一、线性回归
1.算法执行流程:
算法的执行流程可以简述如下:
- 导入必要的库:
- 导入NumPy库,用于数值计算。
- 导入Matplotlib库,用于数据可视化。
- 导入Pandas库,用于数据处理(尽管在这个例子中,Pandas主要用于读取CSV文件,但并未在后续训练模型中使用)。
- 导入Scikit-learn库中的LinearRegression模型,用于线性回归模型的训练。
- 定义真实函数:
- 定义了一个名为
true_fun的函数,该函数表示数据的真实模型(ground truth)。- 设置随机种子和样本数量:
- 使用
np.random.seed(0)设置随机种子,以确保结果的可复现性。- 设置
n_samples为30,表示生成的训练样本数量。- 生成随机数据作为训练集:
- 在0到1之间随机生成
n_samples个排序后的点,作为X_train。- 根据
true_fun函数计算y值,并加上一些随机噪声(标准差为0.05的正态分布),得到y_train。- 读取CSV文件(但此部分数据并未在后续模型训练中使用):
- 使用Pandas的
read_csv函数读取名为'Salary_dataset.csv'的文件。- 提取数据集中的某些列作为X和Y(尽管这部分数据在后续并未被使用)。
- 定义并训练模型:
- 实例化LinearRegression模型。
- 使用X_train和y_train数据训练模型。
- 输出模型参数:
- 打印出模型的权重(w)和截距(b)。
- 生成测试数据并可视化:
- 生成一个从0到1的等差数列作为X_test,用于可视化。
- 使用训练好的模型对X_test进行预测。
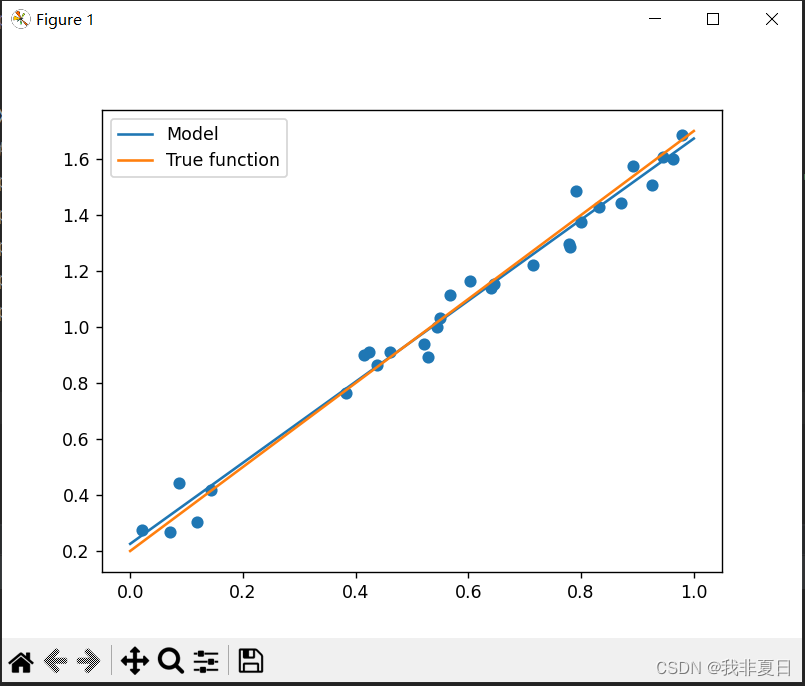
- 使用Matplotlib绘制真实函数、模型预测结果以及训练数据点。
- 显示图形:
- 使用Matplotlib的
show函数显示绘制的图形。需要注意的是,虽然算法读取了CSV文件,但在后续的模型训练和可视化过程中,并没有使用这些数据。模型是基于随机生成的带有噪声的数据进行训练和可视化的。如果目的是使用CSV文件中的数据进行训练和可视化,那么应该使用这些数据替换掉随机生成的数据。
2.代码:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd #
from sklearn.linear_model import LinearRegression # 导入线性回归模型
def true_fun(X): # 这是我们设定的真实函数,即ground truth的模型
return 1.5*X + 0.2
np.random.seed(0) # 设置随机种子
n_samples = 30 # 设置采样数据点的个数
'''生成随机数据作为训练集,并且加一些噪声'''
X_train = np.sort(np.random.rand(n_samples))
y_train = (true_fun(X_train) + np.random.randn(n_samples) * 0.05).reshape(n_samples,1)
# print(X_train)
# print(y_train)
'''读取csv文件'''
df = pd.read_csv('Salary_dataset.csv')
X = df.iloc[:, 1:2]
Y = df.iloc[:, 2:3]
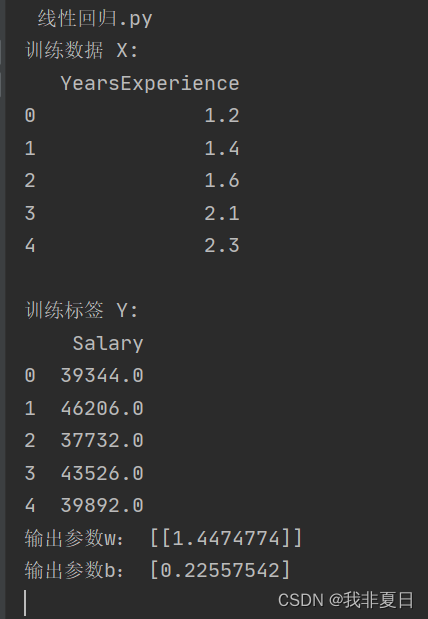
print("训练数据 X:")
print(X.head())
print("\n训练标签 Y:")
print(Y.head())
#exit()
model = LinearRegression() # 定义模型
model.fit(X_train[:,np.newaxis], y_train) # 训练模型
print("输出参数w:",model.coef_) # 输出模型参数w
print("输出参数b:",model.intercept_) # 输出参数b
X_test = np.linspace(0, 1, 100)
# print(X_test)
plt.plot(X_test, model.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), label="True function")
plt.scatter(X_train,y_train) # 画出训练集的点
plt.legend(loc="best")
plt.show()3.结果:
二、贝叶斯分类
1.算法执行流程:
代码执行流程简述如下:
- 导入必要的库:
- 导入
numpy用于数值计算。- 导入
matplotlib.pyplot用于绘图。- 导入
seaborn并设置默认样式。- 导入
sklearn.datasets中的make_blobs函数用于生成模拟数据集。- 导入
sklearn.naive_bayes中的GaussianNB类用于构建朴素贝叶斯分类器。- 生成随机数据:
- 使用
make_blobs函数生成一个包含100个样本、2个特征、2个中心点的模拟数据集。- 样本点围绕两个中心点随机分布,标准差为1.5。
- 绘制原始数据散点图:
- 使用
plt.scatter函数绘制原始数据的散点图,其中x轴和y轴分别对应数据集中的两个特征。- 使用
c=y参数将数据点的颜色根据其对应的类别(标签)设置。- 展示绘制的图形。
- 构建并训练朴素贝叶斯分类器:
- 实例化
GaussianNB类,创建一个高斯朴素贝叶斯分类器对象。- 使用
model.fit(X, y)方法训练分类器。- 生成测试集:
- 创建一个固定点
[-6, -14]和一个随机点集[14, 18] * rng.rand(2000, 2),其中rng是一个随机状态为0的随机数生成器。- 将这两个点集合并形成测试集
X_test。- 对测试集进行预测并绘制结果:
- 使用
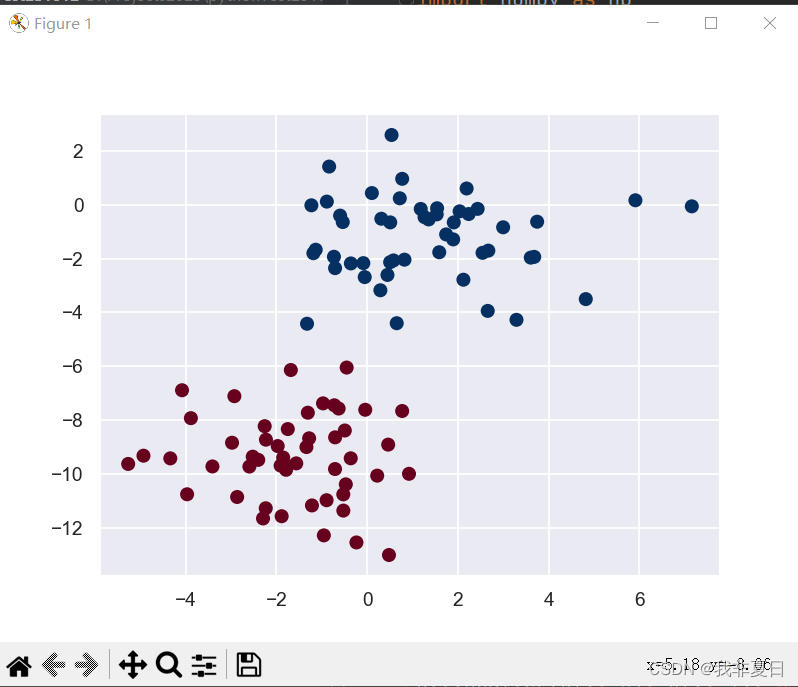
model.predict(X_test)方法对测试集进行预测,得到预测类别y_pred。- 绘制原始数据的散点图(与步骤3相同)。
- 保存当前图形的坐标轴范围(
lim = plt.axis())。- 绘制测试集数据的散点图,使用
c=y_pred设置颜色,s=20设置点的大小,alpha=0.1设置透明度。- 恢复原始图形的坐标轴范围(
plt.axis(lim)),确保新旧数据点在同一坐标系中。- 展示绘制的新图形,其中包含了原始数据和测试集的预测结果。
- 输出预测概率:
- 使用
model.predict_proba(X_test)方法获取测试集中每个样本对每个类别的预测概率。- 打印出测试集中最后8个样本的预测概率,并保留两位小数。
这段代码的目的是演示如何使用高斯朴素贝叶斯分类器对二维数据进行分类,并展示分类结果。同时,它还展示了如何使用Matplotlib绘制散点图,并通过颜色区分不同类别的数据点。
2.代码:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=100, n_features=2, centers=2, random_state=2, cluster_std=1.5)
plt.scatter(X[:,0], X[:,1], c=y, s=50, cmap='RdBu')
plt.show()
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X, y)
rng = np.random.RandomState(0)
X_test = [-6, -14] + [14, 18]*rng.rand(2000, 2)
y_pred = model.predict(X_test)
