本文主要对数据建模与分析中常使用到的pandas内置函数进行总结分析,以此来熟悉数据建模与分析的流程。
文章目录
- 一、Pandas数据结构
- 1.1 数据结构—Series
- 1.1.1 Series的创建方式
- 1.1.2 使用索引和获取数据
- 1.2 数据结构—DataFrame
- 1.2.1 DataFrame的创建方式
- 1.2.2 使用列索引或访问属性获取数据
- 1.2.3 增加列
- 1.2.4 删除列
- 1.2.5 读入txt或者csv文件的操作
- 二、groupby函数
- 2.1 基本格式
- 2.2 groupby的返回形式和正确使用方法
- 2.2.1 单类分组举例
- 2.2.2 多类分组举例
- 三、Pandas读取文件操作
- 3.1 使用read_csv()进行文件读取
- 3.2 pandas读取xlsx、xls文件
- 3.3 pandas读取txt文件
- 四、数据合并concat
- 五、数据连接merge
- 六、apply函数
- 七、pandas.cut()函数
- 八、pandas.get_dummies()函数
一、Pandas数据结构
Pandas有两个最主要也是最重要的数据结构Series 和DataFrame
| 类型 | 描述 |
|---|---|
| Series | 一维的数据结构 |
| DataFrame | 二维的表格型的数据结构 |
提示:以下是本篇文章正文内容,下面案例可供参考
1.1 数据结构—Series
Series是一个类似一维数组的对象,它能够保存任何类型的数据,主要由一组数据和与之相关的索引两部分构成,函数如下:
pandas.Series(data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)index:数据索引标签,如果不指定,默认从 0 开始dtype:数据类型,默认会自己判断name:设置名称 copy:拷贝数据,默认为 False
注意:
Series的索引位于左边,数据位于右边
| index | element |
|---|---|
| 0 | a |
| 1 | b |
| 2 | c |
| 3 | d |
1.1.1 Series的创建方式
Pandas的Series类对象的原型如下(仅作了解):
class pandas.Series(data = None,index = None,dtype = None,
name = None,copy = False,fastpath = False)
data:表示传入的数据。index:表示索引,唯一且与数据长度相等,默认会自动创建一个从0~N的整数索引。
创建series对象举例:
1、通过传入一个列表来创建一个Series类对象:
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
print(ser_obj)
# 输出结果如下:
0 1
1 2
2 3
3 4
4 5
dtype: int64
创建Series类对象,并指定索引
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
ser_obj.index = ['a', 'b', 'c', 'd', 'e']
print(ser_obj)
# 输出结果如下:
a 1
b 2
c 3
d 4
e 5
dtype: int64
2、通过传入一个字典创建一个Series类对象,其中字典的key就是Series的index,例如:
import pandas as pd
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj2 = pd.Series(year_data)
