文章目录
- 一、Linux概述
- 二、Linux目录结构(重点)
- 2.1 Linux文件系统的类型
- 2.2 Linux文件系统的结构
- 2.3 具体的目录结构
- 2.3.1 Linux 根目录
- 2.3.2 Linux /usr目录
- 2.3.3 Linux /var 目录
- 2.3.4 tar包存放目录:crossed_swords:
- 三、vi和vim编辑器
- 四、Lnux开机,重启和用户登录注销
- 4.1 关机和重启的命令
- 4.2 用户登录和注销
- 五、用户管理
- 5.1 基本介绍
- 5.2 添加用户
- 5.3 指定/修改密码
- 5.4 删除用户
- 5.5 查询用户信息 指令
- 5.6 切换用户
- 5.7 查看当前登录用户的信息
- 5.8 用户组
- 5.9 用户和组相关文件
- 六、实用指令
- 6.1 指定运行级别
- 6.2 帮助指令
- 6.3 文件目录类(重要)
- 6.4时间日期
- 6.5 搜索查找
- 6.6 压缩和解压
- 6.7 清屏命令
- 6.8 管道命令
- 6.8.1 管道 | 指令
- 8.8.2 Cut— 根据条件 从命令结果中 提取 对应内容
- 6.8.3 查询指定文件和 目录个数
- 七、linux的主管理和权限管理
- 7.1 Liunx组的基本介绍
- 7.2 文件/目录的 所有者
- 7.3 文件/目录的 所在组
- 7.4 其他组
- 7.5 改变用户所在组
- 7.6 权限的基本介绍
- 7.7 文件及目录权限说明 实际案例
- 7.8 修改文件和目录权限-chmod:crossed_swords:
- 7.9 修改文件和目录 所有者-chown:crossed_swords:
- 7.10 修改文件和目录 所在组-chgrp:crossed_swords:
- 7.11 对文件夹(目录)的rwx的细节讨论
- 7.12 案例
- 八、crond任务调度(定时任务)
- 8.1 crontab 进行 定时任务的设置
- 8.2 at定时任务
- 九、Linux磁盘分区、挂载
- 9.1 Linux分区
- 9.2 挂载的经典案例
- 9.3 磁盘情况查询
- 十、LInux网络配置
- 10.1 Linux网络配置
- 10.2 配置一个指定的ip(不然每次都会变)
- 10.3 设置主机名和hosts映射 (配置别名)
- **10.4 网络请求**
- 十一、进程管理(ps)
- 11.1 基本知识
- 11.2 显示系统执行的进程
- 11.3 终止进程kill 和 killall
- 11.4 查看进程树 pstree
- 11.5 后台/前台任务
- 11.5.1 jobs命令
- 11.5.2 bg命令
- 11.5.3 fg命令
- 十二、服务(service)管理
- 12.1 service命令
- 12.2 服务的运行级别
- 12.3 chkconfig指令(在各个运行级别中)
- 12.4 systemctl命令(推荐)
- 12.5 打开或者关闭指定端口
- 12.6 访问地址
- 12.7 端口号查看
- 十三、动态监控(top)
- 13.1 动态监控进程的基本语法
- 13.2 动态监控进程的交互操作
- 13.3 监控网络状态
- 十四、RPM与YUM
- 14.1 rpm包的管理
- 14.2 yum
- 14.3 配置软件源
- 十五、 linux g++
- 十六、 shell脚本
- 16.1 shell脚本的执行方式
- 16.2 注释
- 16.3 shell变量
- 16.2.1 概要
- 16.2.2 用户自定义变量
- 16.2.2.1 变量定义
- 16.2.2.2 变量的使用
- 16.2.3 位置参数变量
- 16.2.4 预定义变量
- 16.2.5 环境变量
- 16.2.5 引用linux命令的运行结果
- 16.3 功能语句
- 16.3.1 read命令
- 16.3.2 expr命令
- 16.3.3 运算符( 替代expr命令)
- 16.3.4 test语句
- 16.4 分支语句
- 16.4.1 条件语句
- 16.4.2 多路分支语句
- 16.5 循环语句
- 16.5.1 for循环
- 16.5.2 while循环
- 16.5.3 循环控制语句
- 16.6 函数
- 16.6.1 常见的系统函数
- 16.6.1 basename
- 16.6.2 dirname
- 16.6.1 自定义函数
- 16.6.1.1 函数调用格式
- 16.6.1.2 函数变量作用域
- 16.6.1.3 返回值的方式
- 16.7 通配符+正则表达式
- 通配符
- 常用通配符
- shell转义符
- 正则表达式
- 概念
- 常用元字符
- 扩展正则表达式(-E)
- Perl内置正则(-P)
- 综合案列
- 了解:第二类正则
- 16.8 综合案例
- 十七、 日志管理
- 17.1 基本介绍
- 17.2 日志管理服务
- 17.3 自定义日志服务
- 十八、**基础配置**
- 环境变量
- PATH
- 自定义环境变量
- 主机名
- 命令别名
- hosts
- 查看系统信息
一、Linux概述
LInux的应用领域
服务器领域 - Linux在服务器领域的应用是最强的 - LInux免费、稳定、高效等特点在这里得到了很好的体现,尤其是在一些高端领域尤为广泛 嵌入式领域 - linux运行稳定、对网络的良好支持性、低成本,且可以根据需要进行网络裁剪,内核最小可达到几百kb的特点,使近些年来在嵌入式领域的应用得到非常大的提高 - 主要应用:机顶盒、数字电视、网络电话、程控交换机、手机、PDA、智能家居、智能硬件等都是其应用领域。以后在物联网中应用会更加广泛。
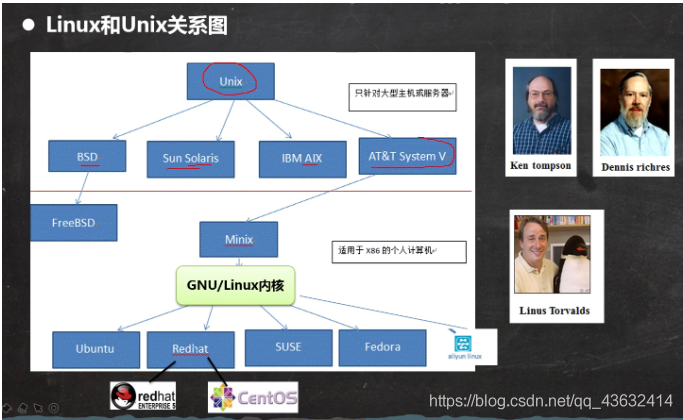
unix和LInux的关系
LInux的应用领域
服务器领域
- Linux在服务器领域的应用是最强的
- LInux免费、稳定、高效等特点在这里得到了很好的体现,尤其是在一些高端领域尤为广泛
嵌入式领域
- linux运行稳定、对网络的良好支持性、低成本,且可以根据需要进行网络裁剪,内核最小可达到几百kb的特点,使近些年来在嵌入式领域的应用得到非常大的提高
- 主要应用:机顶盒、数字电视、网络电话、程控交换机、手机、PDA、智能家居、智能硬件等都是其应用领域。以后在物联网中应用会更加广泛。
LInux的吉祥物tux
Linux主要的发行版本
Ubuntu(乌班图)、RedHat(红帽)、CentOS
vm与Linux的关系
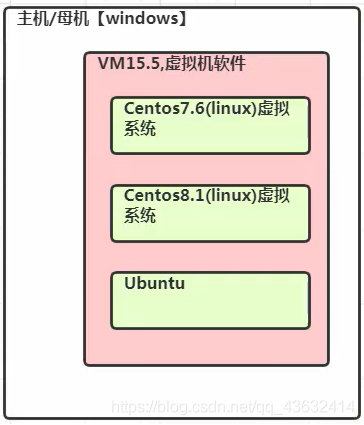
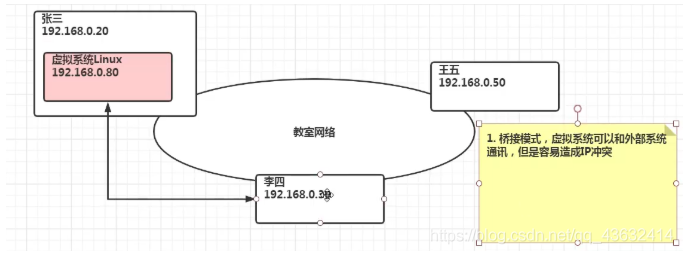
VMware网络连接的三种模式
桥接模式
- VMWare会虚拟一块网卡和真正的物理网卡就行桥接,这样,发到物理网卡的所有数据包就到了VMWare虚拟机,而由VMWare发出的数据包也会通过桥从物理网卡的那端发出。桥接网络是指本地物理网卡和虚拟网卡通过VMnet0虚拟交换机进行桥接。相当于在一个局域网内创立了一个单独的主机,他可以访问这个局域网内的所有的主机
- 该模式下主机网卡和虚拟机网卡的IP地址处于同一个网段,子网掩码、网关、DNS等参数都相同
- 桥接模式下虚拟机和主机在网络上地位相等,可以理解为一台新的电脑
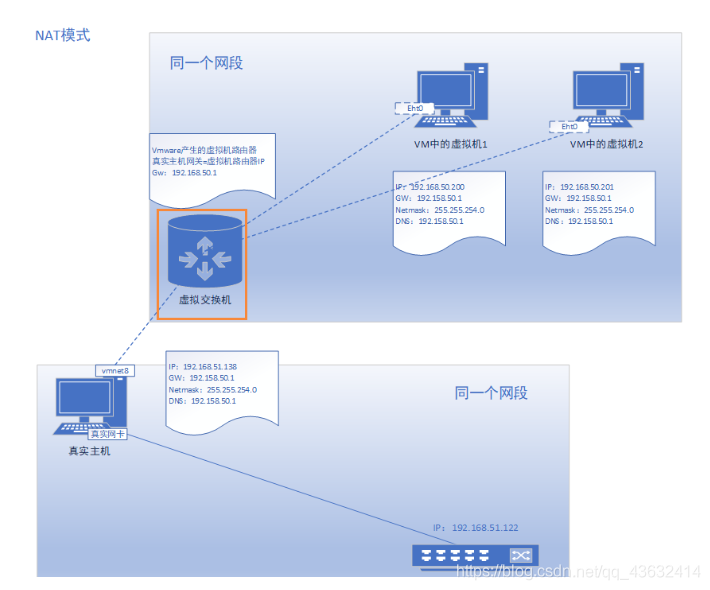
NAT模式
- 虚拟系统会通过真实主机的网络来访问外网,而真实主机相当于有两个网卡:真实网卡和虚拟网卡,真实网卡相当于链接了现实世界的真实路由器,而虚拟网卡相当于链接一个虚拟交换机/路由器(这个虚拟交换机同时链接虚拟机和真实主机),此时虚拟机想访问外网就必须通过真实主机IP地址,而外面看来也确实是真实主机的IP地址,实则是虚拟机访问的,完全看不到虚拟网络局域的内部形式。
- 网络地址转换模式。虚拟机系统可以和外部系统通讯,不早造成IP冲突
主机模式
- 他就是一个独立的系统,不和外界发生联系
二、Linux目录结构(重点)
2.1 Linux文件系统的类型
在任何一个操作系统中,文件系统无疑是其最重要的组件,用于组织和管理计算机存储设备上的大量文件,并提供用户交互接口。Linux同样具备完善的文件系统。用户既可以使用界面友好的Nautilus图形文件管理器,也可以使用功能强大的shell文件系统管理工具。
linux是一种兼容性很高的操作系统,支持的文件系统格式很多,大体可分以下几类:
- 磁盘文件系统:指本地主机中实际可以访问到的文件系统,包括硬盘、CD-ROM、DVD、USB存储器、磁盘阵列等。 常见文件系统格式有:autofs、coda、Ext(Extended File sytem,扩展文件系统)、Ext3、Ext4VFAT、ISO9660(通常是CD-ROM)、UFS(Unix File System,Unix文件系统)、FAT、FAT16、FAT32、NTFS等;
- 网络文件系统:是可以远程访问的文件系统,这种文件系统在服务器端仍是本地的磁盘文件系统,客户机通过网络远程访问数据。 常见文件系统格式有:NFS、Samba等;
- 专有/虚拟文件系统:不驻留在磁盘上的文件系统。常见格式有:TMPFS(临时文件系统)、PROCF(Process File System,进程文件系统)和LOOPBACKFS(Loopback File System,回送文件系统)。
目前Ext4是Linux系统广泛使用的一种文件格式。在Ext3基础上,对有效性保护、数据完整性、数据访问速度、向下兼容性等方面做了改进。最大特点是日志文件系统:可将整个磁盘的写入动作完整地记录在磁盘的某个区域上,以便在必要时回溯追踪。
SCSI与IDE设备命名:
- sata硬盘的设备名称是“/dev/sda”
- IDE硬盘的设备名称是“/dev/hda”
- 如果很在意系统的高性能和稳定性,应该使用SCSI硬盘
- 查看: cat /proc/partitions
Linux分区的命名方式:
- 字母和数字相结合
- 前两个字母表示设备类型
- “hd”代表IDE硬盘
- “sd”表示SCSI或SATA硬盘
- 第三个字母说明具体的设备
- “/dev/hda”表示第一个IDE硬盘
- “/dev/hdb”表示第二个IDE硬盘
交换分区:
- 将内存中的内容写入硬盘或从硬盘中读出,称为内存交换(swapping)
- 交换分区最小必须等于计算机的内存
- 可以创建多于一个的交换分区
- 尽量把交换分区放在硬盘驱动器的起始位置
2.2 Linux文件系统的结构
微软Windows操作系统的用户似乎已经习惯了将硬盘上的几个分区,并用A:、B:、C:、D:等符号标识。
Linux的文件组织模式犹如一颗倒置的树,这与Windows文件系统有很大差别。所有存储设备作为这颗树的一个子目录。存取文件时只需确定目录就可以了,无需考虑物理存储位置。
分区与目录的关系:
- 在Windows下,目录结构属于分区
- 在Linux下,分区属于目录结构
文件存储的具体硬件位置:
- linux的文件系统是采用级层式的树状目录结构,在此结构上的最上层是根目录“/",然后在此目录下在创建其他的目录。用户主目录 ~
- 在LInux世界里,一切皆文件
- 在Linux中,将所有硬件都视为文件来处理,
包括硬盘分区、CD-ROM、软驱以及其他USB移动设备等。Linux中提供了对每种硬件设备相应的设备文件, 一旦Linux系统可以访问到硬件,就将其上的文件系统挂载到目录树中的一个子目录中。==例如,用户插入USB移动存储器,Ubuntu Linux自动识别后,将其挂载到“/media/disk”目录下。==而不象Windows系统将USB存储器作为新驱动器,表示为“F:”盘。
2.3 具体的目录结构
2.3.1 Linux 根目录
| 一级目录 | 功能(作用) |
|---|---|
| /bin/ | 存放shell命令 |
| /boot/ | 系统启动目录,保存与系统启动相关的文件,如内核文件和启动引导程序(grub)文件等 |
| /dev/ | 设备文件保存位置 |
| /etc/ | 配置文件保存位置。系统内所有采用默认安装方式(rpm 安装)的服务配置文件全部保存在此目录中,如用户信息、服务的启动脚本、常用服务的配置文件等所有的系统管理所需要的配置文件和子目录,比如安装mysql数据库 |
| /home/ | 存放普通用户的主目录,在Linux中每个用户都有一个自己的目录,一般该目录是以用户的账号命名, 如用户 liming 的主目录就是 /home/liming |
| /lib/ | 系统开机所需要的最基本的动态链接库 |
| /media/ | 挂载目录。系统建议用来挂载媒体设备,如U盘和光盘 |
| /mnt/ | 挂载目录。早期 Linux 中只有这一个挂载目录,并没有细分。系统建议这个目录用来挂载额外的设备,如 U 盘、移动硬盘和其他操作系统的分区 |
| /misc/ | 挂载目录。系统建议用来挂载 NFS 服务的共享目录。虽然系统准备了三个默认挂载目录 /media/、/mnt/、/misc/,但是到底在哪个目录中挂载什么设备可以由管理员自己决定。例如,笔者在接触 Linux 的时候,默认挂载目录只有 /mnt/,所以养成了在 /mnt/ 下建立不同目录挂载不同设备的习惯,如 /mnt/cdrom/ 挂载光盘、/mnt/usb/ 挂载 U 盘,都是可以的 |
| /opt/ | 第三方安装的软件保存位置。这个目录是放置和安装其他软件的位置,手工安装的源码包软件都可以安装到这个目录中。注意/usr/local/ 目录也可以用来安装软件 |
| /root/ | 超级权限者的用户主日录, 该目录直接在“/”下 |
| /sbin/ | 保存与系统环境设置相关的命令,只有 root 可以使用这些命令进行系统环境设置,但也有些命令可以允许普通用户查看, 存放的是系统管理员使用的系统管理程序 |
| /srv/ | 服务数据目录。一些系统服务启动之后,可以在这个目录中保存所需要的数据 |
| /tmp/ | 临时目录。系统存放临时文件的目录,在该目录下,所有用户都可以访问和写入。建议此目录中不能保存重要数据,最好每次开机都把该目录清空 |
| 一级目录 | 功能(作用) |
|---|---|
| /lost+found/ | 当系统意外崩溃或意外关机时,产生的一些文件碎片会存放在这里。在系统启动的过程中,fsck 工具会检查这里,并修复已经损坏的文件系统。这个目录只在每个分区中出现,例如,/lost+found 就是根分区的备份恢复目录,/boot/lost+found 就是 /boot 分区的备份恢复目录 |
| /proc/ | 虚拟文件系统。该目录中的数据并不保存在硬盘上,而是保存到内存中。主要保存系统的内核、进程、外部设备状态和网络状态等。如 /proc/cpuinfo 是保存 CPU 信息的,/proc/devices 是保存设备驱动的列表的,/proc/filesystems 是保存文件系统列表的,/proc/net 是保存网络协议信息的… |
| /sys/ | 虚拟文件系统。和 /proc/ 目录相似,该目录中的数据都保存在内存中,主要保存与内核相关的信息[不能动] |
2.3.2 Linux /usr目录
usr(注意不是 user),全称为 Unix Software Resource,此目录用于存储系统软件资源。
Linux 系统中,所有系统默认的软件都存储在 /usr 目录下,/usr 目录类似 Windows 系统中 C:\Windows\ + C:\Program files\ 两个目录的综合体。
| 子目录 | 功能(作用) |
|---|---|
| /usr/bin/ | 存放系统命令,普通用户和超级用户都可以执行。这些命令和系统启动无关,在单用户模式下不能执行 |
| /usr/sbin/ | 存放根文件系统不必要的系统管理命令,如多数服务程序,只有 root 可以使用。 |
| /usr/lib/ | 应用程序调用的函数库保存位置 |
| /usr/XllR6/ | 图形界面系统保存位置 |
| /usr/local/ | 手动安装的软件保存位置。我们一般建议源码包软件安装在这个位置 |
| /usr/share/ | 应用程序的资源文件保存位置,如帮助文档、说明文档和字体目录 |
| /usr/src/ | 源码包保存位置。我们手工下载的源码包和内核源码包都可以保存到这里。不过笔者更习惯把手工下载的源码包保存到 /usr/local/src/ 目录中,把内核源码保存到 /usr/src/linux/ 目录中 |
| /usr/include | C/C++ 等编程语言头文件的放置目录 |
2.3.3 Linux /var 目录
/var 目录用于存储动态数据,例如缓存、日志文件、软件运行过程中产生的文件等。通常,此目录下建议包含如表 4 所示的这些子目录。
| /var子目录 | 功能(作用) |
|---|---|
| /var/lib/ | 程序运行中需要调用或改变的数据保存位置。如 MySQL 的数据库保存在 /var/lib/mysql/ 目录中 |
| /var/log/ | 登陆文件放置的目录,其中所包含比较重要的文件如 /var/log/messages, /var/log/wtmp 等。 |
| /var/run/ | 一些服务和程序运行后,它们的 PID(进程 ID)保存位置 |
| /var/spool/ | 里面主要都是一些临时存放,随时会被用户所调用的数据,例如 /var/spool/mail/ 存放新收到的邮件,/var/spool/cron/ 存放系统定时任务。 |
| /var/www/ | RPM 包安装的 Apache 的网页主目录 |
| /var/nis和/var/yp | NIS 服务机制所使用的目录,nis 主要记录所有网络中每一个 client 的连接信息;yp 是 linux 的 nis 服务的日志文件存放的目录 |
| /var/tmp | 一些应用程序在安装或执行时,需要在重启后使用的某些文件,此目录能将该类文件暂时存放起来,完成后再行删除 |
2.3.4 tar包存放目录⚔️
在当前用户下建立二个文件夹,一个用来存放安装包,一个是安装软件。

以安装JDK1.8为例
1.将JDK安装包上传到存放安装包路径中:
2.在Linux目录下查看是否上传成功:
版本是jdk-8u221-linux-x64.tar.gz链接:https://pan.baidu.com/s/1GZnUwB3nraObgperKlmBCg 提取码:17xx
[abc@hadoop102 ~]$ ls /opt/software/
3. 解压 JDK 到/opt/module 目录下
[abc@hadoop102 software]$ tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/module/
4.配置 JDK 环境变量
[abc@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/
export PATH=$PATH:$JAVA_HOME/bin
[abc@hadoop102 ~]$ source /etc/profile
5.测试 JDK 是否安装成功
[abc@hadoop102 ~]$ java -version

