Hive3.1.2分区与排序(内置函数)
1、Hive分区(十分重要!!)
分区的目的:避免全表扫描,加快查询速度!
在大数据中,最常见的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天或者每小时切分成一个个小的文件,这样去操作小的文件就会容易很多了。
假如现在我们公司一天产生3亿的数据量,那么为了方便管理和查询,就做以下的事情。
1)建立分区(可按照日期,部门等等具体业务分区)
2)分门别类的管理
1.2 静态分区(SP)
静态分区(SP)static partition–partition by (字段 类型)
借助于物理的文件夹分区,实现快速检索的目的。
一般对于查询比较频繁的列设置为分区列。
分区查询的时候直接把对应分区中所有数据放到对应的文件夹中。
创建单分区表语法:
注:在将每个分区数据写入到特定文件,使用load data local加载数据将其上传到HDFS上时,会根据其分区来划分为不同的文件夹。当从hive的客户端读取其中数据时,每个分区对应的grade的值会按照HDFS文件夹上Name字段处的分区值进行填入,而不会依据写入文件时的grade的值。

CREATE TABLE IF NOT EXISTS t_student (
sno int,
sname string
) partitioned by(grade int)
row format delimited fields terminated by ',';
-- 分区的字段不要和表的字段相同。相同会报错error10035
1,xiaohu01,1
2,xiaohu02,1
3,xiaohu03,1
4,xiaohu04,1
5,xiaohu05,1
6,xiaohu06,2
7,xiaohu07,2
8,xiaohu08,2
9,xiaohu09,3
10,xiaohu10,3
11,xiaohu11,3
12,xiaohu12,3
13,xiaohu13,3
14,xiaohu14,3
15,xiaohu15,3
16,xiaohu16,4
17,xiaohu17,4
18,xiaohu18,4
19,xiaohu19,4
20,xiaohu20,4
21,xiaohu21,4
-- 载入数据
-- 将相应年级一次导入
load data local inpath '/usr/local/soft/bigdata/grade2.txt' into table t_student partition(grade=2);
-- 演示多拷贝一行上传,分区的列的值是分区的值,不是原来的值
静态多分区表语法:
CREATE TABLE IF NOT EXISTS t_teacher (
tno int,
tname string
) partitioned by(grade int,clazz int)
row format delimited fields terminated by ',';
--注意:前后两个分区的关系为父子关系,也就是grade文件夹下面有多个clazz子文件夹。
1,xiaoge01,1,1
2,xiaoge02,1,1
3,xiaoge03,1,2
4,xiaoge04,1,2
5,xiaoge05,1,3
6,xiaoge06,1,3
7,xiaoge07,2,1
8,xiaoge08,2,1
9,xiaoge09,2,2
--载入数据
load data local inpath '/usr/local/soft/bigdata19/hivedata/teacher_1.txt' into table t_teacher partition(grade=1,clazz=1);
分区表查询
select * from t_student where grade = 1;
// 全表扫描,不推荐,效率低
select count(*) from students_pt1;
// 使用where条件进行分区裁剪,避免了全表扫描,效率高
select count(*) from students_pt1 where grade = 1;
// 也可以在where条件中使用非等值判断
select count(*) from students_pt1 where grade<3 and grade>=1;
查看分区
show partitions t_teacher;
添加分区
alter table t_student add partition (grade=6);
alter table t_teacher add partition (grade=3,clazz=1) location '/user/hive/warehouse/bigdata29.db/t_teacher/grade=3/clazz=1';
删除分区
alter table t_student drop partition (grade=5);
1.3 动态分区(DP)
- 动态分区(DP)dynamic partition
- 静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。
- 详细来说,静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
开启动态分区首先要在hive会话中设置如下的参数
# 表示开启动态分区
hive> set hive.exec.dynamic.partition=true;
# 表示动态分区模式:strict(需要配合静态分区一起使用)、nostrict
# strict: insert into table students_pt partition(dt='anhui',pt) select ......,pt from students;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
===================以下是可选参数======================
# 表示支持的最大的分区数量为1000,可以根据业务自己调整
hive> set hive.exec.max.dynamic.partitions.pernode=1000;
其余的参数详细配置如下
设置为true表示开启动态分区的功能(默认为false)