print(ser_obj2)
# 输出结果如下:
2001 17.8
2002 20.1
2003 16.5
dtype: float64
1.1.2 使用索引和获取数据
为了能方便地操作Series对象中的索引和数据,所以该对象提供了两个属性index和values分别进行获取。
# 获取ser_obj的索引
ser_obj.index
# 获取ser_obj的数据
ser_obj.values
举例:
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
ser_obj.index = ['a', 'b', 'c', 'd', 'e']
print(ser_obj.index)
print('-'*50)
print(ser_obj.values)
# 输出结果如下:
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
--------------------------------------------------
[1 2 3 4 5]
当然,我们也可以直接使用索引来获取数据
# 获取位置索引'c'对应的数据
print(ser_obj['c'])
# 输出结果如下:
3
当某个索引对应的数据进行运算以后,其运算的结果会替换原数据,仍然与这个索引保持着对应的关系。
例如:
# 给pandas起个别名pd
import pandas as pd
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
ser_obj.index = ['a', 'b', 'c', 'd', 'e']
ser_obj2 = ser_obj * 2
print(ser_obj)
print('-' * 50)
print(ser_obj)
print(ser_obj2)
结果如下:
a 1
b 2
c 3
d 4
e 5
dtype: int64
--------------------------------------------------
a 1
b 2
c 3
d 4
e 5
dtype: int64
--------------------------------------------------
a 2
b 4
c 6
d 8
e 10
dtype: int64
1.2 数据结构—DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,它每列的数据都可以是不同的数据类型。
注意:
DataFrame的索引不仅有行索引,还有列索引,数据可以有多列

1.2.1 DataFrame的创建方式
Pandas的DataFrame类对象的原型如下(仅作了解):
pandas.DataFrame(data = None,index = None,columns = None,dtype = None,copy = False )
index:表示行标签。若不设置该参数,则默认会自动创建一个从0~N的整数索引。columns:列标签
1、通过传入数组来创建DataFrame类对象:
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象
df_obj = pd.DataFrame(demo_arr)
print(df_obj)
# 输出结果如下:
0 1 2
0 a b c
1 d e f
在创建DataFrame类对象时,如果为其指定了列索引,则DataFrame的列会按照指定索引的顺序进行排列,比如指定列索引No1,No2, No3的顺序:
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
| index | No1 | No2 | No3 |
|---|---|---|---|
| 0 | a | b | c |
| 1 | d | e | f |
1.2.2 使用列索引或访问属性获取数据
我们可以使用dataframe的列索引的方式来获取一列数据,返回的结果是一个Series对象。
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象,并指定列索引
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print(df_obj)
# 通过列索引的方式获取一列数据
element = df_obj['No2']
# 查看一列数据
print('查看一列数据:\n', element)
# 查看返回结果的类型
print(type(element)) # pandas.core.series.Series
输出结果如下:
No1 No2 No3
0 a b c
1 d e f
查看一列数据:
0 b
1 e
Name: No2, dtype: object
<class 'pandas.core.series.Series'>
我们还可以使用访问属性的方式来获取一列数据,返回的结果是一个Series对象。
# 通过属性获取列数据
element = df_obj.No2
# 查看返回结果的类型
print(type(element))
# 输出类型如下:
<class 'pandas.core.series.Series'>
注意:
在获取DataFrame的一列数据时,推荐使用列索引的方式完成,主要是因为在实际使用中,列索引的名称中很有可能带有一些特殊字符(如空格),这时使用“点字符”进行访问就显得不太合适了。
1.2.3 增加列
要想为DataFrame增加一列数据,则可以通过给列索引或者列名称赋值的方式实现。
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象,并指定列索引
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print('原始数据:\n', df_obj)
# 增加No4一列数据
df_obj['No4'] = ['g', 'h']
print('增加一列之后的数据:\n', df_obj)
输出结果如下:
原始数据:
No1 No2 No3
0 a b c
1 d e f
增加一列之后的数据:
No1 No2 No3 No4
0 a b c g
1 d e f h
1.2.4 删除列
要想删除某一列数据,则可以使用del语句实现。
import numpy as np
import pandas as pd
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象,并指定列索引
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
print('原始数据:\n', df_obj)
# 删除No3一列数据
del df_obj['No3']
print('删除一列之后的数据:\n', df_obj)
输出结果如下所示:
原始数据:
No1 No2 No3
0 a b c
1 d e f
删除一列之后的数据:
No1 No2
0 a b
1 d e
1.2.5 读入txt或者csv文件的操作
前面我们提到了DataFrame是一个类似于二维数组或表格(如excel)的对象,既然如此,那么我们便是能够对excel对象类似于csv、xlsx和txt等文件进行如DataFrame一样的操作。