6.高效修改文件
linux 修改文件 备份原始文件
cp file.txt file_backup.txt
三、vi和vim编辑器
详细见: vim使用
四、Lnux开机,重启和用户登录注销
4.1 关机和重启的命令
基本介绍
shutdown -h now 立刻进行关机
shutdown -h 1 ”hello,1分钟后会关机了“
shutdown -r now 现在重新启动计算机
halt 关机
reboot 重新启动
syn 把内存的数据同步到磁盘
注意细节
-
不管是重启系统还是关闭系统,首先要运行sync命令,把内存中的数据写到磁盘中
-
目前的shutdown/reboot/halt等命令均已,保证在关机前进行了sync
4.2 用户登录和注销
基本介绍
-
登陆时尽量少用root账号登录,因为他是系统管理员,最大的权限,避免操作失误。可以利用普通用户登录,登陆后再用 ”su - 用户名“ 命令来切换成系统管理员身份
-
在提示符下输入logout即可注销用户
使用细节
- logout 注销指令在图形运行级别无效,在shell界面有效
五、用户管理
5.1 基本介绍
Linux系统是一个多用户多任务的操作系统,任何一个要使用系统资源的用户,都必须先向系统管理员申请一个账号,然后以这个账号的身份进入系统
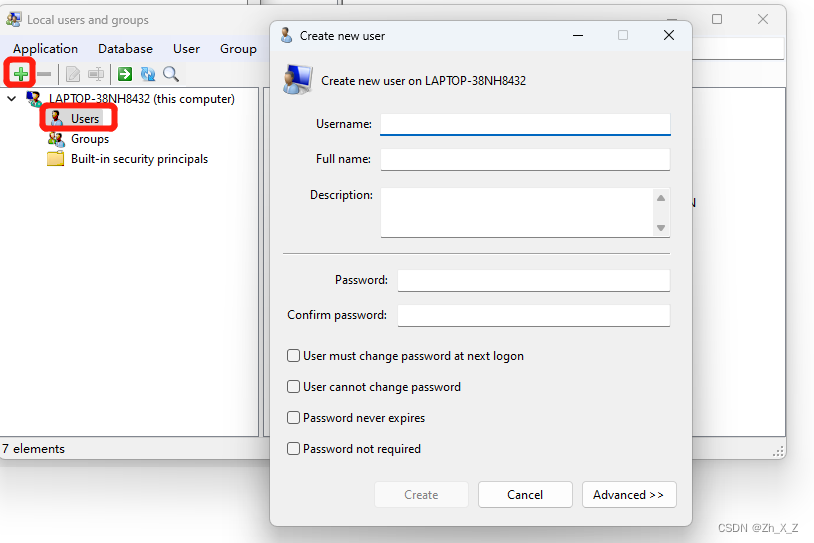
5.2 添加用户
- 基本语法
useradd -m 用户名
useradd -m -g 组名 用户名
- 例子(root权限下)
useradd hucheng
#添加一个用户chucheng,默认该用户的家目录在/home/hucheng
-
细节说明
会自动的创建和创建的用户同名的家目录
1、当用户创建成功后,会自动的创建和用户同名的家目录 2、也可以通过useradd -d 指定目录 新的用户名 来给新创建的用户指定家目录
5.3 指定/修改密码
- 基本语法
passwd 用户名
- 实例

- 补充,显示当前用户所在的目录pwd
5.4 删除用户
- 基本语法
userdel -r 用户名
- 实例
1.删除用户zhanzhiwen,但是要保留目录
2.删除用户以及用户主目录 ,userdel -r 用户名

5.5 查询用户信息 指令
- 基本语法
id 用户名
- 实列
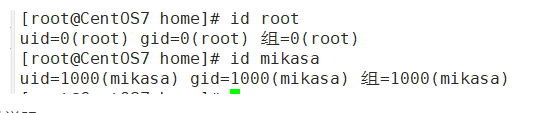
- 细节说明
当用户不存在是,返回无此用户
5.6 切换用户
- 介绍
在操作Linux时,如果当前用户的权限不够,可以通过su - 指令,切换到更高权限的用户,如root
- 基本语法
su 用户名
su -c whoami 用户名 #切换并显示用户信息
- 实列说明
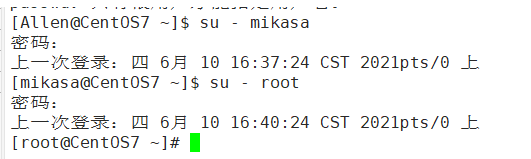
- 细节说明
1.从权限高的用户切换到权限低的用户时,不需要输入密码,反之需要
2**.当需要返回到原来用户时,使用exit/logout指令 建议使用 logout **
5.7 查看当前登录用户的信息
- 基本语法
whoami/who am i
- 实例

5.8 用户组
- 介绍
类似于角色,系统可以对有共性/权限的多个用户进行统一的管理
- 新增组
指令:groupadd 组名
- 删除组
指令:groupdel 组名
- 注意:如果当添加用户时没有指定组,会默认创建和这个用户同名的组,同时把用户放到该组里
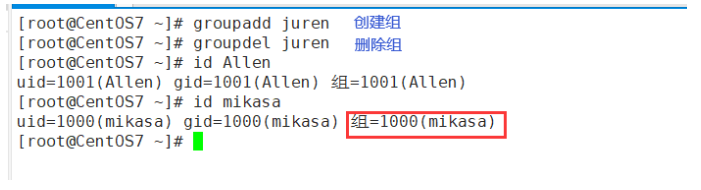
- 增加用户时直接加上组
指令:useradd -g 用户组 用户名

- 移动组
usermod -g 组名 用户名

5.9 用户和组相关文件
- /etc/passwd 文件
用户(user)的配置文件,记录用户的各种信息
每行的含义:用户名:口令:用户标识号:组标识号:注释性描述:主目录: 登录Shell
- /etc/shadow文件
口令配置文件
每行的含义:登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
- /etc/group文件
组(group)的配置文件,记录Linux包含的组的信息
每行含义:组名:口令:组标识号:组内用户列表
六、实用指令
6.1 指定运行级别
基本介绍
运行级别说明:
0:关机
1:单用户【找回丢失密码】
2:多用户状态没有网络服务
3:多用户状态有网络服务
4:系统未使用保留给用户
5:图形界面
6:系统重启
常用运行级别是3和5,也可以指定默认运行级别
应用实例
命令:init[0123456]应用案例:通过init来切换不同的运行级别,比如动5-3,然后关机
查看当前的运行级别
systemctl get-ddefault

改变为 systemctl set-default multi-user.target007
6.2 帮助指令
- man获得帮助信息
基本语法:man [命令或配置文件](功能描述:获得帮助信息)
如:
man ls
通常联机帮助信息包括以下几个部分:
NAME:命令的名称
SYNOPSIS:命令的语法格式
DESCRIPTION:命令的一般描述以及用途
OPTIONS:描述命令所有的参数或选项
SEE ALSO:列出联机帮助页中与该命令直接相关或功
能相近的其他命令
BUGS:解释命令或其输出中存在的任何已知的问题或
缺陷
EXAMPLES:普通的用法示例
AUTHORS:联机帮助页以及命令的作者
设置中文
centos7设置man下显示中文
中文查看命令
cman ls
在linux下隐藏文件是以 “.” 开头的
- help指令
功能描述:获得shell内置命令的帮助信息
基本语法:help
6.3 文件目录类(重要)
- file指令
功能描述:输出将显示该文件信息
基本语法:file filename
应用实例
linux@ubuntu:~$ file /usr/games/banner
banner: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), for GNU/Linux 2.6.0, dynamically linked (uses shared libs), stripped
linux@ubuntu:~$ file Textfile.txt
Textfile.txt: UTF-8 Unicode text
- pwd指令
功能描述:显示当前工作目录的绝对路径
基本语法:pwd
注意: 理解绝对路径和相对路径(相对路径是针对当前位置的路径)
- ls指令
基本语法:ls [选项] [目录或是文件]
常用选项
-a : 显示当前目录所有的文件和目录,包括隐藏的
-l : 以列表的方式显示信息
注意: 一般情况下使用ll指令替代
- cd指令
功能描述:切换到指定的目录
基本语法:cd [参数]
| 特殊符号 | 表达的路径 |
|---|---|
| . | 当前目录 |
| … | 上一级目录 |
| / | 根目录 |
| ~ | 当前登录用户的HOME目录 |
| - | 返回 |
cd 或者cd ~ 回到当前用户的家目录
cd … 回到当前目录的上一级目录
cd / 根目录
- touch指令
功能描述:用于创建空文件
基本语法:touch 文件名1 文件名2 …… // tou tab就行
- mkdir指令
功能描述:mkdir指令用于创建目录(默认只能创建一级目录)
基本语法:mkdir [选项] 要创建的目录
常用选项
-p :创建多级目录
-m<目标属性>或--mode<目标属性>建立目录的同时设置目录的权限
应用实例
创建目录的同时创建文件
mkdir 要创建的目录 && touch 文件名
同时创建多个目录
mkdir linux optee-os trusted-firmware trusted-firmware-ssp-2.2 u-boot tools
设置权限
#在目录`/usr/meng`下建立子目录test,并且只有文件主有读、写和执行权限,其他人无权访问
mkdir -m 700 /usr/meng/test
拓展: 可以用 > 创建单目录
/var/log/hsp.log 单用 > 表示将空写入文件
将空内容覆盖写入到 此文件,如果该文件不存在,就创建该文件
- rmdir
功能描述:用于删除一个目录
基本语法: rmdir [-p] directory_name
- rm指令
基本语法:rm -rf 要删除的目录
常用选项
-r : 递归删除整个文件夹
-f :强制删除不提示
使用细节:强制删除不提示的方式,带上-f参数即可
如果需要删除非空目录,需要使用rm -rf 要删除的目录
应用实例
rm -rf /tmp 命令来删除一个非空的子目录
rm -rf /tmp/* 命令将会删除/tmp目录下的所有文件和子目录,但会保留/tmp目录
- mv指令(move,移动文件与目录或重命名)(以可剪切文件夹)
基本语法:
#方式1:
mv 待移动文件 目标位置/ #(移动文件)
mv 待移动目录 目标位置/ #(移动目录)
mv 待移动文件 目标位置/重命名 #(移动文件+重命名)
#方式2:
[用户名@localhost 目标位置]$ mv 待移动文件 . #不改变名字可以直接. 改名就用新名称代替 .
注意: 写好后缀名
应用实例
案例1:将/home/cat.txt文件 重新命名为pig.txt Cut
案例2:将/home/pig.txt 文件 移动到/root目录下
案例3: 移动整个目录: /opt/bbb 移动到/home下: mv /opt/bbb /home/
- cp指令(copy拷贝文件导指定目录下)
基本语法:
#方法1:
cp -r 待复制文件 目标位置/ #(不改名)
cp -r 待复制文件 目标位置/改名 #(改名)
#方式2:
[用户名@localhost 目标位置]$ cp 待复制文件 . #不改变名字可以直接. 改名就用新名称代替 .
常用选项:
-r 递归复制整个文件夹
应用实例
#案例1:
cp 1.txt ../ #不改名
cp 1.txt ../2.txt #改名
#案例2:将 /home/hello.txt 拷贝到 /home/bbb 目录下
cp /home/hello.txt /home/bbb/
#案例3:递归复制整个文件夹,将/home/aaa 目录下的文件全部拷贝到/home/bbb中
cp -r /home/aaa /hom/bbb/ (是将整个目录和目录本身拷贝进来)
#案例4
一般主机粘文件到终端上时,通过cp来保存
- cat指令
功能描述:查看文件内容
基本语法: cat [选项] 要查看的文件
常用选项:
-n 显示行号
使用细节:**cat只能浏览文件,而不能修改文件,**为了浏览方便,一般会带上管道命令 |more
cat -n /etc/profile | more
- gedit指令
功能描述:可视化方式打开文本文件
- more指令
more指令是一个基于VI编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容。more指令中内置了若干快捷键(交互的指令)
基本语法: more 要查看的文件
操作说明:
空白键(space) 代表向下翻一页;
Enter 代表向下翻「一行」;
q 退出
Ctrl+F 向下滚动一屏
Ctrl+B 返回上一屏
:f 输出文件名和当前行的行号
- less指令
功能描述:大文件查看
基本语法:less 要查看的文件
- head指令
head用于显示文件的开头部分内容,默认情况下head指令显示文件的前10行内容
基本语法:
head 文件 (功能描述:查看文件头10行内容)
head -n 5文件 (功能描述:查看文件头5行内容,5可以是任意行数)
应用实例
/etc/profile的前面5行代码
- tail指令
tail用于输出文件中尾部的内容,默认情况下tail指令显示文件的前10行内容。或者 实时追踪该文档的所有更新
基本语法:
tail文件 (功能描述:查看文件尾10行内容)
tail -n 5文件 (功能描述:查看文件尾5行内容,5可以是任意行数)
tail -f 文件(功能描述:实时追踪该文档的所有更新)
应用实例
案例1:查看/etc/profile最后5行的代码tail-n 5/etc/profile
案例2:实时监控 mydate.txt,看看到文件有变化时,是否看到,实时的追加 hello,world
- echo指令
输出内容到控制台
基本语法
echo [选项] [输出内容] #ec 回车就行
-n 换行输出
应用实例
案例:使用echo指令输出环境变量,比如输出
$PATH $HOSTNAME, echo $HOSTNAME
案例:使用echo指令输出hello,world!

