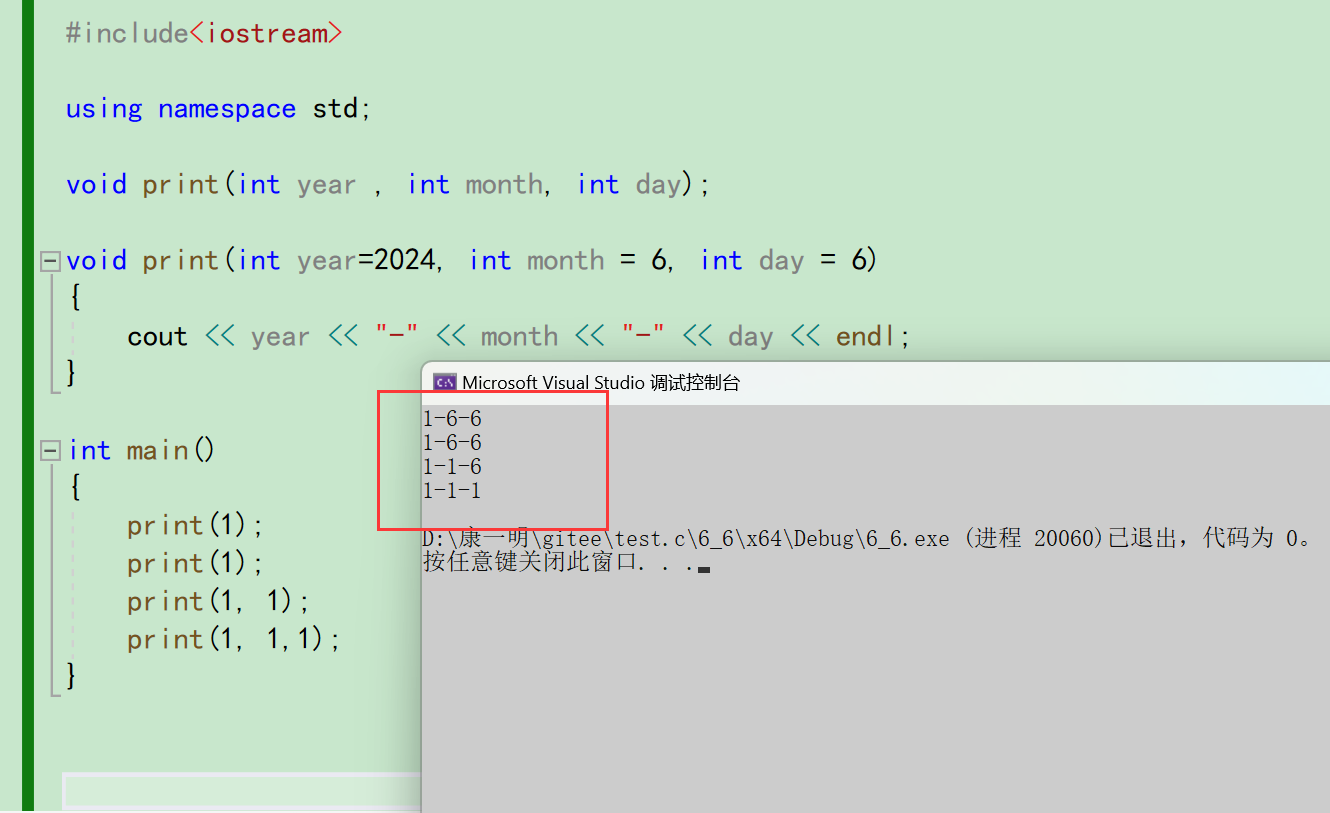
起因
前几天想给一个项目加 eslint,记得自己曾经在博客里写过相关内容,所以来搜索。但是发现 csdn 的只能按标题,没办法搜正文,所以我没搜到自己想要的内容。
没办法只能自己又重新折腾了一通 eslint,很烦躁。迁怒于 CSDN(?),所以打算写一个爬虫,自己搜。
新建项目
只想做一个很简单的爬虫,爬取我自己的 blog,获取所有文章的标题、摘要、分类、标签、内容、发布更新时间。
一说到爬虫我就想到 python,但是懒得配置 python 的开发环境了,用 nodejs 随便搞一搞吧。简单查了一下,决定用 node-crawler
npm init -y
git init
创建 .gitignore
pnpm i crawler
创建 index.js
爬取文章内容页面
此页面可以获取标题、分类、标签、正文内容。
页面中也展示了发布和更新日期,但获取较麻烦,不在此页面爬取。
// index.js
const Crawler = require("crawler");
const crawler = new Crawler();
crawler.direct({
uri: `https://blog.csdn.net/tangran0526/article/details/125663417`,
callback: (error, res) => {
if (error) {
console.error(error);
} else {
const $ = res.$; // node-crawler 内置 cheerio 包。$ 是 cheerio 包提供的,用法和 jQuery 基本一致
const title = $("#articleContentId").text();
const content = $("#article_content").text();
}
},
});