plt.scatter(X[:,0], X[:,1], c=y, s=50, cmap='RdBu')
lim=plt.axis()
plt.scatter(X_test[:,0], X_test[:,1], c=y_pred, s=20, cmap='RdBu', alpha=0.1)
plt.show()
yprob = model.predict_proba(X_test)
print(yprob[-8:].round(2))3.结果:
三、线性SVM
1.算法执行流程:
算法执行流程简述如下:
- 导入必要的库:
- 导入
numpy库用于数值计算。- 导入
matplotlib.pyplot库用于绘图。- 从
sklearn库中导入svm模块,用于支持向量机(SVM)算法。- 准备数据集:
- 使用
numpy创建一个二维数组data,表示数据集的特征。- 创建一个标签列表
label,其中前六个数据的标签为1,后六个为0。- 确定绘图范围:
- 计算数据集在每个特征维度上的最小值和最大值,并扩展一定的范围以绘制完整的分类边界。
- 使用
np.meshgrid函数生成网格点,这些点将用于评估分类器的预测结果并绘制分类边界。- 创建并训练SVM分类器:
- 实例化一个
svm.SVC对象,指定使用线性核('linear')和惩罚参数C(在这里设置为0.001)。- 使用
fit方法训练SVM分类器,传入数据集data和对应的标签label。- 预测和绘制分类边界:
- 使用
predict方法预测网格点上的分类结果,并将结果存储在Z中。- 将
Z的形状调整为与网格xx和yy相同的二维数组。- 使用
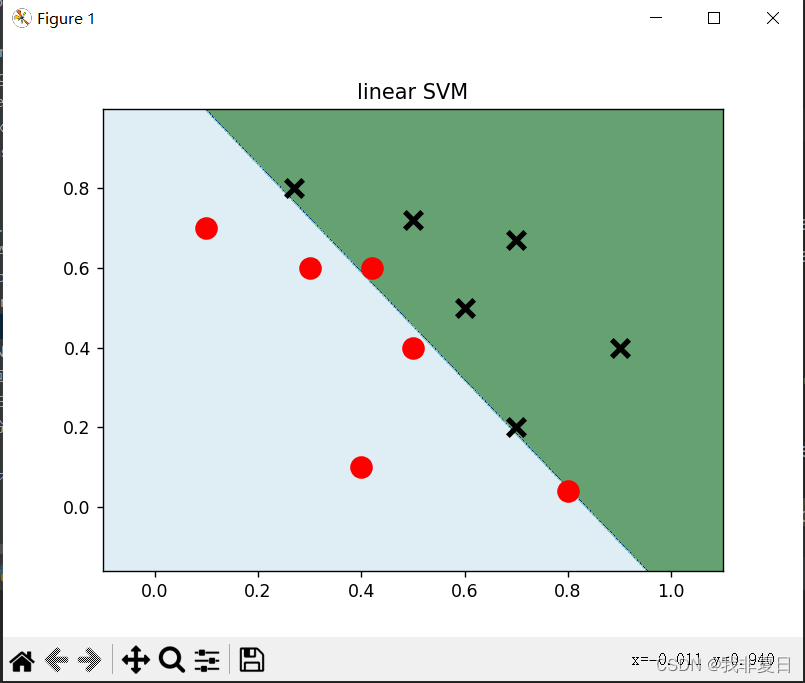
plt.contourf函数绘制分类边界,其中xx和yy定义了网格点,Z是预测的分类结果,cmap参数用于指定颜色映射。- 绘制数据点:
- 使用
plt.scatter函数绘制数据集中的点,其中前六个点(标签为1)用红色'o'表示,后六个点(标签为0)用黑色'x'表示。- 添加标题并展示图形:
- 使用
plt.title函数为图形添加标题。- 使用
plt.show函数显示绘制的图形。在这个流程中,线性SVM分类器通过训练学习一个决策边界(也称为超平面),该边界能够最好地将不同类别的数据点分开。
C参数(惩罚系数)在SVM中用于控制分类器的复杂度和对错误分类的容忍度。在训练完成后,分类器能够预测新数据点的类别,并绘制出分类边界,从而可视化分类器的决策区域。
2.代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
data = np.array([
[0.1, 0.7],
[0.3, 0.6],
[0.4, 0.1],
[0.5, 0.4],
[0.8, 0.04],
[0.42, 0.6],
[0.9, 0.4],
[0.6, 0.5],
[0.7, 0.2],
[0.7, 0.67],
[0.27, 0.8],
[0.5, 0.72]
])
label = [1]*6 + [0]*6
x_min, x_max = data[:,0].min()-0.2, data[:,0].max()+0.2
y_min, y_max = data[:,1].min()-0.2, data[:,1].max()+0.2
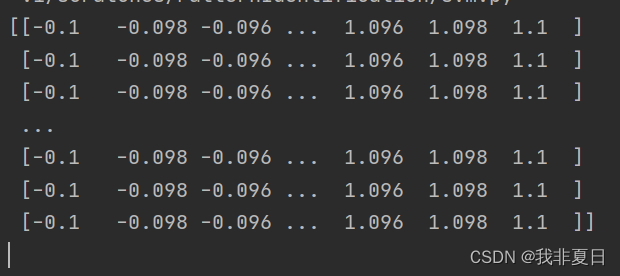
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.002), np.arange(y_min, y_max, 0.002))
print(xx)
model_linear = svm.SVC(kernel='linear', C=0.001)
model_linear.fit(data, label)