- 指令 > 和>> 指令
输出重定向 和 追加 当文件不存在会自动创建
基本语法
ls -l > 文件 (功能描述:列表的内容写入文件a.txt中(覆盖写)
ls -al >> 文件 (功能描述:列表的内容追加到文件aa.txt的末尾)
cat 文件1 > 文件2 (功能描述:将文件1的内容覆盖到文件2)
echo "内容” 文件
xargs
基本语法
指令1 | xargs 指令2
xargs和管道类似, 与管道不同的是,管道给第二个命令传递是直接传到命令输入上,这种方式要求命令本身的支持,支持的命令较少。
xargs,则是把第一个命令的输出作为参数传递到第二个命令上,这种方式只要第二个命令可以接受参数即可,支持的命令较多。
例子:
echo test.txt | cat
test.txt
echo test.txt | xargs cat #显示test.txt中的内容
echo test.txt | cat 是把 “test.txt” 这个字符串直接让cat输出
echo test.txt | xargs cat 是把 “test.txt” 作为参数传递给cat,表示把 test.txt 这个文件的内容输出
exec
基本语法
指令1 -exec 指令2 {} \;
-exec 和 xargs 的作用相似,都是把前一个命令的输出作为参数传给第二个命令
find . -name "test.txt" -exec cat {} \;
显示test.txt中的内容
- ln指令
功能描述:创建链接,类似于windows里的快捷键方式
基本语法:ln -s [原文件或目录] [目标软链接名]
常用选项:
-s: 创建软链接,在缺省情况下,创建硬链接
应用实例
linux@ubuntu:~$ ln -s /proc/cpuinfo mycpuinfo
linux@ubuntu:~$ ls –l mycpuinfo
lrwxrwxrwx 1 wdl wdl 13 2007-09-22 00:43 mycpuinfo -> /proc/cpuinfo
注意:
-
Linux中有两种类型的链接: a. 硬链接是利用Linux中为每个文件分配的物理编号——inode建立链接。因此,硬链接不能跨越文件系统。 b. 软链接(符号链接)是利用文件的路径名建立链接。 -
通常建立软链接使用绝对路径而不是相对路径,以最大限度增加可移植性。
-
如果链接文件名已经存在但不是目录,将不做链接。目标文件可以是任何一个文件名,也可以是一个目录。
-
有效性:
-
如果是修改硬链接的目标文件名,链接依然有效
-
如果修改软链接的目标文件名,则链接将断开
-
假如删除目标文件后,重新创建一个同名文件,软链接将恢复,硬链接不再有效,因为文件的inode已经改变
-
- history指令
查看已经执行过历史命令,也可以执行历史指令
history 显示所有的历史命令
history 10 显示最近使用过的10个指令
!5 执行历史编号为5的指令
6.4时间日期
- date指令-显示当前日期
基本语法:
date 显示当前时间
date +%Y 显示当前年份
date +%m 显示当前月份
date +%d 显示当前是哪一天
date "+%Y-%m-%d %H:%M:%S" 显示年月日时分秒 就是自己设计格式
date指令还可以设置日期
date -s 字符串时间
date -s "2021-6-20 16:44:30"
- cal指令
查看日历指令
cal [选项] (功能描述:不加选项,显示本月日历)
cal 2021 显示2021整年的日历
6.5 搜索查找
- locate指令
locate指令可以快速定位文件路径。locate命令利用事先建立的系统中所有文件名称及路径的locate数据库实现快速定位的文件名。Locate指令无需遍历整个文件系统,查询速度较快。为了保障查询结果的准确度,管理员必须定期更新locate时刻
基本语法:locate 搜索文件
特别说明:由于locate指令基于数据进行查询,所以第一次运行前,必须是使用updatedb指令创建locate数据库
实例1:查找和pwd相关的所有文件
root ~ # locate pwd
/bin/pwd
/etc/.pwd.lock
/sbin/unix_chkpwd
/usr/bin/pwdx
/usr/include/pwd.h
实例2: 搜索etc目录下所有以sh开头的文件
root ~ # locate /etc/sh
/etc/shadow
/etc/shadow-
/etc/shells
实例3:搜索etc目录下,所有以m开头的文件
root ~ # locate /etc/m
/etc/magic
/etc/magic.mime
/etc/mailcap
/etc/mailcap.order
/etc/manpath.config
/etc/mate-settings-daemon
- which指令 ,可以查看某个指令在哪个目录下
查找文件、显示命令路径:
[root@localhost ~]# which pwd
/bin/pwd
[root@localhost ~]# which adduser
/usr/sbin/adduser
- grep指令 和 管道符号 | 查找指定的文件中的内容
grep过滤查找,管道符,“|“,表示将前一个命令输出传递给后面的命令处理
基本语法:grep [选项] 查找内容 源文件
选项:
-n 显示匹配行及行号
-i 忽略字母大小写
-v 不查找后面的
两种写法 hello.txt文件夹中输出同样的
cat /home/hello.txt | grep -n "yes"
grep -n "yes" /home/hello.txt
-
find指令 查找指定的文件
find指令指令 将从指定目录向下递归遍历各个子目录,只要满足条件的文件或者目录就显示在终端上
find [搜索范围] [选项]
常用:
1.搜索桌面目录下,文件名包含(1的文件
find 桌面路径 -name "*1*"
2.搜索桌面目录下,所有以.txt]为扩展名的文件
find 桌面路径 -name "*.txt"
3.搜索桌面目录下,以数字1开头的文件
find 桌面路径 -name ""1*"
选项说明(可填选项)
| 选项 | 功能 |
|---|---|
| -name <查询方式> | 按照指定的文件名查找模式查找文件 |
| -user <用户名> | 查找属于指定用户名所有文件 |
| -size <文件大小> | 按照指定的文件大小查找文件 |
| atime +10 | 读取时间 +10是大于十天 -10是小于十天 |
| -mtime | 修改时间 |
| -ctime | 创建时间 |
-atime<24小时数> 查找在指定时间曾被存取过的文件或目录,单位以24小时计算。
说明:当查询路径下无该文件,就不会有任何显示
# 当前目录搜索所有文件,文件内容 包含 “140.206.111.111” 的内容
find . -type f -name "*" | xargs grep "140.206.111.111"
根据文件或者正则表达式进行匹配
列出当前目录及子目录下所有文件和文件夹
find .
在/home目录下查找以.txt结尾的文件名
find /home -name "*.txt"
同上,但忽略大小写
find /home -iname "*.txt"
当前目录及子目录下查找所有以.txt和.pdf结尾的文件
find . \( -name "*.txt" -o -name "*.pdf" \)
或
find . -name "*.txt" -o -name "*.pdf"
匹配文件路径或者文件
find /usr/ -path "*local*"
基于正则表达式匹配文件路径
find . -regex ".*\(\.txt\|\.pdf\)$"
同上,但忽略大小写
find . -iregex ".*\(\.txt\|\.pdf\)$"
否定参数
找出/home下不是以.txt结尾的文件
find /home ! -name "*.txt"
根据文件类型进行搜索
find . -type 类型参数
类型参数列表:
- f 普通文件
- l 符号连接
- d 目录
- c 字符设备
- b 块设备
- s 套接字
- p Fifo
基于目录深度搜索
向下最大深度限制为3
find . -maxdepth 3 -type f
搜索出深度距离当前目录至少2个子目录的所有文件
find . -mindepth 2 -type f
根据文件时间戳进行搜索
find . -type f 时间戳
UNIX/Linux文件系统每个文件都有三种时间戳:
- 访问时间 (-atime/天,-amin/分钟):用户最近一次访问时间。
- 修改时间 (-mtime/天,-mmin/分钟):文件最后一次修改时间。
- 变化时间 (-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
搜索最近七天内被访问过的所有文件
find . -type f -atime -7
搜索恰好在七天前被访问过的所有文件
find . -type f -atime 7
搜索超过七天内被访问过的所有文件
find . -type f -atime +7
搜索访问时间超过10分钟的所有文件
find . -type f -amin +10
找出比file.log修改时间更长的所有文件
find . -type f -newer file.log
根据文件大小进行匹配
find . -type f -size 文件大小单元
文件大小单元:
- b —— 块(512字节)
- c —— 字节
- w —— 字(2字节)
- k —— 千字节
- M —— 兆字节
- G —— 吉字节
搜索大于10KB的文件
find . -type f -size +10k
搜索小于10KB的文件
find . -type f -size -10k
搜索等于10KB的文件
find . -type f -size 10k
删除匹配文件
删除当前目录下所有.txt文件
find . -type f -name "*.txt" -delete
根据文件权限/所有权进行匹配
当前目录下搜索出权限为777的文件
find . -type f -perm 777
找出当前目录下权限不是644的php文件
find . -type f -name "*.php" ! -perm 644
找出当前目录用户tom拥有的所有文件
find . -type f -user tom
找出当前目录用户组sunk拥有的所有文件
find . -type f -group sunk
借助-exec选项与其他命令结合使用
找出当前目录下所有root的文件,并把所有权更改为用户tom
find .-type f -user root -exec chown tom {} \;
上例中, {} 用于与 -exec 选项结合使用来匹配所有文件,然后会被替换为相应的文件名。
找出自己家目录下所有的.txt文件并删除
find $HOME/. -name "*.txt" -ok rm {} \;
上例中, -ok 和 -exec 行为一样,不过它会给出提示,是否执行相应的操作。
查找当前目录下所有.txt文件并把他们拼接起来写入到all.txt文件中
find . -type f -name "*.txt" -exec cat {} \;> all.txt
将30天前的.log文件移动到old目录中
find . -type f -mtime +30 -name "*.log" -exec cp {} old \;
找出当前目录下所有.txt文件并以“File:文件名”的形式打印出来
find . -type f -name "*.txt" -exec printf "File: %s\n" {} \;
因为单行命令中-exec参数中无法使用多个命令,以下方法可以实现在-exec之后接受多条命令
-exec ./text.sh {} \;
搜索但跳出指定的目录
查找当前目录或者子目录下所有.txt文件,但是跳过子目录sk
find . -path "./sk" -prune -o -name "*.txt" -print
find其他技巧收集
要列出所有长度为零的文件
find . -empty
其它实例
find ~ -name '*jpg' # 主目录中找到所有的 jpg 文件。 -name 参数允许你将结果限制为与给定模式匹配的文件。
find ~ -iname '*jpg' # -iname 就像 -name,但是不区分大小写
find ~ ( -iname 'jpeg' -o -iname 'jpg' ) # 一些图片可能是 .jpeg 扩展名。幸运的是,我们可以将模式用“或”(表示为 -o)来组合。
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f # 如果你有一些以 jpg 结尾的目录呢? (为什么你要命名一个 bucketofjpg 而不是 pictures 的目录就超出了本文的范围。)我们使用 -type 参数修改我们的命令来查找文件。
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type d # 也许你想找到那些命名奇怪的目录,以便稍后重命名它们
最近拍了很多照片,所以让我们把它缩小到上周更改的文件
find ~ \( -iname '*jpeg' -o -iname '*jpg' \) -type f -mtime -7
你可以根据文件状态更改时间 (ctime)、修改时间 (mtime) 或访问时间 (atime) 来执行时间过滤。 这些是在几天内,所以如果你想要更细粒度的控制,你可以表示为在几分钟内(分别是 cmin、mmin 和 amin)。 除非你确切地知道你想要的时间,否则你可能会在 + (大于)或 - (小于)的后面加上数字。
但也许你不关心你的照片。也许你的磁盘空间不够用,所以你想在 log 目录下找到所有巨大的(让我们定义为“大于 1GB”)文件:
find /var/log -size +1G
或者,也许你想在 /data 中找到 bcotton 拥有的所有文件:
find /data -owner bcotton
你还可以根据权限查找文件。也许你想在你的主目录中找到对所有人可读的文件,以确保你不会过度分享。
find ~ -perm -o=r
删除 mac 下自动生成的文件
find ./ -name '__MACOSX' -depth -exec rm -rf {} \;
统计代码行数
find . -name "*.java"|xargs cat|grep -v ^$|wc -l # 代码行数统计, 排除空行
6.6 压缩和解压
文件的归档和压缩
压缩文件: 用户在进行数据备份时,需要把若干文件整合为一个文件以便保存。尽管整合为一个文件进行管理,但文件大小仍然没变。
**归档文件:**归档文件是将一组文件或目录保存在一个文件中。压缩文件也是将一组文件或目录保存一个文件中,并按照某种存储格式保存在磁盘上,所占磁盘空间比其中所有文件总和要少。归档文件仍是没有经过压缩的,它所使用的磁盘空间仍等于其所有文件的总和。因而,用户可以将归档文件再进行压缩,使其容量更小。
压缩工具
-
gzip: 是Linux中最流行的压缩工具,具有很好的移植性,可在很多不同架构的系统中使用。
-
bzip2: 在性能上优于gzip,提供了最大限度的压缩比率
-
zip: 如果用户需要经常在Linux和微软Windows间交换文件
压缩工具 解压工具 文件扩展名
gzip gunzip .gz
bzip2 bunzip2 .bz2
zip unzip .zip
- gzip/gunzip指令
gzip用于压缩文件,gunzip用于解压文件的
基本语法:
gzip -f 文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件
gunzip 文件 (功能描述:解压文件命令)
常用选项
-l 查看压缩文件内的信息,包括文件数、大小、压缩比等参数,并不进行文件解压
-d 将文件解压,功能与gunzip相同
-num 指定压缩比率,num为1~9个等级
例子
linux@ubuntu:~$ gzip -9 file_1
linux@ubuntu:~$ gzip -l file_1.gz
compressed uncompressed ratio uncompressed_name
1200 4896 76.0% file_1
linux@ubuntu:~$ gunzip file_1.gz
- zip/unzip指令
zip用于压缩文件,unzip用于解压的,在整个项目打包发布中很有用的,
zip [选项] xxx.zip (将要压缩的内容(一般是文件和文件夹))
uzip [选项] xxx.zip (功能描述:解压文件)
常用选项
-r 递归压缩,即压缩目录
-d <目录> : 指定解压后文件的存放目录
例子
linux@ubuntu:~$ zip -r myhome.zip /home/
linux@ubuntu:~$ unzip -d /home/dd/
- tar指令
tar指令是打包指令,最后打包后的文件是.tar.gz的文件
# 打包(有gzip属性的)
tar -czvf 目标位置/xxx.tar.gz 待打包的目录1/ 待打包的目录2/ 待打包的文件1 待打包的文件2 ....
# 解压(有gzip属性的)
tar -xzvf 打包的内容 -C 目标位置/ #(打包到目标位置, 一般安装位置为/usr/local/)
tar -xzvf 打包的内容 #(打包到当前位置)
# 总结
#tar.xz(.tar)文件 打包命令是 tar -cvf 目标位置/xxx.tar 待打包的内容
#tar.gz文件 打包命令是 tar -czvf 目标位置/xxx.tar.gz 待打包的内容
#tar.bz2文件 打包命令是 tar -cjvf 目标位置/xxx.tar.bz2 待打包的内容
#tar.xz文件 解压命令是 tar -xvf 打包的内容
#tar.gz文件 解压命令是 tar -xzvf 打包的内容
#tar.bz2文件 解压命令是 tar -xjvf 打包的内容
常用选项
| 选项 | 功能 |
|---|---|
| -c | 打包.tar文件 |
| -x | 解包.tar文件 |
| -v | 显示详细信息 |
| -f | 指定压缩后的文件名 |
| -z | 由tar生成归档,然后由gzip压缩 有gzip属性的(文件名: xxx.tar.gz) |
| -j | 由tar生成归档,然后由bzip2压缩 有bzip2属性的(文件名: xxx.tar.bz2) |
例子
案例1:压缩多个文件,将/home/pig.txt和/home/cat.txt 压缩成 pc.tar.gz
tar -czvf pc.tar.gz /home/pig.txt /home/cat.txt
案例2:将/home的文件夹压缩成myhome.tar.gz
tar -czvf myhome.tar.gz /home/
案例3:pc.tar.gz 解压到当前目录
tar -xzvf pc.tar.gz
案例4:将myhome.tar.gz 解压到/opt/tmp2目录下 mkdr/opt/tmp2/
tar -xzvf myhome.tar.gz -C opt/tmp2/
案例5:将myExamples/目录下的所有文件全部归档,打包到一个文件中myExamples.tar;
linux@ubuntu:~$ tar –cf myExamples.tar myExamples
案例6:将myExamples/目录下的所有文件全部归档,并使用bzip2压缩成一个文件myExamples.tar.bz;
linux@ubuntu:~$ tar -cjf myExamples.tar.bz myExamples
案例7:将myExamples/目录下的所有文件全部归档,并使用gzip压缩成一个文件myExamples.tar.gz。
linux@ubuntu:~$ tar -czf myExamples.tar.gz myExamples
案例8: 前面的数据压缩
"$DATA" | gzip > "$BACKUP/$BATETIME/$BATETIME.gz"
6.7 清屏命令
- 清屏
clear #按住 cle 回车就行
&& 表示继续的操作
用gedit 加文件名称可以直接打开该文件的图形界面
- 以树状显示目录结构
yum install tree
例子
tree /home
6.8 管道命令
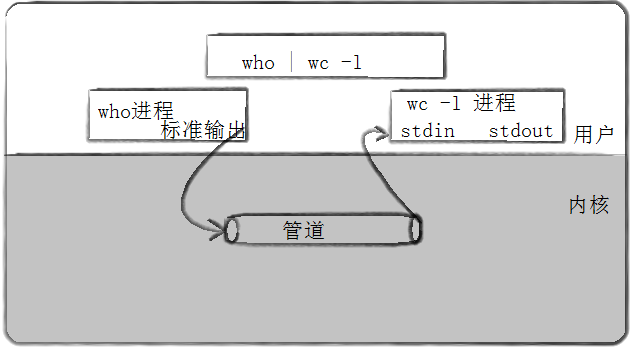
6.8.1 管道 | 指令
基本语法
指令1 | 指令2
作用: 把第一个命令的输出,作为第二个命令的输入。 需要第二个命令支持这种从管道获取输入的功能
8.8.2 Cut— 根据条件 从命令结果中 提取 对应内容
| 命令 | 含义 |
|---|---|
| cut 动作 文件 | 从指定文件截取内容 |
| 参数 | 英文 | 含义 |
|---|---|---|
| -c | characters | 按字符选取内容 |
| -d ‘分隔符’ | delimiter | 指定分隔符 |
| -f n1,n2 | fifields | 分割以后显示第几段内容, 使用 , 分割 |
| n | 只显示第 n 项 | |
| n- | 显示从第 n 项 一直到行尾 | |
| n-m | 显示从第n 项 到m 项(包括m) |
#截取出指定文件中 前2行 的 第5个字符
head -2 文件名 | cut -c 5
#截取出指定文件中前2行以”:”进行分割的第1,2段内容
head -2 文件名 | cut -d ':' -f 1,2,3
#截取出指定文件中前2行以”:”进行分割的第1,2,3段内容
head -2 文件名 | cut -d ':' -f 1-3
6.8.3 查询指定文件和 目录个数
1.统计/opt文件夹下文件的个数
ls -l /opt | grep "^-" | wc -l
2.统计/opt文件夹下目录的个数
ls -l /opt | grep "^d" | wc -l
3.统计/opt文件夹下文件的个数,包括子文件夹里的
ls -lR /opt | grep "^-" | wc -l
4.统计/opt文件夹下目录的个数,包括子文件夹里的
ls -lR /opt | grep "^d" | wc -l
七、linux的主管理和权限管理
7.1 Liunx组的基本介绍
- 在Linux中的每个用户必须属于一个组,不能独立于组外。
- 在Linux中每个文件都有所有者、所在组、其他组的概念
- 所有者
- 所在组
- 其它组
- 改变用户所在的组
7.2 文件/目录的 所有者
- 一般文件的创建者,谁创建了该文件,就自然成为该文件的所有者
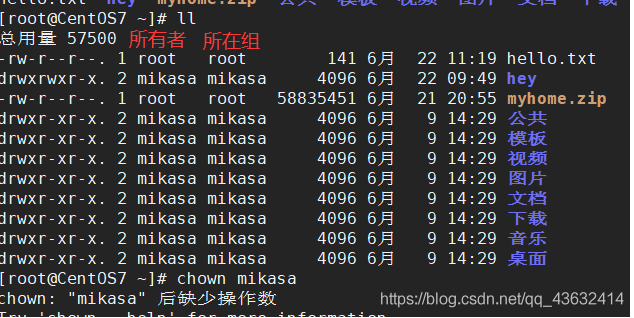
- 查看文件的所有者:
指令: ls -ahl
- 修改文件所有者 求
指令:
chown 用户名 文件名
7.3 文件/目录的 所在组
- 当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组
- 查看文件/目录所在组
ls -ahl
- 修改文件所在的组
chgrp 组名 文件名
7.4 其他组
除文件的所有者和所在组的用户外,系统的其他用户都是文件的其它组
7.5 改变用户所在组
- 在添加用户时,可以指定将该用户添加到哪个组中,同样的用root的管理权限可以改变某个用户所在的组
- 改变用户所在组
usermod -g 组名 用户名
usermod -d 目录名 用户名改变该用户登录的初始目录
7.6 权限的基本介绍
ll 显示的如下内容:
-rw-r--r--. 1 mikasa mikasa 141 6月 22 11:19 hello.txt
| 文件详情 |
|---|
 |
0-9位说明
- 1.第0位确定文件类型(d,-,l,c,b)
- d是目录,相当于windows的文件夹
- l是链接文件,相当于windows的快捷方式
- -是普通文件
- c是字符设备文件,鼠标,键盘
- b是块设备,比如硬盘
- 2.第1-3位确定所有者(该文件的所有者)拥有该文件的权限 --user
- 3.第4-6位确定所属组(同用户组的)拥有该文件的权限 --Group
- 4.第7-9位确定其他用户拥有该文件的权限 --Other
rwx权限详解,难点
- rwx作用到文件
- 【r】 代表可读(read): 可以读取、查看
- 【w】代表可写(write):可以修改,但是不代表可以删除该文件,删除一个文件的前提条件是对该文件所在的目录有些权限,才能删除该文件
- 【x】代表可执行(execute):可以被执行
- rwx作用到目录
- 【r】代表可读(read):可以读取,ls查看目录内容
- 【w】代表可写(write):可以修改,对目录内创建+删除+重命名目录名
- 【x】代表可执行(execute):可以进入该目录
7.7 文件及目录权限说明 实际案例
- ls -l 显示内容
-rwxrw-r-- 1 root root 1213 Feb 2 09:39 abc
- 10个字符确定不同用户能对文件干什么
- 第一个字符代表文件类型: -l d c b
- 其余字符每三个一组(rwx)读(r)写(w)执行(x)
- 第一组rwx:文件拥有者的权限是读、写但不能执行
- 第二组rw-:与文件拥有者同一组的用户的权限是读、写但不能执行
- 第三组r–:不与文件拥有者同组的其他用户的权限是都只能读
- 可用数字表示为:r=4,w=2,x=1 因此rwx=4+2+1=7
- 其他说明
- 1 若是文件:硬件连接 若是目录:子目录数+文件数
- root 用户
- root 组
- 1213 文件大小(字节),如果是文件夹显示4096字节
- Feb 2 09:39 最后修改日期
- abc 文件
7.8 修改文件和目录权限-chmod⚔️
通过chmod指令,可以修改文件或者目录的权限
- 第一种方式:+ 、- 、=变更权限
u:所有者 g:所有组 o:其他用户 a:所有人(u、g、o的总和)
(是指文件或者是目录的拥有者
1)给abc文件的所有者读写执行的权限,给所在组读执行权限, 给其他组读执行权限
chmod u=rwx,g=rx,0=x abc
2)给abc文件的所有者除去执行的权限,增加组写的权限
chmod u-x,g+w abc
3)给abc文件的所有用户添加读的权限
chmod a+r abc
- 第二种方式:通过数字变更权限
r=4 w=2 x=1 rwx=4+2+1
chmod u=rwx,g=rx,o=x 文件目录名
相当于chmod 751 文件目录
linux文件的用户权限的分析图
-rw-r--r-- 1 user staff 651 Oct 12 12:53 .gitmodules
# ↑╰┬╯╰┬╯╰┬╯
# ┆ ┆ ┆ ╰┈ 0 其他人
# ┆ ┆ ╰┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈ g 属组
# ┆ ╰┈┈┈┈ u 属组
# ╰┈┈ 第一个字母 `d` 代表目录,`-` 代表普通文件
例:rwx rw- r–
r=读取属性 //值=4
w=写入属性 //值=2
x=执行属性 //值=1
chmod u+x,g+w f01 # 为文件f01设置自己可以执行,组员可以写入的权限
chmod u=rwx,g=rw,o=r f01
chmod 764 f01
chmod a+x f01 # 对文件f01的u,g,o都设置可执行属性
文件的属主和属组属性设置
chown user:market f01 # 把文件f01给uesr,添加到market组
ll -d f1 查看目录f1的属性
例子
#将`/home/wwwroot/`里的所有文件和文件夹设置为`755`权限
#(1)直接指定路径修改(该路径下所有文件权限都改变)
chmod -R 755 /home/wwwroot/*
#(2)手动进入该目录修改权限(并显示详细过程)
cd /home/wwwroot
chmod -Rv 755 * #注意:“*”表示通配符,指的是所有文件和文件
sudo chmod o+rw /shared #设置文件夹权限以保证其余用户可以访问它。
#将目录`testDir`的其他组用户权限添加可执行权限,同时递归的将该目录下的所有文件或目录都添加可执行权限,可以使用如下命令:
chmod -R o+x testDir
#要求:将/home/abc.txt文件的权限修改成 rwxr-xr-x,使用数字的方式实现
chmod 755 /home/abc.txt
注意: 用户目录也是目录
7.9 修改文件和目录 所有者-chown⚔️
- 基本介绍
chown newowener 文件/目录 改变所有者
chown newonwner:newgroup 改变所有者和所在组
- -R 如果是目录则使其下所有子文件或目录递归生效(recursion)
文件 chown mikasa /home//hello.txt
目录 chown -R mikasa /home/qianxin
#将目录/usr/meng及其下面的所有文件、子目录的文件主改成 liu:
chown -R liu /usr/meng
7.10 修改文件和目录 所在组-chgrp⚔️
- 基本介绍
- -R 如果是目录则使其下所有子文件或目录递归生效(recursion)
文件 chgrp newgroup 文件 [改变所在组]
目录 chown -R 目录 [改变所在组]
例子
#将系统已存在文件oldFile的所属组设置为oldGroup;
chgrp oldGroup oldFile
#将系统已存在目录oldDir1的所属组设置为oldGroup;
chgrp oldGroup oldDir1
#将系统已存在目录oldDir2以及其所有子目录和子文件的所属组设置为oldGroup
chgrp -R oldGroup oldDir2
7.11 对文件夹(目录)的rwx的细节讨论
- x:表示可有进入到该目录,比如cd
- r:表示可以ls,将目录的内容显示
- w:表示可以在该目录删除或者创建文件
7.12 案例

