目录
- 引言
- 一.导数的计算
- 1.epsilon与导数的关系
- 2.其它导数符号形式
- 3.导数小结
- 二.小型神经网络的计算图
- 1.什么是计算图(前向传播过程)
- 2.反向传播计算过程
- 3.验证反向传播的计算结果
- 4.为什么用反向传播计算导数?
- 三.扩大神经网络的计算图
- 1.计算反向传播
- 2.验证反向传播
- 四.总结
引言
在 TensorFlow 中,您可以指定神经网络架构和成本函数,TensorFlow 会自动使用反向传播计算导数,并利用梯度下降或 Adam 等算法训练网络参数。反向传播是神经网络学习中的核心算法,接下来的内容将了解反向传播如何计算导数,也就是反向传播的工作原理。
对于一些简单的机器学习模型,如线性回归或逻辑回归,梯度公式可以手动推导并计算。这些模型的参数较少,导数计算相对简单。而神经网络通常有很多层和大量参数,手动推导和计算每个参数的梯度非常复杂和耗时。反向传播算法通过自动求导和链式法则,更高效地计算每个参数的梯度。
一.导数的计算
1.epsilon与导数的关系
1.1 使用简化的成本函数 J(w) = w^2为例来描述关系,w不变,epsilon变化
- 当参数 w = 3 时, J(w) = 9 。如果我们将 w 增加一个很小的量 epsilon = 0.001 ,那么 w 变为 3.001, J(w) 变为 9.006001。这表明,当 w 增加 0.001 时,J(w) 增加了约 6 倍的 epsilon。在微积分中,这意味着J(w)关于 w 的导数为 6。
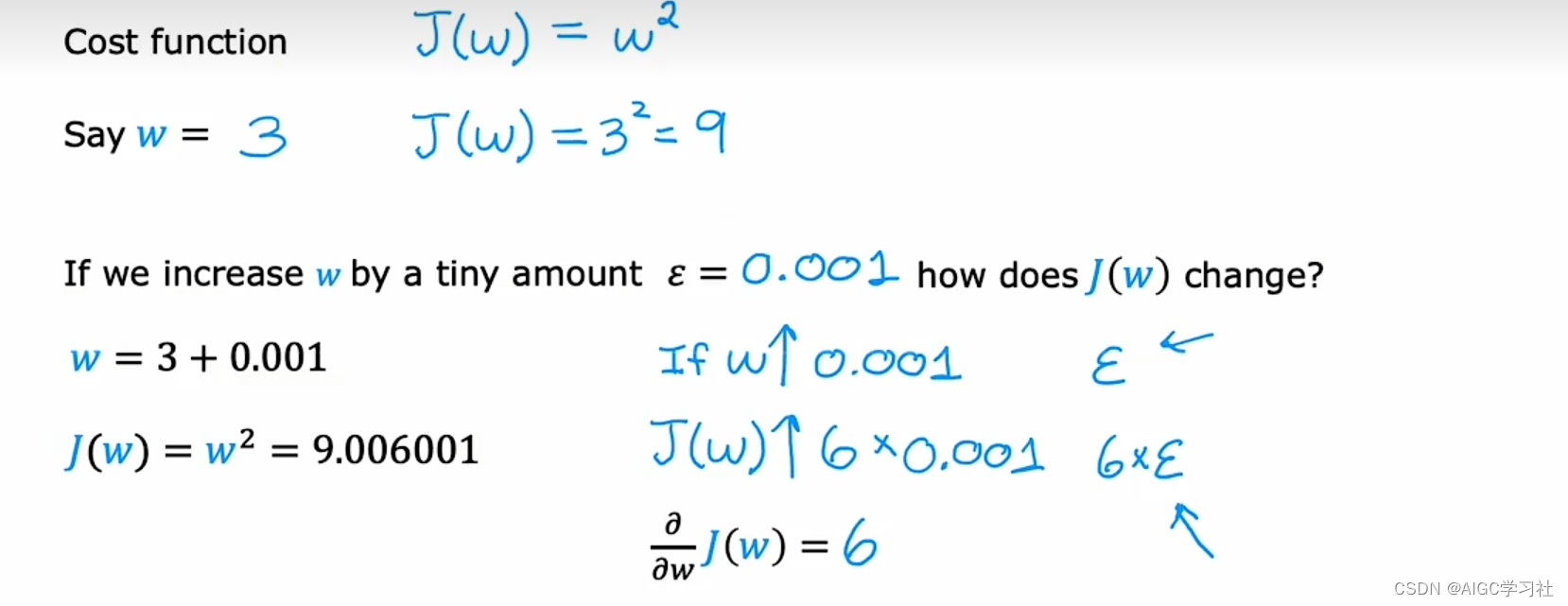
