一文看懂Llama 2:原理、模型与训练
Llama 2是一种大规模语言模型(LLM),由Meta(原Facebook)研发,旨在推动自然语言处理(NLP)领域的发展。本文将详细介绍Llama 2的原理、模型架构及其训练方法,以帮助读者深入理解这一技术的核心概念和实现方式。
一、Llama 2的原理
1.1 语言模型的基本概念
语言模型是一种能够预测文本序列中下一个词或标记(token)的概率分布的模型。在自然语言处理任务中,语言模型可以用于文本生成、翻译、摘要等应用。Llama 2基于Transformer架构,利用深度学习技术实现了对大规模文本数据的建模和理解。
1.2 Transformer架构
Transformer是由Vaswani等人在2017年提出的一种神经网络架构,它通过自注意力机制(Self-Attention)实现对序列数据的高效处理。Transformer架构分为编码器(Encoder)和解码器(Decoder)两个部分,Llama 2采用的是纯编码器部分用于语言建模。
自注意力机制
自注意力机制是Transformer的核心,它通过计算输入序列中每个位置的表示与其他位置的相关性,来捕捉序列内部的依赖关系。自注意力机制计算公式如下:
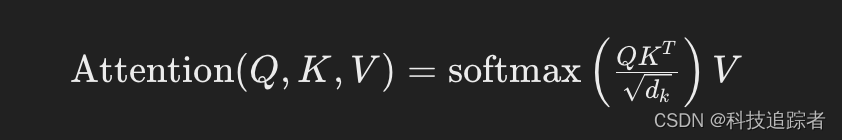
其中,(Q)、(K)和(V)分别表示查询(Query)、键(Key)和值(Value)矩阵,(d_k)是键的维度。
多头注意力
为了提高模型的表达能力,Transformer采用多头注意力机制(Multi-Head Attention),通过并行计算多组注意力,将结果拼接后再进行线性变换:
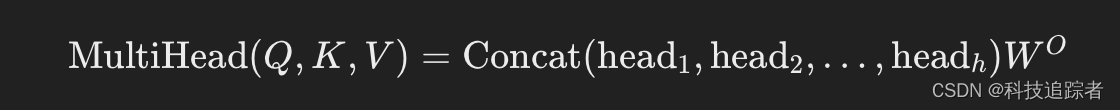
每个头(head)的计算方式与单头注意力机制相同。
1.3 预训练和微调
Llama 2采用了预训练-微调的训练范式。首先,在大规模无监督数据集上进行预训练,使模型学习到广泛的语言知识。然后,根据具体任务在有监督数据集上进行微调,使模型适应特定任务的需求。
预训练
预训练阶段,Llama 2通过自回归语言模型(Autoregressive Language Modeling)任务进行训练,即给定序列的前n个词,预测第n+1个词的概率。训练目标是最大化给定序列的条件概率:

微调
微调阶段,模型在特定任务的数据集上进行训练,例如文本分类、问答系统等。微调过程中,模型参数在保留预训练阶段学到的知识的基础上,进一步适应特定任务的数据分布和目标。
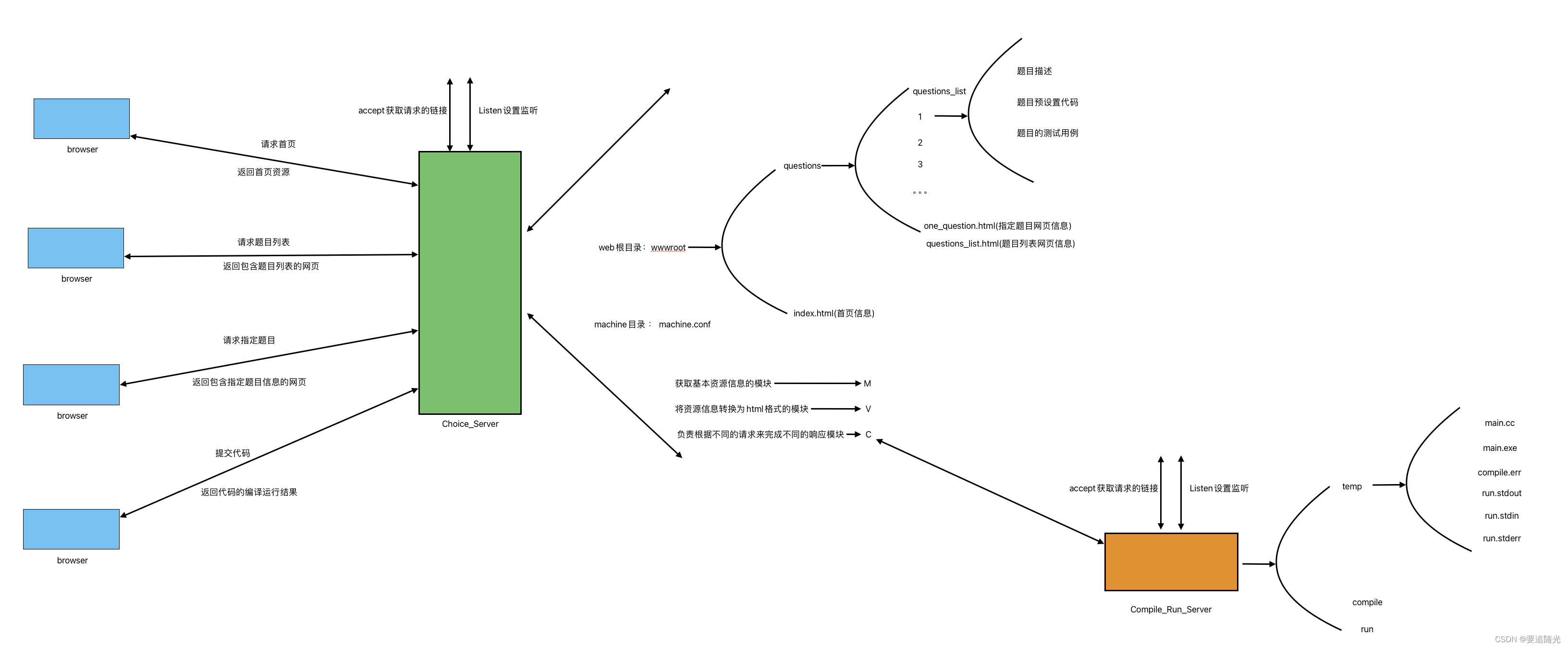
二、Llama 2的模型架构
2.1 模型层次
Llama 2的模型架构基于多层Transformer编码器,每层包含以下几个主要组件:
- 多头自注意力层(Multi-Head Self-Attention Layer):计算输入序列中每个位置的注意力分布,捕捉序列内部的依赖关系。
- 前馈神经网络(Feed-Forward Neural Network, FFN):对每个位置的表示进行非线性变换,提高模型的表达能力。
- 残差连接和层归一化(Residual Connection and Layer Normalization):通过残差连接缓解深层网络的梯度消失问题,通过层归一化加速训练收敛。
每层Transformer编码器的计算流程如下:

2.2 模型参数
Llama 2的模型参数包括以下几部分:
- 嵌入层参数(Embedding Layer Parameters):将输入词标记转换为向量表示的参数。
- 自注意力层参数(Self-Attention Layer Parameters):包括查询、键和值的线性变换矩阵,以及注意力输出的线性变换矩阵。