这里展示一下读取txt文件后的输出结果(部分),详细的在下面我们会讲
import pandas as pd
data1 = pd.read_csv('E:\python机器学习数据建模与分析\数据\ReportCard1.txt', sep='\t')
data2 = pd.read_csv('E:\python机器学习数据建模与分析\数据\ReportCard2.txt', sep='\t')
# 将两个数据文件按照学号合并为一个数据文件
lastdata = pd.merge(data1, data2, on='xh', how='inner')
print(lastdata)
输出结果如下所示:
xh sex poli chi math fore phy che geo his
0 92103 2.0 NaN NaN NaN 66.0 98.0 79.0 89.0 81.0
1 92239 2.0 40.0 63.0 44.0 21.0 54.0 26.0 26.0 55.0
2 92142 2.0 NaN 70.0 59.0 22.0 68.0 26.0 26.0 63.0
3 92223 1.0 56.0 91.0 65.5 68.0 77.0 39.0 54.5 63.0
4 92144 1.0 59.0 79.0 34.0 34.0 57.0 37.0 37.0 76.0
5 92217 2.0 60.0 82.5 76.5 35.0 81.0 60.0 70.5 74.0
通过输出结果我们可以看出,输出的格式和DataFrame的是一模一样。
二、groupby函数
对数据集进行分组,并对各组应用一个聚合函数或转换函数,通常是数据分析的重要组成部分。在数据载入、合并,完成数据准备之后,通常需要计算分组统计或生成数据透视表。pandas提供了灵活高效的groupby()方法,方便用户对数据集进行切片、切块和摘要等操作。
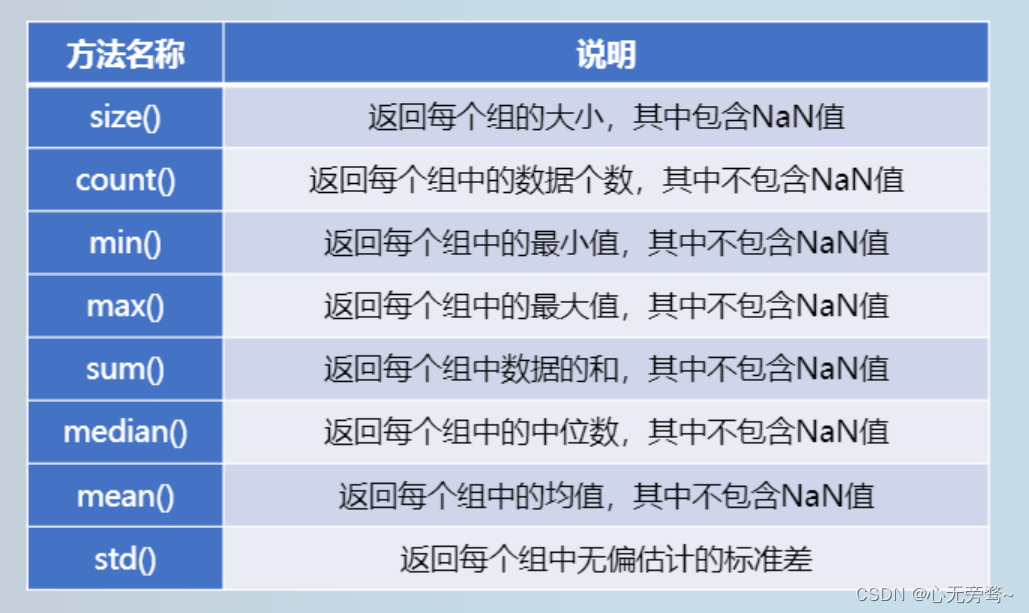
2.1 基本格式
pandas对象支持的groupby()方法语法格式如下:
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
参数by用于指定分组依据,可以是函数、字典、Series对象、DataFrame对象的列名等;参数axis表示分组轴的方向,可以是0或’index’,1或’columns’,默认值为0;参数level表示如果某个轴是一个MultiIndex对象(层级索引),则按照特定级别或多个级别分组;参数as_index=False表示用来分组的列中的数据不作为结果DataFrame对象的index;参数sort指定是否对分组标签进行排序,默认值为True。
使用groupby()方法可以实现两种分组方式,返回的对象结果不同。如果仅对DataFrame对象中的数据进行分组,将返回一个DataFrameGroupBy对象;如果是对DataFrame对象中某一列数据进行分组,将返回一个SeriesGroupBy对象。
举例:
1、按列名对列分组
# 按列名对列分组
obj1 =data['Country'].groupby(data['Region'])
print(type(obj1))
# 输出结果如下:
<class'pandas.core.groupby.generic.SeriesGroupBy’>
2、按列名对数据分组
obj2 = data.groupby(data['Region'])
print(type(obj2))
# 输出结果如下:
<class'pandas.core.groupby.generic.DataFrameGroupBy'>
