大语言模型(LLM) 被描述的神乎其神,无所不能,其实,大语言模型只是一个模型,它能够理解和生成自然语言,唯有依靠应用程序才能够发挥作用。例如,基于大模型可以构建一个最简单的会话机器人,需要有IO 模型,将用户的提问发送给大模型,大模型得到回应后,通过输出模块将问答反馈给用户。为了使大模型能够准确地理解用户的提问,LLM 应用程序要给它合适的提示(Prompt),所有的函数都有合适的描述(Description)。
可以将大语言模型应用是看作一个基于自然语言描述的的程序。传统的条件,循环,状态判断也都是由LLM 完成的。所以,同样结构的LLM 应用,使用不同的LLM,或者不同的提示和描述,其效果的是不同的。这一点与传统的程序是不同的。
从关注程序的语法转向语义的表达是AI时代的最大转变。
各种大语言模型应用架构
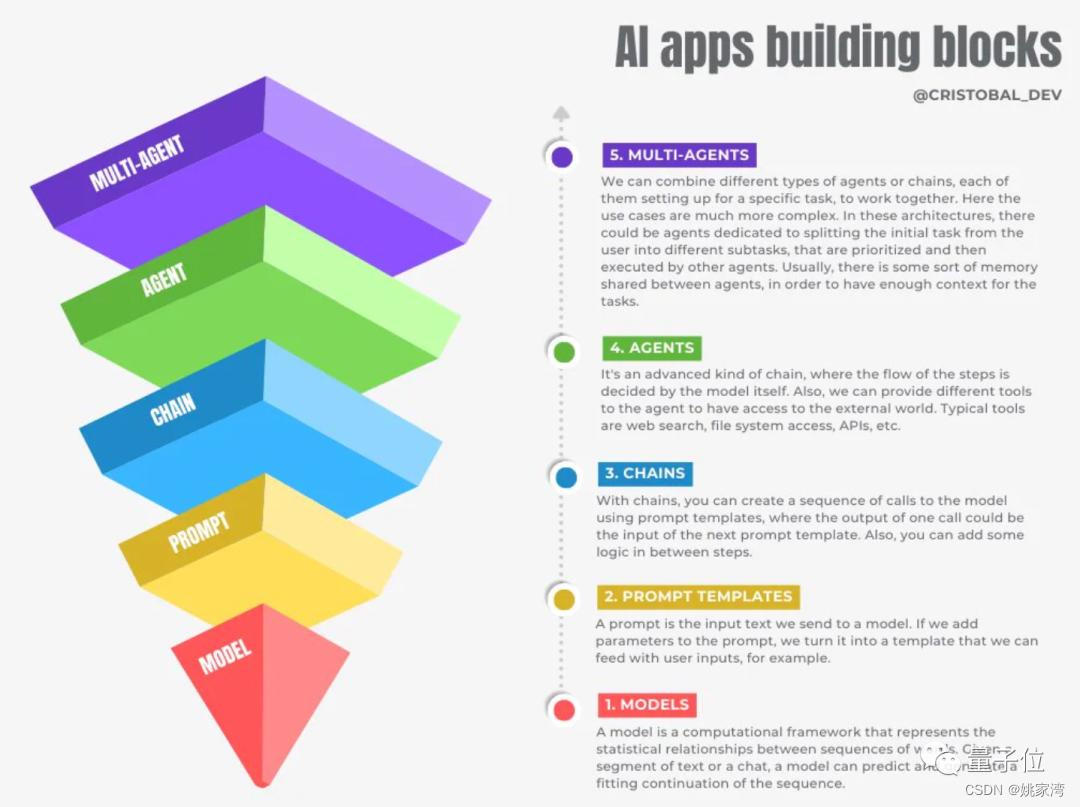
AI应用的五层基石理论
AI应用的的架构, 初创公司Seednapse AI创始人提出构建AI应用的五层基石理论,受到业界关注。
- Models,也就是我们熟悉的调用大模型API。
- Prompt Templates,在提示词中引入变量以适应用户输入的提示模版。
- Chains,对模型的链式调用,以上一个输出为下一个输入的一部分。
- Agent,能自主执行链式调用,以及访问外部工具。
- Multi-Agent,多个Agent共享一部分记忆,自主分工相互协作。
提示工程
提示工程,也称为上下文提示,是指如何与 LLM 通信以在不更新模型权重的情况下引导其行为以获得所需结果的方法。这是一门实证科学,提示工程方法的效果在模型之间可能会有很大差异,因此需要大量的实验和启发式方法。
langchain 链
如同计算机程序一样,当AI 完成复杂的任务时,需要若干的步骤,或者称为组件,这些组件通过一定的顺序链接起来执行,这便是langchain 的核心思想。
链( Chains )是一个非常通用的概念,它指的是将一系列模块化组件(或其他链)以特定方式组合起来,以实现共同的用例。
链(Chain)是对多个独立组件进行端到端封装的一种方式。
简单的说,就是把自然语言输入、关联知识检索、Prompt组装、可用Tools信息、大模型调用、输出格式化等这些LLM 应用中的常见动作,组装成一个可以运行的“链”式过程。链可以直接调用。
最常用的链类型是LLMChain(LLM链),它结合了PromptTemplate(提示模板)、Model(模型)和Guardrails(守卫)来接收用户输入,进行相应的格式化,将其传递给模型并获取响应,然后验证和修正(如果需要)模型的输出。