- 若epsilon = 0.002,则 w变为 3.002, J(w) 变为 9.012004。结论是,若w增加 0.002, J(w)增加约 6 倍的 0.002,即约为 9.012。虽然有少量偏差,但我们观察到J(w) 增加量与 w 增加量之间存在 6:1 的比例,这解释了J(w)关于 w 的导数为 6。随着epsilon变得更小,当 ϵ 趋近于无限小,计算出的导数值会更加精确。
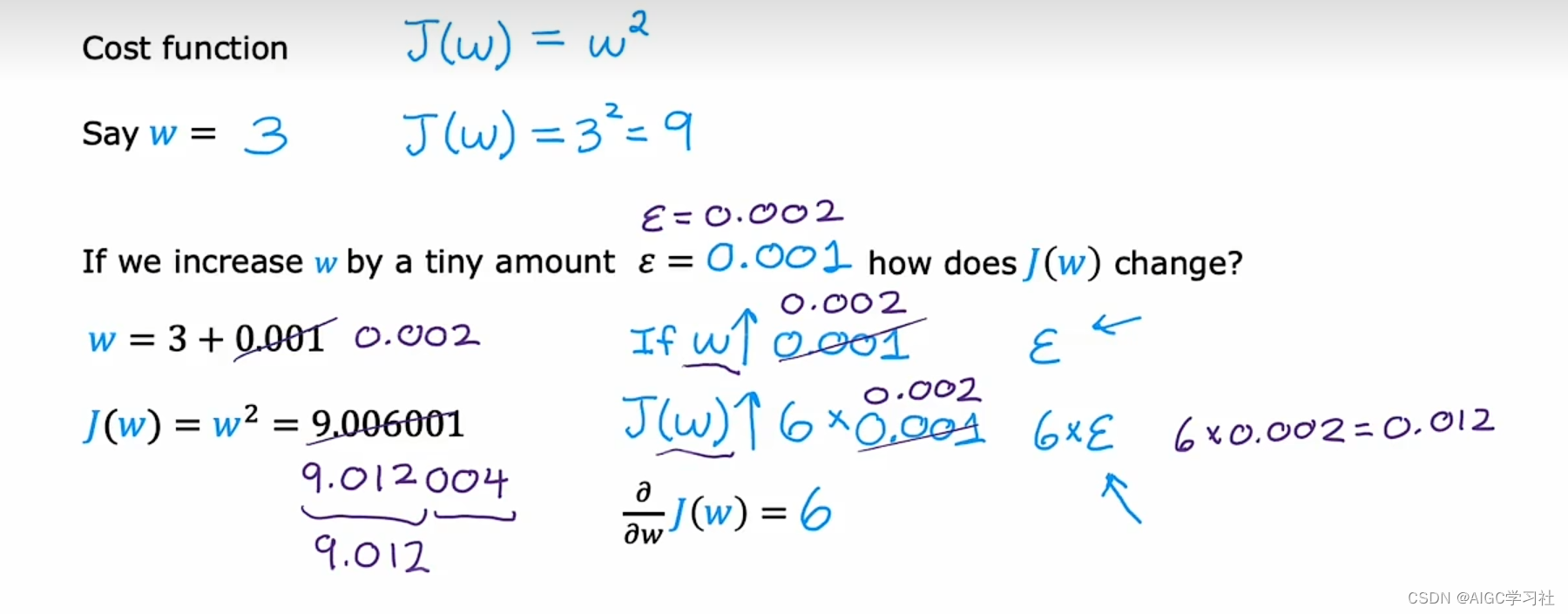
- 这引出了导数的一个非正式定义:每当 w 增加一个极小量 epsilon,导致 J(w) 增加 k 倍的 epsilon,其中 k 在我们的例子中是 6,因此 J(w) 关于 w 的导数等于 6。

1.2 设置不同的w
-
当 w = 3 且 J(w) = w^2 = 9 时,增加 w 0.001,使 J(w) 增加约 0.006,即 6 倍的 epsilon,导数为 6对 w = 2 进行类似分析, J(w) 从 4 增加到 4.004001,导数为 4。对 w = -3 进行分析, J(w) 从 9 减少到 8.994001,导数为 -6。
-
绘制 J(w) = w^2 的图像,可以看到当 w = 3 时,导数为 6;当 w = 2 时,导数为 4;当 w = -3 时,导数为 -6。这些数值是计算切线的斜率。
-
这些导数值对应于 J(w) = w^2 的导数 2w。微积分告诉我们 J(w) = w^2 的导数为 2w,所以 w 值乘以 2 就计算出这些w的导数值。

1.3 使用机器学习库自动计算导数
- 不同形式的成本函数导数如何自动计算?