2.2 groupby的返回形式和正确使用方法
可以使用groupby('label')方法按照单列分组,也可以使用groupby('label1','label2')方法按照多列分组,返回一个GroupBy对象。
举例:
data.groupby('Region')# 按单列分组
# 输出结果如下:
<pandas.core.groupby.generic.DataFrameGroupByobject at 0x7f0aee73e850>
data.groupby(['Region', 'Country'])# 按多列分组
# 输出结果如下:
<pandas.core.groupby.generic.DataFrameGroupByobject at 0x7f0aedeb99d0>
通过以上输出结果我们可以看出,使用数据分组的groupby()方法返回一个GroupBy对象,此时并未真正进行计算,只是保存了数据分组的中间结果。
下面我们就举个例子来简单介绍下如何使用groupby输出自己想要的结果。
原数据data:
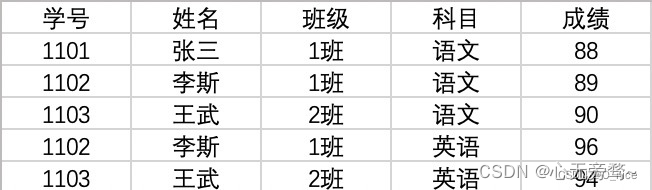
2.2.1 单类分组举例
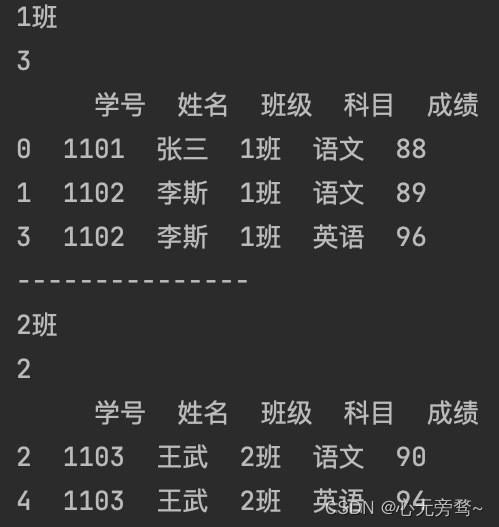
根据“班级”进行分组:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级']):
num_g = group['班级'].count() # 获取组内记录数目
print(name) # name为班级名称
print(num_g)
print(group) # group为每个分组中的记录情况
print('---------------')
“班级”分组结果:
2.2.2 多类分组举例
根据“班级”和“科目”分组:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级','科目']):
num_g = group['学号'].count() # 获取组内记录数目
print(name) # name为班级名称
print(num_g)
print(group) # group为每个分组中的记录情况
print('---------------')
“班级”和“科目”分组结果:

三、Pandas读取文件操作
3.1 使用read_csv()进行文件读取
import pandas as pd
data=pd.read_csv('path',sep=',',header=0,names=["第一列","第二列","第三列"],encoding='utf-8')
-
path:要读取的文件的绝对路径 -
sep:指定列和列的间隔符,默认sep=‘,’若sep=‘’\t",即列与列之间用制表符\t分割,相当于tab——四个空格
-
header:列名行,默认为0 -
names:列名命名或重命名 -
encoding:指定用于unicode文本编码格式
注意:read_csv()函数不仅可以读取csv类型的文件,还可以读取txt类型的文本文件。
3.2 pandas读取xlsx、xls文件
import pandas as pd
data=pd.read_excel('path',sheetname='sheet1',header=0,names=['第一列','第二列','第三列'])
-
path:要读取的文件的绝对路径 -
sheetname:指定读取excel中的哪一个工作表,默认sheetname=0,即默认读取excel中的第一个工作表
若sheetname = ‘sheet1’,即读取excel中的sheet1工作表; -