LCEL表达式语言
LCEL 的全称是"LangChain Expression Language",langchain 表达语言。是一种声明式方法,可以轻松地将链组合在一起。
最基本和常见的用例是将提示模板和模型链接在一起。为了了解这是如何工作的,
创建一个链条,它接受一个主题并生成一个笑话:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-4")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.invoke({"topic": "ice cream"})输出
"为什么冰淇淋从不被邀请参加派对?\n\n因为当事情变热时,它们总是滴下来!使用LCEL将不同的组件组合成一个单一的链条:
chain = prompt | model | output_parser例子
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
vectorstore = DocArrayInMemorySearch.from_texts(
["harrison worked at kensho", "bears like to eat honey"],
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
output_parser = StrOutputParser()
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parser
chain.invoke("where did harrison work?")在这种情况下,组合的链条是:
chain = setup_and_retrieval | prompt | model | output_parser智能体(Agent)
在大模型语境下,可以理解成能自主理解、规划、执行复杂任务的系统。
Agent 包含了一组工具,由大模型不断地思考,选择合适的工具,获得最后的结果。
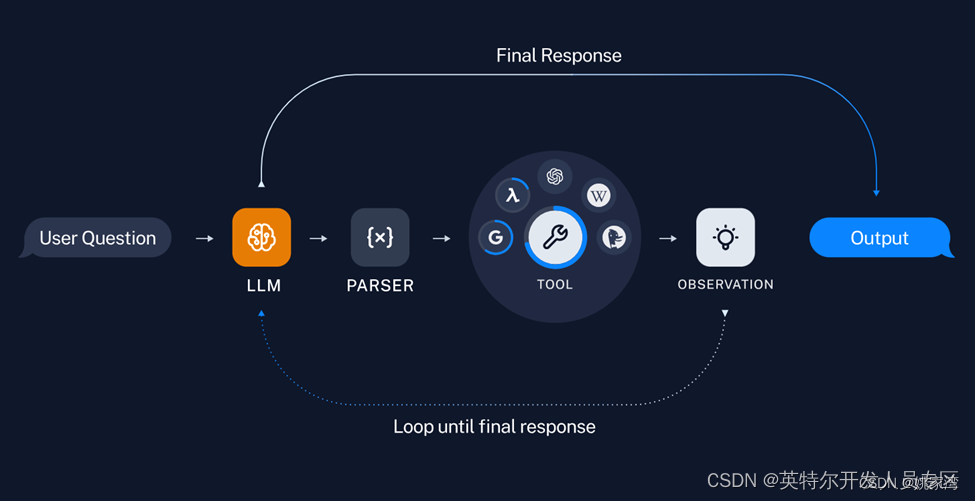
上面的循环也能够使用下面的流程图来表达。
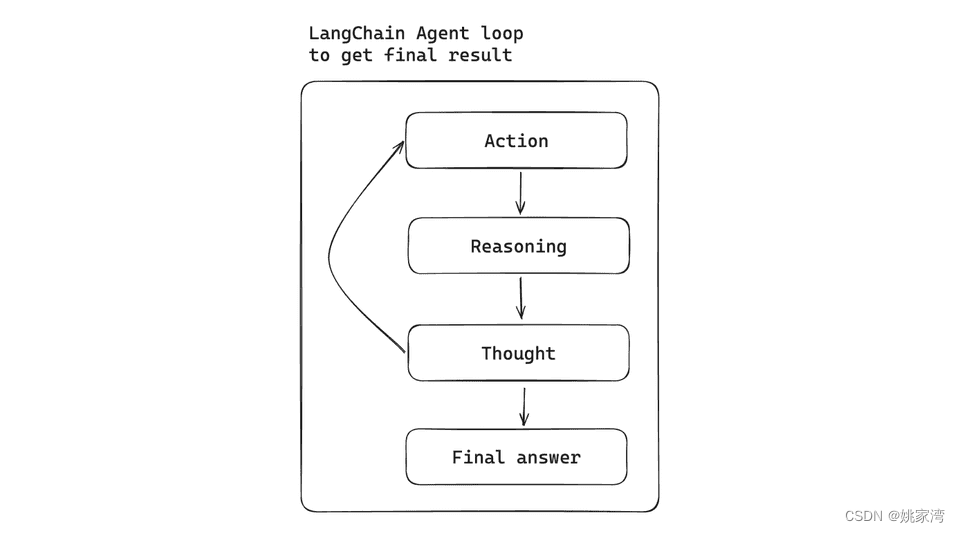
从这个意义上讲,Agent 是一个循环体。在Agent 中,LLM 起到了推理的作用,它可以讲用户的需求分解成若干的任务,选择合适的工具去执行。 Agent 就像一个“小工”(比如一个瓦匠),告诉他要完成的工作,以及一些工具。并且简单的教他一些注意事项,小工就开干了。他会选择不同的工具,直到工作完成。