Z = model_linear.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.ocean, alpha=0.6)
plt.scatter(data[:6,0], data[:6,1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:,0], data[6:,1], marker='x', color='k', s=100, lw=3)
plt.title('linear SVM')
plt.show()
3.结果:
四、Bagging
1.算法执行流程:
算法执行流程简述如下:
- 数据加载与预处理:
- 使用
sklearn.datasets的load_wine()函数加载葡萄酒数据集。- 打印出数据集中所有特征的名字(
wine.feature_names)。- 将数据集的特征部分(
wine.data)转换为pandas的DataFrame对象X,并设置特征名字。- 将数据集的标签部分(
wine.target)转换为pandas的Series对象y。- 数据分割:
- 使用
train_test_split函数将数据集X和y分割为训练集(80%)和测试集(20%)。- 构建并训练决策树分类器:
- 初始化一个决策树分类器
base_model,设置最大深度为1,特征选择标准为基尼指数,并指定随机状态。- 使用训练集
X_train和y_train训练决策树分类器。- 使用训练好的决策树分类器对测试集
X_test进行预测,得到预测结果y_pred。- 计算并打印决策树分类器在测试集上的准确率。
- 构建并训练Bagging分类器:
- 初始化一个Bagging分类器
model,设置基本估计器为前面训练的决策树分类器base_model,最大的弱学习器个数为50,并指定随机状态。- 使用训练集
X_train和y_train训练Bagging分类器。- 使用训练好的Bagging分类器对测试集
X_test进行预测,得到预测结果y_pred。- 计算并打印Bagging分类器在测试集上的准确率。
- 测试估计器个数对Bagging分类器的影响:
- 创建一个列表
x,包含从2到102的偶数,表示要测试的估计器(即弱学习器)的个数。- 创建一个空列表
y,用于存储每个估计器个数对应的Bagging分类器在测试集上的准确率。- 遍历列表
x中的每个估计器个数:
- 初始化一个新的Bagging分类器,设置基本估计器为决策树分类器
base_model,并设置当前遍历到的估计器个数。- 使用训练集
X_train和y_train训练Bagging分类器。- 使用训练好的Bagging分类器对测试集
X_test进行预测,并计算其在测试集上的准确率。- 将该准确率添加到列表
y中。- 使用
matplotlib绘制估计器个数与Bagging分类器测试准确率的关系图,并显示。总结:这个流程首先加载并处理了葡萄酒数据集,然后训练了一个简单的决策树分类器和一个基于该决策树的Bagging分类器,并测试了不同估计器个数对Bagging分类器性能的影响。
2.代码:
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
wine = load_wine()#使用葡萄酒数据集
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1) #训练集0.8,测试集0.2
#构建并训练决策树分类器,这里特征选择标准使用基尼指数,树的最大深度为1
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini',random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)#对训练集进行预测
print(f"决策树的准确率:{accuracy_score(y_test,y_pred):.3f}")