header:用作列名的行号,默认为header=0若header=None,则表明数据中没有列名行若header=0,则表明第一行为列名 -
names:列名命名或重命名
3.3 pandas读取txt文件
read_csv 也可以读取txt文件,读取txt文件的方法同上,也可以用read_table读取txt文件
import pandas as pd
data = pd.read_table('path', sep = '\t', header = None, names = ['第一列','第二列','第三列'])
四、数据合并concat
扩展库pandas支持使用concat()函数按照指定的轴方向对多个pandas对象进行数据合并,常用于多个DataFrame对象的数据合并。语法格式及常用参数如下:
pd.concat((objs, axis=0, join='outer', join_axes=None, keys=None, levels=None, names=None, ignore_index=False, verify_integrity=False, copy=True)
参数objs表示需要连接的多个pandas对象,可以是Series对象,DataFrame或Panel对象构成的列表或字典;参数axis指定需要连接的轴向,默认axis=0表示按行进行纵向合并和扩展,axis=1表示按列进行横向合并和扩展。参数join指定连接方式,默认值为outer,表示按照外连接(并集)方式合并数据;如果join=‘inner’,表示按照内连接(交集)方式合并数据。
举例:
创建DataFrame数据框:
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'C': ['A8', 'A9', 'A10', 'A11'],
'D': ['B8', 'B9', 'B10', 'B11'],
'E': ['C8', 'C9', 'C10', 'C11'],
'F': ['D8', 'D9', 'D10', 'D11']},
index=[0, 1, 2, 3])
输出一下看看:

使用concat()函数进行数据合并,参数axis默认值为0,表示按行进行纵向合并和扩展。
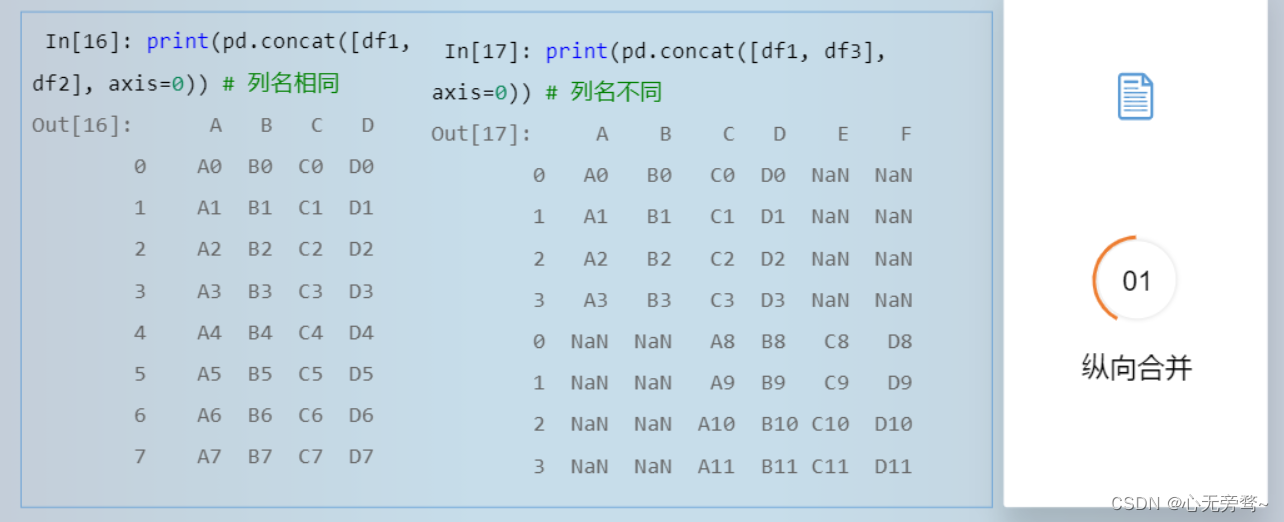
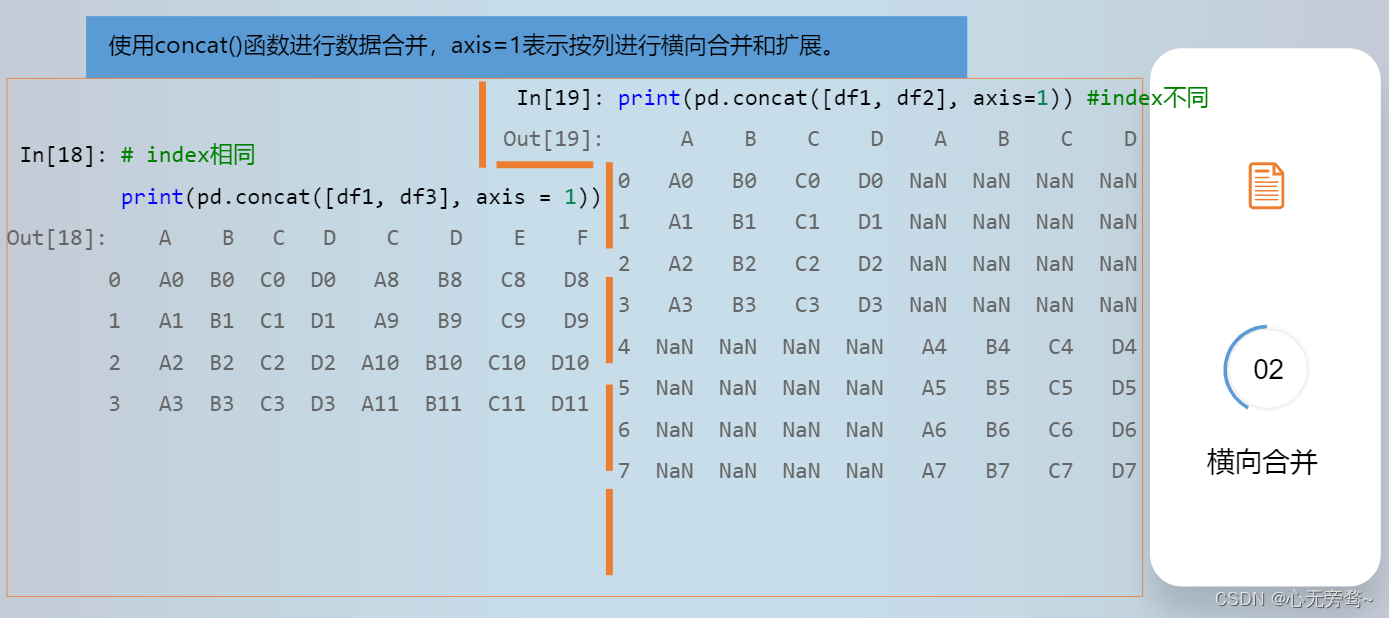
五、数据连接merge
扩展库pandas提供了一个与数据表连接操作类似的merge()函数。DataFrame对象的merge()函数可以根据单个或多个键将不同DataFrame对象的行连接起来,语法格式如下:
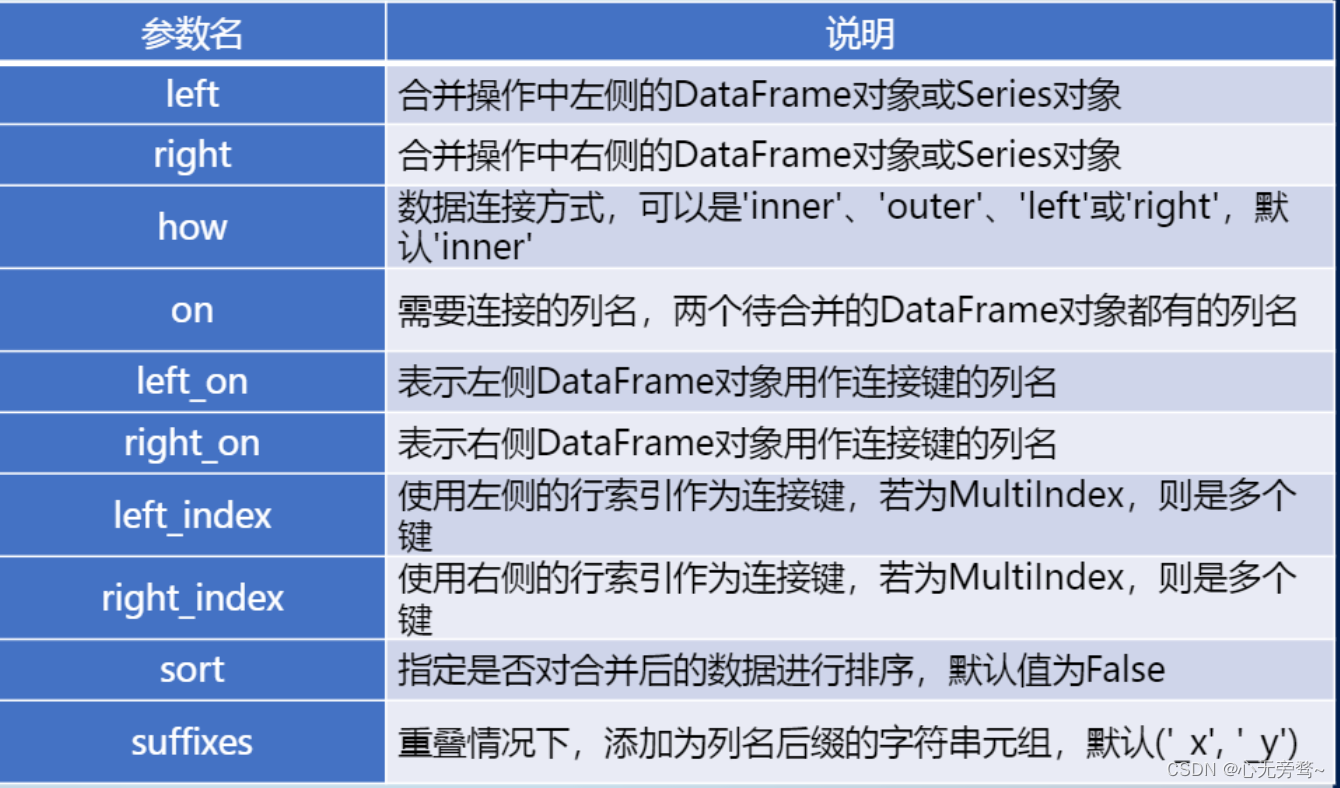
pd. merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'))
merge()函数的主要参数说明如下图所示。
举例:
创建dataframe:
staff_df= pd.DataFrame([{'姓名': '张三', '部门': '研发部'},
{'姓名': '李四', '部门': '财务部'},
{'姓名': '赵六', '部门': '市场部'}])
student_df= pd.DataFrame([{'姓名': '张三', '专业': '计算机'},
{'姓名': '李四', '专业': '会计'},
{'姓名': '王五', '专业': '市场营销'}])
print(staff_df)
print('--------------------')
print(student_df)
# 输出结果如下所示:
姓名 部门
0 张三 研发部
1 李四 财务部