Agent 的效果很大程度上取决于大模型的理解能力,同样的Agent ,使用不同的大语言模型,其效果变化很大。另外一个重要的因素是提示和描述,在大语言模型应用中,每个工具(函数) 都有一段描述,大语言模型依靠阅读并理解工具的描述来决定使用哪一个工具。
agent 内部有一个类似运行时(runtime) 的程序(AgentExecutor )。
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(..., next_action, observation)
return next_actionmulti-Agent(langGraph )
langGraph 是langchain的库,用于构建多Agent 工作流(multi-Agent workFlow)
LangGraph 的核心概念之一是状态。每个图形执行都会创建一个状态,该状态在执行时在图形中的节点之间传递,并且每个节点在执行后使用其返回值更新此内部状态。图形更新其内部状态的方式由所选图形类型或自定义函数定义。
LangGraph本质上是一个状态机。这里的图就是状态图。与传统的状态图类似,它也具有节点(Node)和边(edges)。它被称为认知架构的一类。
LangGraph 将黑盒的 AgentExecutor 透明化,允许开发者定义内部的细节结构(用图的方式),从而实现更强大的功能。那么就可以用LangGraph 来重新实现原来的 AgentExecutor,即实现一个最基础的 ReAct范式的 Agent 应用。
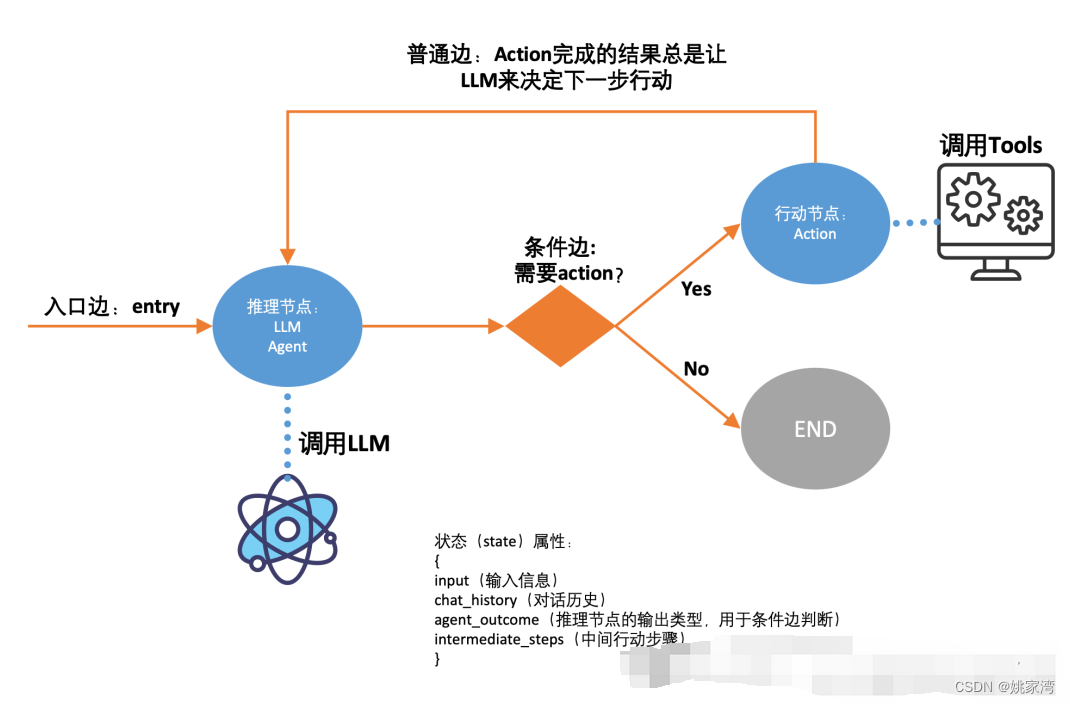
每个代理都可以有自己的提示符、LLM、工具和其他自定义代码,以便与其他代理进行最佳协作。
下面是一个基于langGraph 的例子
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, HumanMessage
from langgraph.graph import END, MessageGraph
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
from typing import Literal
import os
os.environ['OPENAI_API_KEY'] ="sk-xxxxxxxxxxxxxxxxx"
