一、PyTorch和TensorFlow
1、PyTorch
PyTorch是由Facebook开发的开源深度学习框架,它在动态图和易用性方面表现出色。它以Python为基础,并提供了丰富的工具和接口,使得构建和训练神经网络变得简单快捷。
发展历史和背景
PyTorch 是由 Facebook 的 AI 研究团队开发的一个开源机器学习库,最初发布于 2016 年。它的前身是 Torch,这是一个使用 Lua 语言编写的科学计算框架。PyTorch 的出现标志着 Torch 的核心功能被转移到了 Python 这一更加流行和广泛使用的编程语言中,同时保留了原有的灵活性和强大的功能。
PyTorch 很快就因其易用性和强大的灵活性在学术界获得了广泛认可。它特别受到研究人员的青睐,因为它能够轻松地进行快速原型设计和实验。
主要特点和设计理念
动态计算图:PyTorch 的核心特点之一是其动态(也称为“即时”)计算图。这意味着图的结构在运行时是可变的,因此可以根据需要进行更改。这为研究人员提供了极大的灵活性,使他们能够使用普通的 Python 编程构造复杂的动态网络结构。
易用性:PyTorch 的另一个重要特点是其接口的直观性。它采用了 Python 的原生风格,使得代码更加容易理解和编写。同时,它提供了广泛的文档和教程,使得即使是初学者也能够相对容易地上手。
强大的社区支持:PyTorch 得益于其庞大的社区支持,社区成员不断地贡献新的库和扩展,使得 PyTorch 可以应用于计算机视觉、自然语言处理等各种领域。
与其他工具的集成:PyTorch 可以轻松地与其他流行的数据科学和机器学习工具集成,例如 NumPy、SciPy 和 Pandas。
2、TensorFlow
TensorFlow是由Google开发的深度学习框架,最初以静态图著称,但后来也引入了动态图机制。它支持多种编程语言,包括Python、C++和Java,并拥有强大的分布式计算能力。
发展历史和背景
TensorFlow 是由 Google 的 Google Brain 团队开发的,最初发布于 2015 年。它是 Theano 和 DistBelief 的直接后继者,后者是 Google 的早期分布式机器学习努力的一部分。TensorFlow 很快在工业界和学术界获得了广泛的应用,尤其是在需要大规模分布式训练和复杂模型部署的场景中。
Google 开发 TensorFlow 的主要目的是为了支持其广泛的产品和服务,包括搜索、Gmail、Google 照片等,这些服务需要处理大量的数据和复杂的模型。
主要特点和设计理念
静态计算图:TensorFlow 最初采用的是静态计算图。在这种方式中,首先定义一个图来表示计算,然后通过图来运行实际的计算。这种方法使得 TensorFlow 在优化和扩展方面非常有效,特别是在大规模的分布式系统中。
TensorFlow 2.x 的动态特性:随着 2019 年 TensorFlow 2.x 的发布,它引入了 Eager Execution,这是一种动态图机制,使得 TensorFlow 的使用更加直观和用户友好。Eager Execution 允许操作立即评估并返回它们的值,而不是构建一个待稍后执行的图。这使得 TensorFlow 对于新手更加友好,并且在某些方面与 PyTorch 更加相似。
广泛的应用范围:TensorFlow 被设计用于各种规模的项目,从小型个人项目到大型商业系统。它在移动和嵌入式设备上也有广泛的支持,尤其是通过 TensorFlow Lite 实现。
强大的工具和社区:TensorFlow 拥有强大的社区和工具生态系统,包括 TensorBoard(一种用于可视化训练过程的工具)和大量用于不同领域的预训练模型。
2024最详细的AI框架对比指南—PyTorch与TensorFlow到底选谁?-腾讯云开发者社区-腾讯云 (tencent.com)
TensorFlow vs PyTorch的优缺点与区别_tensorflow和pytorch哪个好-CSDN博客
二、DataLoader和Dataset
在使用Pytorch构建和训练模型的过程中,经常需要把原始数据(图片、文本等)转换为张量的格式。对于小数据集,我们可以手动导入,但是在深度学习中,数据集往往是比较大的,这时pytorch的数据导入功能便发挥了作用,Pytorch导入数据主要依靠 torch.utils.data.DataLoader和 torch.utils.data.Dataset这两个类来完成。
Dataset和DataLoader的作用
torch.utils.data.Dataset:这是一个抽象类,所以我们需要对其进行派生,从而使用其派生类来创建数据集。最主要的两个函数实现为__Len__和__getitem__。
__init__:可以在这里设置加载的data和label。
__Len__:获取数据集大小
__getitem__:根据索引获取一条训练的数据和标签。
torch.utils.data.DataLoader:接收torch.utils.data.Dataset作为输入,得到DataLoader,它是一个迭代器,方便我们去多线程地读取数据,并且可以实现batch以及shuffle的读取等。