## bagging
from sklearn.ensemble import BaggingClassifier
# 建立AdaBoost分类器,每个基本分类模型为前面训练的决策树模型,最大的弱学习器的个数为50
model = BaggingClassifier(estimator=base_model,
n_estimators=50,
random_state=1)
model.fit(X_train, y_train)# 训练
y_pred = model.predict(X_test)# 预测
print(f"BaggingClassifier的准确率:{accuracy_score(y_test,y_pred):.3f}")
# 测试估计器个数的影响
x = list(range(2, 102, 2)) # 估计器个数即n_estimators,在这里我们取[2,102]的偶数
y = []
for i in x:
model = BaggingClassifier(estimator=base_model,
n_estimators=i,
random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.style.use('ggplot')
plt.title("Effect of n_estimators", pad=20)
plt.xlabel("Number of base estimators")
plt.ylabel("Test accuracy of BaggingClassifier")
plt.plot(x, y)
plt.show()3.结果:


五、随机森林
1.算法执行流程:
算法执行流程简述如下:
- 数据加载与预处理:
- 使用
sklearn.datasets的load_wine()函数加载葡萄酒数据集。- 打印出数据集中所有特征的名字(
wine.feature_names)。- 将数据集的特征部分(
wine.data)转换为pandas的DataFrame对象X,并设置特征名字。- 将数据集的标签部分(
wine.target)转换为pandas的Series对象y。- 数据分割:
- 使用
train_test_split函数将数据集X和y分割为训练集(80%)和测试集(20%)。- 构建并训练决策树分类器:
- 初始化一个决策树分类器
base_model,设置最大深度为1,特征选择标准为基尼指数,并指定随机状态。- 使用训练集
X_train和y_train训练决策树分类器。- 注意:此处有一个小错误,你实际上是对训练集进行了预测,但通常我们会对测试集进行预测来评估模型性能。不过,你已经打印出了这个“对训练集进行预测”的准确率,尽管这不是常见的做法。
- 打印决策树分类器在测试集上的准确率(尽管基于上述代码,实际上是对训练集的预测)。
- 构建并训练随机森林分类器:
- 初始化一个随机森林分类器
model,设置弱学习器(即决策树)的个数为50,并指定随机状态。- 使用训练集
X_train和y_train训练随机森林分类器。- 使用训练好的随机森林分类器对测试集
X_test进行预测,得到预测结果y_pred。- 打印随机森林分类器在测试集上的准确率。
- 测试估计器个数对随机森林分类器的影响:
- 创建一个列表
x,包含从2到102的偶数,表示要测试的估计器(即决策树)的个数。- 创建一个空列表
y,用于存储每个估计器个数对应的随机森林分类器在测试集上的准确率。- 遍历列表
x中的每个估计器个数:
- 初始化一个新的随机森林分类器,并设置当前遍历到的估计器个数。
- 使用训练集
X_train和y_train训练随机森林分类器。- 使用训练好的随机森林分类器对测试集
X_test进行预测,并计算其在测试集上的准确率。- 将该准确率添加到列表
y中。- 使用