2 赵六 市场部
---------------------
姓名 专业
0 张三 计算机
1 李四 会计
2 王五 市场营销
扩展库pandas中的merge()函数根据共同列或者索引对行进行连接,实现的是数据库的连接操作,包括外连接、内连接、左连接和右连接等。
1、外连接
# 外连接, 或者staff_df.merge(student_df, how='outer', on='姓名’)
print(pd.merge(staff_df, student_df, how='outer', on='姓名'))
输出结果如下:
姓名 部门 专业
0 张三 研发部 计算机
1 李四 财务部 会计
2 赵六 市场部 NaN
3 王五 NaN 市场营销
2、内连接
# 内连接, 或者staff_df.merge(student_df, how='inner', on='姓名’)
print(pd.merge(staff_df, student_df, how='inner', on='姓名'))
输出结果如下:
姓名 部门 专业
0 张三 研发部 计算机
1 李四 财务部 会计
3、左连接
# 左连接,或者staff_df.merge(student_df, how='left', on='姓名’)
print(pd.merge(staff_df, student_df, how='left', on='姓名'))
输出结果如下:
姓名 部门 专业
0 张三 研发部 计算机
1 李四 财务部 会计
2 赵六 市场部 NaN
4、右连接
# 右连接,或者staff_df.merge(student_df, how='right', on='姓名’)
print(pd.merge(staff_df, student_df, how='right', on='姓名'))
输出结果如下:
姓名 部门 专业
0 张三 研发部 计算机
1 李四 财务部 会计
2 王五 NaN 市场营销
5、添加新的列
# 添加新的数据列
staff_df['地址'] = ['天津', '北京', '上海']
student_df['地址'] = ['天津', '上海', '广州']
print(staff_df)
输出结果如下:
姓名 部门 地址
0 张三 研发部 天津
1 李四 财务部 北京
2 赵六 市场部 上海
六、apply函数
介绍:
apply函数是pandas里面所有函数中自由度最高的函数。该函数如下:
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None,args=(), **kwds)
该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
说太多概念性的东西可能不太理解,这里直接上样例:
import pandas as pd
data=pd.read_excel('E:\python机器学习数据建模与分析\数据\北京市空气质量数据.xlsx')
print(data['日期'])
data['年']=data['日期'].apply(lambda x:x.year)
print(data['年'])
# 输出结果如下:
0 2014-01-01
1 2014-01-02
2 2014-01-03
3 2014-01-04
4 2014-01-05
...
2150 2019-11-22
2151 2019-11-23
2152 2019-11-24
2153 2019-11-25
2154 2019-11-26
Name: 日期, Length: 2155, dtype: datetime64[ns]
0 2014
1 2014
2 2014
3 2014
4 2014
...