- 前馈神经网络参数(FFN Parameters):包括前馈网络的权重和偏置。
- 层归一化参数(Layer Normalization Parameters):包括归一化的缩放和偏移参数。
三、Llama 2的训练方法
3.1 训练数据
Llama 2的预训练数据集涵盖了广泛的领域,包括新闻、书籍、维基百科、社交媒体等。通过在大规模多样化的数据集上进行预训练,Llama 2能够学习到丰富的语言模式和知识。
3.2 训练策略
数据增强
数据增强技术在训练过程中起到了重要作用,通过引入噪声、随机掩码等方法,增强模型的泛化能力。例如,随机遮掩(Masked Language Modeling, MLM)任务,通过随机遮掩输入序列中的部分词标记,训练模型预测被遮掩的词。
梯度累积
由于Llama 2的模型参数量巨大,直接训练需要大量的计算资源。梯度累积技术通过在多个小批次上累积梯度,再进行一次反向传播,降低了单次训练的显存需求,提高了训练效率。
混合精度训练
混合精度训练通过使用半精度浮点数(FP16)和单精度浮点数(FP32)相结合的方法,减少计算和存储需求,同时保证训练的数值稳定性。具体方法是在前向传播和梯度计算中使用FP16,在梯度累积和更新参数时使用FP32。
3.3 分布式训练
Llama 2的训练采用了分布式训练技术,将计算任务分配到多个GPU和服务器上并行进行。分布式训练方法包括数据并行和模型并行:
- 数据并行(Data Parallelism):将训练数据划分为多个子集,每个GPU处理一个子集的计算任务,计算梯度后再进行全局同步。
- 模型并行(Model Parallelism):将模型参数划分为多个子集,每个GPU处理一个子集的参数计算,减少单个GPU的内存负担。
四、Llama 2的应用
Llama 2在多个自然语言处理任务中表现出色,以下是一些典型应用:
4.1 文本生成
通过自回归语言模型,Llama 2能够生成连贯、富有逻辑的文本,应用于自动写作、对话系统等领域。
4.2 机器翻译
Llama 2通过在多语言数据上进行预训练,能够实现高质量的机器翻译,支持多种语言之间的相互转换。
4.3 文本摘要
Llama 2能够对长文档进行摘要,提取关键信息,生成简洁的摘要文本,应用于新闻摘要、文档压缩等场景。
4.4 情感分析
通过微调,Llama 2能够对文本情感进行分类,识别文本中的情感倾向,应用于社交媒体监控、市场分析等领域。
4.5 问答系统
Llama 2能够根据上下文回答问题,应用于智能客服、教育辅助等场景,提高信息获取的效率。
五、Llama 2的挑战与未来
尽管Llama 2在多个任务中取得了显著进展,但仍然面临一些挑战和发展方向:
5.1 模型规模与计算资源
Llama 2的模型参数量巨大,训练和推理需要大量的计算资源,限制了其在实际应用中的部署。未来需要探索更高效的模型压缩和加速技术,降低计算成本。
5.2 数据隐私与安全
在大规模数据上进行预训练可能涉及数据隐私和安全问题,未来需要制定更加严格的数据使用规范和隐私保护措施,确保模型训练的合规性。
5.3 模型的可解释性
Llama 2作为一个黑箱模型,缺乏透明度和可解释性,难以理解其决策过程。未来需要研究可解释性技术,提高模型的透明度,增强用户对模型结果的信任。
5.4 多模
态融合
未来的语言模型将不仅局限于文本数据,还需要结合图像、音频等多模态数据,实现更全面的信息理解和生成,推动跨模态应用的发展。
六、总结
Llama 2作为一种先进的大规模语言模型,通过Transformer架构和预训练-微调范式,实现了对大规模文本数据的高效建模和理解。本文详细介绍了Llama 2的原理、模型架构及其训练方法,并探讨了其在多个自然语言处理任务中的应用和未来发展方向。随着技术的不断进步,Llama 2将继续在NLP领域发挥重要作用,推动智能应用的创新和发展。