- 首先导入 SymPy,使用 J 和 w 作为符号。在第一个例子中,成本函数 J 等于 w 的平方。使用 SymPy 求 J 关于 w 的导数(diff),可以得到 2w。定义变量 dJ_dw 并将其设为这个值,打印结果是 2w。如果将 w 的值代入这个表达式,如 derivative.subs(w, 2),结果是 4,解释了当 w 等于 2 时,J 的导数等于 4。
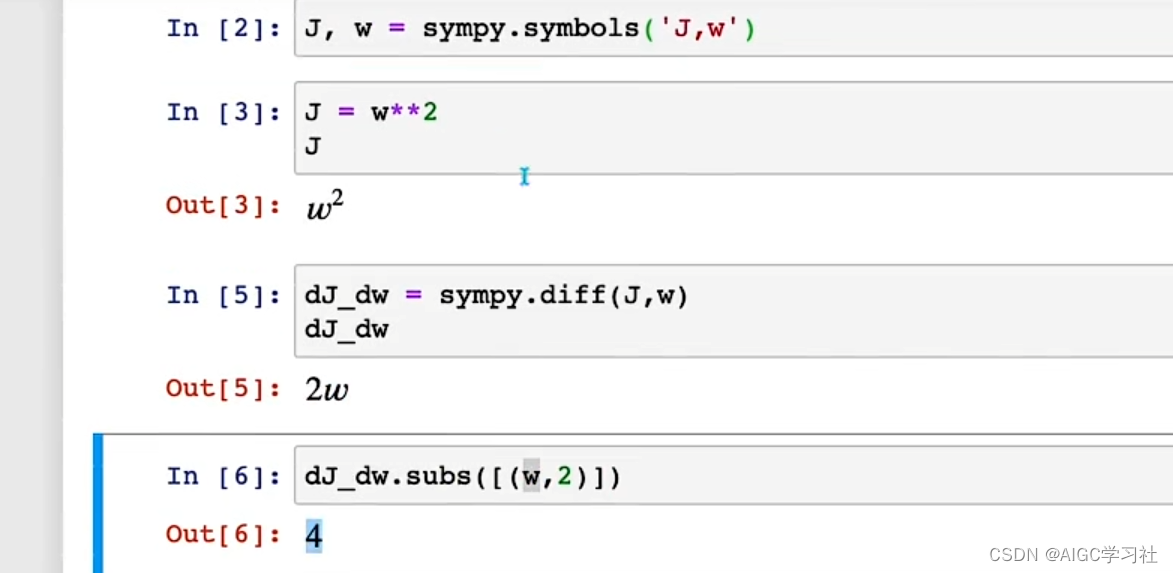
- 如果 J 是 w 的三次方,导数是 3w 的平方。根据微积分,SymPy 计算出当 J 是 w 的三次方时,J 关于 w 的导数是 3w 的平方。代入 w = 2,结果是 12。

- 如果 J 等于 w,导数是 1。

- 如果 J 是 1 除以 w,导数是 -1 除以 w 的平方。代入 w = 2,结果是 -1/4。
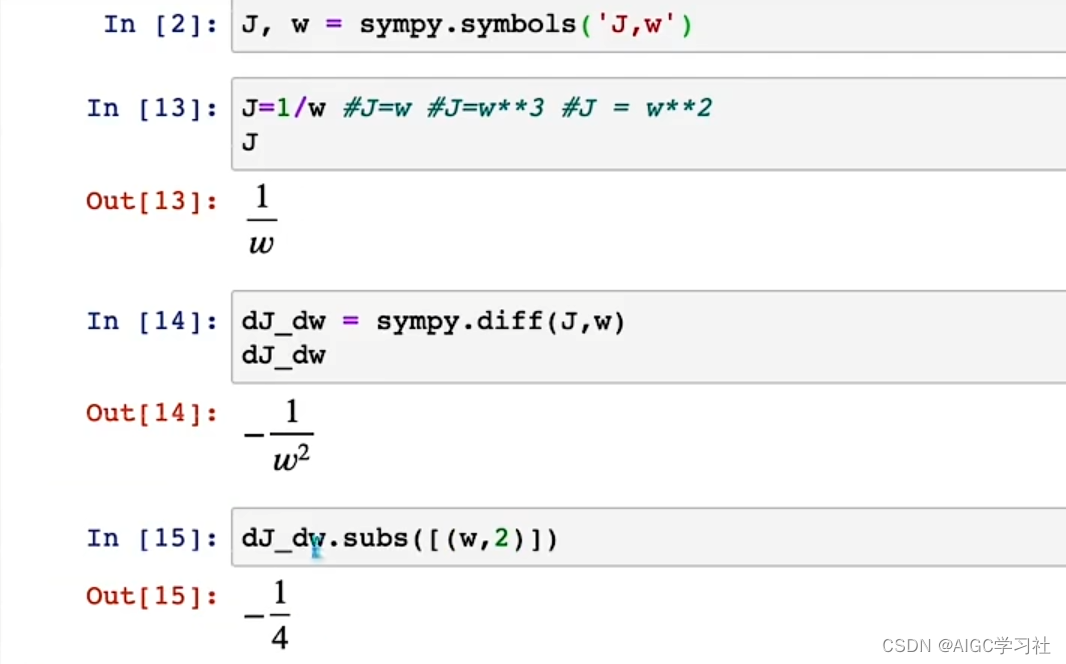
- 上述计算过程告诉我们:若 J(w) 是 w 的三次方,导数是 3w 的平方,当 w = 2 时导数等于 12。若 J(w) 等于 w,导数是 1。 若 J(w) 是 1 除以 w,导数是 -1 除以 w 的平方,当 w = 2 时导数是 -1/4。