2150 2019
2151 2019
2152 2019
2153 2019
2154 2019
Name: 年, Length: 2155, dtype: int64
通过输出结果我们其实可以看出,我们使用apply函数可以将日期中的年份提取出来。
想要更加详细了解可以看这篇博客:python中apply函数
七、pandas.cut()函数
pandas.cut()函数可以将数据进行分类成不同的区间值。在数据分析中,例如有一组年龄数据,现在需要对不同的年龄层次的用户进行分析,那么我们可以根据不同年龄层次所对应的年龄段来作为划分区间,例如 bins = [1,28,50,150],对应 labels = [“青少年”,“中年”,“老年”],划分完后我们就可以很容易取出不同年龄段的用户数据。不仅是年龄数据,对于需要划分区间的数据都是十分有用的。
x:分箱时输入的数组,必须为一位数组bins:分类依据的标准,可以是int、标量序列或间隔索引(IntervalIndex)right:是否包含bins区间的最右边,默认为True,最右边为闭区间,False则不包含labels:要返回的标签,和bins的区间对应retbins:是否返回bins,当bins作为标量时使用非常有用,默认为Falseprecision:精度,int类型include_lowest:第一个区间是否为左包含(左边为闭区间),默认为False,表示不包含,True则包含duplicates:可选,默认为{default ‘raise’, ‘drop’},如果 bin 边缘不是唯一的,则引发 ValueError 或删除非唯一的。ordered:默认为True,表示标签是否有序。如果为 True,则将对生成的分类进行排序。如果为 False,则生成的分类将是无序的(必须提供标签)
举例:
按照学生平均成绩的高低进行分组(分为优、良、中、及格、不及格五种等级):
数据集如下:
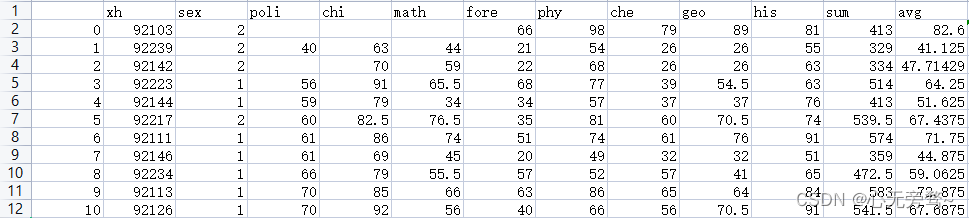
import pandas as pd
bins = [0, 60, 70, 80, 85, 90]
lastdata['等级'] = pd.cut(lastdata['avg'], bins, labels=['不及格', '及格', '中等', ' 良好', '优秀'])
print('对平均成绩的分组结果: \n{0}'.format(lastdata[['xh', 'sex', '等级']]))
结果如下(由于太长了只展示一部分):
对平均成绩的分组结果:
xh sex 等级
0 92103 2.0 良好
1 92239 2.0 不及格
2 92142 2.0 不及格
3 92223 1.0 及格
4 92144 1.0 不及格
5 92217 2.0 及格
6 92111 1.0 中等
7 92146 1.0 不及格
8 92234 1.0 不及格
9 92113 1.0 中等
10 92126 1.0 及格
八、pandas.get_dummies()函数
pandas.get_dummies()函数的作用将分类变量转化为0/1的虚拟变量。
虚拟变量也称作哑变量,是统计学处理分类型数据的一种常用方式。对具有K个类别的分类型变量X,也可以生成K个变量如
X
1
,
X
2
,
.
.
.
,
X
K
X_1,X_2,...,X_K
X1,X2,...,XK,且每个变量仅有0和1两种取值。这些变量称为分类型变量的虚拟变量。其中,1表示属于某个类别,0表示不属于某个类别,和True和False含义差不多。
举例:
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'A']])
#我们这里形成一个(3,2)的dataframe
df.columns = ['color', 'class']
pd.get_dummies(df)
Out[4]:
color_blue color_green color_red class_A class_B
0 0 1 0 1 0
1 0 0 1 0 1
2 1 0 0 1 0
通过上述例子我们可以发现,使用pandas.get_dummies()函数后,我们将所有的行和列索引都创建了个虚拟变量,0代表不属于这个类别,1代表属于该类别。
📢博客主页:https://blog.csdn.net/m0_63007797?spm=1011.2415.3001.5343
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 心无旁骛~ 原创,首发于 CSDN博客🙉
📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