构建数据集-torch.utils.data.Dataset
torch.utils.data.Dataset可通过两种方式生成,一种是通过内置的下载功能,另一种便是自己实现。下载功能需要借助一些其他的包,比如torchvision,下载CIFAR10数据格式大致如下:
import torch
import torchvision
train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=dataset_transform, download=True)
创建一个属于自己的数据集
任何自定义的数据集都要继承自torch.utils.data.Dataset,然后重写两个函数:__len__(self)和__getitem__(self, idx)。
下面是一个简单的自定义小型数据集,以期能够理解它的创建方式。注意下面的示例中并没有通过__init__传入data和label,而是在内部创建的。
import torch
from torch.utils.data import Dataset
class myDataset(Dataset):
def __init__(self):
#创建5*2的数据集
self.data = torch.tensor([[1,2],[3,4],[2,1],[3,4],[4,5]])
#5个数据的标签
self.label = torch.tensor([0,1,0,1,2])
#根据索引获取data和label
def __getitem__(self,index):
return self.data[index], self.label[index] #以元组的形式返回
#获取数据集的大小
def __len__(self):
return len(self.data)
data = myDataset()
print(f'data size is : {len(data)}')
print(data[1]) #获取索引为1的data和label
输出:
data size is : 5
(tensor([3, 4]), tensor(1))
数据载入-torch.utils.data.DataLoader
torch.utils.data.Dataset通过__getitem__获取单个数据,如果希望获取批量数据、shuffle或者其它的一些操作,那么就要由torch.utils.data.DataLoader来实现了,它的实现形式如下:
data.DataLoader(
dataset,
batch_size = 50,
shuffle = False,
sampler=None,
batch_sampler = None,
num_workers = 0,
collate_fn =
pin_memory = False,
drop_last = False,
timeout = 0,
worker_init_fn = None,
)
dataset(必需):用于加载数据的数据集,通常是torch.utils.data.Dataset的子类实例。
batch_size (可选):每个batch有多少个样本,默认值为1。
shuffle (可选):代表数据会不会被随机打乱,在每个epoch开始的时候,对数据进行重新排序。默认为False。False不打乱
sampler(可选):自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(可选):与sampler类似,但一次返回一个批次的索引。不能与batch_size、shuffle和sampler同时使用。
num_workers (可选):是数据载入器使用的进程数目,默认为0,意味着数据将在主进程中加载。
collate_fn(可选):用于自定义sample 如何形成 batch sample 的函数。因为getitem只是得到一条数据,collate_fun组成一个batch数据
pin_memory:如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中。
drop_last(可选):如果设置为true,那么最后的batch的大小如果小于batch_size,那么则会丢弃。默认为False。
timeout(可选):如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0。
worker_init_fn(可选):它决定了每个数据载入的子进程开始时运行的函数
pytorch中的数据导入之DataLoader和Dataset的使用介绍_dataloader 能不能放到gpu上-CSDN博客
Dataloader重要参数与内部机制_dataloader参数-CSDN博客
三、TensorBoard可视化工具
TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。它通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
什么是 TensorBoard?