我们验证这些表达式是否正确:对于 J(w) = w^3,当 w 增加 0.001,J(w) 从 8 增加到约 8.012,增加了 12 倍的 ε,导数是 12。对于 J(w) = w,当 w 增加 0.001,J(w) 增加 0.001,正是 ε 的值,导数是 1。对于 J(w) = 1/w,当 w 增加 0.001,J(w) 变为约 0.49975,减少了 0.00025,即 -0.25 倍的 ε,导数是 -1/4。

2.其它导数符号形式
通常使用偏导数记号更为简洁和实际。例如,J 关于 w_i 的导数常简写为 ∂J/∂w_i。

3.导数小结
导数:当w增加一个小值的Epsilon,J(w)会因此改变多少。具体来说,当 w 增加 ε 时,J(w) 按常数 k 倍的 ε 变化,这个常数 k 就是导数,取决于 J(w) 的函数形式和 w 的值。注意,并不局限于jw和w,这里只是举例,这个规则可以适用于任何函数和变量。
二.小型神经网络的计算图
1.什么是计算图(前向传播过程)
计算图是深度学习中的关键概念,通过分解计算步骤来自动计算神经网络的导数。下图是由节点和边或箭头连接组成的计算图。展示如何使用计算图从输入 x 和参数 w、b 计算输出 a,并进一步计算成本函数 j。通过将计算过程分解成多个小步骤,最终得出成本函数的值。这种方法帮助我们理解前向传播和成本计算的过程。具体过程如下:
- 首先,确定输入和参数:输入 x 和参数 w、b。