用su进入到jack用户的,得切换到home目录,再切换到jack(自己的目录)就能创建文件了

八、crond任务调度(定时任务)
8.1 crontab 进行 定时任务的设置
- 概述
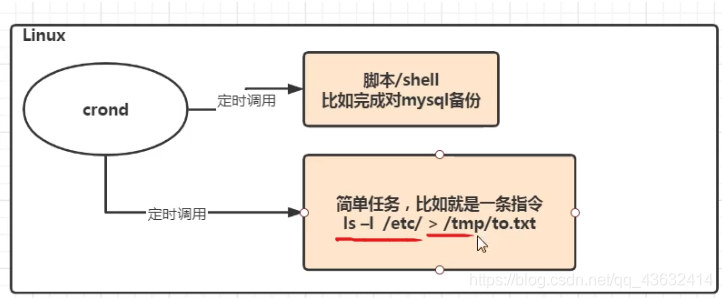
- 任务调度:是指系统在某个时间执行的特定的命令或程序。
- 任务调度分类.
- 系统工作:有些重要的工作必须周而复始地执行。如病毒扫描等
- 个别用户工作:个别用户可能希望执行某些程序,比如对mysql数据库的备份
- 基本语法
crontab [选项]
常用选项有:
-e 编辑crontab定时任务
-l 查询crontab任务
-r 删除当前用户所有的crontab任务
语法:
// 通过 crontab -e 进入
*/每隔多久执行一次(可选) 分钟 小时 月 年 星期 脚本位置
默认 * 代表 每(全部)
, 代表不连续的时间。比如“* * * * 1,6 代表在周一和周六执行
- 代表连续的时间范围。比如”* * * * 1-6 代表在周一到周六执行
-
快速入门
-
设置任务调度文件:/etc/crontab
-
设置个人任务调度。执行crontab -e命令
-
接着输入任务到调度文件
-
如:
*/1 * * * * ls -l /etc/ > /tmp/to.txt 意思说每个小时的每分钟执行 ls -l /etc/ > /tmp/to.txt 命令 -
参数细节说明
-
5个占位符的说明
-
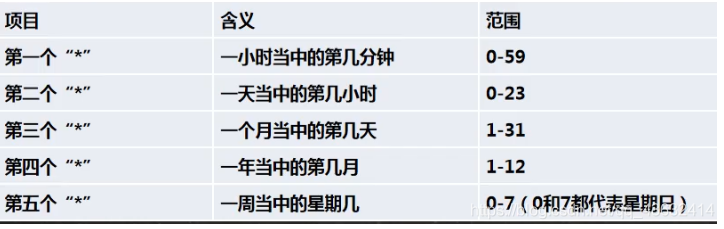
-
特殊符号说明
特殊符号 含义 * 代表任何时间。比如第一个 “ * ” 就代表一小时中每分钟都执行一次的意识 ‘ 代表不连续的时间。比如“0 8,12,16 *** 命令,就代表在每天的8点0分,12点0分,16点0分都执行一次命令 - 代表连续的时间范围。比如”0 5 * * 1-6 命令“,代表在周一到周六的凌晨5点0分执行命令 */n 代表每隔多久执行一次。比如 ” */10 * * * * 命令" ,代表每隔10分钟就执行一遍命令 -
特定时间执行任务案例
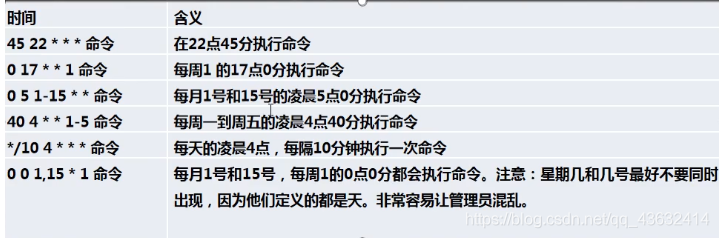
应用实列:
案例1:每隔1分钟,就将当前的日期信息,追加到/tmp/mydate文件中
crontab -e
*/1 * * * * data >> /tmp/mydata
案例2:每隔2分钟,将当前日期和日历都追加到/home/mycal文件中
第一步 编辑一个脚本文件
vim /home/my.sh
date >> /home/mycal
cal >> /home/mycal
给my.sh增加执行权限
使用执行:
./my.sh
cat mycal
第二步:
crontab -e
*/1 * * * * /home/my.sh //满一分钟就调用 my.sh
案列3:每天凌晨2:00将mysql数据库testdb,备份到文件中,提示:
指令为mysqldump -u root -p密码 数据库 >> /home/bd.bak
第一步:crontab -e
第二步:0 2 * * * mysqldump -u root -proot testdb > /home/db.bak
8.2 at定时任务
-
基本介绍
- at命令是一次性定时计划任务,at的守护进程atd会以后台模式运行,检查作业队列来运行
- 默认情况下,atd守护进程每60秒检查作业队列,有作业时,会检查作业运行时间,如果时间与当前时间匹配,则运行此作业
- at命令是一次性定时任务计划,执行完一个任务后不再执行此任务了
- 在使用at命令的时候,一定要保证atd进程的启动,可以使用相关指令来查看
ps -ef | grep xx -
at命令格式
at [选项] [时间] ctrl + D 结束at命令输入(两次)
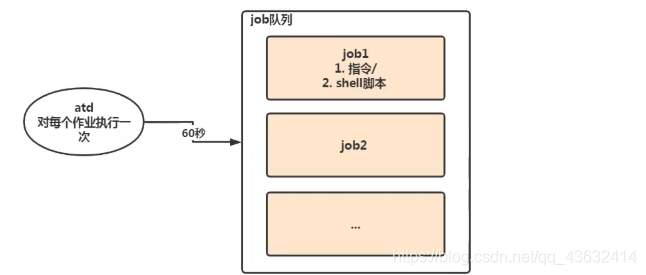
- at命令选项

atq 查看任务
- at时间定义的方法

- 相关方法
- atq命令,来查看系统中没有执行的工作任务
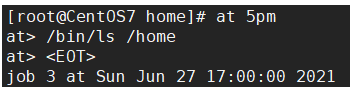
- atrm 编号 删除已经设置的任务
- 案列
- 2天后的下午5点 执行/bin/ls /home
-
- 明天17点钟,输出时间到指定文件内 比如/root/date100.log

九、Linux磁盘分区、挂载
9.1 Linux分区
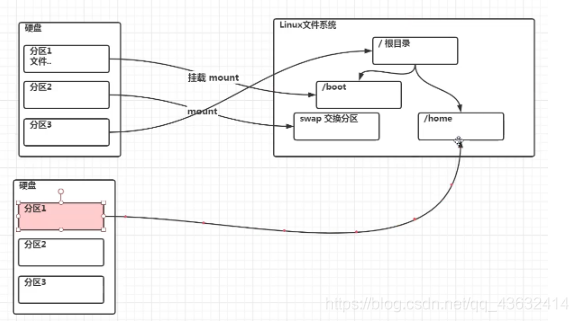
- 原理介绍
-
- Linux来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构,Linux中每个分区都是用来组成整个文件系统的一部分
- **Linux采用了一种叫”载入“的处理方法,**它的整个文件系统包含了一整套的目录,且将一个分区和一个目录联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得
-
-
硬盘shuo’ming
- Linux硬盘分IDE硬盘和SCSI硬盘,目前基本上是SCSI硬盘
- 对于IDE硬盘,驱动驱动标识符为” hdx~ “,其中”hd“表明分区所在的设备类型,这里是指IDE硬盘了。”x“为盘号(a为基本盘,b为基本从属盘,c为辅助主盘,d为辅助从属盘),”~“代表分区,前四个分区用数字1到4表示,他们是主分区和拓展分区;从5开始就是逻辑分区。例,hda3表示为第一个IDE硬盘上的第三个主分区或拓展分区,hdb2表示为第二个IDE硬盘上的第二个主分区或拓展分区
- 对于SCSI硬盘则标识为”sdx~“,**SCSI硬盘是用”sd“来表示分区所在设备的类型的,**其余则和IDE硬盘的标识方式一样
-
查看所有的设备挂载情况
命令:lsblk 或者 lsblk -f
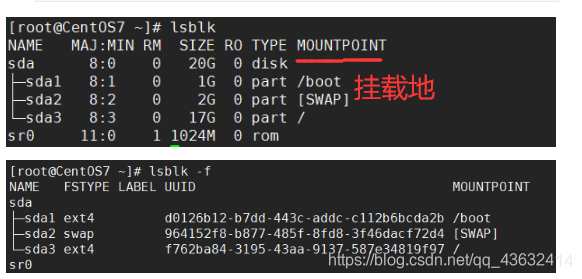
- 针对第二张图
- sda下指得是分区情况
- FSTYPE 指的是文件类型
- UUID值得是分区得唯一标识符(40个位)
- MOUNTPOIN 挂载点
- sda下指得是分区情况
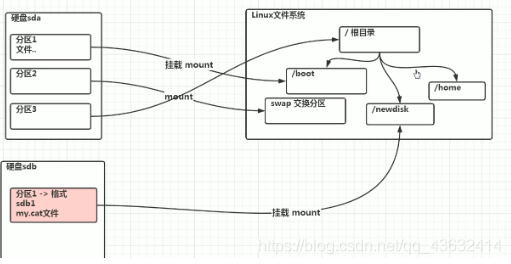
9.2 挂载的经典案例
以增加一块硬盘为例来熟悉磁盘的相关指令和深入理解磁盘分区、挂载、卸载的概念。
如何为linux系统增加一块硬盘?
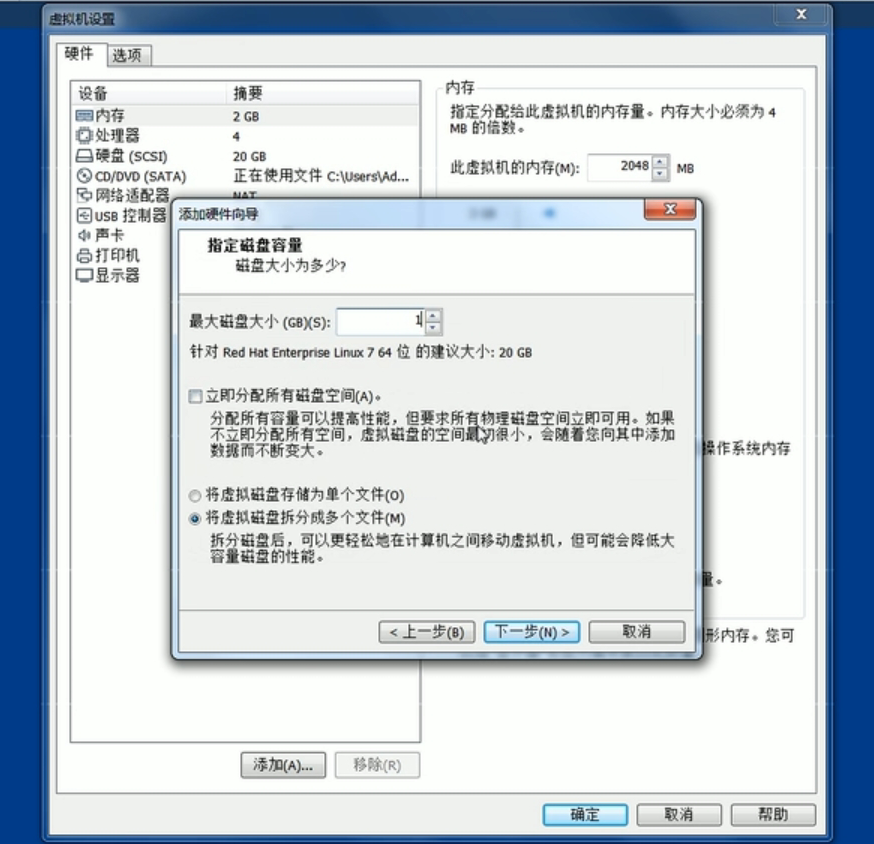
-
1.虚拟机添加硬盘
- 在vmware上实现
- 重启虚拟机
- 重启后的分区情况[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

-
2.分区
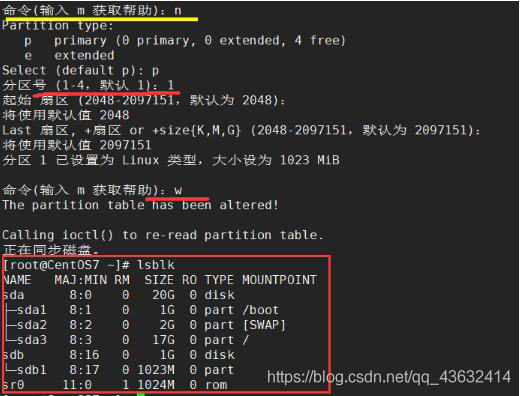
-
分区命令
fdisk /dev/sdb -
(dev(device)这个目录中包含了所有Linux系统中使用的外部设备。但是不是存放外部设备的驱动程序。它实际上是一个访问这些外部设备的端口就。我们可以非常方便的去访问这些外部设备,和访问一个文件,一个目录没有任何区别)
-
sdb就是再dev下面的
-
开始对 /sdb分区
m 显示命令列表 p 显示磁盘分区 同 fdisk -l n 新增分区 d 删除分区 w 写入并退出 说明:开始分区后输入n,新增分区,然后选者p,分区类型为主分区。两次回车默认剩余全部空间。最后输入w写入分区并退出,若不保存退出输入q -
-
3.格式化
- 格式化磁盘 // 格式化指定文件类型 之后才能用
- 分区命令:
mkfs -f ext4 /dev/sdb1 // vext4是分区类型
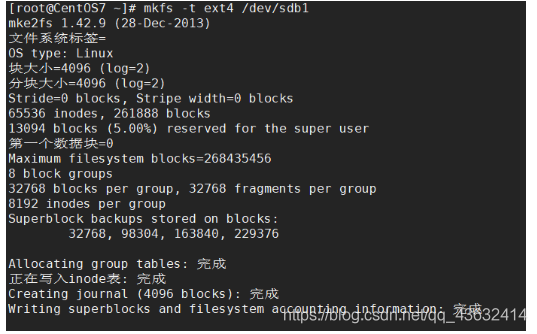
-
4.挂载(将一个分区与一个目录联系起来)
挂载令: mount 设备名称 挂载目录 卸载命令: umout 设备名称(或者已挂载的目录)

注意: 用命令行挂载,重启后就会失效
-
5.设置可以自动挂载
- 永久挂载:通过修改/etc/fstab实现挂载
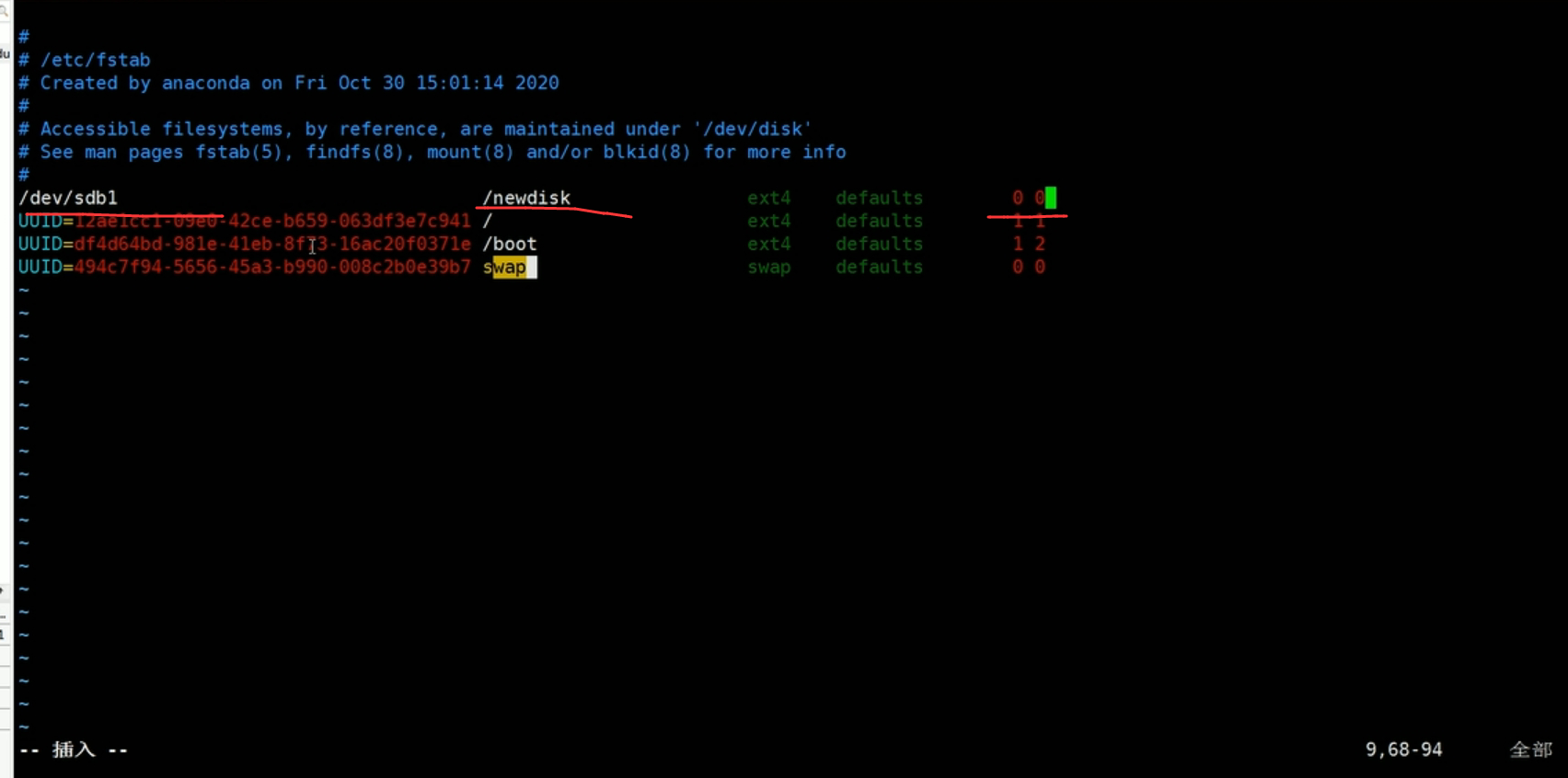
- 添加完成后,执行mount -a立即生效
9.3 磁盘情况查询
-
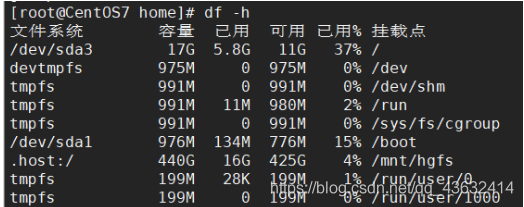
- 查看系统整体磁盘 使用情况
- 基本语法
df -h -
应用实例:查询系统整体磁盘使用情况(使用率到了80以上就不正常了)
-
- 查询指定目录 的磁盘占用情况
- 基本语法
du -h 目录名 -
查询指定目录的磁盘占用情况,默认为当前目录
- 选项
-s 指定目录占用大小汇总
-h 带计量单位
-a 含文件
-c 列出明细的同时,增加汇总值
--max-depth=1 子目录深度
- 案例:查询opt目录的磁盘占用情况,深度为1

十、LInux网络配置
10.1 Linux网络配置
详情可以看开发板中的笔记

主机和虚拟机ping配置
电脑
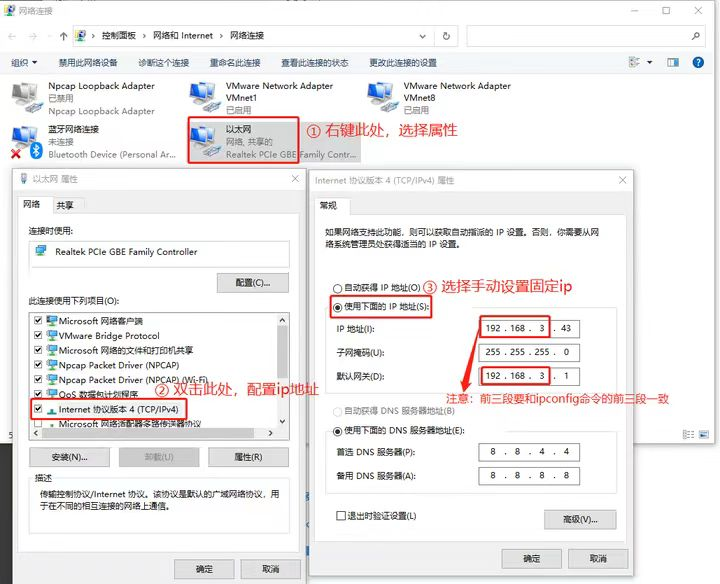
虚拟机
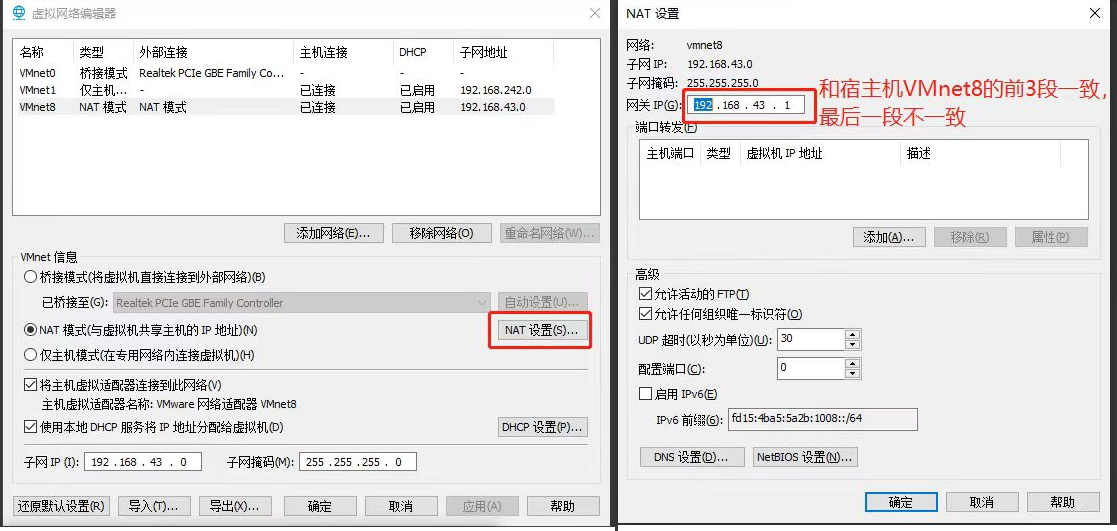
10.2 配置一个指定的ip(不然每次都会变)
- 直接修改配置文件来制定IP,并可以连接到外网(cxy推荐)
- 编辑 vim /etc /sysconfig/network-scripts/ifcfg-ens33
- 修改前
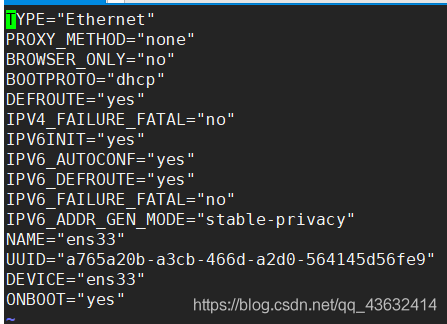
- 要求:将IP地址配置为静态的,比如ip地址为192.168.200.130
- 修改后
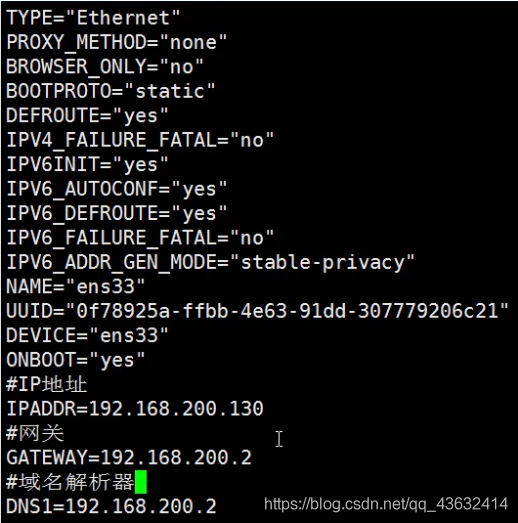
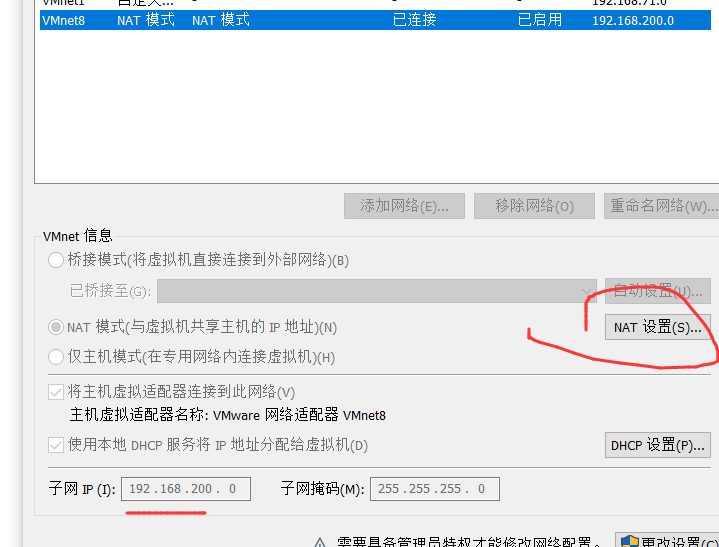
- ifcfg-ens33文件说明

