像OpenAI的ChatGPT、谷歌的Gemini Ultra这样的高级AI模型,训练它们通常需要数百万美元的费用,且该成本还在迅速上升。随着计算需求的增加,训练它们所需的计算能力的费用也在飙升。为此,AI公司正在重新考虑如何训练这些生成式AI系统。在许多情况下,这些策略包括在当前的增长轨迹下降低计算成本。

训练成本是如何确定的?
斯坦福大学与研究公司Epoch AI合作,根据云计算租金估算了AI模型的训练成本。双方所分析的关键因素包括模型的训练时长、硬件的利用率和训练硬件的价值。
尽管许多人猜测,训练AI模型的成本变得越来越高,但缺乏全面的数据来支持这些说法。而斯坦福大学发布的《2024年AI指数报告》正是支持这些说法的罕见来源之一。
不断膨胀的训练成本
下表展示了自2017年以来,经通胀调整后的主要AI模型的培训成本:
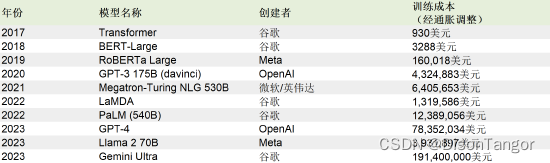
去年,OpenAI的GPT-4培训成本估计为7840万美元,远高于谷歌PaLM (540B) 的训练成本。谷歌PaLM较GPT-4仅早一年推出,但训练成本为1240万美元。
相比之下,2017年开发的早期AI模型Transformer的训练成本为930美元。该模型在塑造当前所使用的许多大型语言模型的体系结构方面起着基础性作用。
谷歌的AI模型Gemini Ultra的训练成更高,达到了惊人的1.91亿美元。截至2024年初,该模型在几个指标上都超过了GPT-4,最引人注目的是在“大规模多任务语言理解”(MMLU)基准测试中胜出。这一基准是衡量大型语言模型能力的重要标尺。例如,它以评估57个学科领域的知识和解决问题的熟练程度而闻名。
训练未来的AI模型
鉴于这些挑战,AI公司正在寻找新的解决方案来训练语言模型,以应对不断上涨的成本。
其中的方法有多种,比如创建用于执行特定任务的较小模型,而其他一些公司正在试验创建自家的合成数据来“投喂”AI系统。但到目前为止,这方面还没有取得明确的突破。
例如,使用合成数据的AI模型有时会“胡言乱语”,引发所谓的“模型崩溃”。





![[数据集][目标检测]脑溢血检测数据集VOC+YOLO格式767张2类别](https://img-blog.csdnimg.cn/direct/abad72cb94ea4462aa6ae3cd81cca51f.png)