--hive.exec.dynamic.partition=true;
设置为nonstrict,表示允许所有分区都是动态的(默认为strict)
-- hive.exec.dynamic.partition.mode=nonstrict;
-- hive.exec.dynamic.partition.mode=strict;
每个mapper或reducer可以创建的最大动态分区个数(默认为100)
比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错
--hive.exec.max.dynamic.partition.pernode=100;
一个动态分区创建可以创建的最大动态分区个数(默认值1000)
--hive.exec.max.dynamic.partitions=1000;
全局可以创建的最大文件个数(默认值100000)
--hive.exec.max.created.files=100000;
当有空分区产生时,是否抛出异常(默认false)
-- hive.error.on.empty.partition=false;
- 案例1: 动态插入学生年级班级信息
--创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS t_student_e (
sno int,
sname string,
grade int,
clazz int
)
row format delimited fields terminated by ','
location "/bigdata30/teachers";
--创建分区表
CREATE TABLE IF NOT EXISTS t_student_d (
sno int,
sname string
) partitioned by (grade int,clazz int)
row format delimited fields terminated by ',';
数据:
1,xiaohu01,1,1
2,xiaohu02,1,1
3,xiaohu03,1,1
4,xiaohu04,1,2
5,xiaohu05,1,2
6,xiaohu06,2,3
7,xiaohu07,2,3
8,xiaohu08,2,3
9,xiaohu09,3,3
10,xiaohu10,3,3
11,xiaohu11,3,3
12,xiaohu12,3,4
13,xiaohu13,3,4
14,xiaohu14,3,4
15,xiaohu15,3,4
16,xiaohu16,4,4
17,xiaohu17,4,4
18,xiaohu18,4,5
19,xiaohu19,4,5
20,xiaohu20,4,5
21,xiaohu21,4,5
如果静态分区的话,我们插入数据必须指定分区的值。
如果想要插入多个班级的数据,我要写很多SQL并且执行24次很麻烦。
而且静态分区有可能会产生数据错误问题
-- 会报错
insert overwrite table t_student_d partition (grade=1,clazz=1) select * from t_student_e where grade=1;
如果使用动态分区,动态分区会根据select的结果自动判断数据应该load到哪儿分区去。
insert overwrite table t_student_d partition (grade,clazz) select * from t_student_e;
优点:不用手动指定了,自动会对数据进行分区
缺点:可能会出现数据倾斜
2、Hive分桶
2.1 业务场景
数据分桶的适用场景:
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式
不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况
分桶是将数据集分解为更容易管理的若干部分的另一种技术。
分桶就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。(都各不相同)
2.2 数据分桶原理
- Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
- bucket num = hash_function(bucketing_column) mod num_buckets ( hash(name)%n == x )
- 列的值做哈希取余 决定数据应该存储到哪个桶
2.3 数据分桶优势
方便抽样
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便
提高join查询效率
获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
2.4 分桶实战
首先,分区和分桶是两个不同的概念,很多资料上说需要先分区在分桶,其实不然,分区是对数据进行划分,而分桶是对文件进行划分。
当我们的分区之后,最后的文件还是很大怎么办,就引入了分桶的概念。
将这个比较大的文件再分成若干个小文件进行存储,我们再去查询的时候,在这个小范围的文件中查询就会快很多。
对于hive中的每一张表、分区都可以进一步的进行分桶。
当然,分桶不是说将文件随机进行切分存储,而是有规律的进行存储。在看完下面的例子后进行解释,现在干巴巴的解释也不太好理解。它是由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
创建顺序和分区一样,创建的方式不一样。
# 分区和分桶的区别
1、在HDFS上的效果区别,分区产生的是一个一个子文件夹,分桶产生的是一个一个文件
2、无论是分区还是分桶,在建表的时候都要指定字段,分区使用partitioned by指定分区字段,分桶使用clustered by指定分桶字段
3、partitioned by指定分区字段的时候,字段后面需要加上类型,而且不能在建表小括号中出现。clustered by指定分桶字段的时候,字段已经出现定义过了,只需要指定字段的名字即可
4、分区字段最好选择固定类别的,分桶字段最好选择值各不相同的。
5、分桶不是必须要建立在分区之上,可以不进行分区直接分桶
首先我们需要开启分桶的支持
(依然十分重要,不然无法进行分桶操作!!!!)