-
-
重启网络服务或者重启兄系统生效
service network restart reboot -
ping指令
ping ip(或域名) (测试连通性)
ping www.baidu.com
10.3 设置主机名和hosts映射 (配置别名)
-
设置hosts映射
- windows
C:\windows\System32\drivers\etc\hosts 文件指定即可- liunx
在/etc/hosts 文件 指定 -
主机名解析过程分析(hosts、DNS)
- hosts文件是什么:一个文本文件,用来记录IP和hostname(主机名)的映射关系
- DNS(Domain Name System,域名系统):是互联网上作为域名和IP地址相互映射的一个分布式数据库
-
主机名解析机制分析
应用实例:用户在浏览器输输入了www.baidu.com-
1.浏览器先检查浏览器缓存中有没有该域名解析ip地址,有就先调用这个IP完成解析;如果没有,就检查DNS解析器缓存,如果有就直接返回ip完成解析。(这两个缓存可以理解为本地解析器缓存)
(一般来说,当电脑第一次成功访问某一网站后,在一定的时间内,浏览器或者操作系统会缓存它的ip地址DNS解析记录,如在命令行输入
ipconfig /displaydns //DNS缓存解析 ipconifg /flushdns //手动清理dns缓存 -
2.如果本地解析器缓存没有找到对应的映射,则检查系统系统中的hosts文件中有没有配置对应的域名ip映射。如果有,则完成解析并返回
-
3.如果本地DNS解析器缓存和hosts文件中均没有找到对应的ip,则到域名服务DNS进行解析
-
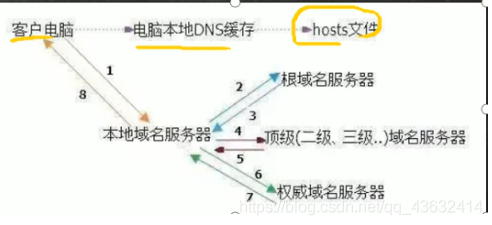
-
10.4 网络请求
十一、进程管理(ps)
11.1 基本知识
- 在Linux中,每一个执行的程序都被称为一个进程。每一个进程都被分配一个ID号(pid,进程号)
- windows下的pid

- linux:top指令 可以看动态监控那章
- 每个进程都可能以两种方式存在。前台与后台,所谓前台进程就是用户目前屏幕上可以进行操作的。后台进程则是实际在操作,但由于屏幕上无法看到的进程,通常使用后台方式执行。
- 一般系统的服务都是以后台进程的方式存在,而且都会常驻在系统中。直到关机才会结束
11.2 显示系统执行的进程
- ps 命令是用来查看目前系统中,有哪些正在执行的进程 ,以及他们的执行状况。可以不加任何参数
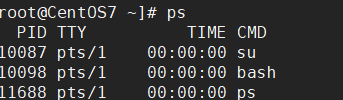
ps显示的信息选项
| 字段 | 说明 |
|---|---|
| PID | 进程识别号 |
| TTY | 终端机号 |
| TIME | 此进程所消耗CPU时间 |
| CMD | 正在执行的命令或进程名 |
ps -a:显示当前终端的所有进程信息
ps -u:以用户的格式显示进程信息
ps -x:显示后台进程运行的参数
执行ps -aux
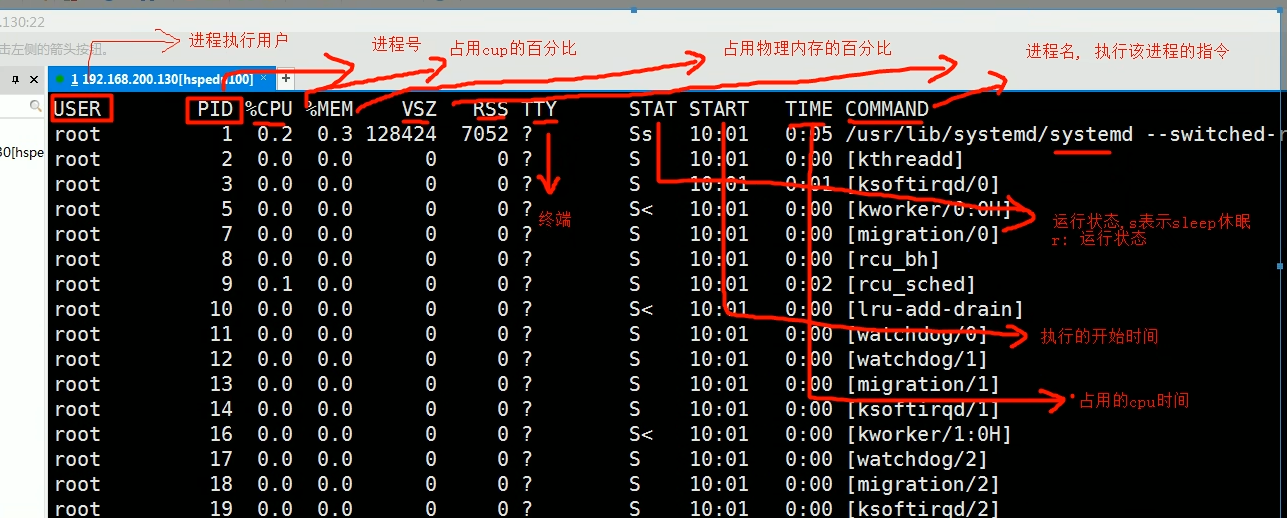
-
参数解释
- USER:进程执行用户
- PID:进程号
- %CPU:当前进程占用cpu的百分比
- %MEM:占用物理内存的百分比
- VSZ:进程占用虚拟内存大小(KB)
- RSS:进程占用的物理内存的大小(KB)
- TTY:终端名称
- STAT:运行状态,S-表示sleep休眠、s-表示该进程是会话的先导进程,N-表示进程拥有比普通优先级更低的优先级,R-表示正在运行,D-短期等待,z-僵尸进程,T-被跟踪或者被停止等等
- STARTED:执行的开始时间
- TIME:占用CPU时间
- COMMAND:启动进程所用的命令和参数,如果过长会被截断显示
参数详细说明
| 表头 | 含义 |
|---|---|
| F | 进程标志,说明进程的权限,常见的标志有两个: · 1:进程可以被复制,但是不能被执行; · 4:进程使用超级用户权限; |
| S | 进程状态。进程状态。常见的状态有以下几种: 1. -D:不可被唤醒的睡眠状态,通常用于 I/O 情况。 2. -R:该进程正在运行。 3. -S:该进程处于睡眠状态,可被唤醒。 4. -T:停止状态,可能是在后台暂停或进程处于除错状态。 5. -W:内存交互状态(从 2.6 内核开始无效)。 6. -X:死掉的进程(应该不会出现)。 7. -Z:僵尸进程。进程已经中止,但是部分程序还在内存当中。 8. -<:高优先级(以下状态在 BSD 格式中出现)。 9. -N:低优先级。 10. -L:被锁入内存。 11. -s:包含子进程。 12. -l:多线程(小写 L)。 13. -+:位于后台。 |
| UID | 运行此进程的用户的 ID; |
| PID | 进程的 ID; |
| PPID | 父进程的 ID; |
| C | 该进程的 CPU 使用率,单位是百分比; |
| PRI | 进程的优先级,数值越小,该进程的优先级越高,越早被 CPU 执行; |
| NI | 进程的优先级,数值越小,该进程越早被执行; |
| ADDR | 该进程在内存的哪个位置; |
| SZ | 该进程占用多大内存; |
| WCHAN | 该进程是否运行。"-"代表正在运行; |
| TTY | 该进程由哪个终端产生; |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间; |
| CMD | 产生此进程的命令名; |
ps -elf | grep xxx 是以全格式显示xxx的进程,查看进程
-e 显示所有的进程
-f 全格式
BSD风格:
ps -ef|grep xxx
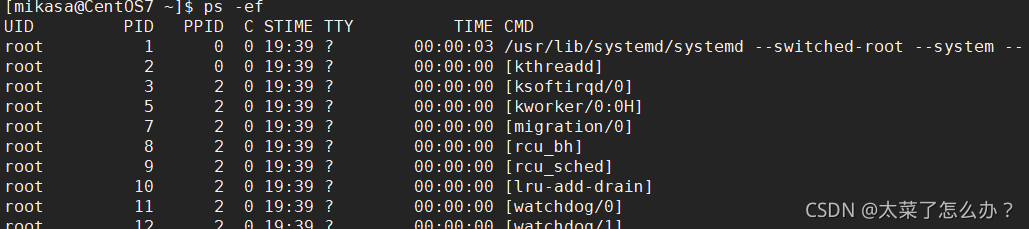
-
UID:用户ID
-
PID:进程ID
-
PPID:父进程ID
-
C:cpu用于计算执行优先的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值越小,表明进程是I/O密集型运算,执行优先级会提高
-
STIME:进程启动时间
-
TTY:完整的终端名称
-
TIME:CPU占用时间
-
CMD启动进程所用的命令和参数
-
ps -ef|grep sshd

sshd进程是1号进程的子进程,9579有是7756的子进程
11.3 终止进程kill 和 killall
- 若是某一个进程执行一半需要停止时,或是已消了很大的系统资源时,此时可以考虑停止该进程。使用kill命令来完成此项任务
- 基本语法
kill -9 进程号 功能描述:通过进程号杀死进程
killall 进程名称 功能描述:通过进程名杀死进程也支持通配符,这在系统因负载过的很慢时很有用
- 常用选项:-9 表示强迫进程立即停止
案例:
- 踢掉某个非法登录用户(mikasa)

ps- ef|grep sshd后可知用户mikasa登录的进程号为9583
kill 进程号
kill 9583
用户mikasa的连接关闭

- 终止远程登录服务sshd,在适当时候再次重启sshd服务
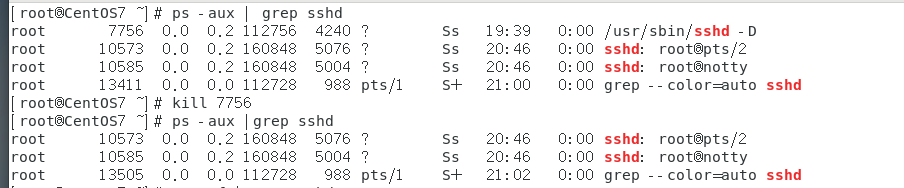
kill 7756
结束远程登录服务sshd后用户无法通过xshell连上Linux虚拟机
启动sshd服务
/bin/systemctl start sshd.service
- 终止多个gedit
killall gedit
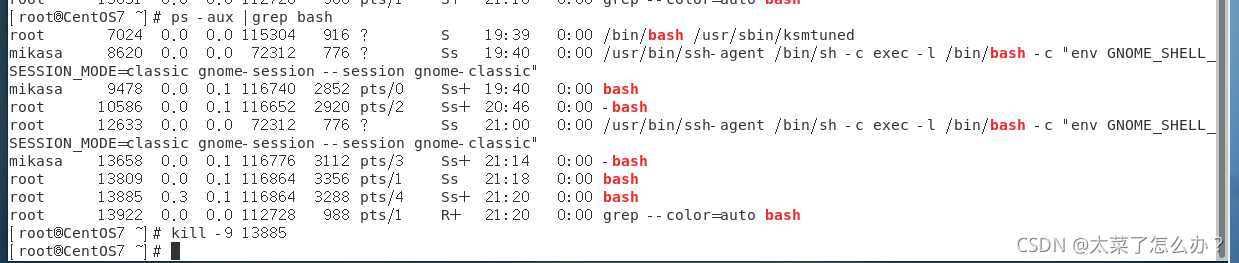
- 强制杀掉一个终端
ps -aux | grep bash 找出终端的进程号
killall -9 bash对应的进程号
11.4 查看进程树 pstree
- 基本语法
pstree [选项] 可以更加直观的来看进程信息
- 常用选项
-p 树状形式显示进程的pid
-u 树状形式显示进程的所属用户
11.5 后台/前台任务
11.5.1 jobs命令
jobs命令 用于显示Linux中的任务列表及任务状态,包括后台运行的任务。该命令可以显示任务号及其对应的进程号。其中,任务号是以普通用户的角度进行的,而进程号则是从系统管理员的角度来看的。一个任务可以对应于一个或者多个进程号。
在Linux系统中执行某些操作时候,有时需要将当前任务暂停调至后台,或有时须将后台暂停的任务重启开启并调至前台,这一序列的操作将会使用到 jobs、bg、和 fg 三个命令以及两个快捷键来完成。
语法
jobs(选项)(参数)
选项
-l:显示进程号;
-p:仅任务对应的显示进程号;
-n:显示任务状态的变化;
-r:仅输出运行状态(running)的任务;
-s:仅输出停止状态(stoped)的任务。
参数
任务标识号:指定要显示的任务识别号。
实例
使用jobs命令显示当前系统的任务列表,输入如下命令:
jobs -l #显示当前系统的任务列表
上面的命令执行后,将显示出当前系统下的任务列表信息,具体如下所示:
[1] + 1903 运行中 find / -name password &
注意:要得到以上输出信息,必须在执行jobs命令之前执行命令find / -name password &。否则,执行jobs命令不会显示任何信息。
其中,输出信息的第一列表示任务编号,第二列表示任务所对应的进程号,第三列表示任务的运行状态,第四列表示启动任务的命令。
11.5.2 bg命令
bg命令 用于将作业放到后台运行,使前台可以执行其他任务。该命令的运行效果与在指令后面添加符号&的效果是相同的,都是将其放到系统后台执行。
在Linux系统中执行某些操作时候,有时需要将当前任务暂停调至后台,或有时须将后台暂停的任务重启开启并调至前台,这一序列的操作将会使用到 jobs、bg、和 fg 三个命令以及两个快捷键来完成。
语法
bg(参数)
参数
作业标识:指定需要放到后台的作业标识号。
实例
使用bg命令将任务号为1的任务放到后台继续执行,输入如下命令:
bg 1 #后台执行任务号为1的任务
如果系统中只有一个挂起的任务时,即使不为该命令设置参数“1”,也可以实现这个功能。
注意:实际上,使用bg命令与在指令后面添加符号“&”的效果是一样的。例如,使用&将find / -name password放到后台执行,输入如下命令:
find / -name password & #后台执行任务
例子: 把作业放到后台运行
1.运行top 和 sleep 1000,然后执行"Ctrl + z"放到后台“暂停”
lfj@lfj-virtual-machine:~$ top
^Z
[1]+ Stopped top
lfj@lfj-virtual-machine:~$ sleep 1000
^Z
[1]+ Stopped sleep 1000
2.让作业在后台运行,以便观察
lfj@lfj-virtual-machine:~$ jobs
[1]- Stopped top
[2]+ Stopped sleep 10000
lfj@lfj-virtual-machine:~$ bg 2
[2]+ sleep 10000 &
lfj@lfj-virtual-machine:~$ jobs
[1]+ Stopped top
[2]- Running sleep 10000 &
lfj@lfj-virtual-machine:~$
作业由"Stopped"变为"Running",命令行的最后多了一个&符号,表明作业在后台启动运行。
11.5.3 fg命令
fg命令 用于将后台作业(在后台运行的或者在后台挂起的作业)放到前台终端运行。与bg命令一样,若后台任务中只有一个,则使用该命令时,可以省略任务号。
在Linux系统中执行某些操作时候,有时需要将当前任务暂停调至后台,或有时须将后台暂停的任务重启开启并调至前台,这一序列的操作将会使用到 jobs、bg、和 fg 三个命令以及两个快捷键来完成。
语法
fg(参数)
参数
作业标识:指定要放到前台的作业标识号。
实例
使用fg命令将任务号为1的任务从后台执行转换到前台执行,输入如下命令:
fg 1 #将任务转换到前台执行
执行上面的命令后,命令行窗口将显示如下信息:
find / -name password #前台执行命令
十二、服务(service)管理
**服务(service)本质就是进程,但是时运行在后台的,通常都会监听某个端口,等待其他程序的请求,**比如(mysqld,sshd 防火墙等),因此称为守护进程,是Linux中非常重要的知识点
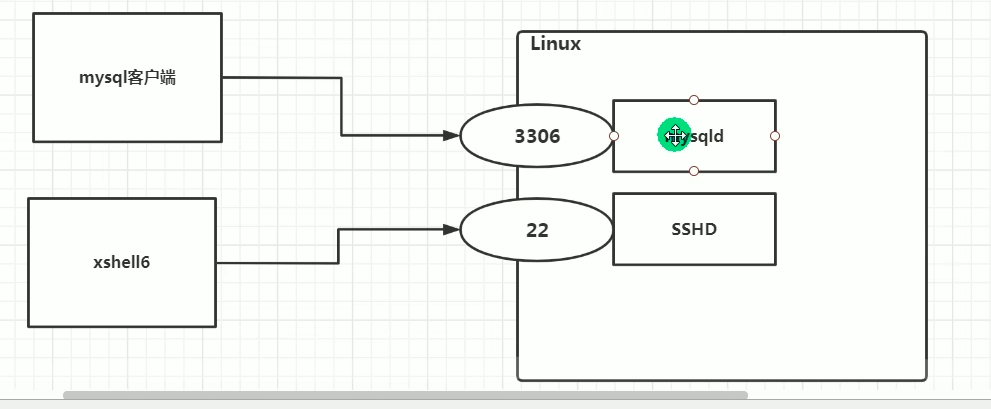
12.1 service命令
-
service管理指令
service 服务名 [start| stop| restart| reload | status] -
在CentOS7.0后很多服务不再使用service,而是systemctl
-
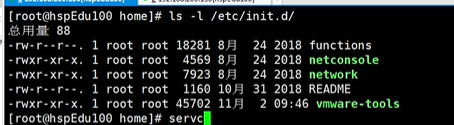
service指令管理的服务在 /etc/init.d查看
-
-
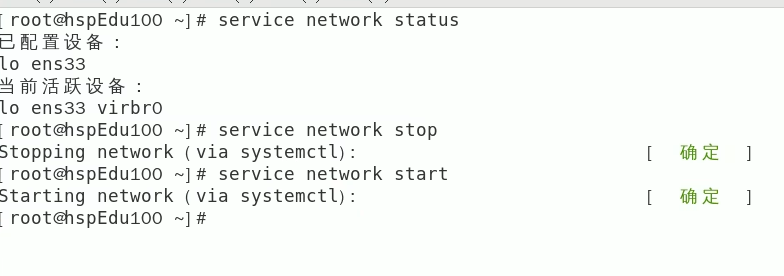
案例
使用servce指令,查看,关闭,启动network 不要在xshell中执行,关闭网络后,连接sshd服务会断开连接)
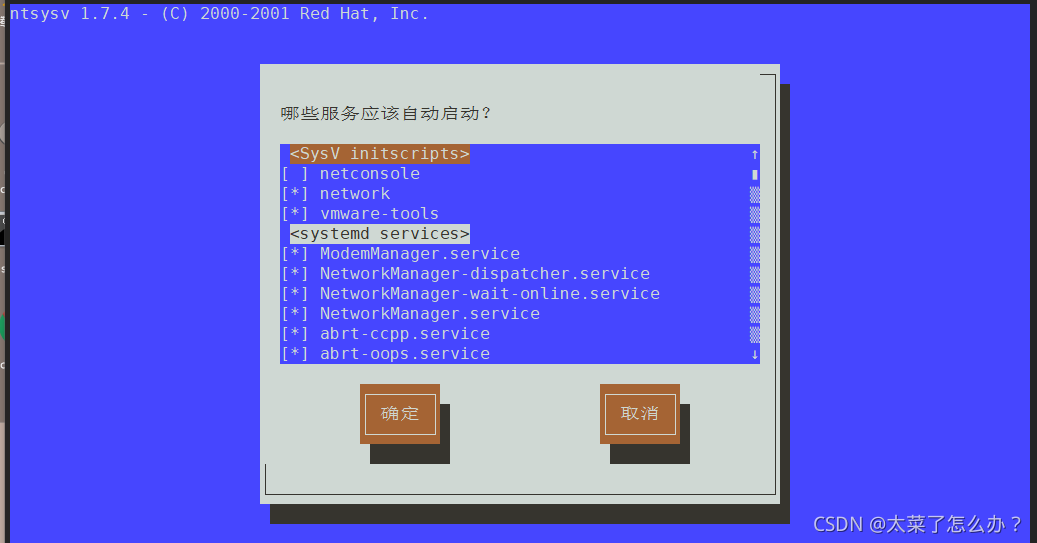
- 查看 服务名:
- 方式1:使用setup——>系统服务,就可以看到全部
- 带*号的服务 是随着linux的启动 自动启动,没有带 *号的都是需要手动启动的
- 退出按Tab
- 方式1:使用setup——>系统服务,就可以看到全部
- 方式2:/etc/init.d 看到service指令管理的服务ls -l /etc/init.d
- 扩展:linux很多服务以d结尾的原因:
- d代表deamon 守护进程
- Linux的大多数服务就是用守护进程
- 守护进程是运行在Linux服务器后台的一种服务程序
- 它周期地执行某种任务或等待处理某些发生的事件
- 比如:xinetd提供网络服务,sshd提供ssh登录服务,httpd提供web服务
12.2 服务的运行级别
-
linux系统有七种运行级别(runlevel):
常用的是级别3和5
- 运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
- 运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登录
- 运行级别2:多用户状态(没有NFS),不支持网络
- 运行级别3:完全的多用户状态(有NFS),登录后进入控制台命令行模式
- 运行级别4:系统未使用,保留
- 运行级别5:X11控制台,登陆后进入图形GUI模式
- 运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
-
开机的流程说明