获取标题、正文很简单,通过 id 直接锁定元素,然后用 text() 获取文本内容。但是分类和标签就要复杂一点了。

对应的 html 结构是:

分类和标签的 class 都是 tag-link,只能从 attr 区分。
注意:cheerio 的 map() 返回伪数组对象,需要调用 get() 获取真数组
const categories = $(`.tag-link[href^="https://blog.csdn.net/tangran0526"]`)
.map((_i, el) => $(el).text())
.get();
const tags = $(`.tag-link[href^="https://so.csdn.net/so/search"]`)
.map((_i, el) => $(el).text())
.get();
发布和更新日期就不在详情页面获取了。因为对有更新和无更新的文章,日期的展示形式不同,而且没有特殊的 class 能锁定元素,获取起来比较麻烦。
获取文章列表
找到文章列表页面,惊喜的发现有滚动加载,也许能找到获取列表的接口。打开浏览器控制台,Network 中看到疑似请求:

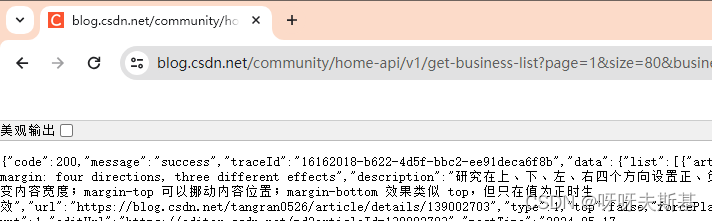
返回值为:
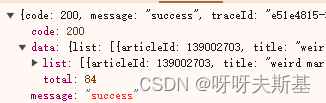
因为是 get 请求,所以可以直接把接口地址放到浏览器地址栏里访问。这样改参数看效果更直接。可以避免吭哧吭哧写代码试,最后发现参数无效或者哪有错的倒霉情况。
在地址栏里改参数发现 size 能正常工作。给它设大一点,就可以一次获取所有文章。
let url = "https://blog.csdn.net/community/home-api/v1/get-business-list";
const queryParams = {
businessType: "blog",
username: "tangran0526",
page: 1,