TensorBoard 是一组用于数据可视化的工具。它包含在流行的开源机器学习库 Tensorflow 中。TensorBoard 的主要功能包括:
(1)可视化模型的网络架构
(2)跟踪模型指标,如损失和准确性等
(3)检查机器学习工作流程中权重、偏差和其他组件的直方图
(4)显示非表格数据,包括图像、文本和音频
(5)将高维嵌入投影到低维空间
TensorBoard算是包含在 TensorFlow中的一个子服务。 TensorFlow 库是一个专门为机器学习应用程序设计的开源库。 Google Brain 于 2011 年构建了较早的 DistBelief 系统。随着其用户群的快速增长,它被简化并重构为我们现在称为 Tensorflow 的库。 TensorFlow 随后于 2015 年向公众发布。TensorBoard刚出现时只能用于检查TensorFlow的指标和TensorFlow模型的可视化,但是后来经过多方的努力其他深度学习框架也可以使用TensorBoard的功能
调用 tensorboard --logdir=你创建的文件夹名字
列如:tensorboard --logdir=logs --port=6007
tensorboard涉及的类:SummaryWriter
全称是:torch.utils.tensorboard.SummaryWriter
常用的方式就是:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
writer.add_image('test', img_array,2, dataformats="HWC")
writer.close() #一定要记得关闭`SummaryWriter` 类提供了一个高级 API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。 该类异步更新文件内容。 这允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度。
(傻瓜教程)TensorBoard可视化工具简单教程及讲解(TensorFlow与Pytorch)_tensorboard可视化梯度参数怎么看-CSDN博客Tensorboard的使用 ---- SummaryWriter类(pytorch版)-CSDN博客
四、Transformer
Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构,它在2017年由Vaswani等人首次提出。Transformer架构引入了自注意力机制(self-attention mechanism),这是一个关键的创新,使其在处理序列数据时表现出色。
Transformer的一些重要组成部分和特点:
1、自注意力机制(Self-Attention):这是Transformer的核心概念之一,它使模型能够同时考虑输入序列中的所有位置,而不是像循环神经网络(RNN)或卷积神经网络(CNN)一样逐步处理。自注意力机制允许模型根据输入序列中的不同部分来赋予不同的注意权重,从而更好地捕捉语义关系。
2、多头注意力(Multi-Head Attention):Transformer中的自注意力机制被扩展为多个注意力头,每个头可以学习不同的注意权重,以更好地捕捉不同类型的关系。多头注意力允许模型并行处理不同的信息子空间。
3、堆叠层(Stacked Layers):Transformer通常由多个相同的编码器和解码器层堆叠而成。这些堆叠的层有助于模型学习复杂的特征表示和语义。
4、位置编码(Positional Encoding):由于Transformer没有内置的序列位置信息,它需要额外的位置编码来表达输入序列中单词的位置顺序。
残差连接和层归一化(Residual Connections and Layer Normalization):这些技术有助于减轻训练过程中的梯度消失和爆炸问题,使模型更容易训练。
5、编码器和解码器:Transformer通常包括一个编码器用于处理输入序列和一个解码器用于生成输出序列,这使其适用于序列到序列的任务,如机器翻译。
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客
The Annotated Transformer的中文注释版(1) - 知乎 (zhihu.com)
torchvision
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision.transforms主要是用于常见的一些图形变换。以下是torchvision的构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
Transformer的使用
1、transforms.ToTensor()
torchvision.transforms 数据预处理:ToTensor()-CSDN博客
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/bees_image/17209602_fe5a5a746f.jpg')
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image('ToTensor', img_tensor)
writer.close()2、数据归一化处理transforms.Normalize()
Normalize — Torchvision main documentation (pytorch.org)
数据归一化处理transforms.Normalize()-CSDN博客
torchvision中Transform的normalize参数含义, 自己计算mean和std,可视化后的情况,其他必要的数据增强方式_transforms.normalize(mean=[0.485, 0.456, 0.406], s-CSDN博客
功能:逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
output = (input - mean) / std
mean:各通道的均值
std:各通道的标准差
inplace:是否原地操作
3、指定图像的大小torchvision.transforms.Resize()
Resize — Torchvision main documentation (pytorch.org)
torchvision.transforms.Resize() 是 PyTorch 中 torchvision 库中的一个数据预处理类,用于将 PIL.Image 或者 ndarray 转换成指定大小的图像。
