的访问分段加锁(从JDK 8起已取消分段加锁,改为 CAS+Synchronized锁单个元素)。无论采用怎样的实现方法,这些线 程安全措施都会带来一定的吞吐量损失。
命中率与淘汰策略
有限的物理存储决定了任何缓存的容量都不可能是无限的,所以 缓存需要在消耗空间与节约时间之间取得平衡,这要求缓存必须能够 自动或者人工淘汰掉缓存中的低价值数据。考虑到由人工管理的缓存 淘汰主要取决于开发者如何编码,不能一概而论,这里只讨论由缓存 自动进行淘汰的情况。笔者所说的“缓存如何自动地实现淘汰低价值 目标”,现在被称为缓存的淘汰策略。
在了解缓存如何实现自动淘汰低价值数据之前,首先要定义怎样 的数据才算是“低价值”。由于缓存的通用性,这个问题的答案必须 是与具体业务逻辑无关的,只能从缓存工作过程收集到的统计结果来 确定数据是否有价值,通用的统计结果包括但不限于数据何时进入缓 存、被使用过多少次、最近什么时候被使用,等等。一旦确定选择何 种统计数据,就决定了如何通用地、自动地判定缓存中每个数据的价 值高低,也相当于决定了缓存的淘汰策略是如何实现的。目前,最基 础的淘汰策略实现方案有以下三种。
- FIFO(First In First Out):优先淘汰最早进入被缓存的数据。 FIFO的实现十分简单,但一般来说它并不是优秀的淘汰策略,越是频 繁被用到的数据,往往会越早存入缓存之中。如果采用这种淘汰策 略,很可能会大幅降低缓存的命中率。
- LRU(Least Recent Used):优先淘汰最久未被访问过的数据。 LRU通常会采用HashMap加LinkedList的双重结构(如LinkedHashMap) 来实现,以HashMap来提供访问接口,保证常量时间复杂度的读取性 能,以LinkedList的链表元素顺序来表示数据的时间顺序,每次缓存命 中时把返回对象调整到LinkedList开头,每次缓存淘汰时从链表末端开 始清理数据。对大多数的缓存场景来说,LRU明显要比FIFO策略合 理,尤其适合用来处理短时间内频繁访问的热点对象。但是如果一些 热点数据在系统中被频繁访问,只是最近一段时间因为某种原因未被 访问过,那么这些热点数据此时就会有被LRU淘汰的风险,换句话 说,LRU依然可能错误淘汰价值更高的数据。
- LFU(Least Frequently Used):优先淘汰最不经常使用的数据。 LFU会给每个数据添加一个访问计数器,每访问一次就加1,需要淘汰 时就清理计数器数值最小的那批数据。LFU可以解决上面LRU中热点数 据间隔一段时间不访问就被淘汰的问题,但同时它又引入了两个新的 问题。第一个问题是需要对每个缓存的数据专门维护一个计数器,每 次访问都要更新,但这样做会带来高昂的维护开销;另一个问题是不 便于处理随时间变化的热度变化,譬如某个曾经频繁访问的数据现在 不需要了,但很难自动将它清理出缓存。
缓存的淘汰策略直接影响缓存的命中率,没有一种策略是完美 的、能够满足系统全部需求的。不过,随着淘汰算法的不断发展,近 年来的确出现了许多相对性能更好、也更复杂的新算法。以LFU为例, 针对它存在的两个问题,近年来提出的TinyLFU和W-TinyLFU算法就会 有更好的效果。
分布式缓存
相比缓存数据在进程内存中读写的速度,一旦涉及网络访问,由 网络传输、数据复制、序列化和反序列化等操作所导致的延迟要比内 存访问高得多,所以对分布式缓存来说,处理与网络相关的操作是对 吞吐量影响更大的因素,往往也是比淘汰策略、扩展功能更重要的关 注点,这也决定了尽管有Ehcache、Infinispan这类能同时支持分布式 部署和进程内部署的缓存方案,但通常进程内缓存和分布式缓存选型 时会有完全不同的候选对象及考察点。在我们决定使用哪种分布式缓 存前,首先必须确定自己的需求是什么。