set hive.enforce.bucketing=true;
数据准备(id,name,age)
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
创建一个普通的表
create table person
(
id int,
name string,
age int
)
row format delimited
fields terminated by ',';
将数据load到这张表中
load data local inpath '/usr/local/soft/bigdata30/person.txt' into table person;
创建分桶表
create table psn_bucket
(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited fields terminated by ',';
将数据insert到表psn_bucket中
(注意:这里和分区表插入数据有所区别,分区表需要select 和指定分区,而分桶则不需要)
insert into psn_bucket select * from person;
在HDFS上查看数据
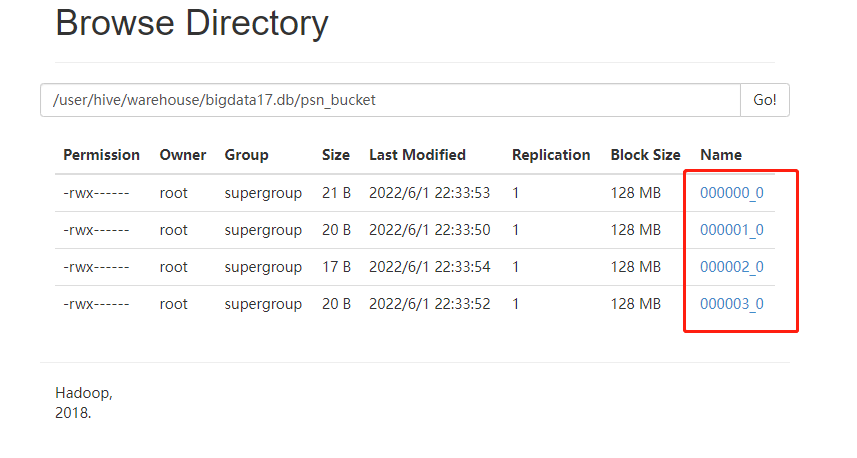
查询数据
我们在linux中使用Hadoop的命令查看一下(与我们猜想的顺序一致)
hadoop fs -cat /user/hive/warehouse/bigdata30_test.db/psn_bucket/*
这里设置的桶的个数是4 数据按照 年龄%4 进行放桶(文件)
11%4 == 3 -----> 000003_0
22%4 == 2 -----> 000002_0
33%4 == 1 -----> 000001_0
44%4 == 0 -----> 000000_0
…以此类推

面试题:分桶和分区的区别?
3、Hive JDBC
启动hiveserver2
nohup hiveserver2 &
或者
hiveserver2 &
新建maven项目并添加两个依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
编写JDBC代码
import java.sql.*;
public class HiveJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://master:10000/bigdata29");
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery("select * from students limit 10");
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
int age = rs.getInt(3);
String gender = rs.getString(4);
String clazz = rs.getString(5);
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}
rs.close();
stat.close();
conn.close();
}
}
4、Hive查询语法(DQL)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
4.1 全局排序
- order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间
- 使用 order by子句排序 :ASC(ascend)升序(默认)| DESC(descend)降序
- order by放在select语句的结尾
select * from 表名 order by 字段名1[,别名2...];
4.2 局部排序(对reduce内部做排序)
- sort by 不是全局排序,其在数据进入reducer前完成排序。
- 如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by 只保证每个reducer的输出有序,不保证全局有序。asc,desc
- 设置reduce个数
set mapreduce.job.reduces=3;
- 查看reduce个数
set mapreduce.job.reduces;
- 排序
select * from 表名 sort by 字段名[,字段名...];
4.3 分区排序(本身没有排序)
distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
类似MR中partition,进行分区,结合sort by使用。(注意:distribute by 要在sort by之前)
对于distrbute by 进行测试,一定要多分配reduce进行处理,否则无法看到distribute by的效果。
设置reduce个数
set mapreduce.job.reduce=7;
- 排序
select * from 表名 distribute by 字段名[,字段名...] sort by 字段;
4.3 分区并排序
- cluster by(字段)除了具有Distribute by的功能外,还会对该字段进行排序 asc desc
- cluster by = distribute by + sort by 只能默认升序,不能使用倒序
select * from 表名 cluster by 字段名[,字段名...];
select * from 表名 distribute by 字段名[,字段名...] sort by 字段名[,字段名...];
5、Hive内置函数
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
-- 1.查看系统自带函数
show functions;
-- 2.显示自带的函数的用法
desc function xxxx;
-- 3.详细显示自带的函数的用法
desc function extended upper;
5.1 内置函数分类
关系操作符:包括 = 、 <> 、 <= 、>=等
算数操作符:包括 + 、 - 、 *、/等
逻辑操作符:包括AND 、 && 、 OR 、 || 等
复杂类型构造函数:包括map、struct、create_union等
复杂类型操作符:包括A[n]、Map[key]、S.x
数学操作符:包括ln(double a)、sqrt(double a)等
集合操作符:包括size(Array)、sort_array(Array)等
类型转换函数: binary(string|binary)、cast(expr as )
日期函数:包括from_unixtime(bigint unixtime[, string format])、unix_timestamp()等
条件函数:包括if(boolean testCondition, T valueTrue, T valueFalseOrNull)等
字符串函数:包括acat(string|binary A, string|binary B…)等
其他:xpath、get_json_objectscii(string str)、con
5.2 UDTF hive中特殊的一个功能(进一出多)
-- UDF 进一出一
-- UDAF 进多出一
-- collect_set()和collect_list()都是对多列转成一行,区别就是list里面可重复而set里面是去重的
-- concat_ws(':',collect_set(type)) ':' 表示你合并后用什么分隔,collect_set(stage)表示要合并表中的那一列数据
select 字段名,concat_ws(':',collect_set(列名)) as 别名 from 表名 group by id;
-- UDTF 进一出多
-- explode 可以将一组数组的数据变成一列表
select explode(split(列名,"数据的分隔符")) from 表名;
-- lateral view 表生成函数,可以将explode的数据生成一个列表
select id,name,列名 from 表1,lateral view explode(split(表1.列名,"数据的分隔符"))新列名 as 别列名;
-- 创建数据库表
create table t_movie1(
id int,
name string,
types string
)
row format delimited fields terminated by ','
lines terminated by '\n';
-- 电影数据 movie1.txt
-- 加载数据到数据库 load data inpath '/shujia/movie1.txt' into table t_movie1;
1,这个杀手不太冷,剧情-动作-犯罪
2,七武士,动作-冒险-剧情
3,勇敢的心,动作-传记-剧情-历史-战争
4,东邪西毒,剧情-动作-爱情-武侠-古装
5,霍比特人,动作-奇幻-冒险
-- explode 可以将一组数组的数据变成一列表
select explode(split(types,"-")) from t_movie1;
-- lateral view 表生成函数,可以将explode的数据生成一个列表
select id,name,type from t_movie1 lateral view explode(split(types,"-")) typetable as type;
-- 创建数据库表
create table t_movie2(
id int,
name string,
type string
)
row format delimited fields terminated by ','
lines terminated by '\n';
-- 电影数据 movie2.txt
-- 加载数据到数据库 load data inpath '/shujia/movie2.txt' into table t_movie2;
1,这个杀手不太冷,剧情
1,这个杀手不太冷,动作
1,这个杀手不太冷,犯罪
2,七武士,动作
2,七武士,冒险
2,七武士,剧情
3,勇敢的心,动作
3,勇敢的心,传记
3,勇敢的心,剧情
3,勇敢的心,历史
3,勇敢的心,战争
4,东邪西毒,剧情
4,东邪西毒,动作
4,东邪西毒,爱情
4,东邪西毒,武侠
4,东邪西毒,古装
5,霍比特人,动作
5,霍比特人,奇幻
5,霍比特人,冒险
-- collect_set()和collect_list()都是对列转成行,区别就是list里面可重复而set里面是去重的
-- concat_ws(':',collect_set(type)) ':' 表示你合并后用什么分隔,collect_set(stage)表示要合并表中的那一列数据
select id,concat_ws(':',collect_set(type)) as types from t_movie2 group by id;
5.3 WordCount案例
数据准备
hello,world
hello,bigdata
like,life
bigdata,good
建表
create table wc2
(
line string
)
row format delimited fields terminated by '\n'
导入数据
load data local inpath '/usr/local/soft/data/wc1.txt' into table wc;
步骤1:先对一行数据进行切分
select split(line,',') from wc;
步骤2:将行转列
select explode(split(line,',')) from wc;
步骤3:将相同的进行分组统计
select w.word,count(*) from (select explode(split(line,',')) as word from wc) w group by w.word;