- 计算 w * x,并称其为 c。
- 计算 a = wx + b。
- 计算 a - y,并称其为 d。
- 计算成本函数 j = (1/2) * d^2。

2.反向传播计算过程
通过计算图,我们理解了前向传播的过程,现在我们想要计算 j 相对于 w 的导数以及j相对于 b 的导数。前向传播从左到右计算输出和成本函数,反向传播则从右到左计算导数,这就是为什么它被称为反向传播。通过逐步改变各个节点的值,观察成本函数的变化,我们得出了各个参数的导数。具体过程如下
-
反向传播的第一步是,如果 d 的值稍微改变,例如增加 0.001,j 的值会变化多少?如果 d 从 2 变为 2.001,则 j 从 2 变为 2.002。因此,如果 d 增加 ε,j 增加约 2 倍 ε。所以,j 对 d 的导数等于 2。
-
接着,我们计算 j 相对于 a 的导数。如果 a 增加 0.001,d 也增加 0.001,而 j 增加两倍 0.001。因此,j 对 a 的导数也等于 2。
-
接下来,我们继续从右到左计算 j 对 c 和 b 的导数。如果 c 增加 ε,a 增加 ε,而 j 增加 2 倍 ε,所以 j 对 c 的导数也是 2。同样,如果 b 增加 0.001,a 增加 0.001,j 增加 2 倍 0.001,所以 j 对 b 的导数也是 2。
-