Pytorch transforms.Resize()的简单用法_torchvision.transforms.resize-CSDN博客
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/bees_image/17209602_fe5a5a746f.jpg')
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize) #img_resize PIL->tensor
print(img_resize)
writer.add_image('Resize', img_resize,0)
writer.close()4、 数据变换组合torchvision.transforms.Compose()
Compose — Torchvision main documentation (pytorch.org)
transforms.Compose是PyTorch中的一个实用工具,用于创建一个包含多个数据变换操作的变换对象。这些变换操作通常用于数据预处理,例如图像数据的缩放、裁剪、旋转等。使用 transforms.Compose 可以将多个数据变换组合在一起,以便将它们应用于数据。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/bees_image/17209602_fe5a5a746f.jpg')
# compose()中的参数需要是一个列表
# 在compose中, 参数数据是 transforms类型
# compose - resize -2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2,1)
writer.close()5、随机裁剪torchvision.transforms.RandomCrop
RandomCrop — Torchvision main documentation (pytorch.org)
transforms.RandomCrop()是PyTorch中的一个数据增强操作,用于随机裁剪图像。它可以在图像的任意位置随机裁剪出指定大小的图像,并返回裁剪后的图像。这个操作可以增加数据集的多样性,提高模型的泛化能力。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/bees_image/17209602_fe5a5a746f.jpg')
# RandomCrop
trans_totensor = transforms.ToTensor()
trans_random = transforms.RandomCrop(100)
#其中trans_compose_2将会对输入的图像进行随机裁剪为100 x 100大小的正方形,
#并将其转换为Tensor格式。
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
6、其他参考
torchvision.transforms - PyTorch中文文档 (pytorch-cn.readthedocs.io)
torchvision.transforms 常用方法解析(含图例代码以及参数解释)_torchvision 斜切-CSDN博客
五、图像处理 PIL
Python Pillow PIL 库的用法介绍,Pillow库是一个Python的第三方库。
PIL库是一个具有强大图像处理能力的第三方库,不仅包含了丰富的像素、色彩操作功能,还可以用于图像归档和批量处理。
PIL库支持图像存储、显示和处理,它能够处理几乎所有图片格式,可以完成对图像的缩放、剪裁、叠加以及向图像添加线条、图像和文字等操作。
PIL库主要可以实现图像归档和图像处理两方面动能需求:
(1)图像归档:对图像进行批处理、生成图像预览、图像格式转换等。
(2)图像处理:图像基本处理、像素处理、颜色处理等。
1、安装
pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple2、PIL库 Image 类解析
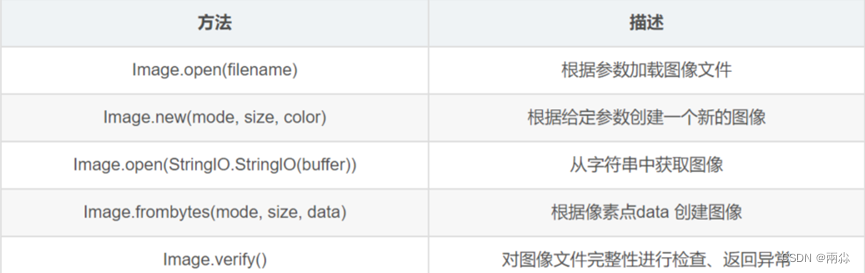
Image是PIL最重要的类,它代表一张图片,引入这个类的方法如下:
from PIL import Image在 PIL 中,任何一个图像文件都可以用 Image 对象表示。Image类的图像读取和创建方法如下(共5个):
Python 图像处理 PIL 第三方库详细使用教程(更新中)-CSDN博客
六、OpenCV
什么是OpenCV,它有什么作用?
OpenCV(全称为Open Source Computer Vision Library)是一个开源的计算机视觉库,由英特尔公司发起并开发,支持多种编程语言(如C++、Python、Java等),旨在为计算机视觉领域的研究、开发和应用提供一组通用的工具和算法。
OpenCV可以用于处理数字图像和视频数据,其功能包括图像和视频的读取、写入、显示、变换、滤波、特征提取、目标检测、人脸识别、物体跟踪、相机标定、三维重建、机器学习等。
OpenCV最初由Intel开发,现在已经成为了一个开源项目,其源代码可以免费获取和使用。
OpenCV提供了许多计算机视觉中常用的算法和工具,例如:
-
读取和保存图像和视频数据
-
图像和视频的显示、缩放、剪切和旋转等操作
-
直方图均衡化、图像滤波和形态学操作等图像处理技术
-
特征提取和描述符匹配算法,如SIFT和SURF等
-
目标检测和跟踪算法,如Haar Cascade和MeanShift等
-
人脸检测和识别算法,如LBPH和FisherFace等
-
相机标定和三维重建算法,如SfM和PnP等
-
机器学习算法,如SVM、KNN和随机森林等
除了以上的功能,OpenCV还有一个重要的特点就是跨平台性,可以在Windows、Linux、macOS等操作系统上运行,并且支持多种编程语言,如C++、Python和Java等。
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
OpenCV-Python是一个Python绑定库,旨在解决计算机视觉问题。
OpenCV-Python使用了Numpy,这是一个高度优化的库,用于使用MATLAB风格的语法进行数值运算。所有OpenCV数组结构都可以转换为Numpy数组。这也使得它更容易与其他使用Numpy的库集成,如SciPy和Matplotlib。
OpenCV最详细入门(一)-python(代码全部可以直接运行)_opencv python-CSDN博客



![[行业原型] 汽车供应链多地分销一站式云端解决方案](https://img-blog.csdnimg.cn/img_convert/d58d8c5ecb572aa036843ca6b02a1a8a.jpeg)