size: 1000, // 设大一点,一次取完所有文章
};
url += "?" + Object.entries(queryParams).map(([key, value]) => key + "=" + value).join("&");
crawler.direct({
uri: url,
callback: (error, res) => {
if (error) {
console.error(error);
} else {
console.log(res);
}
},
});
这次返回值是 json,不是 html 了。不确定返回的 res 是什么结构,node-crawler 的官方文档中有写:
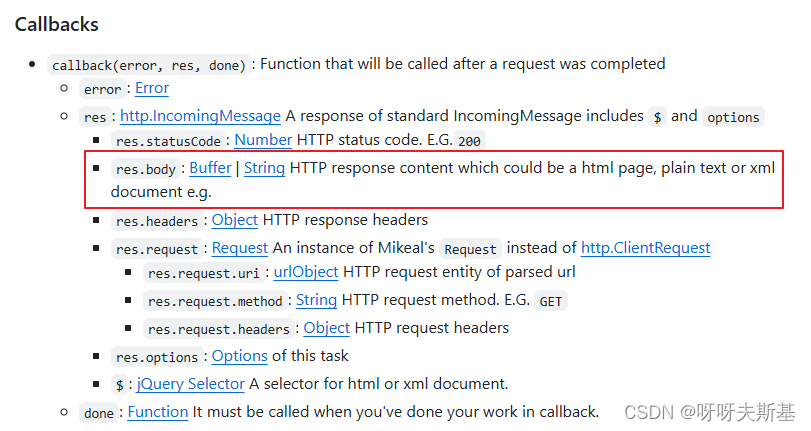
打断点查看:
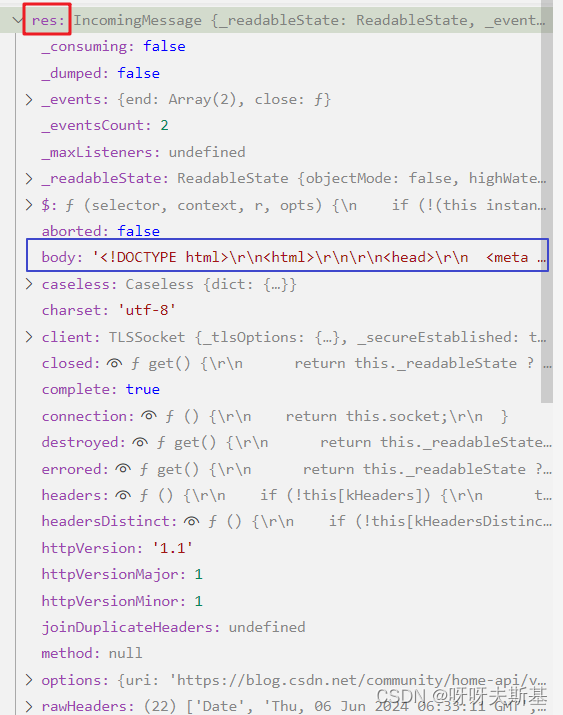
res.body 是一段 html。内容是提示:当前访问人数过多,请完成安全认证后继续访问。
应该是网站的防爬虫、防网络攻击的策略。google 了“爬虫、安全验证、验证码”等相关内容,找到了解决方法。
找到刚才用浏览器成功访问的请求,把它的 request header 全部赋给 crawler 里面的 header
crawler.direct({
uri: url,
headers: {
// 全部放这里
},
callback,
}
再次重试,res.body 是想要的结果了。现在是字符串, 再 JSON.parse 一下就可以了。

下面来精简 request headers。之前是把所有的 headers 都拿过来了,但应该不需要那么多。筛查哪些 headers 是必不可少的:
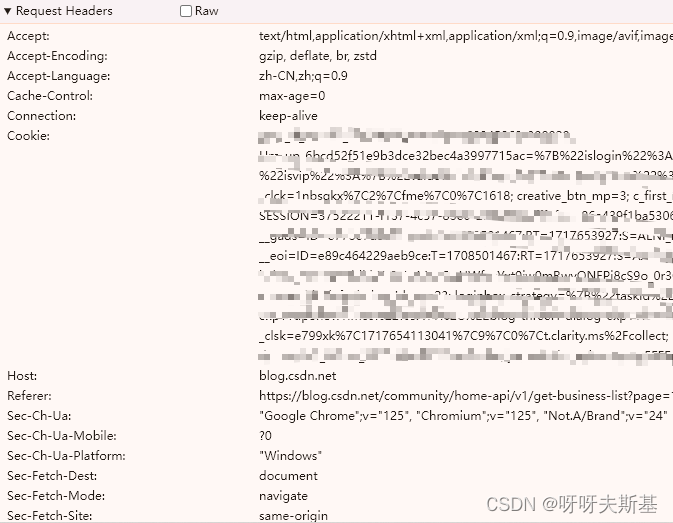
二分法排除,确认了只有 cookie 是必须的。
去浏览器中清除 cookie 后,在浏览器中重新访问接口,也弹出了这个安全验证页面。双重实锤 cookie 是关键!