最后,我们计算 j 对 w 的导数。如果 w 增加 0.001,c 变为 -4.002,j 变为 1.996,减少 4 倍的 0.001,所以 j 对 w 的导数为 -4。
总结一下,前向传播从左到右进行计算,反向传播从右到左计算导数,依次计算 j 相对于各个变量的导数。

3.验证反向传播的计算结果
在 w、b、x 和 y 值为图中设置的情况下,- j 等于 1/2 乘以 (2 * -2 + 8 - 2) 的平方,结果为 2。如果 w 增加 0.001,j 变为 1/2 乘以 (2.001 * -2 + 8 - 2) 的平方,结果约为 1.996002。因此,j 从 2 降至 1.996,减少了 0.004,即 4 倍的 ε。
这表明,如果 w 增加 ε,j 下降 4 倍的 ε,等价于 j 上升负 4 倍的 ε,因此 j 对 w 的导数是 -4。而 j 对 b 的导数是 2,即如果 b 增加 ε,j 上升 2 倍的 ε。
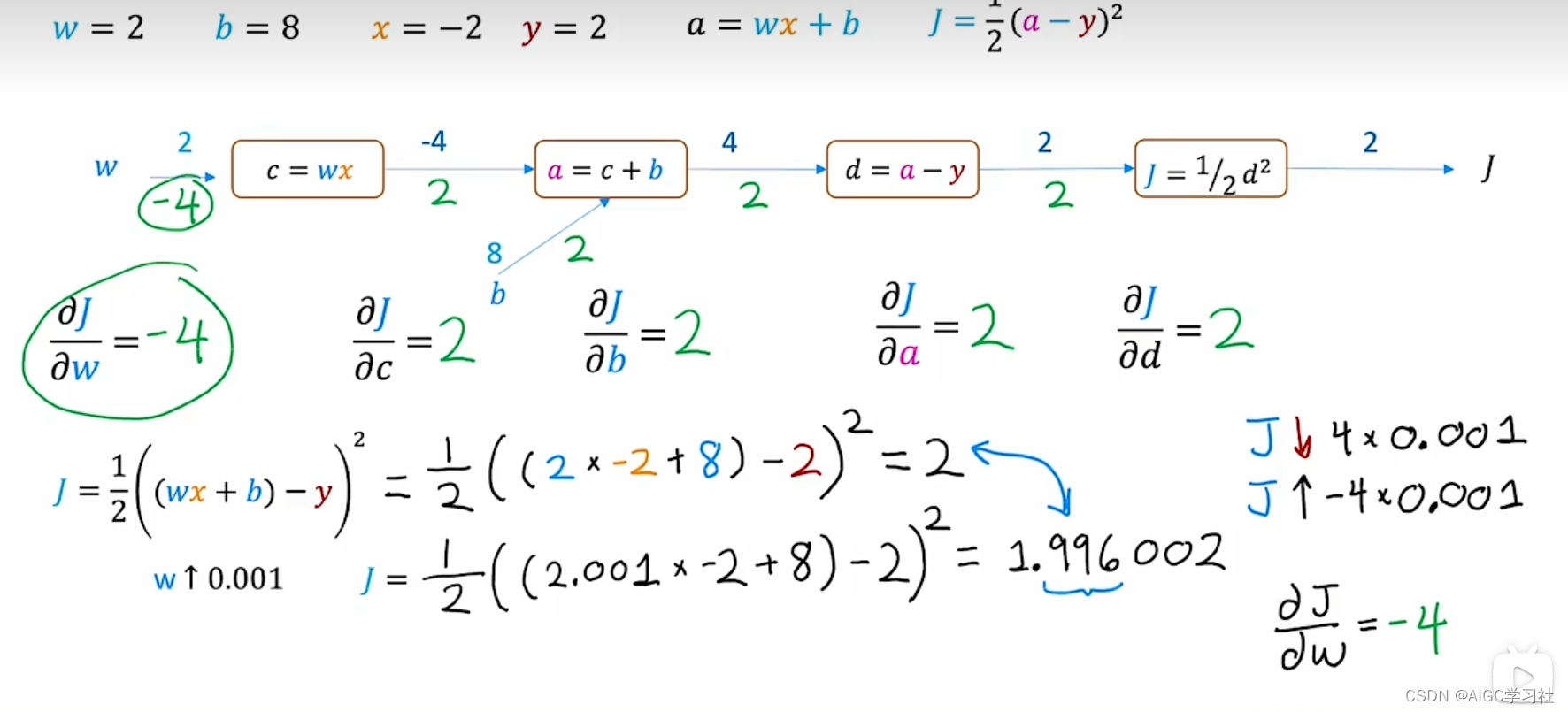
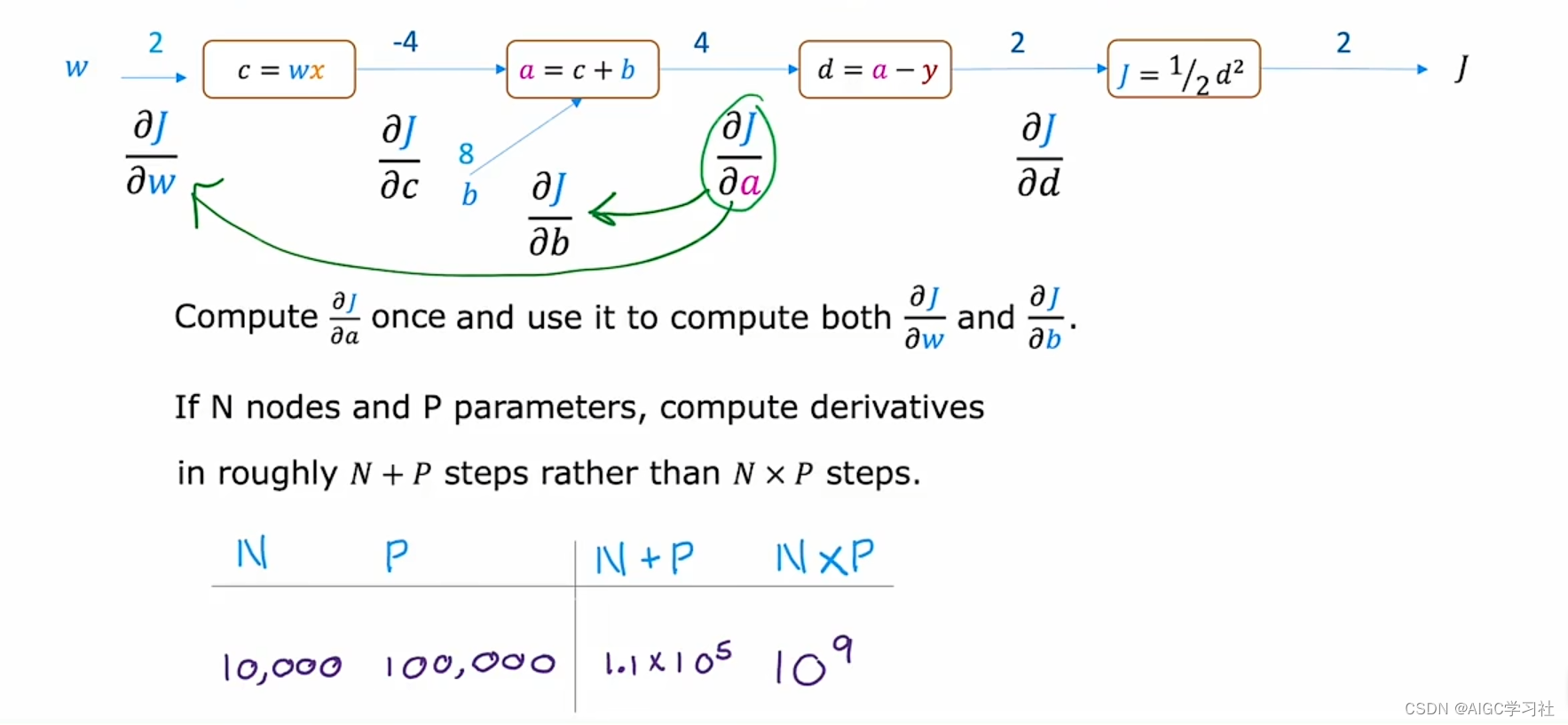
4.为什么用反向传播计算导数?
反向传播算法通过从右到左计算的方式高效地求出成本函数对各参数的导数。因为这种方法可以一步步计算中间量(如 c、a、d)和参数(如 w、b)的导数,所以只需要 n + p 步,而不是传统方法的 n 乘以 p 步,从而大大减少了计算量。