matplotlib绘制估计器个数与随机森林分类器测试准确率的关系图,并显示。总结:这个流程首先加载并处理了葡萄酒数据集,然后训练了一个简单的决策树分类器(尽管没有正确评估其在测试集上的性能),接着训练了一个随机森林分类器,并测试了不同估计器个数对随机森林分类器性能的影响。
2.代码:
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
wine = load_wine()
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.200, random_state=1)
base_model = DecisionTreeClassifier(max_depth=1, criterion='gini', random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"决策树的准确率:{accuracy_score(y_test, y_pred):.3f}")
#随机森林
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=50, random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"RandomForestClassifier的准确率:{accuracy_score(y_test, y_pred):3f}")
x = list(range(2, 102, 2))
y = []
for i in x:
model = RandomForestClassifier(n_estimators=i, random_state=1)
model.fit(X_train, y_train)
model_test_sc = accuracy_score(y_test, model.predict(X_test))
y.append(model_test_sc)
plt.style.use('ggplot')
plt.title('Effect of n_estimators', pad = 20)
plt.xlabel('Number of base estimators')
plt.ylabel('Test accuracy of RandomForestClassifier')
plt.plot(x, y)
plt.show()3.结果:
![]()
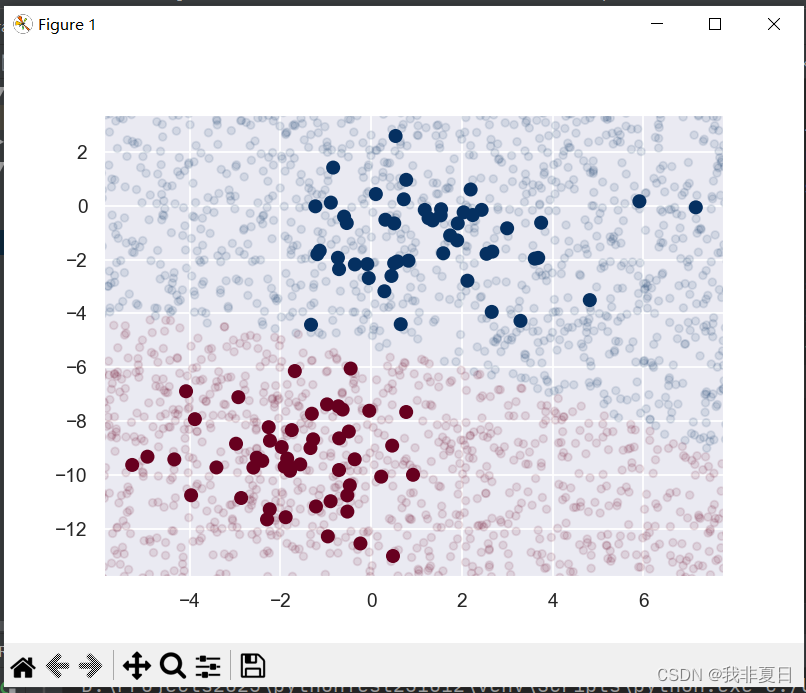
六、k_means
1.算法执行流程:
算法执行流程可以简述如下:
- 数据准备:
- 使用
numpy.random.rand(100, 2)生成一个包含100个样本点、每个样本点有两个特征的数据集X。- 使用
matplotlib.pyplot.scatter绘制这些样本点在一个二维平面上。- 初始化质心:
- 定义一个函数
InitCentroids(X, k),用于从数据集X中随机选择k个样本点作为初始质心。- 在这个例子中,虽然代码示例中包含了
InitCentroids函数的定义,但在后面的代码中并没有实际调用它,因为KMeans类内部已经实现了质心的初始化。- 执行KMeans聚类:
- 创建一个
KMeans对象,并设置n_clusters=2,意味着要将数据分为两类。- 调用
fit(X)方法对数据集X进行聚类。在fit方法内部,KMeans 算法会执行以下步骤:
- 初始化质心(如果未提供初始质心,则KMeans类内部会随机选择)。
- 执行迭代过程,直到质心不再显著变化或达到最大迭代次数:
- 将每个样本点分配给最近的质心。
- 对于每个簇,计算其所有样本点的均值,并将该均值设置为新的质心。
- 聚类完成后,
KMeans对象会存储质心的位置、每个样本点的簇标签等信息。- 绘制聚类结果:
- 使用
KMeans对象的labels_属性获取每个样本点的簇标签。- 使用
matplotlib.pyplot.scatter绘制聚类后的样本点,并使用不同的颜色表示不同的簇。- 调用