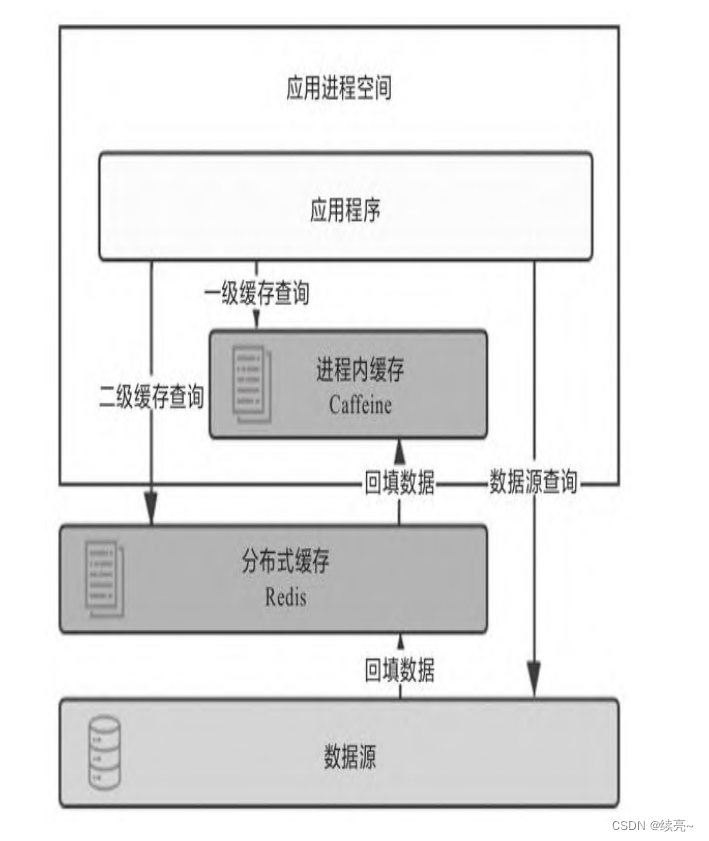
尽管多级缓存结合了进程内缓存和分布式缓存的优点,但它的代 码侵入性较大,需要由开发者承担多次查询、多次回填的工作,也不 便于管理,如超时、刷新等策略都要设置多遍,数据更新更是麻烦, 很容易出现各个节点的一级缓存以及二级缓存中数据不一致的问题。 所以,必须“透明”地解决以上问题,才能使多级缓存具有实用的价 值。一种常见的设计原则是变更以分布式缓存中的数据为准,访问以 进程内缓存的数据优先。大致做法是当数据发生变动时,在集群内发 送推送通知(简单点的话可采用Redis的PUB/SUB,求严谨的话可引入 ZooKeeper或etcd来处理),让各个节点的一级缓存中的相应数据自动 失效。当访问缓存时,提供统一封装好的一、二级缓存联合查询接 口,接口外部是只查询一次,接口内部自动实现优先查询一级缓存, 未获取到数据再自动查询二级缓存的逻辑。
缓存风险
1.缓存穿透
缓存的目的是缓解CPU或者I/O的压力,譬如对数据库做缓存,大 部分流量都从缓存中直接返回,只有缓存未能命中的数据请求才会流 到数据库中,这样数据库压力自然就减小了。但是如果查询的数据在 数据库中根本不存在,缓存里自然也不会有,这类请求的流量每次都 不会命中,且每次都会触及末端的数据库,缓存就起不到缓解压力的 作用了,这种查询不存在的数据的现象被称为缓存穿透。
缓存穿透有可能是业务逻辑本身就存在的固有问题,也有可能是 恶意攻击所导致。为了解决缓存穿透问题,通常会采取下面两种办 法。
- 对于业务逻辑本身不能避免的缓存穿透,可以约定在一定时间 内对返回为空的Key值进行缓存(注意是正常返回但是结果为空,不 应把抛异常的也当作空值来缓存),使得在一段时间内缓存最多被穿 透一次。如果后续业务在数据库中对该Key值插入了新记录,那应当 在插入之后主动清理掉缓存的Key值。如果业务时效性允许的话,也 可以对缓存设置一个较短的超时时间来自动处理。
- 对于恶意攻击导致的缓存穿透,通常会在缓存之前设置一个布 隆过滤器来解决。所谓恶意攻击是指请求者刻意构造数据库中肯定不 存在的Key值,然后发送大量请求进行查询。布隆过滤器是用最小的 代价来判断某个元素是否存在于某个集合的办法。如果布隆过滤器给 出的判定结果是请求的数据不存在,直接返回即可,连缓存都不必去 查。虽然维护布隆过滤器本身需要一定的成本,但比起攻击造成的资 源损耗仍然是值得的。
2.缓存击穿
我们都知道缓存的基本工作原理是首次从真实数据源加载数据, 完成加载后回填入缓存,以后其他相同的请求就从缓存中获取数据, 以缓解数据源的压力。如果缓存中某些热点数据忽然因某种原因失效 了,譬如由于超期而失效,此时又有多个针对该数据的请求同时发送 过来,这些请求将全部未能命中缓存,到达真实数据源中,导致其压 力剧增,这种现象被称为缓存击穿。要避免缓存击穿问题,通常会采 取下面两种办法。
- 加锁同步,以请求该数据的Key值为锁,使得只有第一个请求 可以流入真实的数据源中,对其他线程则采取阻塞或重试策略。如果 是进程内缓存出现问题,施加普通互斥锁即可,如果是分布式缓存中 出现问题,就施加分布式锁,这样数据源就不会同时收到大量针对同 一个数据的请求了。
- 热点数据由代码来手动管理。缓存击穿是仅针对热点数据自动 失效才引发的问题,对于这类数据,可以直接由开发者通过代码来有 计划地完成更新、失效,避免由缓存的策略自动管理。
3.缓存雪崩