例如,对于一个有 1 万个节点和 10 万个参数的神经网络,这种方法需要 11 万步,而不是 10 亿步。因此,反向传播在大规模神经网络中应用非常高效,是深度学习算法中的一个关键概念。
三.扩大神经网络的计算图
1.计算反向传播
在更大的神经网络示例中,计算图展示了如何逐步计算神经网络的输出和成本函数,并使用反向传播计算各参数的导数。前向传播从输入计算到输出和成本函数,而反向传播则从成本函数反向计算各节点和参数的导数。
-
前向传播:
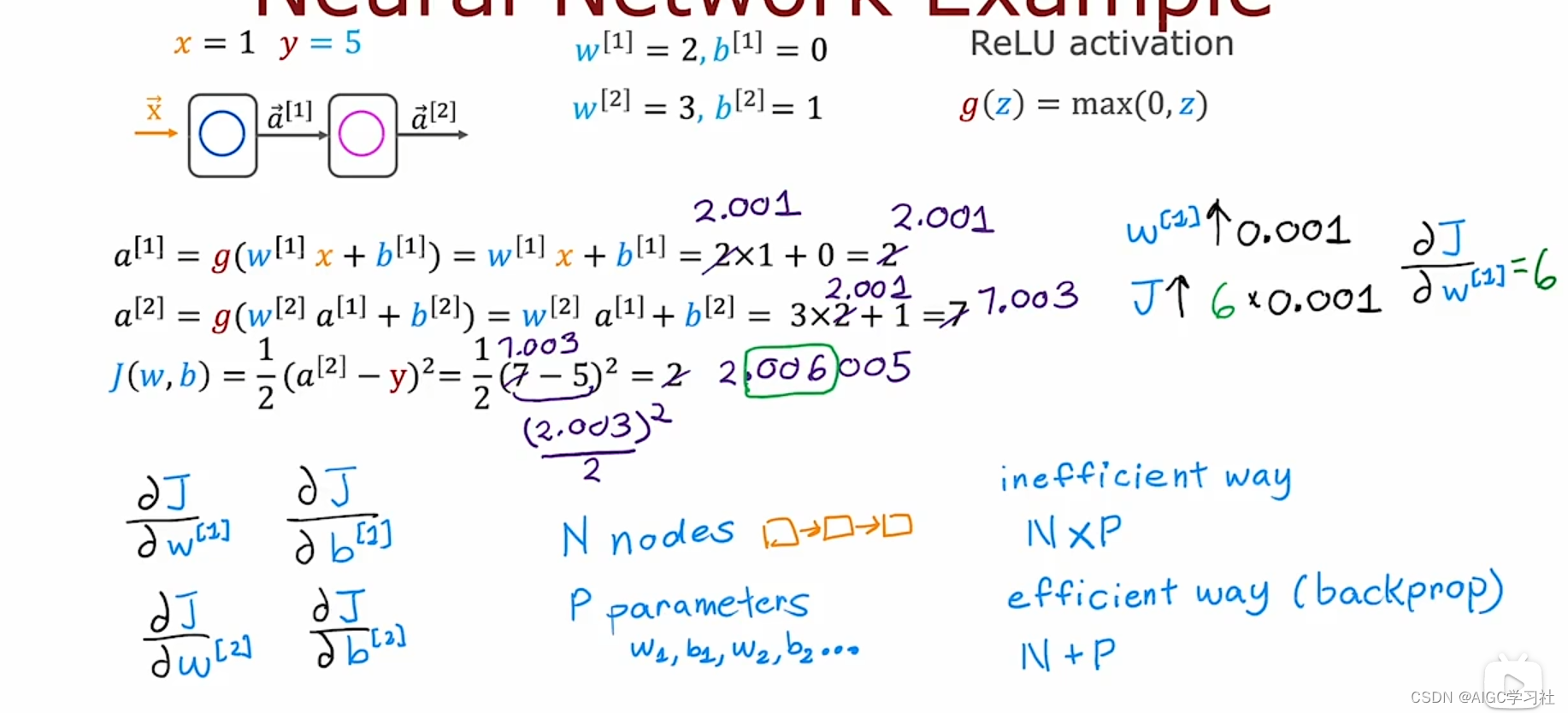
- 输入 x = 1, y = 5。
- 计算第一个隐藏单元的输出:a[1] = g(w[1] x + b[1]) = g(2 x 1 + 0) = 2。
- 计算输出层的输出:a[2] = g(w[2] a[1] + b[2]) = g(3 x 2 + 1) = 7。
- 成本函数 J(w, b) = (1/2)(a[2] - y)^2 = (1/2)(7 - 5)^2 = 2。
-
反向传播:
- 逐步计算各参数的导数,从右到左进行:
- ∂J/∂a[2] = 2
- ∂J/∂z[2] = 2
- ∂J/∂b[2] = 2
- ∂J/∂t[2] = 2
- ∂J/∂a[1] = 6