plt.show()显示图形。- 结果展示:
- 用户可以看到一个二维散点图,其中不同颜色的点表示不同的簇,每个簇的质心可以用一个特殊的标记(如“x”)表示(虽然在这个代码示例中没有明确绘制质心)。
注意:虽然代码中包含了
InitCentroids函数的定义,但在实际的KMeans聚类过程中并没有使用它,因为KMeans类内部已经实现了质心的初始化和更新过程。如果你想要自定义质心的初始化方式,可以通过设置KMeans类的init参数来实现(例如,init='k-means++'或init=InitCentroids,但后者需要稍作修改以适应KMeans类的要求)。
2.代码:
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans
x = np.random.rand(100, 2)
plt.scatter(x[:,0], x[:,1], marker='o')
def InitCentroids(x, k):
index = np.random.randint(0, len(x)-1, k)
return x[index]
kmeans = KMeans(n_clusters=2).fit(x)
label_pred = kmeans.labels_
plt.scatter(x[:,0], x[:,1], c=label_pred)
plt.show()
3.结果:
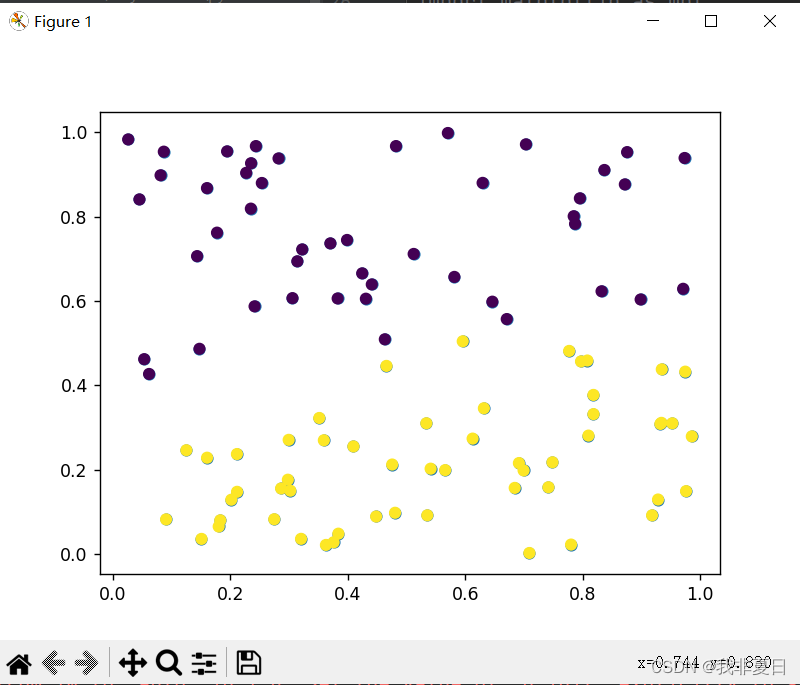
七、MLP
1.算法执行流程:
算法执行流程简述如下:
- 导入必要的库和模块:
- 导入
sklearn.neural_network中的MLPClassifier,用于构建多层感知机(MLP)分类器。- 导入
sklearn.datasets中的fetch_openml函数,用于从OpenML数据集中获取MNIST数据集。- 导入NumPy库,用于数据操作。
- 加载MNIST数据集:
- 使用
fetch_openml函数从OpenML加载MNIST数据集,指定数据集名称为'mnist_784'并设置解析器为'auto'。- 将加载的数据集分为特征(
X)和目标变量(y)。- 划分训练集和测试集:
- 将原始数据集
X和y的前60,000个样本作为训练集(X_train和y_train)。- 将剩余的样本作为测试集(
X_test和y_test)。- 将这些数据转换为NumPy数组,并指定特征数据的数据类型为浮点数(
float),目标变量的数据类型为整数(int)。- 创建MLP分类器实例:
- 使用
MLPClassifier类创建一个MLP分类器实例clf。- 设置分类器的参数,包括正则化项
alpha(防止过拟合),隐藏层的大小hidden_layer_sizes(指定了神经网络的架构),以及随机种子random_state(确保结果的可复现性)。- 训练模型:
- 调用
clf.fit方法,传入训练集的特征X_train和目标变量y_train,开始训练MLP分类器。- 在训练过程中,MLP分类器会学习如何根据输入特征(手写数字的图像)预测输出目标(数字的分类)。
- 评估模型:
- 调用
clf.score方法,传入测试集的特征X_test和目标变量y_test,对模型进行评估。score方法会返回模型在测试集上的准确率,即模型正确分类的样本比例。- 打印测试结果:
- 使用
通过这个过程,你可以了解到使用多层感知机(MLP)分类器来训练MNIST数据集的基本流程,包括数据加载、预处理、模型构建、训练和评估等步骤。
2.代码:
#使用多层感知机(MLP)分类器来训练MNIST数据集
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import fetch_openml
import numpy as np
mnist = fetch_openml('mnist_784', parser='auto')