-
CentOS7运行级别说明
- 在/etc/initab,进行了简化如下
multi-user.target:analogous to runlevel 3 graphical.target:analogous to runlevel 5-
#to view current default target,run: systemctl get-default -
#To set a default target,run: systemctl set-default TARGET.target
12.3 chkconfig指令(在各个运行级别中)
- 作用:
- 1.通过chkconfig命令可以给服务在各个运行级别中的 启动/关闭
- 2.chkconfig指令管理的服务在 /etc/init.d查看
- 注意:CentOS7.0后,很多服务使用systemctl管理
- 基本语法:
chkconfig --list | grep xxx 查看某个服务
// chkconfig 服务名 --list 查看服务
chkconfig --level 5 服务名 on/off 对服务在各等级下的状态进行控制

- 案列
对network服务进行操作,把network在3运行级别关闭自启动
chkconfig --level 3 network off
- 注意:chkconfig重新设置服务后自启动或关闭,需要重启机器reboot生效
12.4 systemctl命令(推荐)
CentOS7.0后很多服务不再使用service,而是systemctl
-
systemctl管理命令
# 针对服务的启动,停止,重启,开机自动启动,禁止开机自动启动,查看服务状态。 systemctl start|stop|restart|enable|disable|status 服务名称-
使用 ls -l /usr/lib/systemd/system | grep xxx 中查看systemctr服务
-
比如看防火墙的:

-
-
systemctl设置服务的自启动状态
systemctl list-unit-files | grep 服务名 (查看服务开机启动状态) systemctl enable 服务名 (设置服务开机启动) // 永久设置 systemctl disable 服务名 (关闭服务开机启动)关闭和开启都是默认的3和5两级别 // 永久设置 systemctl is-enabled 服务名 (查询某个服务是否是自启动的) -
案列:
ll /usr/lib/systemd/system |grep fire 查找防火墙服务 systemctl list-unit-files | grep firewalld 查看当防火墙的服务状态 systemctl is-enabled firewalld 查看防火墙服务是否是自启的 查看当前防火墙的状态,关闭防火墙和重启防火墙 systemctl status firewalld 停止防火墙 systemctl stop firewalld 启动防火墙 systemctl s

-
细节点
- 关闭或者启动防火墙后,立即生效。[telnet测试 某个端口即可]
- 这种方式只是临时生效,当重启系统后,还是回归以前对服务的设置
- 如果设置某个服务自启动或关闭永久生效,要使用systemctl [enable|disable]服务名
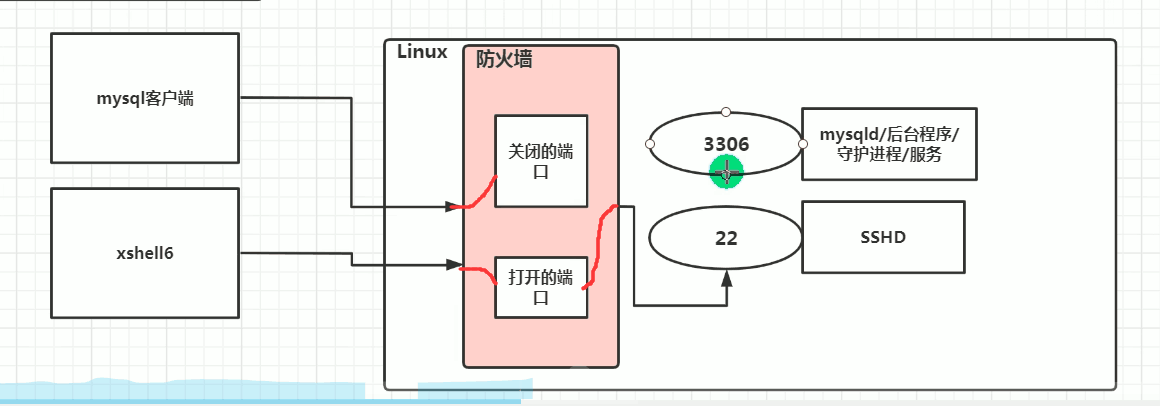
12.5 打开或者关闭指定端口
在真正的生产环境,往往需要将防火墙打开,但是如果我们把防火墙打开,那么外部请求数据包就不能给服务器监听端口通讯。这时,需要打开指定的端口。比如80,22,8080
-
firewall指令
注意: 端口号/协议 通过 netstat -anp | more
- 打开端口
firewall-cmd --permanent --add-port=端口号/协议 // permanent n.永久- 关闭端口
firewall-cmd --permanent --remove-port =端口号/协议- 无论是关闭还是开启端口都需要重新载入防火墙才能生效
firewall-cmd --reload- 查看端口是否开放
firewall-cmd --query-port=端口/协议 -
案例
- 启用防火墙,测试111端口是否能telnet
- 开放111端口

- 再次关闭111端口

12.6 访问地址
类似浏览器访问路径,无法图形化显示,一般用于测试
curl 访问地址
12.7 端口号查看
如发现端口号被占用,可以使用如下方式查找pid,并结束进程
# 想使用指定的命令需要事先下载netstat
yum -y install net-tools
# 查看端口号占用情况
netstat -naop | grep 端口号
十三、动态监控(top)
13.1 动态监控进程的基本语法
top和ps命令很相似。他们都用来显示正在执行的进程Top和ps最大的不同处在于top在执行一段时间可以更行正在运行的进程
基本语法
top [选项]
选项说明
| 选项 | 功能 | 实例 |
|---|---|---|
| -d 秒数 | 指定top命令每隔几秒更新。默认是3秒 | top -d 5 |
| -i | 是top不显示任何闲置或者僵死进程 | |
| -p | 通过指定监控进程ID来仅仅监控某个进程的状态 |
注意:
shift +> 后翻页 shift +< 前翻页
top -p PID 查看某个进程

- 僵死进程:进程已经死掉了(进程运行结束),但是内存没有被释放掉。僵死进程需要定时清除!!
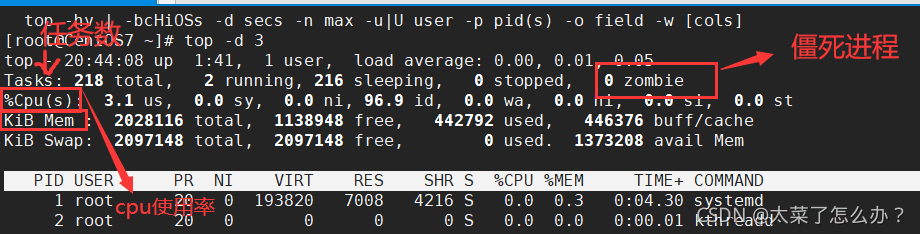
- 其中cpu使用率和KiB Mem(内存管理)最为重要
13.2 动态监控进程的交互操作
- 交互操作说明
| 操作 | 功能 |
|---|---|
| P | 以CPU施一公率排序,默认就是此项 |
| M | 以内存使用率排序 |
| u | 输入用户名 |
| N | 以PID排序 |
| q | 退出top |
-
实例
案例1.监视特定用户,比如说监控mikasa用户 top:输入此命令,按回车键,查看执行的进程 然后输入“u”,回车,在输入用户名,即可 案例2:终止指令的进程 先输入top指令后,在输入“k“ ,在输入想要终止的进程号 案例3:指定系统状态更新的时间(每隔10秒自动更新)(默认的是3秒) top -d 10
13.3 监控网络状态
-
查看系统网络情况netstat
- 基本语法
netstat [-anp]- 选项说明
-an 按一定顺序排列输出 -p 显示所在进程
例子:
使用 netstat -an :


增加一个tom用户

-
检测主机连接命令ping
- 是一种网络检测工具,它主要是用来检测远程主机是否正常,或是两部主机间的网线或网卡故障
十四、RPM与YUM
14.1 rpm包的管理
-
介绍
- rpm用于互联网下载包的打包及安装工具,它包含在某些LInux分发版中。它生成具有.RPM拓展名的文件。RPM是RedHat Package Manager (RedHat软件包管理工具)的缩写,类似windows的setup.ext,这一文件格式名称虽然打上了RedHat的标志,但理念是通用的。
- Linux的分发版都有采用(suse,redhat,centos等),可以说是公用的行业标准。
-
rpm包的简单查询指令
- rpm -qa 查询所安装的所rpm包软件包
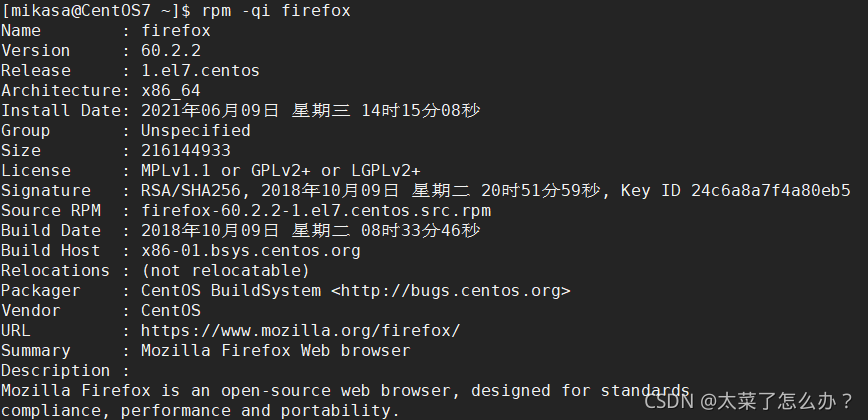
rpm -qa | more rpm -qa | grep xxx(如:rpm -qa | grep firefox) 查看当前系统是否安装firefoxrpm -qa | grep firefox
- rpm包名基本格式
一个rpm包名:firefox-60.2.2-1.el7.centos.x86_64 名称:firefox 版本号:60.2.2-1 适用操作系统:el7.centos.x86_64 表示centos7.x的64位系统 (如果似乎i686、i386表示32位系统,noarch表示通用) -
rpm包的其它查询指令
- rpm -q 软件包名 查询软件包信息
rpm -q firefox- rpm -qi 软件包名 查询软件包信息
rpm -qi firefox
- rpm -ql 软件包名 查询软件包中的文件

-
- rpm -qf 文件全路径名 查询文件所属的软件包
rpm -af /etd/shadow

-
安装rpm包
- 基本语法
rpm -ivh RPM包全路径名称 rpm -ivh /opt/firefox (tab补全再回车)- 参数说明
i=install 安装 v=verbose 提示 h=hash 进度条 -
卸载rpm包
- 基本语法
rpm -e RPM包的名称 //erass rpm -e firefox 删除firefox 软件包-
注意
- 如果其它软件包依赖于要卸载的软件包,卸载时则会产生错误的信息
- 如果必须要删除这个软件包,可以增加参数 --nodeps,就可以强制删除,但是一般不推荐这么做,因为依赖于该软件包的程序可能无法运行
rpm -e --nodeps 软件包名
14.2 yum
-
介绍:Yum是一个Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并安装. 相当于应用商店,可以自动处理依赖关系,并且一次安装所有依赖的软件包
-
yum的基本指令
查询yum服务器是否有需要安装的软件(软件列表) yum list|grep xx 安装指定的yum包(下载安装) yum install xxx -
实列:使用yum的方式安装firefox
rpm -e firefox 先卸载centos中的firefox yum list | grep firefox 查询firefox的软件 yum install firefox 下载!
注意: opt是放软件包的
14.3 配置软件源
百度(选择网速快的服务器)
十五、 linux g++
文件其实就是普通的纯文本文件。 在文本和可执行程序之间,g++做所谓的编译。
g++就是将包含了代码的文本文件编译(预处理、编译、汇编、链接)成可执行的文件。
比如:
你写了一段代码(名为a.cpp),可以用任意文本编辑软件来写,不需要是IDE。
#include <iostream>
using namespace std;
int main()
{
cout<< "Hello, World!" << endl;
return 0;
}
下面我们开始编译程序,会经历4个步骤。
预处理
第一步,预处理, 以#开头的行都将被预处理器当做预处理命令来解释,比如#include包含头文件,在这一步就会将系统或本地的头文件插入的当前文本中。如果 #define 定义的宏则这这一步做展开(直接替换)
g++ -E a.cpp
编译
第二步,编译, 就是把文本中的代码转成汇编代码。
g++ -S a.cpp
会生成一个a .s文件,里面是汇编代码,这一步还是文本文件。
汇编
第三步,汇编,就是把汇编代码转成目标文件的格式
g++ -c a.cpp
会生成一个a .o文件,这一步开始已经是二进制文件了。但还不是可执行文件。
链接
第四步,链接,就是把上一步的目标文件转成可执行文件。
默认生成的可执行文件名称就是 a.out (默认可执行文件都叫是a.out)
例子:
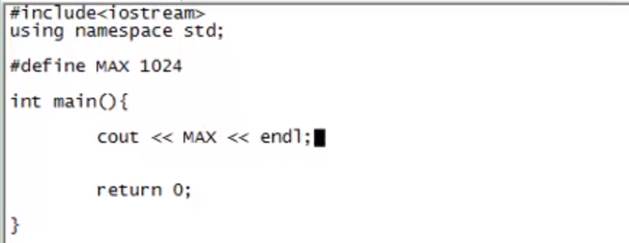
预编译,宏替换,头文件加载:
g++ -E test.cpp test.h -o test.i // -o test.i 输出成什么文件
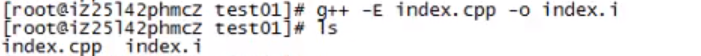
编译,生成汇编代码:
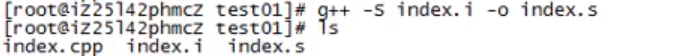
汇编,生成机器码:
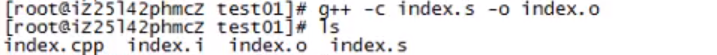
汇编+链接,生成可执行文件:

(28条消息) g++编译详解_三级狗的博客-CSDN博客_g++编译
十六、 shell脚本
Shell是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用Shell来启动、挂起、停止甚至是编写一些程序。看一个示意图

16.1 shell脚本的执行方式
脚本格式要求
- 脚本以#!/bin/bash开头
- 脚本需要有可执行权限
脚本的常用执行方式
-
方式1 (./脚本)
-
首先赋予xxx.sh脚本的可执行权限,再执行脚本
chmod 744 xxx.sh -
使用
./xxx.sh
-
-
方式2 (sh 脚本)
sh xxx,sh
16.2 注释
单行注释
#注释内容
多行注释
:<<!
#注释内容
!
16.3 shell变量
shell允许用户建立变量存储数据,但不支持数据类型(整型、字符、浮点型),将任何赋给变量的值都解释为一串字符
16.2.1 概要
Bourne Shell有如下四种变量:
- 用户自定义变量
- 位置变量(命令行参数)
- 预定义变量
- 环境变量
Linux Shell中的变量分为,系统变量($HOME, $PWD, $SHELL, $ USER等等)和用户自定义变量
显示当前shell中所有变量: set
16.2.2 用户自定义变量
定义变量规范
-
变量名称可以由字母、数字和下划线组成,但是不能以数字开头。5A=200(×)
-
等号两侧不能有空格
-
变量名称一般习惯为大写,这是一个规范
16.2.2.1 变量定义
-
定义变量: 变量名=值
注意: 不能有空格, 不用声明数据类型
#!/bin/bash a=100 echo "a=$a" 结果: a=100 -
撤销变量: unset 变量
#!/bin/bash a=100 echo "a=$a" unset a echo "a=$a" 结果: a=100 a= -
声明静态变量: readonly 变量. 注意:不能对静态变量 unset
readonly b=2 unset b #无效
16.2.2.2 变量的使用
基本语法
$变量名
注意: 可以直接放在字符串里面, 如echo “a=$a”
16.2.3 位置参数变量
当我们执行一个shell脚本时,如果希望获取到命令行的参数信息,就可以使用到位置参数变量
基本语法
$n (功能描述:n为数字,$0代表./脚本文件名,$1-$9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10})
$? (功能描述: 包含前一个命令的退出状态)
$$ (功能描述: 包含正在执行进程的ID号)
$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
$@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
$# (功能描述:命令行参数的个数)
例子
./myshell.sh 100 200,这个就是一个执行SnelI命令,可以在myshell脚本中获取到参数的信息:
#!/bin/bash
echo "$0 $1 $2"
echo "所有的参数=$*"
echo "$@"
echo "参数的个数=$#"
运行结果
[root@localhost shcode]# ./myshell.sh
./myshell.sh
所有的参数=
参数的个数=0
[root@localhost shcode]# ./myshell.sh 100 200
./myshell.sh 100 200
所有的参数=100 200
100 200
参数的个数=2
16.2.4 预定义变量
shell设计者事先已经定义好的变量,可以直接在shell脚本中使用
基本语法
$$(功能描述: 当前进程的进程号(PID))
$!(功能描述: 后台运行的最后一个进程的进程号(PID))
$?(功能描述: 最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;
如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)
if [ "$?" = "0" ]
例子
在一个shell脚本中简单使用一下预定义变量preVar.sh
# ! /bin/bash
echo "当前执行的进程id=$s"
#以后台的方式运行一个脚本,并获取他的进程号
echo "最后一个后台方式运行的进程id=$!"
echo_"执行的结果是=s?"
运行结果
lfj@lfj-virtual-machine:~/shell$ ./test.sh
当前执行的进程id=341916
最后一个后台方式运行的进程id=
执行的结果是=0
16.2.5 环境变量
常用shell环境变量
HOME: /etc/passwd文件中列出的用户主目录
IFS:Internal Field Separator, 默认为空格,tab及换行符
PATH :shell搜索路径
PS1,PS2:默认提示符($)及换行提示符(>)
TERM:终端类型,常用的有vt100,ansi,vt200,xterm等
基本语法
- export变量名=变量值(功能描述:将shell变量输出为环境变量/全局变量)
- source 配置文件
(功能描述:让修改后的配置信息立即生效) - echo $变量名
(功能描述:查询环境变量的值)
自定义使用:
-
在vim /etc/profile文件中定义TOMCAT_HOME环境变量:
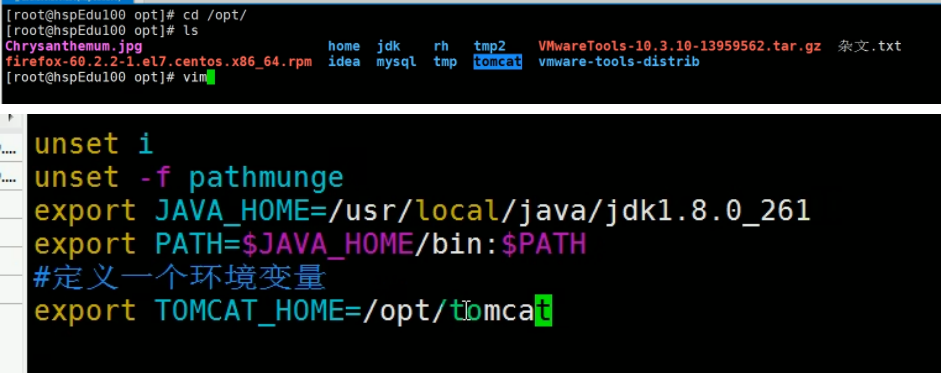
-
终端中查看环境变量TOMCAT_HOME:
echo $TOMCAT_HOME -
在脚本中直接使用TOMCAT_HOME
echo "tomcat_home=$TOMCAT_HOME"
注意: 在输出TOMCAT_HOME 环境变量前,需要让其生效source /etc/profile
16.2.5 引用linux命令的运行结果
基本语法
#语法1
A=`linux命令` 运行里面的命令,并把结果返回给变量A
#语法2
A=$(linux命令) 运行里面的命令,并把结果返回给变量A
例子
```shell
#!/bin/bash
c=`date`
D=$(date)
echo "C=$c"
echo "D=$D"
# 运行结果:
rootaLocaLhost shcode]#sh xxx.sh
C=Thu Aug 11 01:06:53 PDT 2022
D=Thu Aug 11 01:06:53 PDT 2022
16.3 功能语句
16.3.1 read命令
功能描述: 读入终端数据
基本语法
read var 把读入的数据全部赋给var
read var1 var2 var3 把读入行中的第一个单词(word)赋给var1, 第二个单词赋给var2, ……把其余所有的词赋给最后一个变量.如果执行read语句时标准输入无数据, 则程序在此停留等侯, 直到数据的到来或被终止运行。
常用选项:
-p: 指定读取值时的提示符;
-t: 指定读取值时等待的时间(秒),超出指定的时间内输入,就不再等待
例子
读取控制台输入一个NUM1值
#!/bin/bash
read -p "请输入一个数=" NUM1
echo "$NUM1"
#运行结果:
rootaLocaLhost shcode]#sh xxx.sh
请输入一个数=22
22
读取控制台输入一个num值,在10秒内输入
v#!/bin/bash
read -t 10 -p "请输入第二个数" NUM2
echo "$NUM2"
#运行结果:
rootaLocaLhost shcode]#sh xxx.sh
请输入第二个数=22
22
读取文件
一、按行读取文件
方法一:while循环中执行效率最高,最常用的方法。
#!/bin/bash
while read line
do
echo $line
done < filename(待读取的文件)
方法2 : 重定向法;管道法: cat $FILENAME | while read LINE
#!/bin/bash
cat filename(待读取的文件) | while read line
do
echo $line
done
方法3; for 循环
#!/bin/bash
for line in `cat filename(待读取的文件)`
do
echo $line
done
二、 读取特定行的内容
1. sed用法,读取某一行内容
#!/bin/bash
#sed用法 sed -n 'xp' data.txt
#读取第一行数据
sed -n '1p' data.txt
2. sed用法,读取文件X行到Y行的内容
#!/bin/bash
# 获取data.txt 第10-18行内容
sed -n '10,18p' data.txt
3. tail用法,读取文件末尾的数据。
#!/bin/bash
# 获取文件最后3行数据
tail -n -3 data.txt
# 获取文件第3行到最后一行数据
tail -n +3 data.txt
4. head用法,读取文本的前n行数据
#!/bin/bash
# 获取文本前10行数据
head -n 10 data.txt
5. tail和head的结合使用
#!/bin/bash
# 获取文本倒数第二行数据,结果如图所示
tail -n 2 data.txt | head -n 1
6. awk用法,awk在文本处理方面有着强大的功能,配合脚本使用,可以打印指定行和列。
#!/bin/bash
# NR指定行号
awk 'NR==18{print}' data.txt
16.3.2 expr命令
算术运算命令expr主要用于进行简单的整数运算,包括加(+)、减(-)、乘(\*)、整除(/)和求模(%)等操作。
基本语法
value_name=`expr 运算式`
例子
#!/bin/bash
num=9
sum=`expr $num \* 6` 反撇号引用命令的运行结果
16.3.3 运算符( 替代expr命令)
基本语法
#语法1(推荐)
$[运算式]
#语法2
$((运算式))
例子
#!/bin/bash
sum=$[2 * 10]
16.3.4 test语句
test语句可测试三种对象:
-
字符串
s1 = s2 测试两个字符串的内容是否完全一样 s1 != s2 测试两个字符串的内容是否有差异 -z s1 测试s1 字符串的长度是否为0 -n s1 测试s1 字符串的长度是否不为0 -
整数
a -eq b 测试a 与b 是否相等 a -ne b 测试a 与b 是否不相等 a -gt b 测试a 是否大于b a -ge b 测试a 是否大于等于b a -lt b 测试a 是否小于b a -le b 测试a 是否小于等于b注意: 大于greater than 小于less than 等于equal
-
文件属性
-d name 测试name 是否为一个目录
-e name 测试一个文件是否存在
-f name 测试name 是否为普通文件
-L name 测试name 是否为符号链接
-r name 测试name 文件是否存在且为可读
-w name 测试name 文件是否存在且为可写
-x name 测试name 文件是否存在且为可执行
-s name 测试name 文件是否存在且其长度不为0
f1 -nt f2 测试文件f1 是否比文件f2 更新
f1 -ot f2 测试文件f1 是否比文件f2 更旧
例子
test "$answer" = "yes"
变量answer的值是否为字符串yes
test $num –eq 18
变量num的值是否为整数18
test -d tmp
测试tmp是否为一个目录名
test -f "/root/shcode/aaa.txt"
测试/root/shcode/aaa.txt是否为一个文件
16.4 分支语句
16.4.1 条件语句
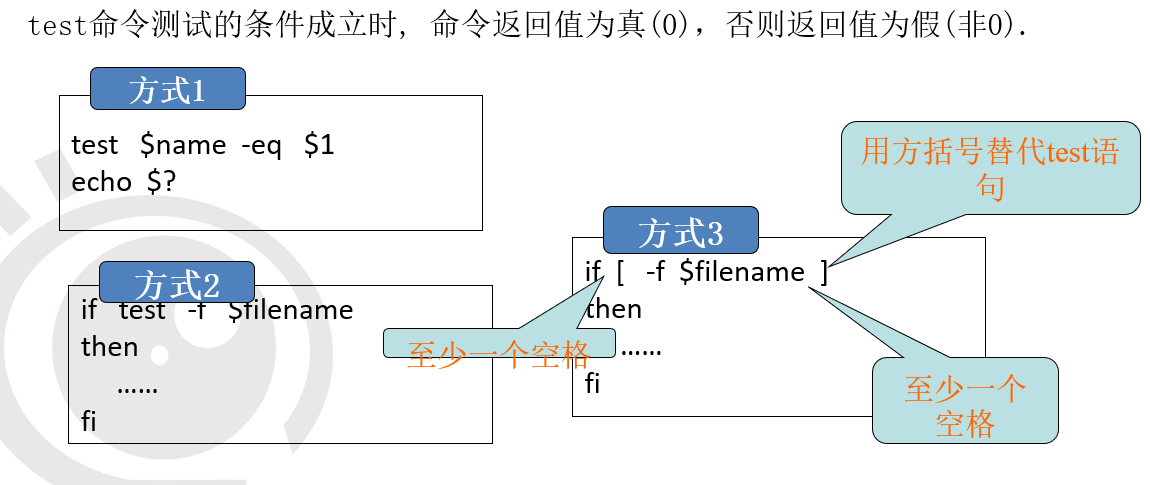
基本语法
if [ condition1 ]
then
#代码
elif [ condition2 ]
then
#代码
else
#代码
fi
注意: 注意condition前后必须要有空格
例子
#! /bin/bash
if [ $# -eq 0 ]
then
echo "$0 filename"
exit
fi
if ! [ -e $1 ]
then
echo "$1 not exist"
exit
fi
if [ -L $1 ]
then
echo "$1 是链接文件"
fi
if [ -w $1 ]
then
echo "$1 是存在的且可写"
fi
if [ -r $1 ]
then
echo "$1 是存在的且可读"
fi
if [ -S $1 ]
then
echo "$1 是套接字文件"
fi
if [ -b $1 ]
then
echo "$1 是块设备文件"
fi
例子
#! /bin/bash
if [ $# -eq 0 ]
then
echo "$0 filename"
exit
fi
if ! [ -e $1 ]
then
echo "$1 not exist"
exit
fi
if [ -L $1 ]
then
echo "$1 是链接文件"
elif [ -d $1 ]
then
echo "d"
elif [ -f $1 ]
then
echo "-"
elif [ -b $1 ]
then
echo "b"
elif [ -c $1 ]
then
echo "c"
elif [ -S $1 ]
then
echo "S"
else
echo "p"
fi
16.4.2 多路分支语句
基本语法
case 字符串变量 in
模式1)
命令表1
;;
模式2 | 模式3)
命令表2
;;
……
模式n)
命令表n
;;
esac
例子
#!/bin/bash
read -p "input a number = " var
if [ $var -lt 0 ] || [ $var -gt 100 ]
then
echo "input error"
exit 0
fi
val=`expr $var / 10`
case $val in
8|9|10)
echo "A"
;;
6|7)
echo "B"
;;
*)
echo "C"
;;
esac
例子
#! /bin/bash
echo -e "请输入: \c"
read A
case $A in
gao | Gao | g |G)
echo "1111111111"
;;
yyy)
echo "2222222"
;;
*)
echo "error"
;;
esac
例子
#! /bin/bash
echo -n "please input score:"
read S
if [ $S -lt 0 -o $S -gt 100 ]
then
echo "not in [ 0-100 ]"
exit
fi
G=`expr $S / 10`
case $G in
9|10)
echo "$S A"
;;
6|7|8)
echo "$S B"
;;
*)
echo "$S C"
esac
16.5 循环语句
16.5.1 for循环
基本语法
# 语法1
for 变量 in 值1值2值3….
do
#代码
done
# 语法2
for ((初始值;循环控制条件;变量变化))
do
#代码
done
例子
拷贝当前目录下的所有文件到backup子目录下:
#!bin/bash
if [ !-d $HOME/backup ]
then
mkdir $HOME/backup
fi
flist=`ls`
for file in $flist
do
if [ $# = 1 ]
then
if [ $1 = $file ]
then
echo "$file found" ; exit
fi
else
cp $file $HOME/backup
echo "$file copied"
fi
done
echo ***Backup Completed***
打印命令行输入的参数:
!bin/bash
# $* 是把终端参数当成一个整体
# $@ 是把终端参数会区分的
for i in "$*" # 用$@ 或者 不加双引号就是一个一个依次输出了
do
echo "num is $i"
done
#运行结果:
# 用"$*"
[root@localhost shcode]# sh testFor.sh 10 20 30
num is 10 20 30
# 用$@ 不加双引号就是一个一个依次输出了
[root@localhost shcode]# sh testFor.sh 10 20 30
num is 10
num is 20
num is 30
从1加到100的值输出显示:
#!bin/bash
SUM=0
for ((i = 1; i <= 100; i++))
do
SUM=$[$SUM+$i]
done
echo "总和=$SUM"
#运行结果:
[root@localhost shcode]# sh testFor.sh
总和=5050
16.5.2 while循环
基本语法
# 语法1
while [ 条件判断式 ]
do
#代码
done
# 语法2
while ((条件判断式))
do
#代码
done
例子
从命令行输入一个数n,统计从1+x+n的值是多少:
#!/bin/bash
SUN=0
i=0
while [ $i -le $1 ]
do
SUM=$[$SUM+$i]
i=$[$i+1]
done
echo $SUM
#运行结果
rootaLocaLhost shcode]#sh testwhile.sh10
55
例子
#! /bin/bash
I=0
while true
do
I=`expr $I + 1`
echo -n "input : "
read S
case `expr $S / 10` in
10|9)
echo "A"
;;
6|7|8)
echo "B"
;;
*)
echo "C"
;;
esac
done
例子
#! /bin/bash
I=0
echo -n "input number:"
read S
while [ $I -lt $S ]
do
I=`expr $I + 1`
>FILE$I
done
16.5.3 循环控制语句
- break
- continue
例子
#! /bin/bash
i=1
sum=0
while [ $i -le 10 ]
do
sum=`expr $sum + $i`
i=`expr $i + 1`
if [ $i -eq 3 ]
then
break
fi
done
echo "i = $i sum = $sum"
16.6 函数
shell编程和其它编程语言一样,有系统函数,也可以自定义函数
16.6.1 常见的系统函数
16.6.1 basename
功能描述: 返回完整路径最后/ 的部分,常用于获取文件名
basename [pathname] [suffix]
basename [string] [suffix](basename命令会删掉所有的前缀包括最后一个(‘T)字符,然后将字符串显示出来
常用选项
-suffix: basename会将pathname或string中的suffix去掉
例子
返回/home/aaa/test.txt 的"test.txt"部分
[root@localhost shcode]# basename /home/aaa/test.txt
test.txt
[root@localhost shcode]# basename /home/aaa/test.txt .txt
test
16.6.2 dirname
功能描述: 返回文件名前路径的部分
[root@localhost shcode]# dirname /home/aaa/test.txt
/home/aaa
[root@localhost shcode]# dirname /home/aaa/bbb/test.txt
/home/aaa/bbb
注意: 这两个函数经常使用在脚本文件里,得到一般是全路径,需要用这两个函数做处理
16.6.1 自定义函数
基本语法
function funname()
{
程序/代码
}
16.6.1.1 函数调用格式
function_name [arg1 arg2 … ]
16.6.1.2 函数变量作用域
-
全局作用域:在脚本的其他任何地方都能够访问该变量。(默认)
-
局部作用域:只能在声明变量的作用域内访问。
-
声明局部变量的格式:
local variable_name=value
-
16.6.1.3 返回值的方式
-
使用return返回值:
使用return返回值,只能返回1-255的整数 函数使用return返回值,通常只是用来供其他地方调用获取状态,通常仅返回0或1;接收方式:通过$?获取返回值。
#方式2:获取函数的返回的状态 function_name [arg1 arg2 …] echo $? -
使用echo返回值:
使用echo可以返回任何字符串]结果 通常用于返回数据,比如一个字符串值或者列表值接收方式:通过$()或``获取返回值。
#方式1:函数的所有标准输出都传递给了主程序的变量 value_name=`function_name [arg1 arg2 … ]`
例子
#!/bin/bash
getSum1()
{
SUM=$[$n1+$n2]
echo "test1和是=$SUM"
}
getSum2()
{
SUM=$[$n1+$n2]
echo $SUM
}
getSum3()
{
SUM=$[$n1+$n2]
return $SUM
}
function scope()
{
local lclvariable=1
Gblvariable=2
echo "lclavariable in function = $lclvariable"
echo "Gblvariable in function = $Gblvariable"
}
#输入两个值
read -p "请输入一个数" n1
read -p "请输入一个数" n2
##### 不带返回值 #####
#调用自定义函数1
getSum1 $nl $n2
##### 返回值 #####
#调用自定义函数2
value_sum=`getSum2 $nl $n2`
echo "test2和是=$value_sum"
#调用自定义函数3
getSum3 $nl $n2
echo "test3和是=$?"
##### 变量作用域 #####
#调用自定义函数4
scope
echo "lclavariable in function = $lclvariable"
echo "Gblvariable in function = $Gblvariable"
#运行结果
lfj@lfj-virtual-machine:~/shell$ ./function.sh
请输入一个数1
请输入一个数9
test1和是=10
test2和是=10
test3和是=10
lclavariable in function = 1
Gblvariable in function = 2
lclavariable in function =
Gblvariable in function = 2
例子
grep_user()
{
R=`grep "$1" /etc/passwd | wc -l`
echo $R
return $R
}
echo -n "input username:"
read USER
grep_user $USER
RET=$?
if [ $RET -eq 1 ]
then
echo "$USER exist"
else
echo "$USER not exist"
fi
例子
grep_user()
{
R=`grep "^$1:" /etc/passwd | wc -l`
echo $R
}
echo -n "input username:"
read USER
RET=`grep_user $USER`
echo "----return $RET----"
if [ $RET -eq 1 ]
then
echo "$USER exist"
else
echo "$USER not exist"
fi
16.7 通配符+正则表达式
SHELL脚本-通配符+正则表达式
通配符
一般用于文件名匹配
常用通配符
*: 匹配0或多个任意字符
?: 匹配任意一个字符
[list] : 匹配list中的任意单个字符
[c1-c2]: 匹配c1‐c2中任意单个字符
[!list]: 匹配除list中的任意单个字符
[^list]: 匹配除list中的任意单个字符
{string1,string2,...}:匹配string1,string2或更多字符串
{c1‐c2}: 匹配c1‐c2中任意多个字符
12345678910
- 用法
[root@server1 tmp]# touch file{1..8}
[root@server1 tmp]# ls
file1 file2 file3 file4 file5 file6 file7 file8
[root@server1 tmp]# rm -rf file*
[root@server1 tmp]# ls
[root@server1 tmp]# touch file{1,2,3}
[root@server1 tmp]# ls file[123]
file1 file2 file3
[root@server1 tmp]# touch file{a..f}
[root@server1 tmp]# ls file[a-f]
filea fileb filec filed filee filef
[root@server1 tmp]# touch file{4,5,6}
[root@server1 tmp]# ls file[^456]
file1 file2 file3 filea fileb filec filed filee filef
[root@server1 tmp]# touch file{10..15}
[root@server1 tmp]# ls
file10 file11 file12 file13 file14 file15
12345678910111213141516171819
shell转义符
" ": 软转义,引号内部为整体,允许执行内部命令
' ': 硬转义,引号内部为整体
` `: 同$()一样,引号(括号)里的命令会优先执行,但若存在嵌套,反撇号不能用
123
- 用法
[root@server1 tmp]# echo $(date +%F)
2021-08-21
[root@server1 tmp]# echo "$(hostname)"
server1
[root@server1 tmp]# echo '$(hostname)'
$(hostname)
123456
正则表达式
概念
- 正则表达式(Regular Expression、regex或regexp,缩写为RE),也译为正规表示法、常规表示法,是一种字符模式,用于在查找过程中匹配指定的字符。针对文件内容的文本过滤工具里,大都用到正则表达式,如vi,grep,awk, sed,find等
- 元字符:在正则表达式中具有特殊意义的专用字符
- 前导字符:位于元字符前面的字符
常用元字符
#示例文件
[root@server1 tmp]# cat test.txt
hello
hello kugou
scjnhbjzj cbhx
xvjnk jnffjkdfjkvn jfddnvfkvsi
scnjdsj
dvvre
192.168.138.14
10086/
sdffregkksdknaer;
www.baidui.com
www.taobao.com.
114.114.114.114
192.168.226.14/24
. : 任意单个字符
* : 前导字符出现0次或连续多次,ab*能匹配“a”,“ab”以及“abb”
.*: 任意长度的字符
[root@server1 tmp]# cat test.txt |grep sc.*
scjnhbjzj cbhx
scnjdsj
^ : 以什么开头
$ : 以什么结尾
^$: 空行
[root@server1 tmp]# cat test.txt |grep '^hel'
hello
hello kugou
[root@server1 tmp]# cat test.txt |grep 'ou$'
hello kugou
[list] : 匹配list中的任意单个字符
[^list] : 匹配除list中的任意单个字符
^[list] : 匹配以list中的任意单个字符开头的
^[^list]: 匹配除list中的任意单个字符开头的
[root@server1 tmp]# cat test.txt |grep '[^abc]'
hello
hello kugou
scjnhbjzj cbhx
xvjnk jnffjkdfjkvn jfddnvfkvsi
scnjdsj
dvvre
192.168.138.14
10086/
sdffregkksdknaer;
www.baidui.com
www.taobao.com.
114.114.114.114
192.168.226.14/24
[root@server1 tmp]# cat test.txt |grep '^[dcb]'
dvvre
\< : 以什么开头
\> : 以什么结尾
\<\>: 精确匹配
[root@server1 tmp]# cat test.txt |grep '\<hello'
hello
hello kugou
[root@server1 tmp]# cat test.txt |grep 'kugou\>'
hello kugou
[root@server1 tmp]# cat test.txt |grep '\<10086\>'
10086/
\{n\} : 匹配前导字符连续出现n次 如:go\{2\},匹配goo...
\{n,\} : 匹配前导字符至少出现n次 如:go\{2,\},匹配goo...,gooo...,goooo...,gooooo...等
\{n,m\}: 匹配前导字符出现n次与m次之间 如:go\{2,\},匹配goo...,gooo...
\(strings\) : 保存被匹配的字符,后面可以用标签\1代替
[root@server1 tmp]# sed 's/\(SELINUX=\)disabled/\1enforced/' /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# disabled - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of disabled.
# disabled - No SELinux policy is loaded.
SELINUX=enforced
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
扩展正则表达式(-E)
+ : 匹配一个或多个前导字符
? : 匹配零个或一个前导字符
[root@server1 tmp]# cat test.txt |grep -E 'h+'
hello
hello kugou
scjnhbjzj cbhx
a|b : 匹配a或b
() : 组字符
[root@server1 tmp]# cat test.txt |grep -E '3|4'
192.168.138.14
114.114.114.114
192.168.226.14/24
[root@server1 tmp]# cat test.txt |grep -E '(taobao|baidui).com'
www.baidui.com
www.taobao.com.
{n} : 前导字符重复n次 \{n\}
{n,} : 前导字符重复至少n次 \{n,\}
{n,m}: 前导字符重复n到m次 \{n,m\}
[root@server1 tmp]# cat test.txt |grep -E '1{1,2}'
192.168.138.14
10086/
114.114.114.114
192.168.226.14/24
Perl内置正则(-P)
\d : 匹配数字 [0-9]
\w : 匹配字母数字下划线[a-zA-Z0-9_]
\s : 匹配空格、制表符、换页符[\t\r\n]
[root@server1 tmp]# cat test.txt |grep '[0-9]'
192.168.138.14
10086/
114.114.114.114
192.168.226.14/24
[root@server1 tmp]# cat test.txt |grep -P '\d'
192.168.138.14
10086/
114.114.114.114
192.168.226.14/24
[root@server1 tmp]# cat test.txt |grep -P '\s'
hello kugou
scjnhbjzj cbhx
xvjnk jnffjkdfjkvn jfddnvfkvsi
1234567891011121314151617
综合案列
在test.txt文件中匹配ip地址
匹配IP地址
[root@server1 tmp]# cat test.txt |grep '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}'
192.168.138.14
[root@server1 tmp]# cat test.txt |grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'
192.168.138.14
[root@server1 tmp]# cat test.txt |grep -P '\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}'
192.168.138.14
[root@server1 tmp]# cat test.txt |grep -P '(\d{1,3}\.){3}\d{1,3}'
192.168.138.14
匹配本机IP地址、广播地址、子网掩码
[root@server1 tmp]# ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.226.10 netmask 255.255.255.0 broadcast 192.168.226.255
inet6 fe80::1b78:bfb3:4567:b45c prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:17:9d:b3 txqueuelen 1000 (Ethernet)
RX packets 13611 bytes 12551752 (11.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5499 bytes 485078 (473.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@server1 tmp]# ifconfig ens33|grep broadcast|grep -o -P '(\d{1,3}\.){3}\d{1,3}'
192.168.226.10
255.255.255.0
192.168.226.255
[root@server1 tmp]# cat /etc/sysconfig/network-scripts/ifcfg-ens33 |grep -v 'DNS'|grep -P '(\d{1,3}\.){3}\d{1,3}'
IPADDR=192.168.226.10
GATEWAY=192.168.226.2
NETMASK=255.255.255.0
了解:第二类正则
| 表达式 | 功能 | 备注 |
|---|---|---|
| [:alnum:] | 字母与数字字符 | [[:alnum:]]=[a-zA-Z0-9] |
| [:alpha:] | 字母字符(包括大小写字母) | [[:alpha:]]=[a-zA-Z] |
| [:blank:] | 空格与制表符 | [[:blank:]]=[\t\r] |
| [:digit:] | 数字 | [[:digit:]]=[0-9] |
| [:lower:] | 小写字母 | [[:lower:]]=[a-z] |
| [:upper:] | 大写字母 | [[:upper:]]=[A-Z] |
| [:punct:] | 标点符号 | |
| [:space:] | 包括换行符,回车等在内的所有空白 | [[:space:]]=[\t\r\n]=\s |
16.8 综合案例
Shell编程综合案例
-
每天凌晨2:30备份;
-
备份开始和备份结束能够给出相应的提示信息
-
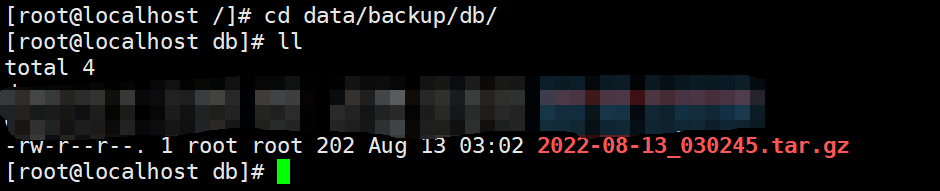
备份后的文件要求以备份时间为文件名,并打包成.tar.gz的形式,比如:2021-03-12_230201.tar.gz
-
在备份的同时,检查是否有10天前备份的数据库文件,如果有就将其删除。
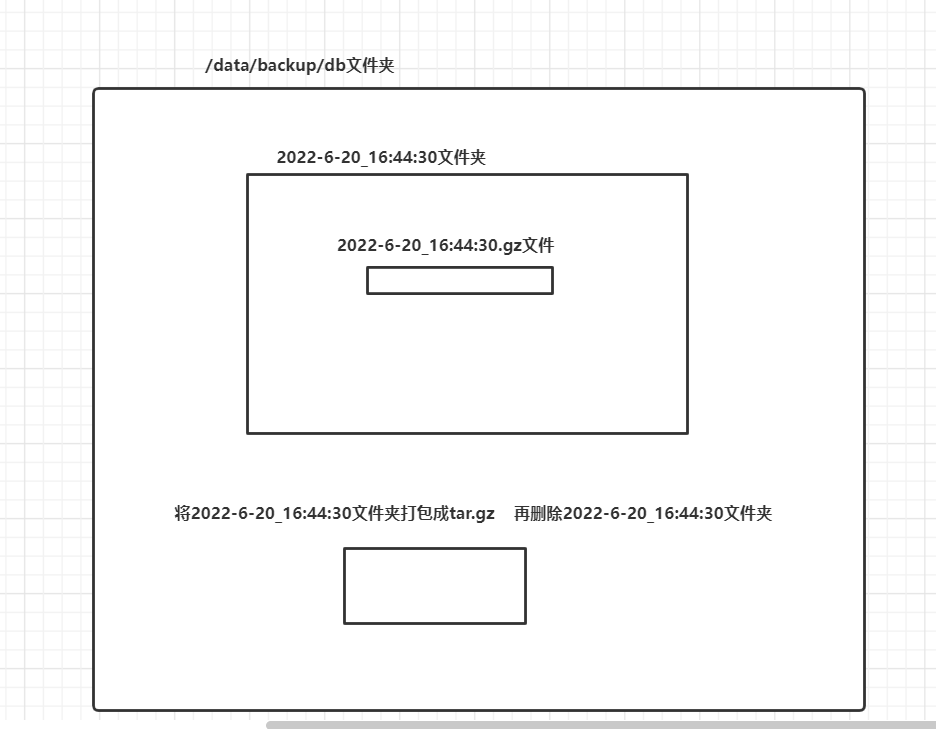
BACKUP="/data/backup/db"
BATETIME=$(date "+%Y-%m-%d_%H%M%S")
echo "$BATETIME"
DATA="数据库"
if [ ! -d "$BACKUP/$BATETIME" ]
then
mkdir -p "$BACKUP/$BATETIME"
fi
echo "$DATA" | gzip > "$BACKUP/$BATETIME/$BATETIME.gz"
#将文件处理成 tar.gz
cd "$BACKUP"
tar -czvf "$BATETIME.tar.gz" "$BATETIME"
#删除对应的多余文件
rm -rf "$BATETIME"
#删除10天前的文件
find "$BACKUP" -atime +10 -name "*.tar.gz" -exec -rf {} \;
echo "操作成功"
"test.sh" 26L, 474C
设置crond任务调度(定时任务)
crontab -e
0 2 * * * /root/shcode/test.sh
效果:
十七、 日志管理
17.1 基本介绍
- 日志文件是重要的系统信息文件,其中记录了许多重要的系统事件,包括用户的登录信息、系统的
启动信息、系统的安全信息、邮件相关信息、各种服务相关信息等。 - 日志对于安全来说也很重要,它记录了系统每天发生的各种事情,通过日志来检查错误发生的原因,
或者受到攻击时攻击者留下的痕迹。 - 可以这样理解日志是用来记录重大事件的工具
/var/log/目录就是系统日志文件的保存位置
进入 cd /var/log/ 可以查看日志
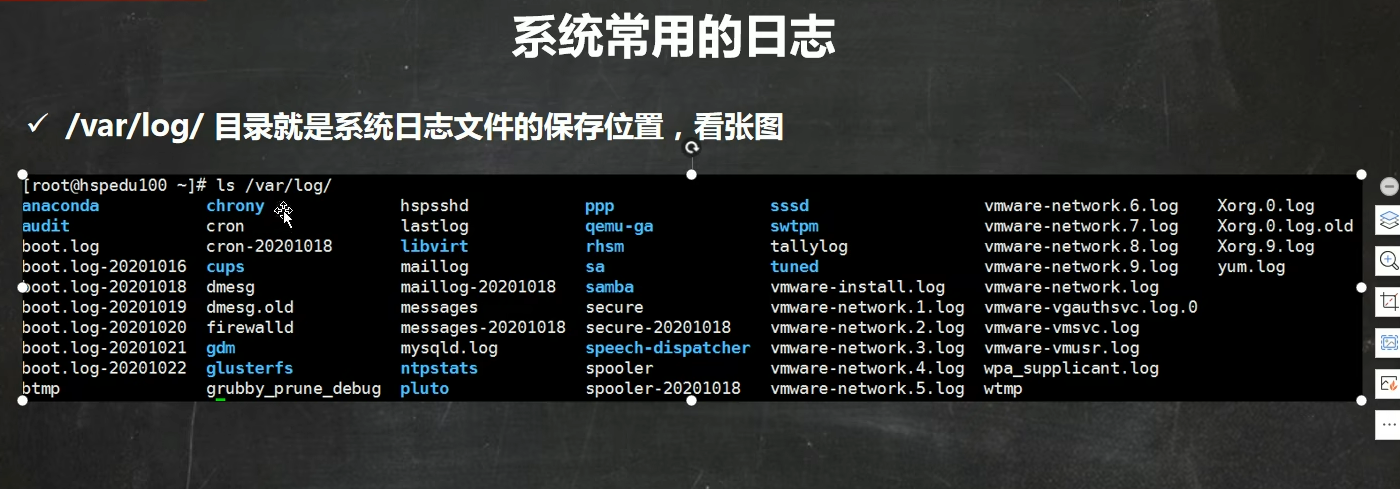

| 日志文件 | 说 明 |
|---|---|
| /var/log/cron | 记录与系统定时任务相关的曰志 |
| /var/log/cups/ | 记录打印信息的曰志 |
| /var/log/dmesg | 记录了系统在开机时内核自检的信总。也可以使用dmesg命令直接查看内核自检信息 |
| /var/log/btmp | 记录错误登陆的日志。这个文件是二进制文件,不能直接用Vi查看,而要使用lastb命令查看。命令如下: [root@localhost log]#lastb root tty1 Tue Jun 4 22:38 - 22:38 (00:00) #有人在6月4 日 22:38便用root用户在本地终端 1 登陆错误 |
| /var/log/lasllog | 记录系统中所有用户最后一次的登录时间的曰志。这个文件也是二进制文件.不能直接用Vi 查看。而要使用lastlog命令查看 |
| /var/Iog/mailog | 记录邮件信息的曰志 |
| /var/log/messages | 它是核心系统日志文件,其中包含了系统启动时的引导信息,以及系统运行时的其他状态消息。I/O 错误、网络错误和其他系统错误都会记录到此文件中。其他信息,比如某个人的身份切换为 root,已经用户自定义安装软件的日志,也会在这里列出。 |
| /var/log/secure | 记录验证和授权方面的倍息,只要涉及账户和密码的程序都会记录,比如系统的登录、ssh的登录、su切换用户,sudo授权,甚至添加用户和修改用户密码都会记录在这个日志文件中 |
| /var/log/wtmp | 永久记录所有用户的登陆、注销信息,同时记录系统的后动、重启、关机事件。同样,这个文件也是二进制文件.不能直接用Vi查看,而要使用last命令查看 |
| /var/tun/ulmp | 记录当前已经登录的用户的信息。这个文件会随着用户的登录和注销而不断变化,只记录当前登录用户的信息。同样,这个文件不能直接用Vi查看,而要使用w、who、users等命令查看 |
17.2 日志管理服务
日志管理服务 rsyslogd
CentOS7.6日志服务是rsyslogd , CentOS6.x日志服务是syslogd 。 rsyslogd功能更强大。rsyslogd 的使用、日志文件的格式,和syslogd服务兼容的。
原理示意图
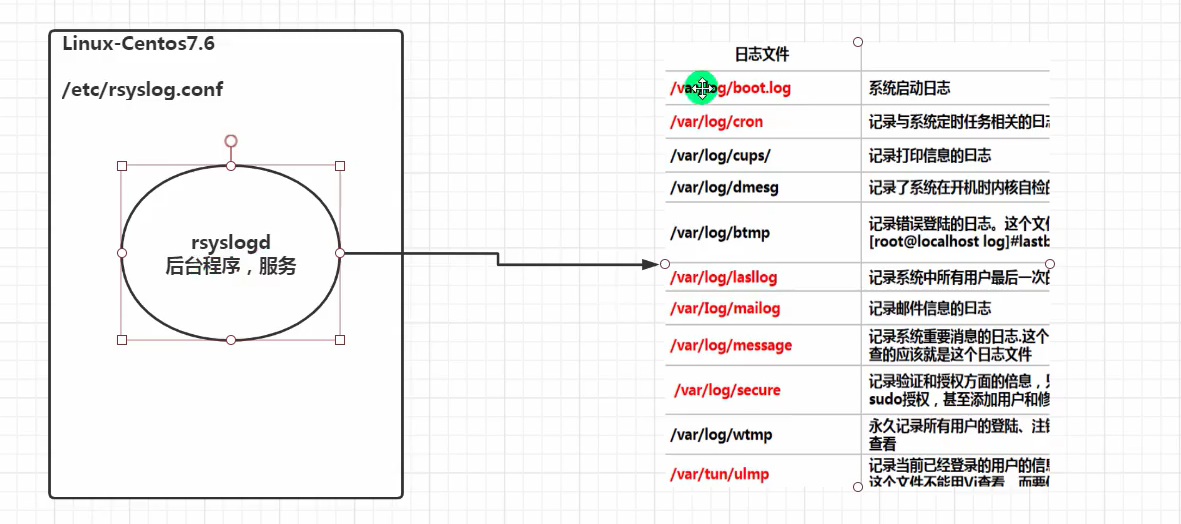
- 查询Linux 中的rsyslogd 服务是否启动
ps aux | grep “rsyslog” | grep -v “grep” - 查询rsyslogd 服务的自启动状态
systemctl list-unit-files | grep rsyslog
配置文件: /etc/rsyslog.conf
日志级别分为:
debug ##有调试信息的,日志通信最多
info ##—般信息日志,最常用
notice ##最具有重要性的普通条件的信息
warning ##警告级别
err ##错误级别,阻止某个功能或者模块不能正常工作的信息
crit ##严重级别,阻止整个系统或者整个软件不能正常工作的信息
alert ##需要立刻修改的信息
emerg ##内核崩溃等重要信息
none ##什么都不记录
注意:从上到下,级别从低到高,记录信息越来越少
**由日志服务rsyslogd记录的日志文件,日志文件的格式包含以下4列:**基本日志格式包含以下四列:
(1) 事件产生的时间
(2) 发生事件的服务器的主机名
(3) 产生事件的服务名或程序名
(4) 事件的具体信息
日志如何查看实例
查看一下/ar/log/secure日志,这个日志中记录的是用户验证和授权方面的信息来分析如何查看Nov 12 12:18:26

17.3 自定义日志服务
在/etc/rsyslog.conf 中添加一个日志文件/var/log/hsp.log,当有事件发送时(比如sshd服务相关事件),该文件会接收到信息并保存。演示重启,登录的情况,看看是否有日志保存
- vim /etc/rsyslog.conf 进入日志管理服务

- 重启服务 systemctl restart rsyslog.service
- 进入 cd /var/log/ 使用 cat hsp.log 查看自定义的日志
十八、基础配置
环境变量
变量是计算机系统用于保存可变值的数据类型。在Linux系统中,变量名称一般都是大写的,这是一种约定俗成的规范。我们可以直接通过变量名称来提取到对应的变量值。Linux系统中的环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的家目录、邮件存放位置等。
环境变量配置位于 ~/.bash_profile
$ vim ~/.bash_profile
PATH=$PATH:$HOME/bin:/usr/local/python3/bin
export PATH
Linux系统中最重要的10个环境变量:
●HOME 用户的主目录(即家目录)
●SHELL 用户在使用的Shell解释器名称
●HISTSIZE 输出的历史命令记录条数
●HISTFILESIZE 保存的历史命令记录条数
●MAIL 邮件保存路径
●LANG 系统语言、语系名称
●RANDOM 生成一个随机数字
●PS1 Bash解释器的提示符
●PATH 定义解释器搜索用户执行命令的路径
●EDITOR 用户默认的文本编辑器
PATH
PATH 不同的环境变量使用 : 分割。
执行source命令使其生效:
source ~/.bash_profile
也可直接对PATH变量进行设置
$ echo $PATH
/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin
PATH=$PATH:/root/bin
$ echo $PATH
/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin:/root/bin
自定义环境变量
其实变量是由固定的变量名与用户或系统设置的变量值两部分组成的,我们完全可以自行创建变量,来满足工作需求。例如设置一个名称为WORKDIR的变量,方便用户更轻松地进入一个层次较深的目录:
mkdir /home/workdir
WORKDIR=/home/workdir
cd $WORKDIR
$ pwd
/home/workdir
但是,这样的变量不具有全局性,作用范围也有限,默认情况下不能被其他用户使用。如果工作需要,可以使用export命令将其提升为全局变量,这样其他用户也就可以使用它了:
[root@linuxprobe workdir]# su linuxprobe
Last login: Fri Mar 20 20:52:10 CST 2017 on pts/0
[linuxprobe@linuxprobe ~]$ cd $WORKDIR
[linuxprobe@linuxprobe ~]$ echo $WORKDIR
[linuxprobe@linuxprobe ~]$ exit
[root@linuxprobe ~]# export WORKDIR
[root@linuxprobe ~]# su linuxprobe
Last login: Fri Mar 20 21:52:10 CST 2017 on pts/0
[linuxprobe@linuxprobe ~]$ cd $WORKDIR
[linuxprobe@linuxprobe workdir]$ pwd
/home/workdir
主机名
当使用多台主机的时候, 如果使用默认主机名, 将很难区分其名字, 可以使用以下命令进行重命名主机名:
hostname node1
以上修改, 将在服务器不重启的条件下生效, 若服务器重启将恢复默认主机名。
或者修改配置文件 /etc/hostname, 配置将在重启服务器后生效:
$ vim /etc/hostname
node1
命令别名
命令别名配置位于 ~/.bashrc
$ vim ~/.bashrc
alias cp='cp -i'
alias mv='mv -i'
alias rm='rm -i'
alias saferm='saferm.sh'
执行source命令使其生效:
source ~/.bashrc
可以直接用 alias 命令来创建一个属于自己的命令别名,格式为 alias 别名=命令 , 直接使用 alias 别名 可以查看当前别名绑定的命令。若要取消一个命令别名,则是用 unalias 命令,格式为 unalias 别名。
创建一个别名:
alias netstatl='netstat -ntlp'
netstatl
我们之前在使用rm命令删除文件时,Linux系统都会要求我们再确认是否执行删除操作,其实这就是Linux系统为了防止用户误删除文件而特意设置的rm别名命令,接下来我们把它取消掉:
$ ls
anaconda-ks.cfg Documents initial-setup-ks.cfg Pictures Templates
Desktop Downloads Music Public Videos
$ rm anaconda-ks.cfg
rm: remove regular file 'anaconda-ks.cfg'? y
$ alias rm
alias rm='rm -i'
unalias rm
rm initial-setup-ks.cfg
hosts
hosts 文件位于 /etc/hosts
vim /etc/hosts
# 单个虚拟主机
127.0.0.1 localhost
# 多个虚拟主机
192.168.0.15 node1 node2 node3
查看系统信息
uname -a # 显示系统名、节点名称、操作系统的发行版号、操作系统版本、运行系统的机器 ID 号
arch # 显示机器的处理器架构
iconv -l # 列出已知的编码
cat /proc/cpuinfo # 显示CPU info的信息
cat /proc/interrupts # 显示中断
cat /proc/meminfo # 校验内存使用
cat /proc/swaps # 显示哪些swap被使用
cat /proc/version # 显示内核的版本
cat /proc/net/dev # 显示网络适配器及统计
cat /proc/mounts # 显示已加载的文件系统
cat /etc/issue # 查看系统版本
$ cat /etc/redhat-release # 查看内核信息(红帽系)
CentOS Linux release 7.6.1810 (Core)