- ∂J/∂z[1] = 6
- ∂J/∂b[1] = 0
- ∂J/∂w[1] = 6
- 逐步计算各参数的导数,从右到左进行:
通过计算 J 对各个节点和参数的导数,逐步更新参数。首先计算 J 对 a2 的导数,然后逐步计算 J 对 z2、b2、t2 等等的导数。反向传播的目标是计算出 J 对所有参数 w1, b1, w2, b2 的导数。

2.验证反向传播
具体例子验证:
如果 W1 从 2 增加到 2.001,计算得到的 a1 从 2 增加到 2.001。计算 a2 得到 7.003,最终成本函数 j 从 2 增加到 2.006005。因此,验证了 j 对 W1 的导数确实等于 6。
四.总结
反向传播提供了一种高效的方法来计算所有导数,可以用于梯度下降或 Adam 优化算法,以训练神经网络的参数。反向传播计算导数的过程是从右到左进行的,而不是每次只改变一个参数并观察其对 j 的影响。
前向传播:输入数据通过网络层层传播,计算出预测结果。计算损失:比较预测结果与真实标签,计算出损失值。反向传播:从输出层开始,逐层向前计算损失函数相对于每个参数的梯度。这些梯度反映了每个参数对损失的影响。参数更新:使用梯度下降算法,根据计算出的梯度调整参数,使损失减少。常用的优化算法有梯度下降、Adam等。通过循环实现反复进行这个过程,神经网络的参数逐步优化,模型的性能逐步提高。