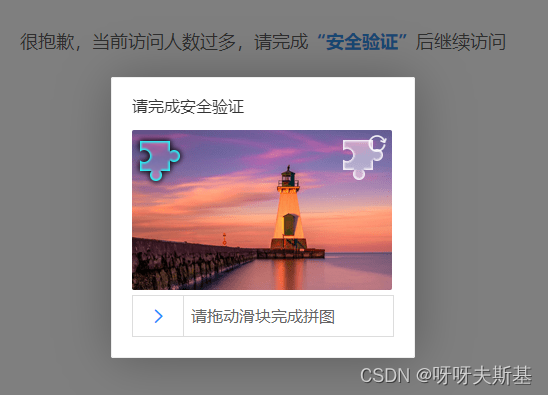
cookies 内容也很多,根据名称猜测,二分法筛查找到了两个关键cookie:

只要有它们两个,就不会触发安全验证。
const cookie_yd_captcha_token = "略";
const cookie_waf_captcha_marker = "略";
crawler.direct({
uri: url,
headers: {
Cookie: `yd_captcha_token=${cookie_yd_captcha_token}; waf_captcha_marker=${cookie_waf_captcha_marker}`,
},
callback
});
这两个 cookie 的值应该是有时效的。每次失效后都必须:打开浏览器——清除cookies后访问接口——遇到安全验证——通过后获取新的有效cookie。
所以这是一个人工爬虫——需要人力辅助的爬虫。。。。我知道这很烂,但没兴趣继续研究了,就这样吧。
如果想真正解决,应该使用 puppeteer 这类爬虫:内置 Headless Browser,可以模拟用户操作,也许能解决图形、滑块等验证。
将爬取结果输出到文件
先调用 list,再对每一篇文章获取详情。最后将结果输出到文件。
执行 node index.js,等待一会后,输出 result.json 文件:
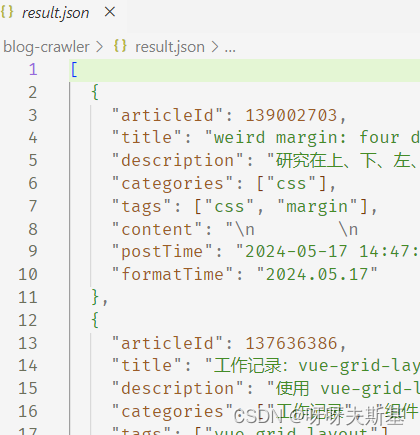
完整代码如下:
// index.js
const Crawler = require("crawler");
const { writeFile } = require("fs");
const { username, cookie_yd_captcha_token, cookie_waf_captcha_marker } = require("./configs.js");
const crawler = new Crawler();
// https://github.com/request/request
// https://github.com/bda-research/node-crawler/tree/master?tab=readme-ov-file#basic-usage
// https://github.com/cheeriojs/cheerio/wiki/Chinese-README
const articleList = [];
function getArticleList() {
let url = "https://blog.csdn.net/community/home-api/v1/get-business-list";
const queryParams = {
businessType: "blog",
username,
page: 1,
size: 1000,
};
url +=
"?" +
Object.entries(queryParams)
.map(([key, value]) => key + "=" + value)
.join("&");
return new Promise((resolve, reject) => {
crawler.direct({
uri: url,
headers: {
Cookie: `yd_captcha_token=${cookie_yd_captcha_token}; waf_captcha_marker=${cookie_waf_captcha_marker}`,
},
callback: (error, res) => {
if (error) {
reject(error);
} else {
const { code, data, message } = JSON.parse(res.body);
if (code === 200) {
resolve(data);
} else {
reject({ code, message });
}
}
},
});
});
}
function getArticleDetail(articleId) {
return new Promise((resolve, reject) => {
crawler.direct({
uri: `https://blog.csdn.net/${username}/article/details/${articleId}`,
callback: (error, res) => {
if (error) {
reject(error);
} else {
const $ = res.$;
const title = $("#articleContentId").text();
const content = $("#article_content").text();
const categories = $(`.tag-link[href^="https://blog.csdn.net"]`)
.map((_i, el) => $(el).text())
.get();
const tags = $(`.tag-link[href^="https://so.csdn.net/so/search"]`)
.map((_i, el) => $(el).text())
.get();
const articleDetail = {
title,
categories,
tags,
content,
};
resolve(articleDetail);
}
},
});
});
}
async function start() {
const { list } = await getArticleList();
for (let i = 0; i < list.length; i++) {
const { articleId, description, formatTime, postTime, title } = list[i];
const { categories, tags, content } = await getArticleDetail(articleId);
articleList.push({
articleId,
title,
description,
categories,
tags,
content,
postTime,
formatTime,
});
}
outputToJson();
}
function outputToJson() {
const path = "./result.json";
writeFile(path, JSON.stringify(articleList), (error) => {
if (error) {
console.log("An error has occurred ", error);
return;
}
console.log("Data written successfully to disk");
});
}
start();