X, y = mnist['data'], mnist['target']
X_train = np.array(X[:60000], dtype=float)
y_train = np.array(y[:60000], dtype=int)
X_test = np.array(X[60000:], dtype=float)
y_test = np.array(y[60000:], dtype=int)
clf = MLPClassifier(alpha=1e-5,
hidden_layer_sizes=(15,15), random_state=1)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print(f"Test accuracy: {score}")
3.结果:
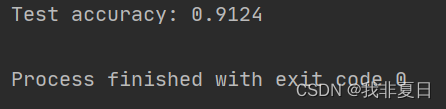
八、knn
1.算法执行流程:
算法执行流程简述如下:
- 导入必要的库和模块:
- 导入
sklearn.datasets中的load_digits函数,用于加载手写数字数据集。- 导入
sklearn.model_selection中的train_test_split函数,用于分割数据集为训练集和测试集。- 导入
sklearn.neighbors中的KNeighborsClassifier类,用于创建K近邻(KNN)分类器。- 导入
sklearn.metrics中的accuracy_score函数,用于评估模型的准确度。- 加载数据集:
- 使用
load_digits函数加载手写数字数据集。- 从加载的数据集中提取特征集(
data)和目标集(target)。- 分割数据集:
- 使用
train_test_split函数将数据集分割为训练集和测试集。- 设置测试集大小为25%,剩余75%作为训练集。
- 设置随机种子
random_state=33以确保结果的可复现性。- 创建KNN分类器:
- 实例化
KNeighborsClassifier类,创建KNN分类器对象knn。- 由于没有指定任何参数,分类器将使用默认参数(例如,
n_neighbors=5,即使用最近的5个邻居进行预测)。- 拟合模型:
- 使用
fit方法,传入训练集的特征train_x和目标train_y,让KNN分类器学习训练集中的样本特征和目标之间的映射关系。- 预测数据:
- 使用
predict方法,传入测试集的特征test_x,让KNN分类器对测试集中的样本进行预测,并返回预测的目标值predict_y。- 评估模型:
- 使用
accuracy_score函数,传入测试集的真实目标值test_y和KNN分类器的预测目标值predict_y,计算模型的准确度。- 准确度是模型正确预测样本的比例,用于评估模型的性能。
- 输出结果:
- 打印出模型的准确度
score。整个流程涵盖了从数据加载、预处理、模型构建、训练、预测到评估的完整步骤,是机器学习中的一个标准流程。
2.代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
digits = load_digits()
data = digits.data
target = digits.target
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25, random_state=33)
knn = KNeighborsClassifier()
knn.fit(train_x, train_y)
predict_y = knn.predict(test_x)
score = accuracy_score(test_y, predict_y)
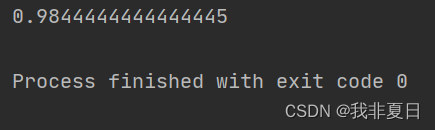
print(score)3.结果: