1、XPath介绍
XPath 是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。
2、安装lxml
lxml是Python的第三方解析库,支持HTML和XML解析,而且效率极高,弥补了Python自带的xml标准库在XML解析方面的不足。
第三方库的安装方式:
pip install lxml
3、XPath解析原理
- 实例化一个etree对象,且需要将被解析的页面源码数据加载到该对象中。
- 调用etree对象中的xpath方法结合着xpath的表达式实现标签的定位与内容的捕获。
4、实例化etree对象
- 将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath) - 将互联网上获取的源码数据加载到对象中:
etree.HTML(response.text) - xpath(‘xpath表达式’)
5、XPath路径表达式
| 表达式 | 说明 |
|---|---|
| / | 从根节点选取 |
| // | 表示是多个层级,从任意位置开始定位 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| //div[@class=‘title’] tag[@attrName=“attrValue”] | 属性定位 |
| //div[@class=“zhang”]/p[3] | 索引定位,索引是从1开始 |
| /text() | 获取的是标签中直系的文本内容 |
| //text() | 标签中非直系的文本内容(所有的文本内容) |
| /@attrName ==>img/src | 取属性 |
6、结合实战讲解
在此以CSDN网站为例进行讲解
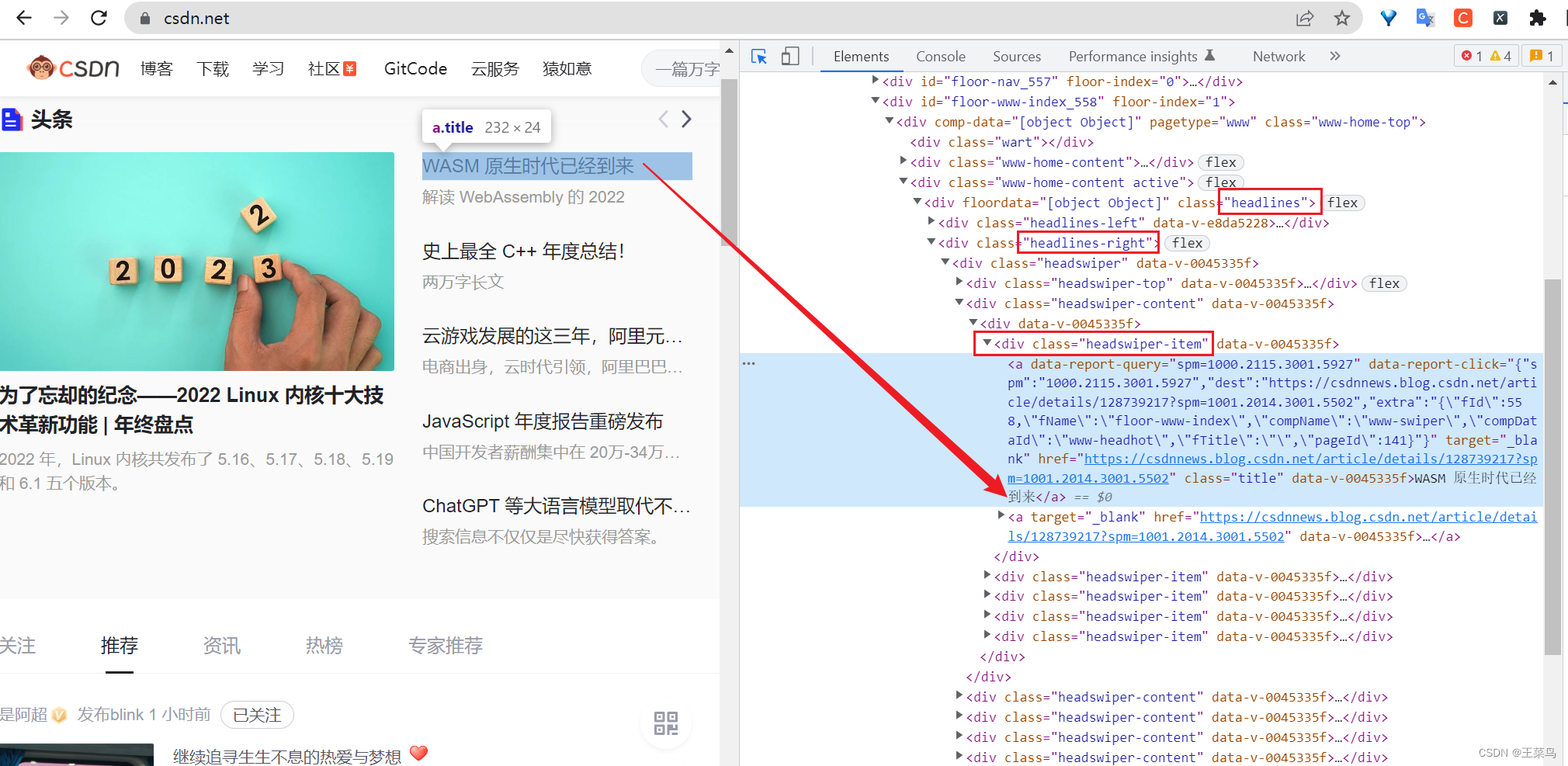
例:在这里我要获取官网首页的头条博客的标题,打开控制台(点击控制台的小箭头或者同时按住Ctrl+Shift+C),指向该标题,根据div标签的class值进行定位(这是我们平时使用xpath语法比较多的地方。
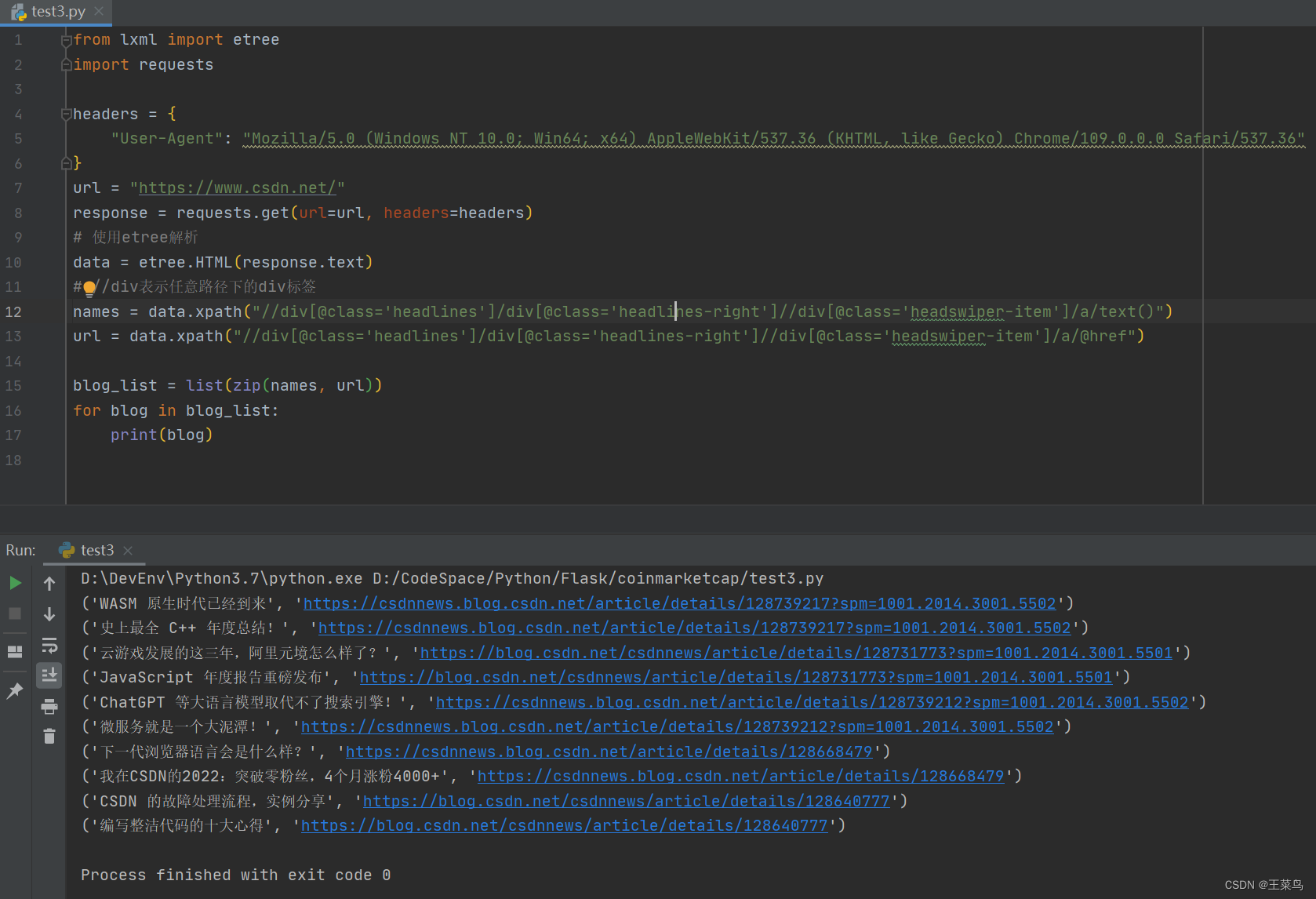
from lxml import etree
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
url = "https://www.csdn.net/"
response = requests.get(url=url, headers=headers)
# 使用etree解析
data = etree.HTML(response.text)
# //div表示任意路径下的div标签
names = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/text()")
url = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/@href")
blog_list = list(zip(names, url))
for blog in blog_list:
print(blog)
实现效果: