Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
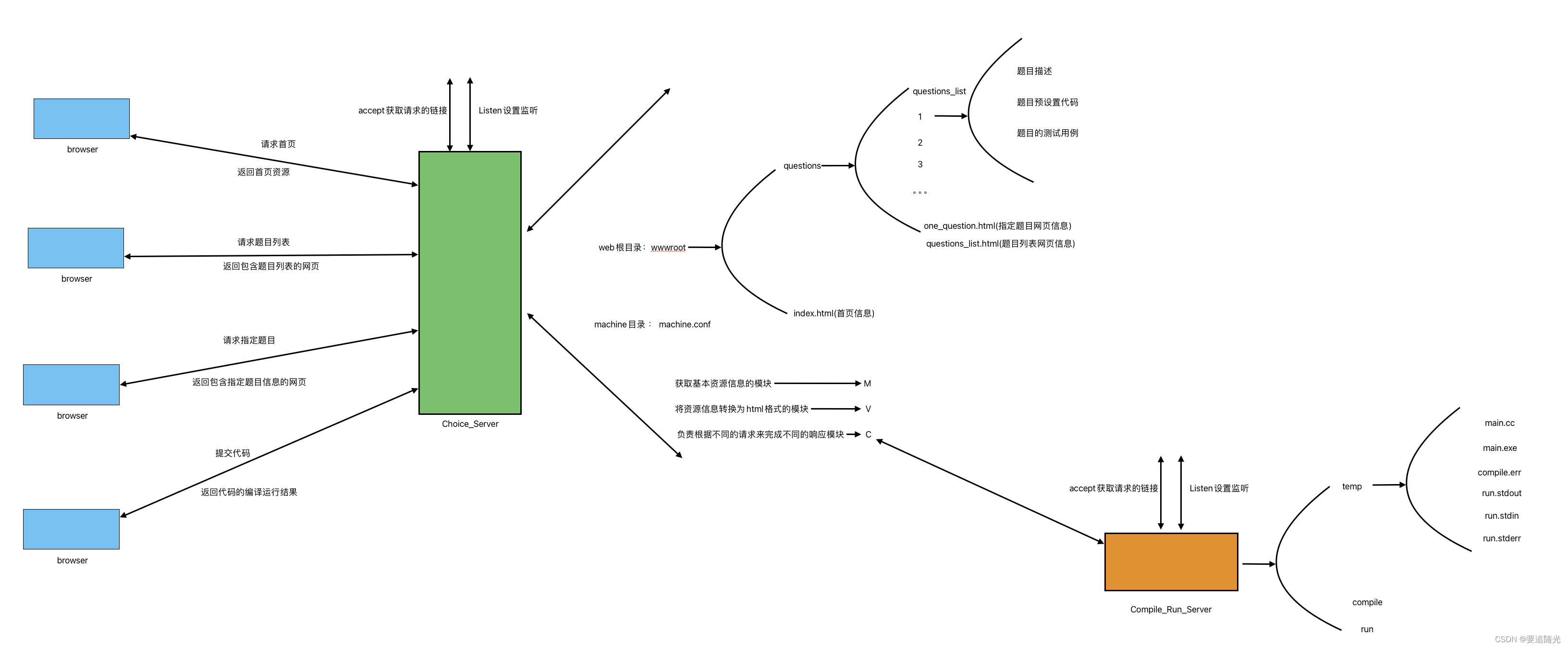
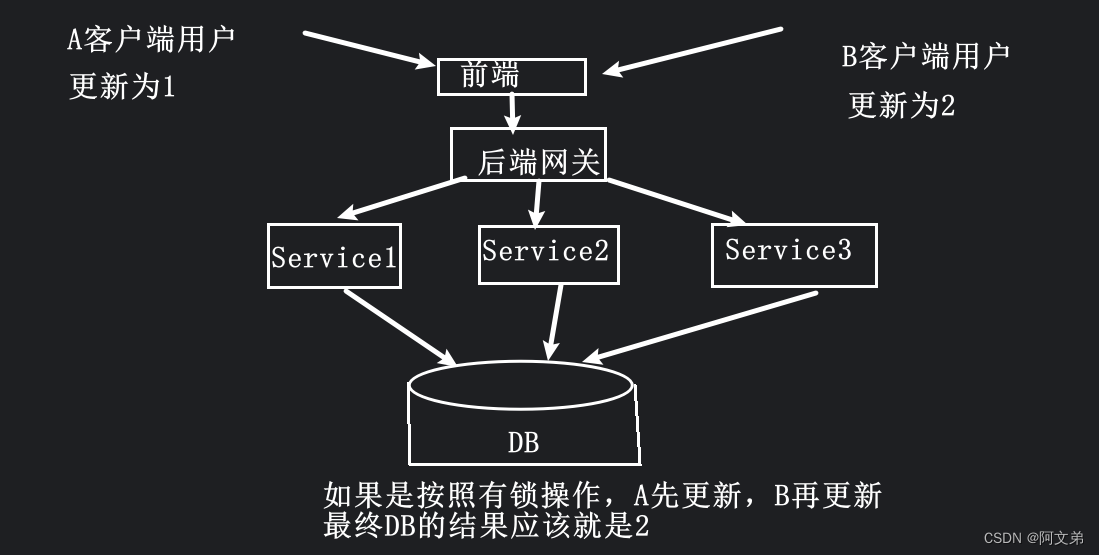
RAG结合了信息检索和文本生成两种方法,旨在突破传统问答系统的局限。通过将外部数据检索的相关信息输入大语言模型,大语言模型能够基于这些信息生成回答,进而增强答案生成的能力。RAG能够处理更广泛、更复杂的问题。使用RAG后可以有效解决大语言模型细分领域的幻觉和知识过期问题。
1、RAG的和核心组件
(1)信息检索
(2)文本生成
2、RAG工作流程
(1)最基础的RAG

(2)增加预处理查询的RAG

(3)带有聊天历史的RAG

(4)增加自动排序的RAG

3、RAG在Chatbot中的应用
(1)提高回应的相关性和准确性
(2)处理复杂查询
(3)增强个性化和上下文理解能力
4、RAG面临的挑战
(1)检索与生成的协同工作:检索到的内容与生成的内容能否紧密结合是一个关键问题。
(2)计算效率:执行检索和生成着两个步骤可能导致系统响应延迟,使整个系统的运行速度变慢,因此对时间敏感的应用而言,RAG可能不太适用。
(3)数据噪声:外部检索的数据可能带有噪声,这会影响生成内容的准确性。
5、RAG与Fine-tuning
RAG和Fine-tuning都是强大的工具,可以增强大语言模型应用的性能,但它们针对的是优化过程的不同方面。两者是截然不同的两种技术,不是替代关系,而是关联关系,在不同场景下应该选择不同的方案。
| 对比项 | RAG | Fine-tuning |
|---|---|---|
| 需要获取外部数据吗 | yes | no |
| 需要改变模型行为模式吗 | no | yes |
| 幻觉有最小化吗 | yes | no |
| 训练数据充足吗 | no | yes |
| 数据动态性高吗 | yes | no |
| 数据可解释度如何 | yes | no |
参考
- Chatbot从0到1(第2版):对话式交互实践指南
- 浅谈RAG的十大挑战