os.environ['OPENAI_BASE_URL'] ="https://api.chatanywhere.tech/v1"
model = ChatOpenAI(temperature=0)
@tool
def multiply(first_number: int, second_number: int):
"""Multiplies two numbers together."""
return first_number * second_number
model = ChatOpenAI(temperature=0)
model_with_tools = model.bind_tools(tools=[multiply])
graph = MessageGraph()
graph.add_node("oracle", model_with_tools)
tool_node = ToolNode([multiply])
graph.add_node("multiply", tool_node)
graph.add_edge("multiply", END)
graph.set_entry_point("oracle")
def router(state: list[BaseMessage]) -> Literal["multiply", "__end__"]:
tool_calls = state[-1].additional_kwargs.get("tool_calls", [])
if len(tool_calls):
return "multiply"
else:
return END
graph.add_conditional_edges("oracle", router)
runnable = graph.compile()
result=runnable.invoke(HumanMessage("What is 123 * 456??"))
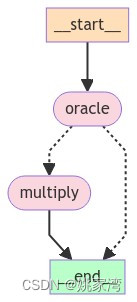
print(result)构建的图结构
大模型应用的关键是大模型本身
尽管大模型应用程序看上去与传统的程序架构相似的。但是它们是截然不同的,传统程序的循环和跳转是根据条件判断的,是确定的。而大语言模型的跳转,循环是依靠大模型的判断和推理,使用不同的大语言模型,应用执行的效果是不同的。LLM 应用的另一个重要的地方,就是各种提示和描述。比较确切的描述能够提升大语言模型应用的效果。说句不太贴切的话“大语言模型的应用程序的执行全靠大模型”猜“。调试LLM 应用的感觉就像训练一个小狗。很多程度靠”狗脑子十分灵光“。