缓存击穿是针对单个热点数据失效,由大量请求击穿缓存而给真 实数据源带来压力。还有一种可能更普遍的情况,即不是针对单个热 点数据的大量请求,而是由于大批不同的数据在短时间内一起失效, 导致这些数据的请求都击穿缓存到达数据源,同样令数据源在短时间 内压力剧增。 出现这种情况,往往是因为系统有专门的缓存预热功能,或者大 量公共数据是由某一次冷操作加载的,使得由此载入缓存的大批数据 具有相同的过期时间,在同一时刻一起失效;也可能是因为缓存服务 由于某些原因崩溃后重启,造成大量数据同时失效。这种现象被称为 缓存雪崩。要避免缓存雪崩问题,通常会采取下面三种办法。
- 提升缓存系统可用性,建设分布式缓存的集群
- 启用透明多级缓存,这样各个服务节点一级缓存中的数据通常 会具有不一样的加载时间,也就分散了它们的过期时间。
- 将缓存的生存期从固定时间改为一个时间段内的随机时间,譬 如原本是1h过期,在缓存不同数据时,可以设置生存期为55min到 65min之间的某个随机时间。
4.缓存污染
缓存污染是指缓存中的数据与真实数据源中的数据不一致的现象。这种情况通常是由于开发者在更新缓存时操作不规范造成的,可能导致数据的不一致性。虽然缓存通常不追求强一致性,但最终一致性仍然是必须的。
造成缓存污染的常见原因
- 更新缓存不规范:开发者从缓存中获得某个对象并更新其属性,但由于某些原因(如业务异常回滚),最终未能成功写入数据库,导致缓存中的数据是新的,但数据库中的数据是旧的。
- 操作顺序错误:如果更新操作的顺序不正确,例如先失效缓存后写数据源,可能会导致缓存和数据源的不一致。
提高缓存一致性的设计模式
为了尽可能地提高使用缓存时的一致性,以下几种常见的设计模式可以帮助管理缓存更新:
-
Cache Aside:
- 读数据:先读缓存,如果缓存中没有,再读数据源,然后将数据放入缓存,再响应请求。
- 写数据:先写数据源,然后失效缓存。
这种模式的关键在于:
- 先后顺序:必须先写数据源后失效缓存。如果先失效缓存后写数据源,可能在缓存失效和数据源更新之间存在时间窗口,此时新的查询请求会读到旧的数据并重新填充到缓存中,导致数据不一致。
- 失效缓存:而不是尝试更新缓存,因为更新过程中数据源可能会被其他请求再次修改,处理多次赋值的时序问题非常复杂。失效缓存可以避免这种情况,确保下次读取时自动回填最新的数据。
-
Read/Write Through:
- 读数据:先读缓存,如果没有,再读数据源,并将数据写入缓存。
- 写数据:先写缓存,再写数据源。
这种模式保证了缓存和数据源的一致性,但实现起来比较复杂,可能会带来性能开销。
-
Write Behind Caching:
- 读数据:先读缓存,如果没有,再读数据源,并将数据写入缓存。
- 写数据:先写缓存,然后异步地将数据写入数据源。
这种模式通过异步更新数据源,提高了写操作的性能,但在数据源更新的延迟期间,可能会导致数据不一致。
Cache Aside 模式的局限性
Cache Aside 模式虽然简洁且成本低,但依然不能完全保证一致性。例如,当某个从未被缓存的数据请求直接流到数据源,如果数据源的写操作发生在查询请求之后但回填到缓存之前,缓存中回填的内容可能与数据库的实际数据不一致。然而,这种情况的发生概率较低,Cache Aside 模式仍然是一个低成本且相对可靠的解决方案。
通过以上设计模式,可以在一定程度上减少缓存污染,确保缓存与数据源之间的一致性,但完全避免是不现实的,特别是在高并发和复杂业务场景下。










![[word] word怎样转换成pdf #职场发展#经验分享#职场发展](https://img-blog.csdnimg.cn/img_convert/4ec11645aaa8126e892ff5acb146cd2f.png)